The Gen AI evaluation service provides enterprise-grade tools for objective, data-driven assessment of generative AI models. It supports and informs a number of development tasks like model migrations, prompt editing, and fine-tuning.
Gen AI evaluation service features
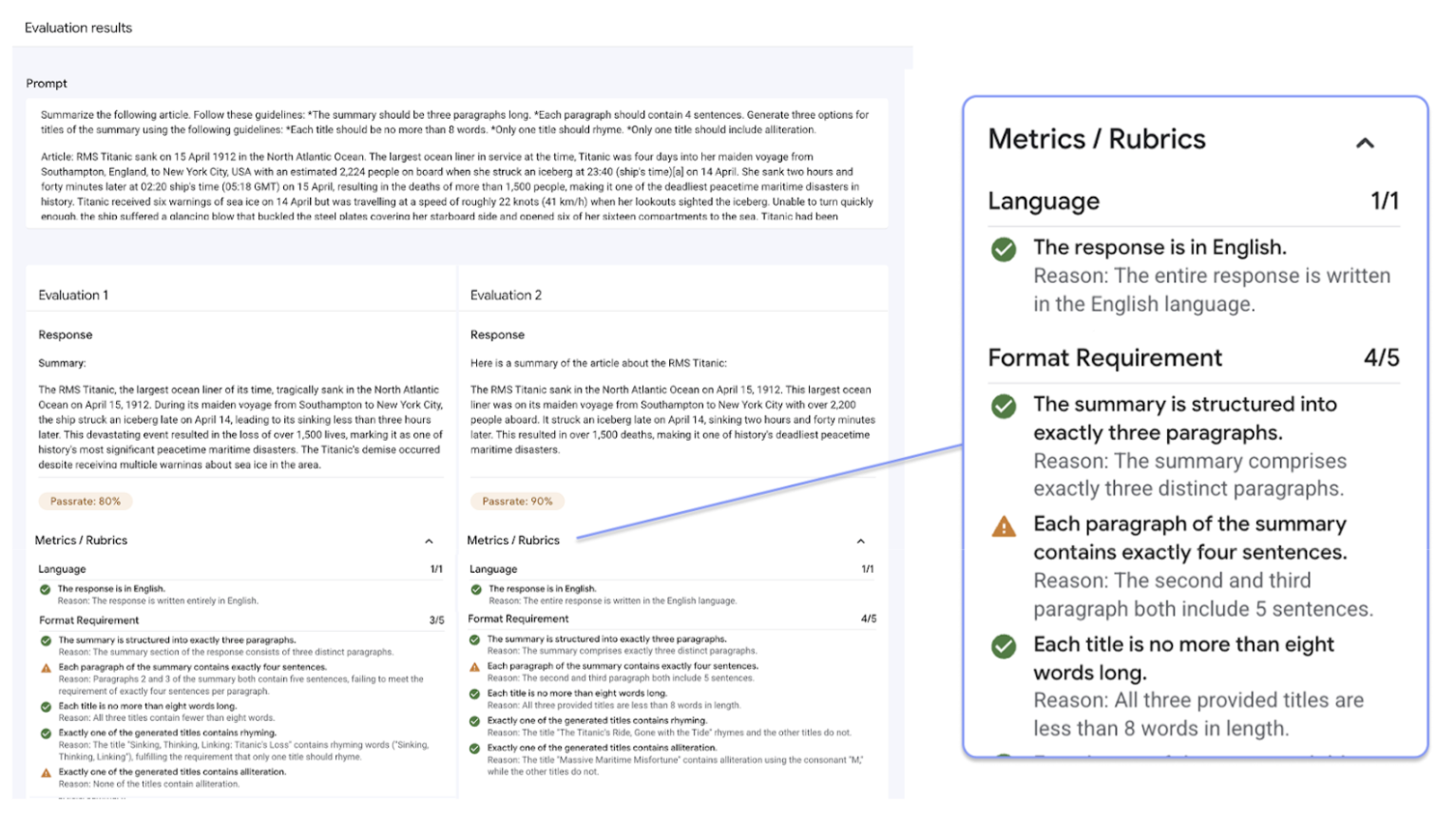
The defining feature of the Gen AI evaluation service is the ability to use adaptive rubrics, a set of tailored pass or fail tests for each individual prompt. Evaluation rubrics are similar to unit tests in software development and aim to improve model performance across a variety of tasks.
The Gen AI evaluation service supports the following common evaluation methods:
Adaptive rubrics (Recommended): Generates a unique set of pass or fail rubrics for each individual prompt in your dataset.
Static rubrics: Apply a fixed set of scoring criteria across all prompts.
Computation-based metrics: Use deterministic algorithms like
ROUGEorBLEUwhen a ground truth is available.Custom functions: Define your own evaluation logic in Python for specialized requirements.
Evaluation dataset generation
You can create an evaluation dataset through the following methods:
Upload a file containing complete prompt instances, or provide a prompt template alongside a corresponding file of variable values to populate the completed prompts.
Sample directly from production logs to evaluate the real-world usage of your model.
Use synthetic data generation to generate a large number of consistent examples for any prompt template.
Supported interfaces
You can define and run your evaluations using the following interfaces:
Google Cloud console: A web user interface that provides a guided, end-to-end workflow. Manage your datasets, run evaluations, and dive deep into interactive reports and visualizations. See Perform evaluation using the console.
Python SDK: Programmatically run evaluations and render side-by-side model comparisons directly in your Colab or Jupyter environment. See Perform evaluation using the GenAI Client in Vertex AI SDK
Use cases
The Gen AI evaluation service lets you see how a model performs on your specific tasks and against your unique criteria providing valuable insights which cannot be derived from public leaderboards and general benchmarks. This supports critical development tasks, including:
Model migrations: Compare model versions to understand behavioral differences and fine-tune your prompts and settings accordingly.
Finding the best model: Run head-to-head comparisons of Google and third-party models on your data to establish a performance baseline and identify the best fit for your use case.
Prompt improvement: Use evaluation results to guide your customization efforts. Re-running an evaluation creates a tight feedback loop, providing immediate, quantifiable feedback on your changes.
Model fine-tuning: Evaluate the quality of a fine-tuned model by applying consistent evaluation criteria to every run.
Evaluations with adaptive rubrics
Adaptive rubrics are the recommended method for most evaluation use cases and are typically the fastest way to get started with evaluations.
Instead of using a general set of rating rubrics like most LLM-as-a-judge systems, the test-driven evaluation framework adaptively generates a unique set of pass or fail rubrics for each individual prompt in your dataset. This approach ensures that every evaluation is relevant to the specific task being evaluated.
The evaluation process for each prompt uses a two-step system:
Rubric generation: The service first analyzes your prompt and generates a list of specific, verifiable tests—the rubrics—that a good response should meet.
Rubric validation: After your model generates a response, the service assesses the response against each rubric, delivering a clear
PassorFailverdict and a rationale.

The final result is an aggregated pass rate and a detailed breakdown of which rubrics the model passed, giving you actionable insights to diagnose issues and measure improvements.
By moving from high-level, subjective scores to granular, objective test results, you can adopt an evaluation-driven development cycle and bring the software engineering best practices to the process of building generative AI applications.
Rubrics evaluation example
To understand how the Gen AI evaluation service generates and uses rubrics, consider this example:
User prompt: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
For this prompt, the rubric generation step might produce the following rubrics:
Rubric 1: The response is a summary of the provided article.
Rubric 2: The response contains exactly four sentences.
Rubric 3: The response maintains an optimistic tone.
Your model may produce the following response: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
During rubric validation, the Gen AI evaluation service assesses the response against each rubric:
Rubric 1: The response is a summary of the provided article.
Verdict:
PassReason: The response accurately summarizes the main points.
Rubric 2: The response contains exactly four sentences.
Verdict:
PassReason: The response is composed of four distinct sentences
Rubric 3: The response maintains an optimistic tone.
Verdict:
FailReason: The final sentence introduces a negative point, which detracts from the optimistic tone.
The final pass rate for this response is 66.7%. To compare two models, you can evaluate their responses against this same set of generated tests and compare their overall pass rates.
Evaluation workflow
Completing an evaluation typically requires going through the following steps:
Create an evaluation dataset: Assemble a dataset of prompt instances that reflect your specific use case. You can include reference answers (ground truth) if you plan to use computation-based metrics.
Define evaluation metrics: Choose the metrics you want to use to measure model performance. The SDK supports all metric types, while the console supports adaptive rubrics.
Generate model responses: Select one or more models to generate responses for your dataset. The SDK supports any model callable via
LiteLLM, while the console supports Google Gemini models.Run the evaluation: Execute the evaluation job, which assesses each model's responses against your selected metrics.
Interpret the results: Review the aggregated scores and individual responses to analyze model performance.
Getting started with evaluations
You can get started with evaluations using the console.
Alternatively, the following code shows how to complete an evaluation with the GenAI Client in Vertex AI SDK:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
The Gen AI evaluation service offers two SDK interfaces:
GenAI Client in Vertex AI SDK (Recommended) (Preview)
from vertexai import clientThe GenAI Client is the newer, recommended interface for evaluation, accessed through the unified Client class. It supports all evaluation methods and is designed for workflows that include model comparison, in-notebook visualization, and insights for model customization.
Evaluation module in Vertex AI SDK (GA)
from vertexai.evaluation import EvalTaskThe evaluation module is the older interface, maintained for backward compatibility with existing workflows but no longer under active development. It is accessed through the
EvalTaskclass. This method supports standard LLM-as-a-judge and computation-based metrics but does not support newer evaluation methods like adaptive rubrics.
Supported regions
The following regions are supported for the Gen AI evaluation service:
Iowa (
us-central1)Northern Virginia (
us-east4)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Belgium (
europe-west1)Netherlands (
europe-west4)Paris, France (
europe-west9)
Available notebooks
| Notebook links | Description |
|---|---|
| Getting Started: Quick Gen AI Evaluation | Provides an introduction to the Gen AI evaluation service. |
| Evaluating third-party models with the Gen AI evaluation service | Demonstrates how to use the Vertex Gen AI Evaluation SDK to evaluate various types of third-party models, including models accessed using API (like OpenAI, Anthropic), Model as a Service (MaaS) from Vertex Model Garden, and Bring Your Own Model (BYOM) endpoints. |
| Model migration with the Gen AI evaluation service | Shows how to use the Vertex AI SDK for Gen AI evaluation service to compare two first-party models (such as Gemini 2.0 Flash to Gemini 2.5 Flash). It highlights using predefined adaptive rubric-based metrics and how evaluation results can guide prompt optimization. Key features like multi-candidate evaluation, in-notebook visualization, and asynchronous batch evaluation are also covered. |