This page describes Web Grounding for Enterprise compliance controls and how to use the Web Grounding for Enterprise API to generate responses that are grounded on the web. The indexed content is a subset of what's available on Google Search and suitable for customers in highly-regulated industries, such as finance, healthcare, and the public sector.
If you don't require the additional compliance controls, use Ground with Google Search, because it offers access to a broader and even more up-to-date web index.
Overview
Web Grounding for Enterprise uses a web index that is used to generate grounded responses. The service doesn't log customer data and supports VPC service controls. For more information, see Security controls for generative AI. Because no customer data is persisted, customer-managed encryption keys (CMEK) and Access Transparency (AxT) aren't applicable.
Index freshness and curation
The web index of Web Grounding for Enterprise is automatically selected to meet the expected needs of customers in the healthcare, finance, and public sector verticals. While specific update schedules can vary, fast-changing content is updated every 6 hours, and the whole index is updated every 24 hours.
Choose a product
Choosing the right grounding tool depends on your organization's specific needs regarding compliance controls and the required freshness of information.
Grounding with Google Search: This is the recommended option for customers seeking the highest quality and freshness in their grounded responses. Freshness relates to how recent the web information is that is being used to generate the response. It is crucial for use cases where accessing the most up-to-date and comprehensive information from the web is critical. Grounding with Google Search stores reliability logs for up to 30 days as per the the Service Specific Terms. Google does not train on customer data processed by Grounding with Google Search.
Web Grounding for Enterprise: This solution is specifically designed for enterprise customers, who have stringent compliance requirements that include 'no logging of customer data'. Web Grounding for Enterprise is the preferred choice for organizations in highly-regulated industries that require the additional compliance controls. Web Grounding for Enterprise doesn't store customer data.
Supported models
This section lists the models that support Web Grounding for Enterprise.
- Gemini 2.5 Flash (Preview)
- Gemini 2.5 Flash-Lite (Preview)
- Gemini 2.5 Flash-Lite
- Gemini 2.5 Flash with Live API native audio (Preview)
- Gemini 2.0 Flash with Live API (Preview)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Use the API
This section provides sample requests of using the Generative AI API Gemini 2 on Vertex AI to create grounded responses with Gemini. To use the API, you must set the following fields:
Contents.parts.text: The text query users want to send to the API.tools.enterpriseWebSearch: When this tool is provided, Web Grounding for Enterprise can be used by Gemini.
Python
Install
pip install --upgrade google-genai
To learn more, see the SDK reference documentation.
Set environment variables to use the Gen AI SDK with Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Replace the following variables with values:- PROJECT_NUMBER: Your project number.
- LOCATION: The region to process the request. To use the
globalendpoint, exclude the location from the endpoint name, and configure the location of the resource toglobal. - PROMPT: Your prompt.
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" -H "x-server-timeout: 60" https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION/publishers/google/models/gemini-2.0-flash:generateContent -d '
{
"contents": [{
"role": "user",
"parts": [{
"text": PROMPT
}]
}],
"tools": [{
"enterpriseWebSearch": {
}
}]
}
'
Use Google Search suggestions
When you use Web Grounding for Enterprise, and you receive Search suggestions in your response, you must display the Search suggestions in production and in your applications.
Specifically, you must display the search queries that are included in the grounded response's metadata. The response includes:
"content": The LLM-generated response."webSearchQueries": The queries to be used for Search suggestions.
For example, in the following code snippet, Gemini responds to a Search grounded prompt, which asks about a type of tropical plant.
"predictions": [
{
"content": "Monstera is a type of vine that thrives in bright indirect light…",
"groundingMetadata": {
"webSearchQueries": ["What's a monstera?"],
}
}
]
You can take this output, and display it by using Search suggestions.
Requirements for Search suggestions
The following are requirements for suggestions:
| Requirement | Description |
|---|---|
| Do |
|
| Don't |
|
Display requirements
The following are the display requirements:
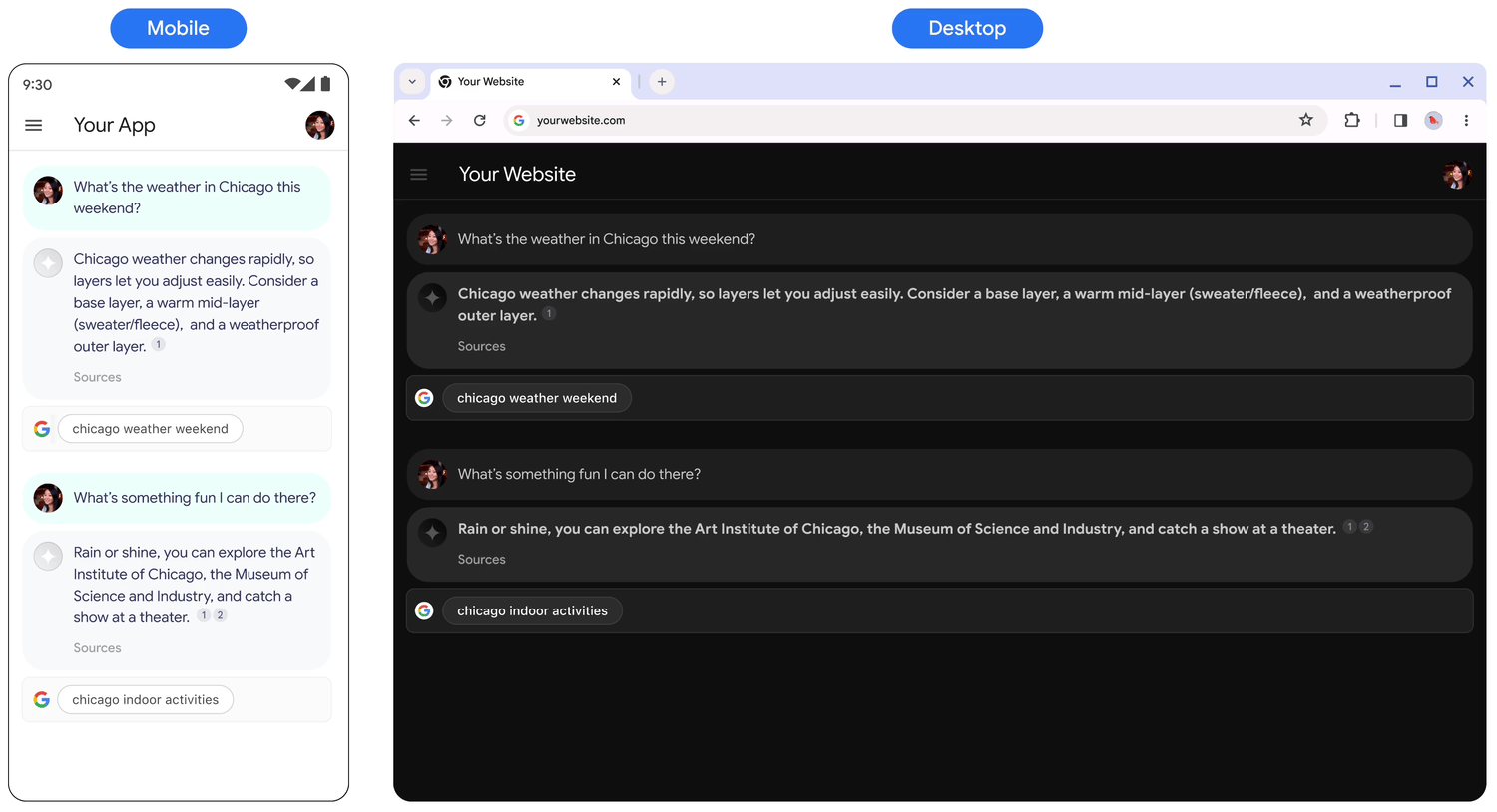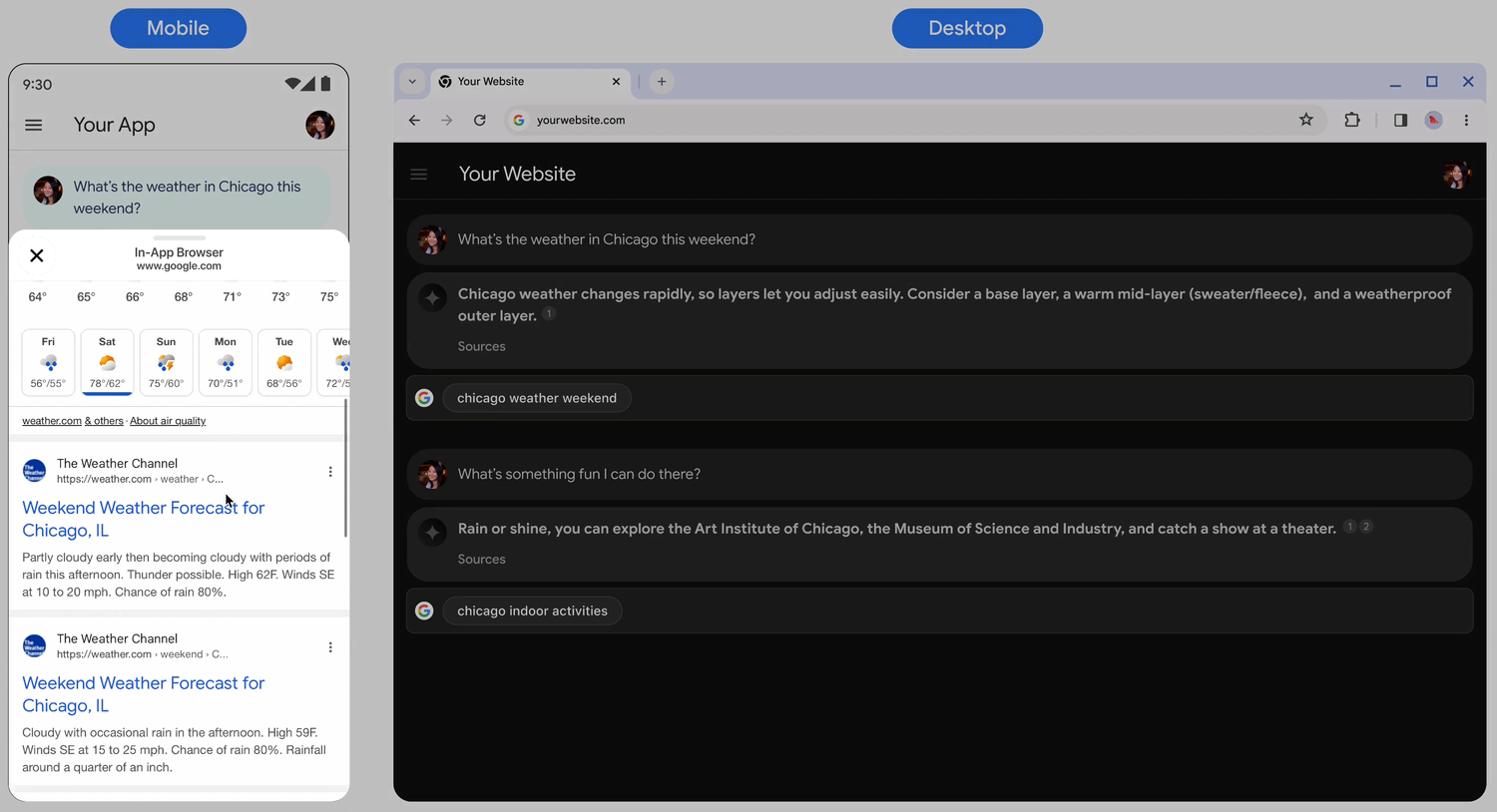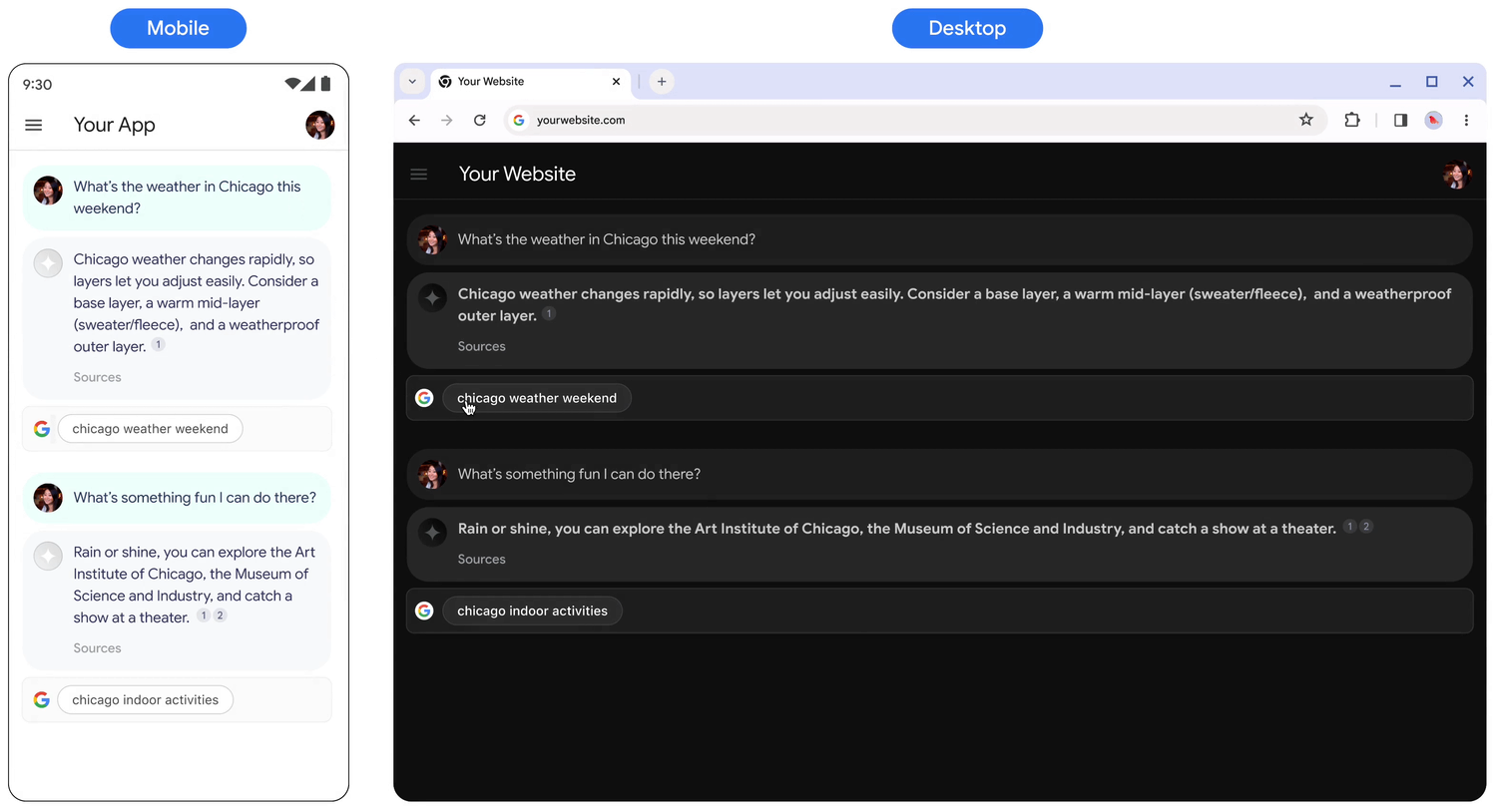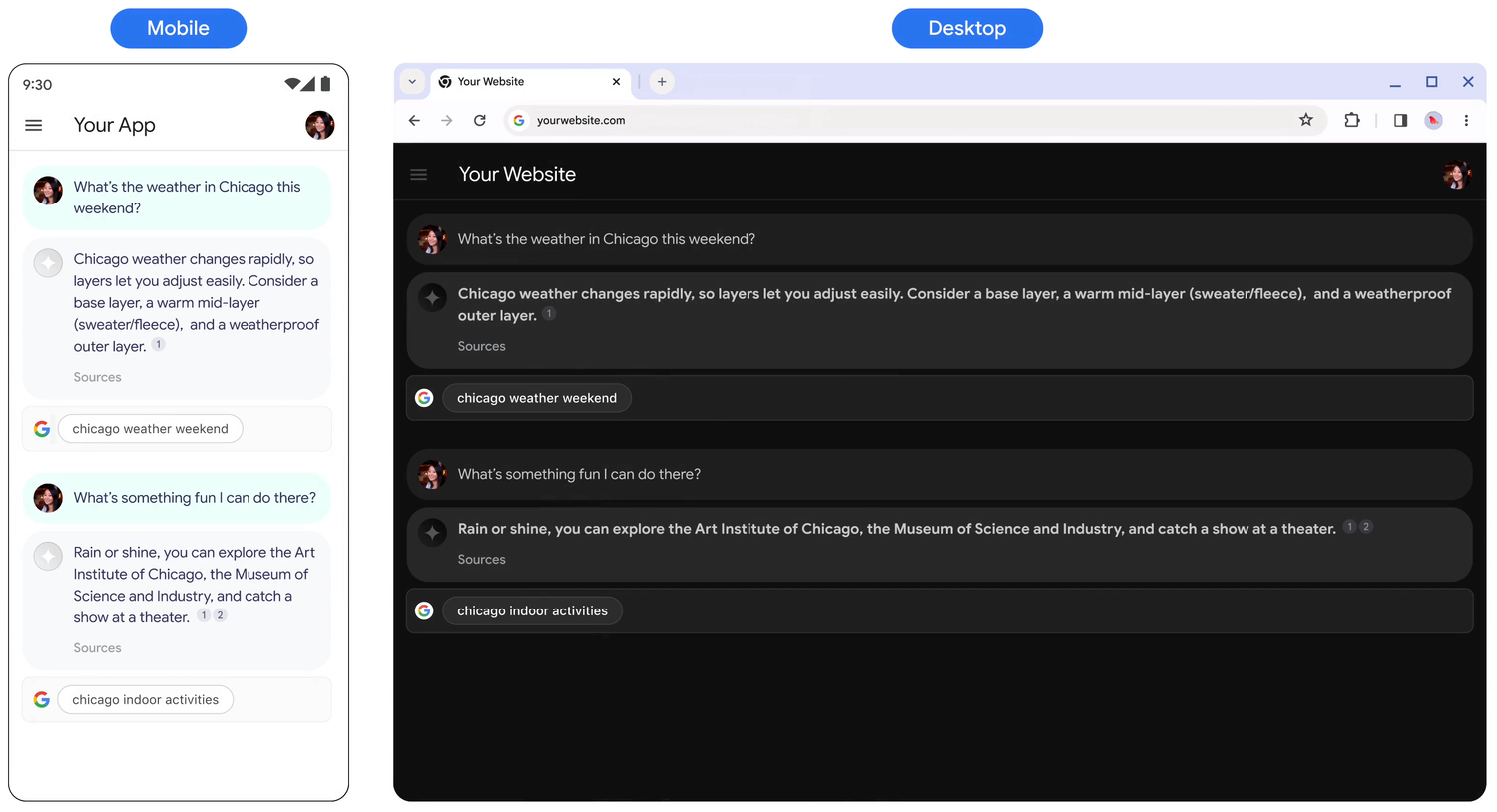
- Display the Search suggestion exactly as provided, and don't make any modifications to colors, fonts, or appearance. Ensure the Search suggestion renders as specified in the following mocks such as light and dark mode:
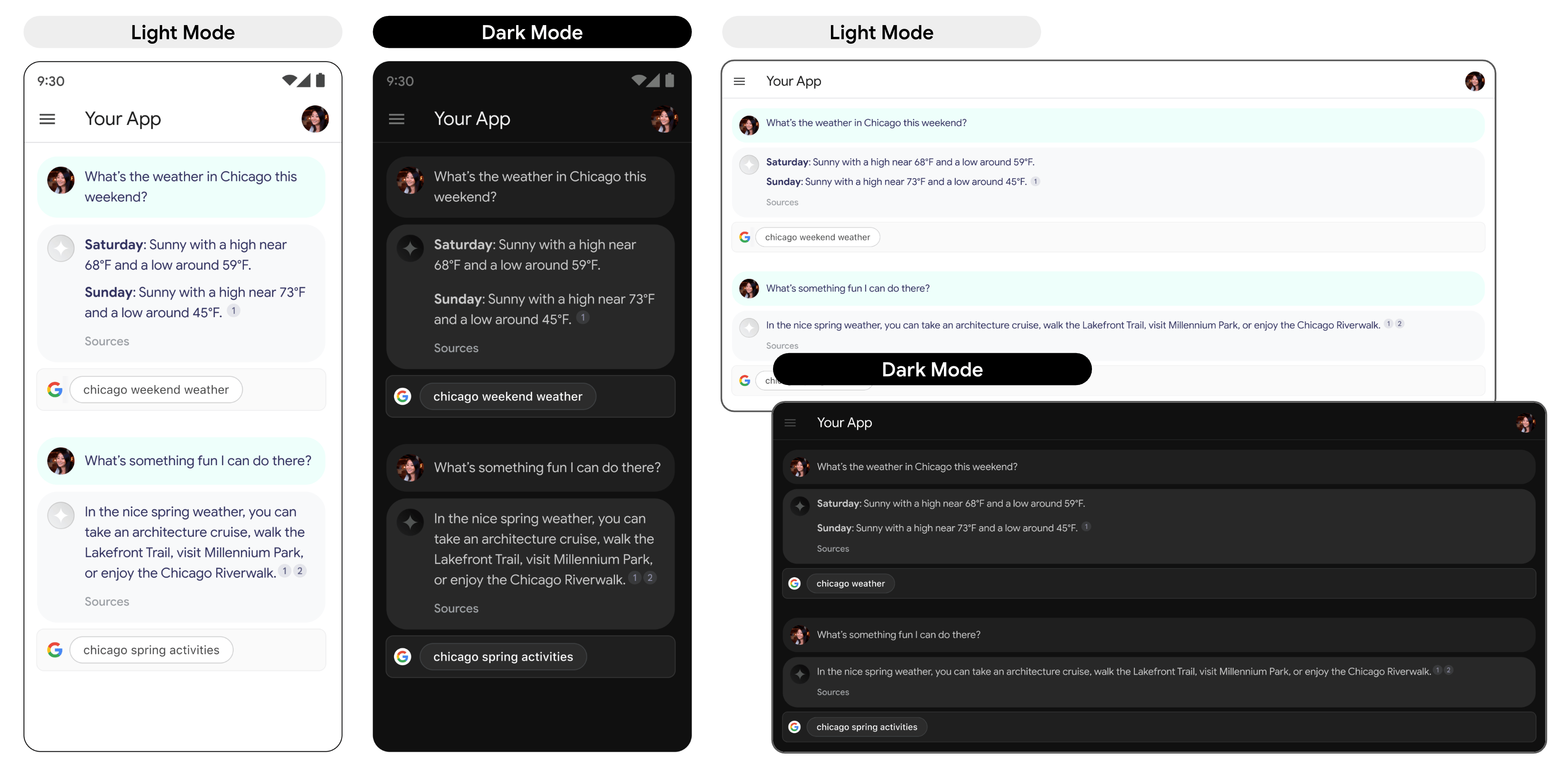
- Whenever a grounded response is shown, its corresponding Search suggestion should remain visible.
- For branding, you must strictly follow Google's guidelines for third-party use of Google brand features at the Welcome to our Brand Resource Center.
- When you use Web Grounding for Enterprise, Search suggestion chips display. The field that contains the suggestion chips must be the same width as the grounded response from the LLM.
Behavior on tap
When a user taps the chip, they are taken directly to a Search results page (SRP) for the search term displayed in the chip. The SRP can open either within your in-application browser or in a separate browser application. It's important to not minimize, remove, or obstruct the SRP's display in any way. The following animated mockup illustrates the tap-to-SRP interaction.
Code to implement a Search suggestion
When you use the API to ground a response to search, the model response provides
compliant HTML and CSS styling in the renderedContent field, which you
implement to display Search suggestions in your
application.
What's next
- To learn more about how to ground Gemini models to your data, see Grounding with Vertex AI Search.
- To learn more about responsible AI best practices and Vertex AI's safety filters, see Responsible AI.