Dopo aver creato e valutato il modello di AI generativa, puoi utilizzarlo per creare un agente come un chatbot. Il servizio di valutazione dell'AI generativa ti consente di misurare la capacità del tuo agente di completare attività e obiettivi per il tuo caso d'uso.
Panoramica
Per valutare il tuo agente, hai a disposizione le seguenti opzioni:
Valutazione della risposta finale: valuta l'output finale di un agente (indipendentemente dal fatto che l'agente abbia raggiunto il suo obiettivo).
Valutazione della traiettoria: valuta il percorso (sequenza di chiamate di strumenti) seguito dall'agente per raggiungere la risposta finale.
Con Gen AI evaluation service, puoi attivare l'esecuzione di un agente e ottenere metriche sia per la valutazione della traiettoria sia per la valutazione della risposta finale in una query dell'SDK Vertex AI.
Agenti supportati
Gen AI evaluation service supporta le seguenti categorie di agenti:
| Agenti supportati | Descrizione |
|---|---|
| Agente creato con il modello di Agent Engine | Agent Engine (LangChain su Vertex AI) è una Google Cloud piattaforma in cui puoi eseguire il deployment e gestire gli agenti. |
| Agenti LangChain creati utilizzando il modello personalizzabile di Agent Engine | LangChain è una piattaforma open source. |
| Funzione agente personalizzata | La funzione dell'agente personalizzato è una funzione flessibile che accetta un prompt per l'agente e restituisce una risposta e una traiettoria in un dizionario. |
Definizione delle metriche per la valutazione degli agenti
Definisci le metriche per la valutazione della risposta finale o della traiettoria:
Valutazione della risposta finale
La valutazione della risposta finale segue la stessa procedura della valutazione della risposta del modello. Per ulteriori informazioni, consulta Definisci le metriche di valutazione.
Valutazione della traiettoria
Le seguenti metriche ti aiutano a valutare la capacità del modello di seguire la traiettoria prevista:
Corrispondenza esatta
Se la traiettoria prevista è identica a quella di riferimento, con le stesse chiamate di strumenti nello stesso ordine, la metrica trajectory_exact_match restituisce un punteggio di 1, altrimenti 0.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale. |
reference_trajectory |
L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| 0 | La traiettoria prevista non corrisponde a quella di riferimento. |
| 1 | La traiettoria prevista corrisponde a quella di riferimento. |
Corrispondenza in ordine
Se la traiettoria prevista contiene tutte le chiamate di strumenti della traiettoria di riferimento nello stesso ordine e potrebbe contenere anche chiamate di strumenti aggiuntive, la metrica trajectory_in_order_match restituisce un punteggio di 1, altrimenti 0.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
La traiettoria prevista utilizzata dall'agente per raggiungere la risposta finale. |
reference_trajectory |
La traiettoria prevista per l'agente per soddisfare la query. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| 0 | Le chiamate dello strumento nella traiettoria prevista non corrispondono all'ordine nella traiettoria di riferimento. |
| 1 | La traiettoria prevista corrisponde a quella di riferimento. |
Corrispondenza in qualsiasi ordine
Se la traiettoria prevista contiene tutte le chiamate di strumenti della traiettoria di riferimento, ma l'ordine non è importante e può contenere chiamate di strumenti aggiuntive, la metrica trajectory_any_order_match restituisce un punteggio di 1, altrimenti 0.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale. |
reference_trajectory |
L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| 0 | La traiettoria prevista non contiene tutte le chiamate di strumenti nella traiettoria di riferimento. |
| 1 | La traiettoria prevista corrisponde a quella di riferimento. |
Precisione
La metrica trajectory_precision misura quante chiamate allo strumento nella traiettoria prevista sono effettivamente pertinenti o corrette in base alla traiettoria di riferimento.
La precisione viene calcolata nel seguente modo: conta quante azioni nella traiettoria prevista compaiono anche nella traiettoria di riferimento. Dividi questo conteggio per il numero totale di azioni nella traiettoria prevista.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale. |
reference_trajectory |
L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| Un valore float compreso nell'intervallo [0,1] | Più alto è il punteggio, più precisa è la traiettoria prevista. |
Richiamo
La metrica trajectory_recall misura quante delle chiamate agli strumenti essenziali della traiettoria di riferimento vengono effettivamente acquisite nella traiettoria prevista.
Il richiamo viene calcolato nel seguente modo: conta quante azioni nella traiettoria di riferimento compaiono anche nella traiettoria prevista. Dividi questo conteggio per il numero totale di azioni nella traiettoria di riferimento.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale. |
reference_trajectory |
L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| Un valore float compreso nell'intervallo [0,1] | Più alto è il punteggio, migliore è il richiamo della traiettoria prevista. |
Utilizzo di un singolo strumento
La metrica trajectory_single_tool_use verifica se uno strumento specifico specificato nella specifica della metrica viene utilizzato nella traiettoria prevista. Non controlla l'ordine delle chiamate di strumenti o il numero di volte in cui lo strumento viene utilizzato, ma solo se è presente o meno.
Parametri di input della metrica
| Parametro di input | Descrizione |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale. |
Punteggi di output
| Valore | Descrizione |
|---|---|
| 0 | Lo strumento è assente |
| 1 | Lo strumento è presente. |
Inoltre, per impostazione predefinita, ai risultati della valutazione vengono aggiunte le seguenti due metriche sul rendimento dell'agente. Non è necessario specificarli in EvalTask.
latency
Tempo impiegato dall'agente per restituire una risposta.
| Valore | Descrizione |
|---|---|
| Un galleggiante | Calcolato in secondi. |
failure
Un valore booleano per descrivere se l'invocazione dell'agente ha generato un errore o è andata a buon fine.
Punteggi di output
| Valore | Descrizione |
|---|---|
| 1 | Errore |
| 0 | Risposta valida restituita |
Preparare il set di dati per la valutazione dell'agente
Prepara il set di dati per la valutazione della risposta finale o della traiettoria.
Lo schema dei dati per la valutazione della risposta finale è simile a quello della valutazione della risposta del modello.
Per la valutazione della traiettoria basata sul calcolo, il tuo set di dati deve fornire le seguenti informazioni:
| Tipo di input | Contenuti del campo di input |
|---|---|
predicted_trajectory |
L'elenco delle chiamate di strumenti utilizzate dagli agenti per raggiungere la risposta finale. |
reference_trajectory (non richiesto per trajectory_single_tool_use metric) |
L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query. |
Esempi di set di dati di valutazione
I seguenti esempi mostrano set di dati per la valutazione della traiettoria. Tieni presente che reference_trajectory è obbligatorio per tutte le metriche, ad eccezione di trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Importa il set di dati di valutazione
Puoi importare il set di dati nei seguenti formati:
File JSONL o CSV archiviato in Cloud Storage
Tabella BigQuery
DataFrame Pandas
Il servizio di valutazione dell'AI generativa fornisce set di dati pubblici di esempio per mostrare come valutare gli agenti. Il seguente codice mostra come importare i set di dati pubblici da un bucket Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
dove dataset è uno dei seguenti set di dati pubblici:
"on-device"per un assistente per la casa sul dispositivo, che controlla i dispositivi per la casa. L'agente ti aiuta con query come "Programma il condizionatore d'aria della camera da letto in modo che sia acceso tra le 23:00 e le 8:00 e spento il resto del tempo"."customer-support"per un addetto all'assistenza clienti. L'agente aiuta con domande come "Puoi annullare gli ordini in attesa e riassegnare i ticket di assistenza aperti?""content-creation"per un agente di creazione di contenuti di marketing. L'agente aiuta con query come "Ripianifica la campagna X in modo che diventi una campagna una tantum sul sito di social media Y con un budget ridotto del 50%, solo il 25 dicembre 2024".
Esegui la valutazione dell'agente
Esegui una valutazione per la traiettoria o la valutazione della risposta finale:
Per la valutazione dell'agente, puoi combinare le metriche di valutazione della risposta e le metriche di valutazione della traiettoria come nel seguente codice:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Personalizzazione delle metriche
Puoi personalizzare una metrica basata su un modello linguistico di grandi dimensioni per la valutazione della traiettoria utilizzando un'interfaccia basata su modelli o da zero. Per ulteriori dettagli, consulta la sezione sulle metriche basate su modelli. Ecco un esempio di modello:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Puoi anche definire una metrica personalizzata basata sul calcolo per la valutazione della traiettoria o della risposta nel seguente modo:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Visualizzare e interpretare i risultati
Per la valutazione della traiettoria o della risposta finale, i risultati della valutazione vengono visualizzati nel seguente modo:
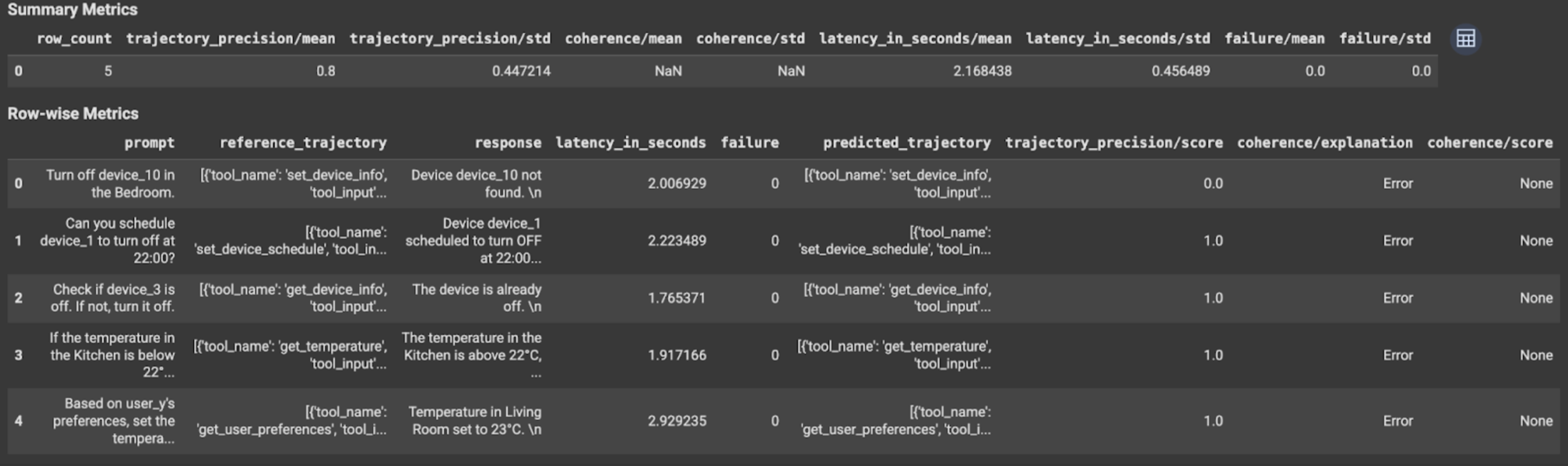
I risultati della valutazione contengono le seguenti informazioni:
Metriche della risposta finale
Risultati a livello di istanza
| Colonna | Descrizione |
|---|---|
| risposta | Risposta finale generata dall'agente. |
| latency_in_seconds | Tempo impiegato per generare la risposta. |
| operazione non riuscita | Indica se è stata generata o meno una risposta valida. |
| punteggio | Un punteggio calcolato per la risposta specificata nella specifica della metrica. |
| spiegazione | La spiegazione del punteggio specificato nella specifica della metrica. |
Risultati aggregati
| Colonna | Descrizione |
|---|---|
| medio | Punteggio medio per tutte le istanze. |
| deviazione standard | Deviazione standard per tutti i punteggi. |
Metriche della traiettoria
Risultati a livello di istanza
| Colonna | Descrizione |
|---|---|
| predicted_trajectory | Sequenza di chiamate di strumenti seguite dall'agente per raggiungere la risposta finale. |
| reference_trajectory | Sequenza di chiamate agli strumenti previste. |
| punteggio | Un punteggio calcolato per la traiettoria prevista e la traiettoria di riferimento specificate nella specifica della metrica. |
| latency_in_seconds | Tempo impiegato per generare la risposta. |
| operazione non riuscita | Indica se è stata generata o meno una risposta valida. |
Risultati aggregati
| Colonna | Descrizione |
|---|---|
| medio | Punteggio medio per tutte le istanze. |
| deviazione standard | Deviazione standard per tutti i punteggi. |
Protocollo Agent2Agent (A2A)
Se stai creando un sistema multi-agente, ti consigliamo vivamente di esaminare il protocollo A2A. Il protocollo A2A è uno standard aperto che consente una comunicazione e una collaborazione fluide tra gli agenti AI, indipendentemente dai framework sottostanti. È stato donato da Google Cloud alla Linux Foundation nel giugno 2025. Per utilizzare gli SDK A2A o provare gli esempi, consulta il repository GitHub.
Passaggi successivi
Prova i seguenti blocchi note di valutazione degli agenti: