This tutorial guides you through deploying the Meta-Llama-3.1-8B model on Vertex AI. You'll learn how to deploy endpoints and optimize for your specific needs. If you have fault-tolerant workloads, you can optimize for costs by using Spot VMs. If you want to ensure availability, use Compute Engine reservations. You'll learn how to deploy endpoints that utilize:
- Spot VMs: Use spot-provisioned instances for significant cost savings.
- Reservations: Guarantee resource availability for predictable performance, especially for production workloads. This tutorial demonstrates using an automatic (
ANY_RESERVATION) and specific (SPECIFIC_RESERVATION) reservations.
For more information, see Spot VMs or Reservations of Compute Engine resources.
Prerequisites
Before you begin, complete the following prerequisites:
- A Google Cloud project with billing enabled.
- The Vertex AI and Compute Engine APIs enabled.
- Sufficient quota for the machine type and accelerator that you intend to use, such as NVIDIA L4 GPUs. To check your quotas, see Quotas and system limits in the Google Cloud console.
- A Hugging Face account and a User Access Token with read access.
- If you are using shared reservations, grant IAM permissions between projects. Those permissions are all covered in the notebook.
Deploy on Spot VMs
The following sections guide you through the process of setting up your Google Cloud project, configuring Hugging Face authentication, deploying the Llama-3.1 model using Spot VMs or reservations, and testing the deployment.
1. Set up your Google Cloud project and shared reservation
Open the Colab Enterprise notebook.
In the first section, set the PROJECT_ID, SHARED_PROJECT_ID (if applicable), BUCKET_URI, and REGION variables in the Colab notebook.
The notebook grants to the compute.viewer role to the service account of both projects.
If you intend to use a reservation that was created in a different project within the same organization, make sure to grant the compute.viewer role to the P4SA (Principal Service Account) of both projects. The notebook code will automate this, but ensure that SHARED_PROJECT_ID is correctly set. This cross-project permission allows the Vertex AI endpoint in your primary project to see and use the reservation capacity in the shared project.
2. Set Up Hugging Face authentication
To download the Llama-3.1 model, you need to provide your Hugging Face User Access Token in the HF_TOKEN variable within the Colab notebook. If you don't provide one, you get the following error: Cannot access gated repository for URL.
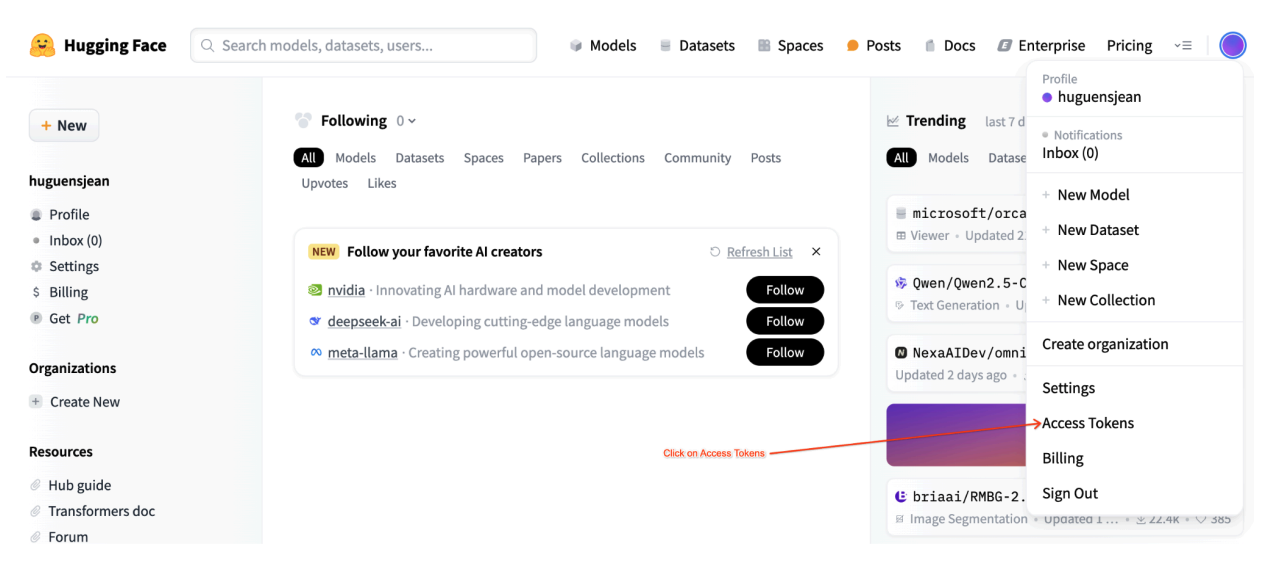 Figure 1: Hugging Face Access Token Settings
Figure 1: Hugging Face Access Token Settings
3. Deploy with Spot VM
To deploy the Llama model to a Spot VM, navigate to the "Spot VM Vertex AI Endpoint Deployment" section in the Colab notebook and set is_spot=True.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
Deploy on shared reservation instances
The following sections guide you through the process of creating a shared reservation, configuring the reservation settings, deploying the Llama-3.1 model using ANY_RESERVATION or SPECIFIC_RESERVATION, and testing the deployment.
1. Create a shared reservation
To configure your reservations, go to the "Set Up Reservations for Vertex AI Predictions" section of the notebook. Set the required variables for the reservation such as the RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE, and RES_ACCELERATOR_COUNT.
You are required to set RES_ZONE to be {REGION}-{availability_zone}
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. Share your reservations
There are two types of reservations: single-project reservations (the default) and shared reservations. Single-project reservations can only be used by VMs within the same project as the reservation itself. Shared reservations, on the other hand, can be used by VMs in the project where the reservation is located, as well as by VMs in any other project to which the reservation has been shared. Utilizing shared reservations can improve the utilization of your reserved resources and reduce the overall number of reservations you need to create and manage. This tutorial focuses on shared reservations. For more information, see How shared reservations work.
Before proceeding, make sure to "Share with other Google Services" from the Google Cloud console as shown in the figure:
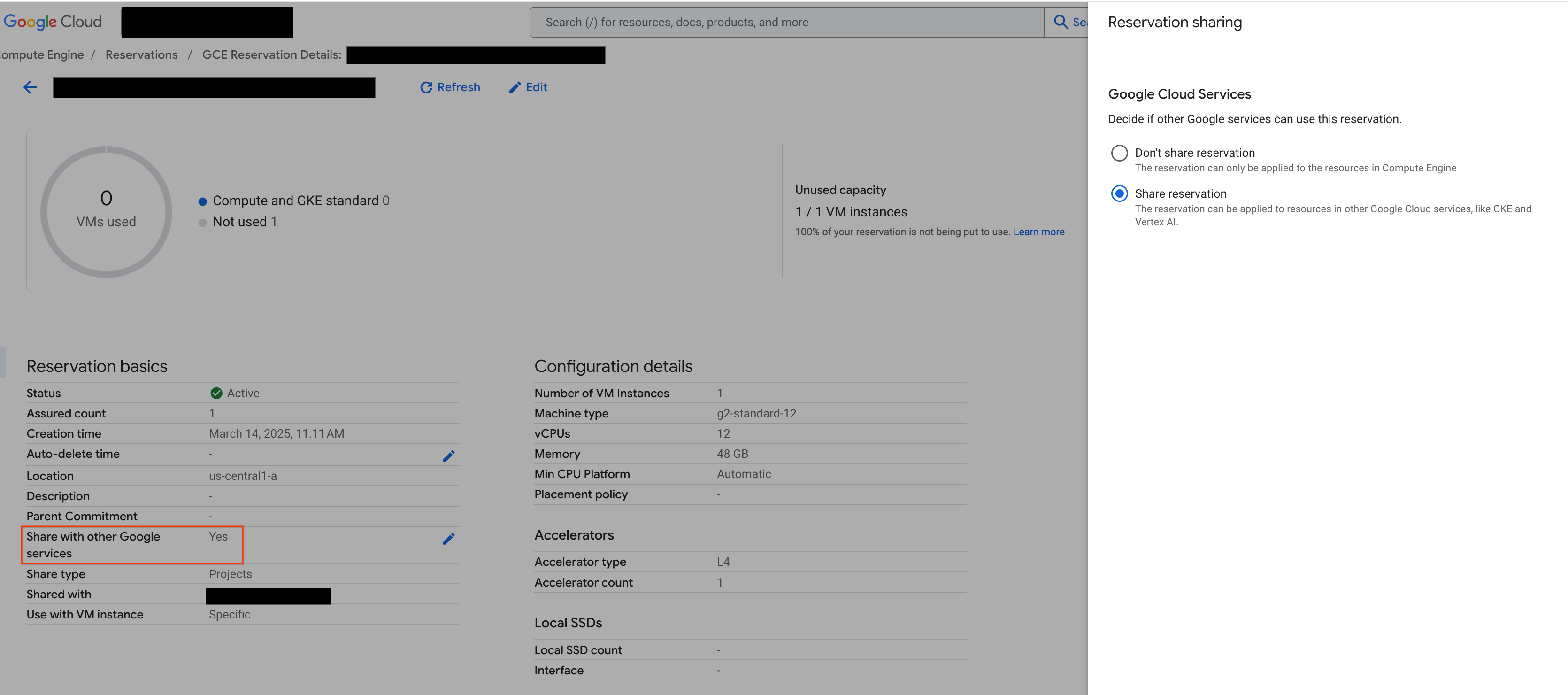 Figure 2: Share reservation with other Google services
Figure 2: Share reservation with other Google services
3. Deploy with ANY_RESERVATION
To deploy the endpoint using ANY_RESERVATION, go to the "Deploy Llama-3.1 Endpoint with ANY_RESERVATION" section of the notebook. Specify your deployment settings and then set reservation_affinity_type="ANY_RESERVATION". Then, run the cell to deploy the endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. Test ANY_RESERVATION endpoint
With your endpoint deployed, make sure to test a few prompts to ensure it is deployed properly.
5. Deploy with SPECIFIC_RESERVATION
To deploy the endpoint using SPECIFIC_RESERVATION, go to the "Deploy Llama-3.1 Endpoint with SPECIFIC_RESERVATION" section of the notebook. Specify the following parameters: reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project, and reservation_zone. Then, run the cell to deploy the endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. Test SPECIFIC_RESERVATION endpoint
With your endpoint deployed, verify that the reservation is used by Vertex AI online prediction, and make sure to test a few prompts to ensure it is deployed properly.
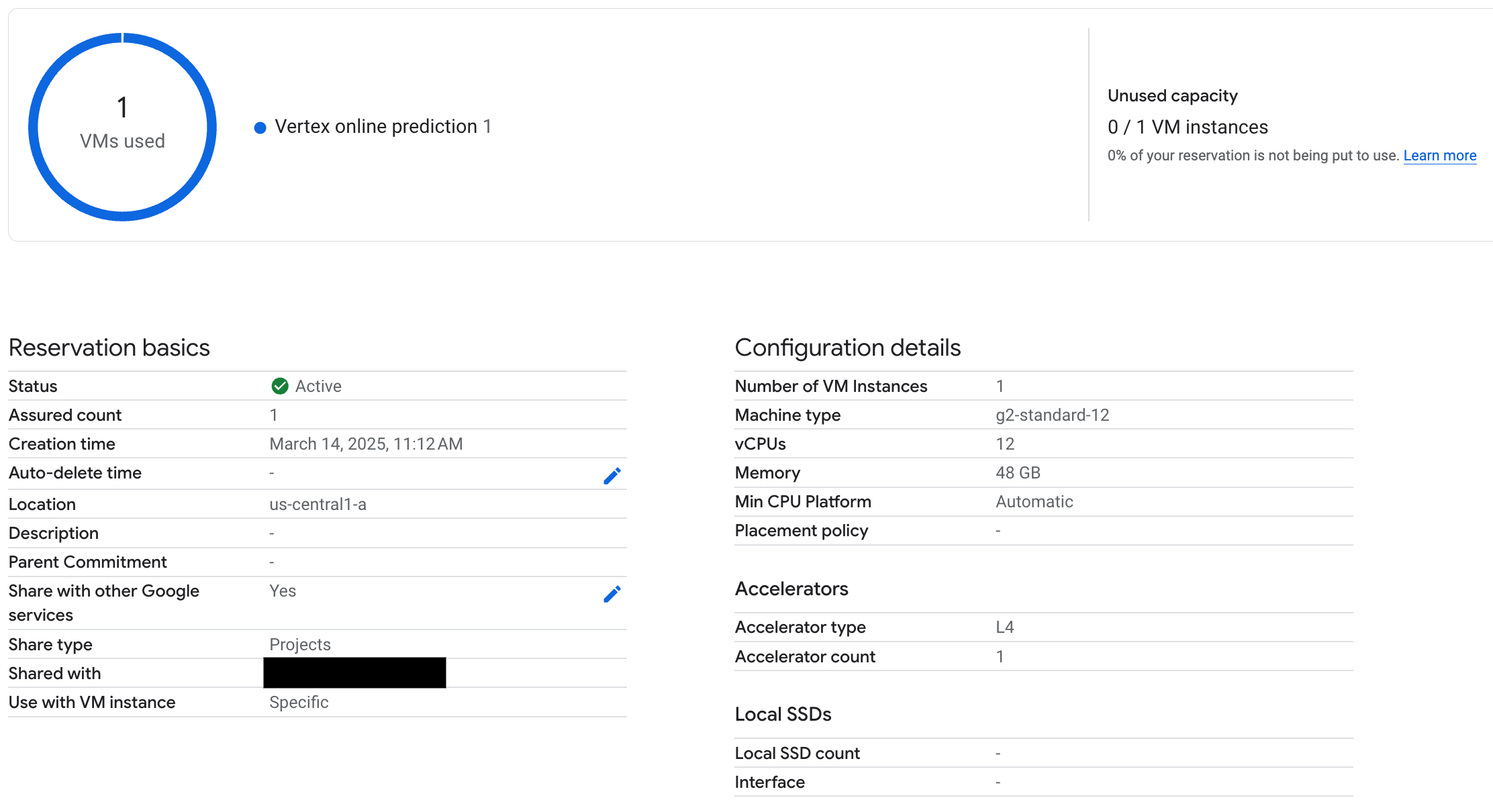 Figure 3: Check reservation is used by Vertex online prediction
Figure 3: Check reservation is used by Vertex online prediction
7. Clean up
To avoid ongoing charges, delete the models, endpoints, and reservations created during this tutorial. The Colab notebook provides code in the "Clean Up" section to automate this cleanup process.
Troubleshooting
- Hugging Face Token Errors: Double-check that your Hugging Face token has
readpermissions and is correctly set in the notebook. - Quota Errors: Verify that you have sufficient GPU quota in the region you are deploying to. Request a quota increase if needed.
- Reservation Conflicts: Ensure that the machine type and accelerator configuration of your endpoint deployment match the settings of your reservation. Ensure that the reservations are enabled to be shared with Google Services
Next steps
- Explore different Llama 3 model variants.
- Learn more about reservations with this Compute Engine Reservations Overview.
- Learn more about Spot VMs with this Spot VMs Overview.