You can check the health of a Persistent Disk or Google Cloud Hyperdisk volume by reviewing the disk performance status metric. This metric indicates whether the disk's performance is potentially affected by adverse events within Compute Engine.
An issue affecting the disk performance status might also be visible in your project's Personal Service Health (PSH) dashboard or the Google Cloud Service Health dashboard.
This document discusses the disk performance status and how to use it to troubleshoot performance issues.
When to check a disk's health
If you notice a performance issue with a disk, check the disk's health by reviewing the disk performance status metric. The disk performance status metric is updated every minute and represents disk performance over the entire previous minute. For steps to check the disk's health, see view disk performance status.
The following table summarizes the possible values of the disk performance status.
| Status | Meaning |
|---|---|
Healthy |
Disk performance is as expected. |
Degraded |
You might temporarily observe higher than expected I/O latency. |
Severely degraded |
High I/O latency or other errors are occurring. |
If the performance status isn't Healthy, see Understand each status
for next steps.
If the performance status is Healthy, the disk is functioning normally and you
need to check for other causes for the performance issue.
You should check for application or operating system errors and make sure your
disk is optimized correctly. For optimization guidelines,
see Optimize Hyperdisk
and Optimize Persistent Disk.
How the disk health relates to other disk performance metrics
The disk's health as indicated by the performance status metric shows the
internal status of the disk from Google's perspective. If a disk's status is
Degraded or Severely Degraded, the root cause is always within the
Compute Engine infrastructure.
You generally can't change a disk's health by modifying the workload. However, in rare cases, a change to the workload might trigger an internal issue, so it might be possible to mitigate an issue by modifying the workload.
To learn about the other available disk performance metrics, see Review disk performance metrics.
Scenarios that don't affect the disk performance status
The disk performance status is unrelated to performance issues caused by the following factors:
- Incomplete or insufficient disk optimization
- Performance limit associated with the disk and machine type (if the chosen machine type can't meet the performance requirements of your workload)
- Increased load on the disk due to workload traffic
- User, application, or operating system error
- Full or corrupted disks
- For Hyperdisk and Extreme Persistent Disk volumes, insufficiently provisioned IOPS or throughput.
In these situations, it is your responsibility to improve performance, such as by optimizing the disk, scaling up the workload, changing the machine type, and provisioning more capacity, IOPS, or throughput.
View a disk's health in Cloud Monitoring
To view a disk's health, create a chart in Metrics Explorer.
Required roles and permissions
To get the permissions that you need to check the disk performance status metric, ask your administrator to grant you the following IAM roles on the project:
-
Monitoring Viewer (
roles/monitoring.viewer) -
To save a chart to a dashboard:
Monitoring Editor (
roles/monitoring.editor)
For more information about granting roles, see Manage access to projects, folders, and organizations.
You might also be able to get the required permissions through custom roles or other predefined roles.
Create a chart in Metrics Explorer
To create a chart, build a query with either the menu-driven interface or PromQL.
Menu-driven interface
To view the health of one or more disks on a chart, follow these instructions.
-
In the Google Cloud console, go to the leaderboard Metrics explorer page:
If you use the search bar to find this page, then select the result whose subheading is Monitoring.
- In the toolbar of the Google Cloud console, select your Google Cloud project. For App Hub configurations, select the App Hub host project or the app-enabled folder's management project.
- In the Metric element, expand the Select a metric menu,
enter
VM Instancein the filter bar, and then use the submenus to select a specific resource type and metric:- In the Active resources menu, select VM Instance.
- In the Active metric categories menu, select Instance.
- In the Active metrics menu, select Disk performance status.
- Click Apply.
compute.googleapis.com/instance/disk/performance_status. To add filters, which remove time series from the query results, use the Filter element.
- Configure how the data is viewed.
Disable aggregation. Make sure that in the Aggregation element, first menu is set to Unaggregated and the second menu is set to None.
To view the health of a specific disk, filter bydevice_name.
For more information about configuring a chart, see Select metrics when using Metrics Explorer.
PromQL
Open the query editor: follow the steps in Write PromQL Queries.
Enter your query in the query editor. For example, to view the performance status of a specific disk, enter the following query:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
Replace DISK_NAME with the disk name, for example,
disk-1.
If you view the results in a chart, then there are 3 lines for each disk, one for each possible status. Similarly, if you view the query result in a table, then the table has 3 rows for each disk.
If you built the query with PromQL, then each row or line will
have a value of 1 or 0. For queries built with the menus, the values for
will be 100% or 0.
The disk's current health is represented by the row or line whose value is 100%
or 1.
For example, the following screenshot shows the chart for a disk named a-test-VM,
whose status is Healthy:
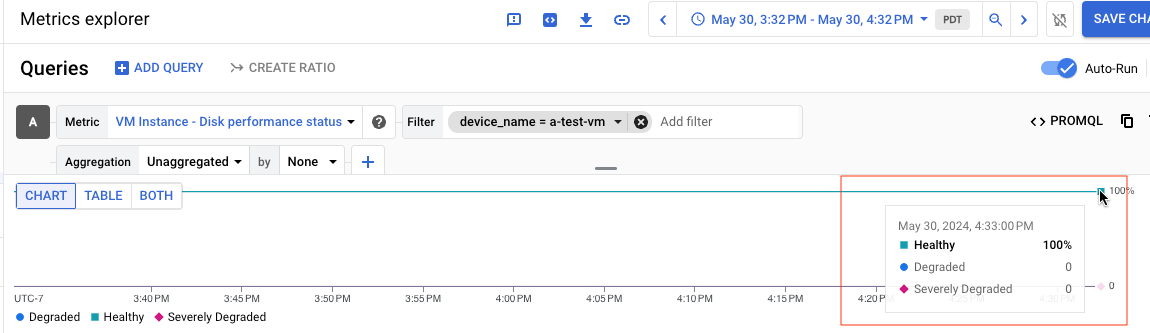
If you view the query results as a table, the following table is an example of
the results for a disk that's Healthy:
| performance_status | value |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
The following screenshot shows the chart for a disk called replica-23509 whose status is Degraded:
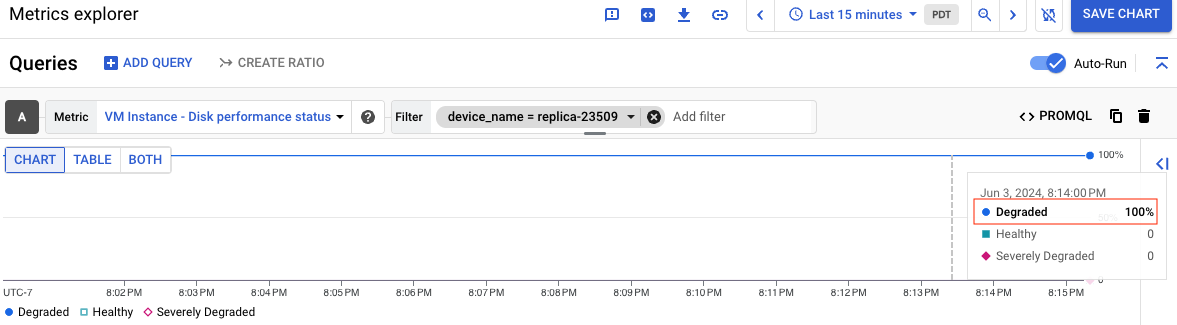
For information about what each performance status means, see Understand each status. After you create the chart, you can save the chart to a dashboard for future use.
Fractional results
If your query includes fractional results like in the following table,
this is typically because the selected display period
was long. As a result Cloud Monitoring aggregated the data over time.
A value of 77% for the Healthy status means that the disk's status was Healthy
77% of the selected display period.
| performance_status | value |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
For a more granular view of a disk's health, use a display period of a few hours or some number of minutes.
Understand each status
This section discusses what each status means and when you might need to take further action.
Healthy
The Healthy status indicates that from Google's perspective, the disk is
working normally.
If a Healthy disk has performance issues, don't contact support. Instead,
troubleshoot the disk using some of the following suggestions:
- Review disk performance metrics, such as latency and queue depth.
- Check your workload's logs and metrics for anomalies and bottlenecks.
- If you're using a Persistent Disk, make sure the provisioned capacity can meet the disk's performance needs. If you're using Hyperdisk or Extreme Persistent Disk volumes, verify you've provisioned enough IOPS and throughput.
- Ensure you have followed the guidelines to optimize the disk. For more information, see Optimize Hyperdisk and Optimize Persistent Disk.
Degraded
You usually do not need to contact support if your disk's status
is Degraded. A Degraded status is generally caused by normal internal
maintenance on the Compute Engine infrastructure.
You might not notice any impact to the disk's performance while its status is
Degraded. If the performance issue and the Degraded status
correlate in time, the performance issue might still be unrelated to the
Degraded status.
In the unlikely event that a performance issue is due to the Degraded status,
the impact is usually temporary. The disk's status should revert to Healthy within
a few minutes.
You can safely ignore the Degraded status if there are no performance issues
with the disk.
What to do if there is a performance problem
If your disk's performance status is Degraded, and you're observing a performance
issue, follow these steps:
- Check the PSH dashboard to see if there is an incident affecting the disk. If there is an incident, don't contact support as Google is aware and working to resolve the issue.
- If there are no known issues, wait at least 5 minutes for the performance issue to resolve on its own.
If after 5 minutes, the performance issue is unresolved and the status is still
Degraded, make sure that the performance issue isn't because the disk is insufficiently optimized. For example, check the disk's latency and queue depth. It's possible that the performance issue and theDegradedstatus are unrelated and only coincidental. To do so, review the disk's metrics and the performance optimization guidelines.If the performance issues continue and all the following conditions are met, you can contact support for assistance:
- The disk's status has been
Degradedfor more than 5 minutes - You are reasonably confident it's not a workload issue because you've optimized the disk and verified there are no other issues such as a bottleneck or an overloaded application
- There are no alerts in the PSH dashboard
- The disk's status has been
Google doesn't recommend creating an alert for the Degraded status
directly, but rather alerting on higher level application status and using
this metric to debug problems.
Severely Degraded
A disk whose performance status is Severely Degraded is experiencing a
performance issue. This issue can be due to an incident or error and might
already be visible in the PSH dashboard
or the Google Cloud service health dashboard.
What to do
If your disk's performance status is Severely Degraded, follow these steps:
- Check the PSH dashboard and the general Google Cloud health dashboard for an incident affecting the disk. If there is an incident, don't contact support as Google is aware and working to resolve the issue.
- If there are no known issues in both dashboards, contact support for assistance.
Decision tree
The following diagram illustrates how to proceed if a disk has a performance issue and summarizes the information in the preceding sections.

As shown in the flowchart, you should only contact support if there are no known
alerts in PSH and Cloud service dashboards and the disk status is
Severely Degraded. If the disk is Degraded, contact support only if all of the
following conditions have been met:
- The disk has been
Degradedfor more than 5 minutes - You have ruled out a workload error or misconfiguration (such as networking issues)
- No additional optimizations can be performed at the application, workload, or disk level
- You've reviewed all the disk's metrics
- You've examined your workload and virtual machine (VM) logs
What's next
- Learn more about creating charts with Metric Explorer and how to refine query results by adding filters to a chart.
- Check for active and past service health events in the Personal Service Health dashboard and the Google Service Health
- For performance optimization guidelines, see Optimize Hyperdisk and Optimize Persistent Disk.