Puoi utilizzare Imagen su Vertex AI per generare nuove immagini da un prompt di testo. Le interfacce supportate includono la console Google Cloud e l'API Vertex AI.
Per ulteriori informazioni sulla scrittura di prompt di testo per la generazione e la modifica di immagini, consulta la guida per i prompt.
Visualizza la scheda del modello Imagen per la generazione
Prova la generazione di immagini (Vertex AI Studio)
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Configura l'autenticazione per il tuo ambiente.
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
Python
Per utilizzare gli esempi di Python questa pagina in un ambiente di sviluppo locale, installa e inizializza gcloud CLI, quindi configura le credenziali predefinite dell'applicazione con le tue credenziali utente.
Installa Google Cloud CLI.
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Per saperne di più, consulta Configurare ADC per un ambiente di sviluppo locale nella documentazione sull'autenticazione Google Cloud .
REST
Per utilizzare gli esempi di API REST in questa pagina in un ambiente di sviluppo locale, utilizza le credenziali che fornisci a gcloud CLI.
Installa Google Cloud CLI.
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
Per saperne di più, consulta Autenticarsi per l'utilizzo di REST nella documentazione sull'autenticazione di Google Cloud .
Generare immagini con testo
Puoi generare nuove immagini utilizzando solo testo descrittivo come input. Gli esempi seguenti mostrano le istruzioni di base per generare immagini.
Console
Nella console Google Cloud , vai alla pagina Vertex AI > Media Studio.
Fai clic su Immagine. Viene visualizzata la pagina di generazione di immagini di Imagen Media Studio.
(Facoltativo) Nel riquadro Impostazioni, configura le seguenti impostazioni:
Modello: scegli un modello tra le opzioni disponibili.
Per saperne di più sui modelli disponibili, consulta Modelli Imagen.
Proporzioni: scegli un formato tra le opzioni disponibili.
Numero di risultati: regola il cursore o inserisci un valore compreso tra 1 e 4.
Risoluzione di output: scegli una risoluzione tra le opzioni disponibili.
(Facoltativo) Nella sezione Opzioni avanzate, seleziona una Regione in cui generare le immagini.
Nella casella Scrivi il prompt, inserisci il prompt di testo che descrive le immagini da generare. Ad esempio, piccola barca sull'acqua al mattino illustrazione ad acquerello.
Per saperne di più su come scrivere prompt efficaci, consulta la guida ai prompt e agli attributi delle immagini.
Fai clic su Genera.
Una filigrana digitale viene aggiunta automaticamente alle immagini generate. Non puoi disattivare la filigrana digitale per la generazione di immagini utilizzando la console Google Cloud .
Puoi selezionare un'immagine da visualizzare nella finestra Dettagli immagine. Le immagini con filigrana contengono un badge Filigrana digitale. Puoi anche verificare esplicitamente una filigrana immagine.
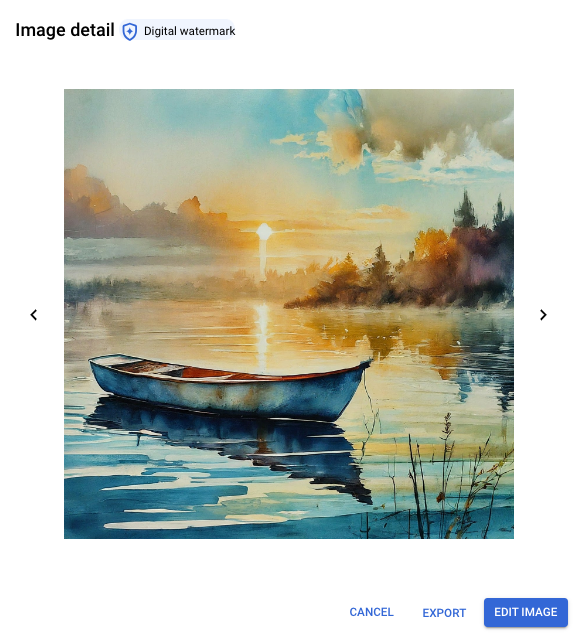
Visualizzazione dei dettagli dell'immagine di un'immagine con filigrana generata con Imagen 2 dal prompt: piccola barca rossa sull'acqua al mattino, illustrazione ad acquerello con colori tenui.
Python
Installa
pip install --upgrade google-genai
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
In questo esempio, chiami il metodo
generate_imagessuImageGenerationModele salvi le immagini generate localmente. Puoi quindi utilizzare facoltativamente il metodoshow()in un blocco note per visualizzare le immagini generate. Per ulteriori informazioni sulle versioni e sulle funzionalità dei modelli, consulta Modelli Imagen.REST
Per saperne di più sulle richieste del modello
imagegeneration, consulta il riferimento API del modelloimagegeneration.Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: il tuo Google Cloud ID progetto.
-
MODEL_VERSION: la versione del modello Imagen da utilizzare. Per saperne di più sui modelli disponibili, consulta Modelli Imagen.
- LOCATION: la regione del progetto. Ad esempio,
us-central1,europe-west2oasia-northeast3. Per un elenco delle regioni disponibili, consulta Località dell'AI generativa su Vertex AI. - TEXT_PROMPT: il prompt di testo che guida le immagini che il modello genera. Questo campo è obbligatorio sia per la generazione che per la modifica.
- IMAGE_COUNT: il numero di immagini generate.
Valori interi accettati: 1-8 (
imagegeneration@002), 1-4 (tutte le altre versioni del modello). Il valore predefinito è 4. - ADD_WATERMARK: booleano. Facoltativo. Se attivare una filigrana per le immagini generate.
Qualsiasi immagine generata quando il campo è impostato su
truecontiene una filigrana digitale SynthID che puoi utilizzare per verificare un'immagine con filigrana. Se ometti questo campo, viene utilizzato il valore predefinitotrue; devi impostare il valore sufalseper disattivare questa funzionalità. Puoi utilizzare il camposeedper ottenere un output deterministico solo quando questo campo è impostato sufalse. - ASPECT_RATIO: stringa. Facoltativo. Un parametro della modalità di generazione che controlla le proporzioni. Valori del rapporto supportati e loro utilizzo previsto:
1:1(valore predefinito, quadrato)3:4(annunci, social media)4:3(TV, fotografia)16:9(orizzontale)9:16(verticale)
- ENABLE_PROMPT_REWRITING: booleano. Facoltativo. Un parametro per utilizzare una funzionalità di riscrittura del prompt basata su LLM per fornire immagini di qualità superiore che riflettano meglio l'intent del prompt originale. La disabilitazione di questa funzionalità potrebbe influire sulla qualità delle immagini e
sull'aderenza del prompt. Valore predefinito:
true. -
INCLUDE_RAI_REASON: booleano. Facoltativo. Se attivare il codice del motivo del filtro dell'AI responsabile nelle risposte con input o output bloccati. Valore predefinito:
true. - INCLUDE_SAFETY_ATTRIBUTES: booleano. Facoltativo. Indica se attivare i punteggi di AI responsabile arrotondati per un elenco di attributi di sicurezza nelle risposte per input e output non filtrati. Categorie di attributi di sicurezza:
"Death, Harm & Tragedy","Firearms & Weapons","Hate","Health","Illicit Drugs","Politics","Porn","Religion & Belief","Toxic","Violence","Vulgarity","War & Conflict". Valore predefinito:false. - MIME_TYPE: stringa. Facoltativo. Il tipo MIME del contenuto dell'immagine. Valori
disponibili:
image/jpegimage/gifimage/pngimage/webpimage/bmpimage/tiffimage/vnd.microsoft.icon
- COMPRESSION_QUALITY: numero intero. Facoltativo. Si applica solo ai file di output JPEG. Il livello di dettaglio che il modello conserva per le immagini generate in formato file JPEG. Valori:
Da
0a100, dove un numero più alto indica una maggiore compressione. Predefinito:75. - PERSON_SETTING: stringa. Facoltativo. L'impostazione di sicurezza che controlla il tipo di
persone o volti che il modello può generare. Valori disponibili:
allow_adult(impostazione predefinita): consente la generazione di immagini solo per adulti, ad eccezione di quelle di celebrità. La generazione di celebrità non è consentita per nessuna impostazione.dont_allow: disattiva l'inclusione di persone o volti nelle immagini generate.
- SAFETY_SETTING: stringa. Facoltativo. Un'impostazione che controlla le soglie del filtro di sicurezza
per le immagini generate. Valori disponibili:
block_low_and_above: la soglia di sicurezza più elevata, che comporta il maggior numero di immagini generate filtrate. Valore precedente:block_most.block_medium_and_above(impostazione predefinita): una soglia di sicurezza media che bilancia il filtraggio di contenuti potenzialmente dannosi e sicuri. Valore precedente:block_some.block_only_high: una soglia di sicurezza che riduce il numero di richieste bloccate a causa dei filtri di sicurezza. Questa impostazione potrebbe aumentare i contenuti discutibili generati da Imagen. Valore precedente:block_few.
- SEED_NUMBER: numero intero. Facoltativo. Qualsiasi numero intero non negativo fornito per rendere deterministiche le immagini di output. Fornire lo stesso numero di seed genera sempre le stesse immagini di output. Se
il modello che utilizzi supporta la filigrana digitale, devi impostare
"addWatermark": falseper utilizzare questo campo. Valori interi accettati:1-2147483647. - OUTPUT_STORAGE_URI: stringa. Facoltativo. Il bucket Cloud Storage in cui archiviare le immagini di output. Se non vengono forniti, nella risposta vengono restituiti i byte dell'immagine con codifica base64. Valore di esempio:
gs://image-bucket/output/.
Parametri facoltativi aggiuntivi
Utilizza le seguenti variabili facoltative a seconda del tuo caso d'uso. Aggiungi alcuni o tutti i seguenti parametri nell'oggetto
"parameters": {}. Questo elenco mostra i parametri facoltativi comuni e non è esaustivo. Per ulteriori informazioni sui parametri facoltativi, consulta Riferimento API Imagen: Genera immagini."parameters": { "sampleCount": IMAGE_COUNT, "addWatermark": ADD_WATERMARK, "aspectRatio": "ASPECT_RATIO", "enhancePrompt": ENABLE_PROMPT_REWRITING, "includeRaiReason": INCLUDE_RAI_REASON, "includeSafetyAttributes": INCLUDE_SAFETY_ATTRIBUTES, "outputOptions": { "mimeType": "MIME_TYPE", "compressionQuality": COMPRESSION_QUALITY }, "personGeneration": "PERSON_SETTING", "safetySetting": "SAFETY_SETTING", "seed": SEED_NUMBER, "storageUri": "OUTPUT_STORAGE_URI" }Metodo HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict
Corpo JSON della richiesta:
{ "instances": [ { "prompt": "TEXT_PROMPT" } ], "parameters": { "sampleCount": IMAGE_COUNT } }Per inviare la richiesta, scegli una di queste opzioni:
La seguente risposta di esempio è per una richiesta concurl
Salva il corpo della richiesta in un file denominato
request.json, ed esegui questo comando:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict"PowerShell
Salva il corpo della richiesta in un file denominato
request.json, ed esegui questo comando:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict" | Select-Object -Expand Content"sampleCount": 2. La risposta restituisce due oggetti di previsione, con i byte dell'immagine generata codificati in base64.{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }
Se utilizzi un modello che supporta il miglioramento dei prompt, la risposta include un ulteriore campo
promptcon il prompt migliorato utilizzato per la generazione:{ "predictions": [ { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_1", "bytesBase64Encoded": "BASE64_IMG_BYTES_1" }, { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_2", "bytesBase64Encoded": "BASE64_IMG_BYTES_2" } ] }Passaggi successivi
Leggi gli articoli su Imagen e altri prodotti di AI generativa su Vertex AI:
- Guida per gli sviluppatori per iniziare a utilizzare Imagen 3 su Vertex AI
- Nuovi modelli e strumenti di media generativi, creati con e per i creator
- Novità di Gemini: Gem personalizzati e generazione di immagini migliorata con Imagen 3
- Google DeepMind: Imagen 3, il nostro modello di conversione da testo a immagine di altissima qualità
Salvo quando diversamente specificato, i contenuti di questa pagina sono concessi in base alla licenza Creative Commons Attribution 4.0, mentre gli esempi di codice sono concessi in base alla licenza Apache 2.0. Per ulteriori dettagli, consulta le norme del sito di Google Developers. Java è un marchio registrato di Oracle e/o delle sue consociate.
Ultimo aggiornamento 2025-10-19 UTC.