Setelah mengembangkan agen, Anda dapat menggunakan layanan evaluasi AI Generatif untuk mengevaluasi kemampuan agen dalam menyelesaikan tugas dan sasaran untuk kasus penggunaan tertentu.
Menentukan metrik evaluasi
Mulai dengan daftar metrik kosong (yaitu metrics = []) dan tambahkan metrik yang relevan ke dalamnya. Untuk menyertakan metrik tambahan:
Respons akhir
Evaluasi respons akhir mengikuti proses yang sama dengan evaluasi berbasis model. Untuk mengetahui detailnya, lihat Menentukan metrik evaluasi.
Pencocokan persis
metrics.append("trajectory_exact_match")
Jika lintasan yang diprediksi identik dengan lintasan referensi, dengan panggilan alat yang sama persis dalam urutan yang sama persis, metrik trajectory_exact_match akan menampilkan skor 1, jika tidak 0.
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Pencocokan berurutan
metrics.append("trajectory_in_order_match")
Jika lintasan yang diprediksi berisi semua panggilan alat dari lintasan
referensi dalam urutan yang sama, dan mungkin juga memiliki panggilan alat tambahan, metrik
trajectory_in_order_match akan menampilkan skor 1, atau 0.
Parameter input:
predicted_trajectory: Trajektori yang diprediksi dan digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Trajektori prediksi yang diharapkan agar agen dapat memenuhi kueri.
Pencocokan dengan urutan apa pun
metrics.append("trajectory_any_order_match")
Jika lintasan yang diprediksi berisi semua panggilan alat dari lintasan referensi, tetapi urutannya tidak penting dan mungkin berisi panggilan alat tambahan, maka metrik trajectory_any_order_match akan menampilkan skor 1, atau 0.
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Presisi
metrics.append("trajectory_precision")
Metrik trajectory_precision mengukur berapa banyak panggilan alat dalam
trajektori yang diprediksi yang sebenarnya relevan atau benar menurut
trajektori referensi. Nilai ini adalah nilai float dalam rentang [0, 1]: makin tinggi skornya, makin akurat prediksi lintasannya.
Presisi dihitung sebagai berikut: Hitung berapa banyak tindakan dalam lintasan yang diprediksi juga muncul dalam lintasan referensi. Bagilah jumlah tersebut dengan jumlah total tindakan dalam lintasan yang diprediksi.
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Recall
metrics.append("trajectory_recall")
Metrik trajectory_recall mengukur berapa banyak panggilan alat penting
dari lintasan referensi yang benar-benar tercatat dalam lintasan
yang diprediksi. Nilai ini adalah nilai float dalam rentang [0, 1]: makin tinggi skornya, makin baik recall lintasan yang diprediksi.
Perolehan dihitung sebagai berikut: Hitung jumlah tindakan dalam lintasan rujukan yang juga muncul dalam lintasan yang diprediksi. Bagi jumlah tersebut dengan jumlah total tindakan dalam lintasan referensi.
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Penggunaan satu alat
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
Metrik trajectory_single_tool_use memeriksa apakah alat tertentu yang ditentukan dalam spesifikasi metrik digunakan dalam lintasan yang diprediksi. Tidak memeriksa urutan panggilan alat atau berapa kali alat digunakan, hanya apakah alat ada atau tidak. Nilainya adalah 0 jika alat tidak ada, 1 jika ada.
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.
Kustom
Anda dapat menentukan metrik kustom sebagai berikut:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
Dua metrik performa berikut selalu disertakan dalam hasil. Anda
tidak perlu menentukannya di EvalTask:
latency(float): Waktu yang diperlukan (dalam detik) oleh agen untuk merespons.failure(bool):0jika pemanggilan agen berhasil,1jika tidak.
Menyiapkan set data evaluasi
Untuk menyiapkan set data Anda untuk respons akhir atau evaluasi lintasan:
Respons akhir
Skema data untuk evaluasi respons akhir mirip dengan skema evaluasi respons model.
Pencocokan persis
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Pencocokan berurutan
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Trajektori yang diprediksi dan digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Trajektori prediksi yang diharapkan agar agen dapat memenuhi kueri.
Pencocokan dengan urutan apa pun
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Presisi
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Recall
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.reference_trajectory: Penggunaan alat yang diharapkan oleh agen untuk memenuhi kueri.
Penggunaan satu alat
Set data evaluasi harus memberikan input berikut:
Parameter input:
predicted_trajectory: Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir.
Untuk tujuan ilustrasi, berikut adalah contoh set data evaluasi.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Contoh set data
Kami telah menyediakan contoh set data berikut untuk menunjukkan cara Anda dapat mengevaluasi agen:
"on-device": Set data evaluasi untuk Asisten Rumah di Perangkat. Agen membantu kueri seperti "Jadwalkan AC di kamar tidur agar menyala antara pukul 23.00 dan 08.00, dan mati di waktu lainnya.""customer-support": Set data evaluasi untuk Agen Dukungan Pelanggan. Agen membantu menjawab pertanyaan seperti "Dapatkah Anda membatalkan pesanan yang tertunda dan mengeskalasikan tiket dukungan yang masih terbuka?""content-creation": Set data evaluasi untuk Agen Pembuatan Konten Pemasaran. Agen membantu menjawab kueri seperti "Jadwalkan ulang kampanye X menjadi kampanye satu kali di situs media sosial Y dengan anggaran yang dikurangi 50%, hanya pada 25 Desember 2024."
Untuk mengimpor contoh set data:
Instal dan lakukan inisialisasi CLI
gcloud.Download set data evaluasi.
Di Perangkat
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Dukungan Pelanggan
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Pembuatan Konten
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Memuat contoh set data
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Membuat hasil evaluasi
Untuk membuat hasil evaluasi, jalankan kode berikut:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
Melihat dan menafsirkan hasil
Hasil evaluasi ditampilkan sebagai berikut:
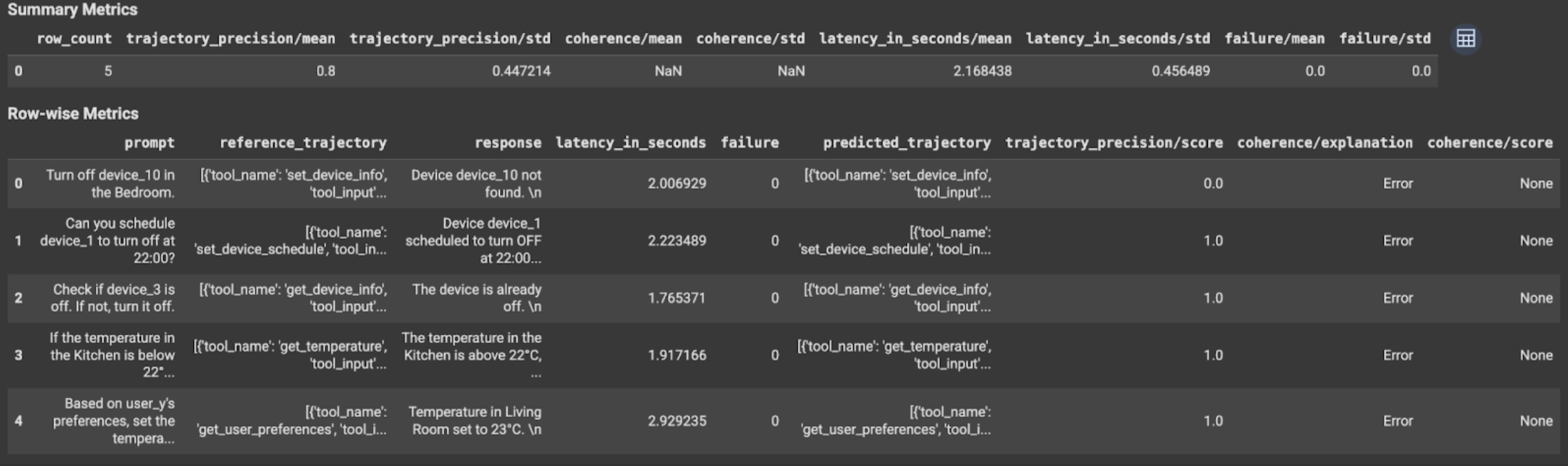
Hasil evaluasi berisi informasi berikut:
Metrik respons akhir
Metrik menurut baris:
response: Respons akhir yang dihasilkan oleh agen.latency_in_seconds: Waktu yang diperlukan (dalam detik) untuk membuat respons.failure: Menunjukkan apakah respons yang valid dihasilkan atau tidak.score: Skor yang dihitung untuk respons yang ditentukan dalam spesifikasi metrik.explanation: Penjelasan untuk skor yang ditentukan dalam spesifikasi metrik.
Metrik ringkasan:
mean: Skor rata-rata untuk semua instance.standard deviation: Standar deviasi untuk semua skor.
Metrik lintasan
Metrik menurut baris:
predicted_trajectory: Urutan panggilan alat yang diikuti oleh agen untuk mencapai respons akhir.reference_trajectory: Urutan panggilan alat yang diharapkan.score: Skor yang dihitung untuk lintasan yang diprediksi dan lintasan referensi yang ditentukan dalam spesifikasi metrik.latency_in_seconds: Waktu yang diperlukan (dalam detik) untuk membuat respons.failure: Menunjukkan apakah respons yang valid dihasilkan atau tidak.
Metrik ringkasan:
mean: Skor rata-rata untuk semua instance.standard deviation: Standar deviasi untuk semua skor.
Langkah berikutnya
Coba notebook berikut: