Después de desarrollar un agente, puedes usar el servicio de evaluación de IA generativa para evaluar la capacidad del agente de completar tareas y objetivos para un caso de uso determinado.
Define las métricas de evaluación
Comienza con una lista vacía de métricas (es decir, metrics = []) y agrégale las métricas pertinentes. Para incluir métricas adicionales, sigue estos pasos:
Respuesta final
La evaluación de la respuesta final sigue el mismo proceso que la evaluación basada en el modelo. Para obtener más información, consulta Define tus métricas de evaluación.
Concordancia exacta
metrics.append("trajectory_exact_match")
Si la trayectoria predicha es idéntica a la de referencia, con las mismas llamadas a herramientas en el mismo orden, la métrica trajectory_exact_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Coincidencia en orden
metrics.append("trajectory_in_order_match")
Si la trayectoria predicha contiene todas las llamadas a herramientas de la trayectoria de referencia en el mismo orden y también puede tener llamadas a herramientas adicionales, la métrica trajectory_in_order_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada:
predicted_trajectory: Es la trayectoria predicha que usa el agente para llegar a la respuesta final.reference_trajectory: Es la trayectoria prevista esperada para que el agente satisfaga la búsqueda.
Coincidencia en cualquier orden
metrics.append("trajectory_any_order_match")
Si la trayectoria predicha contiene todas las llamadas a herramientas de la trayectoria de referencia, pero el orden no importa y puede contener llamadas a herramientas adicionales, la métrica trajectory_any_order_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Precisión
metrics.append("trajectory_precision")
La métrica trajectory_precision mide cuántas de las llamadas a herramientas en la trayectoria predicha son realmente relevantes o correctas según la trayectoria de referencia. Es un valor de float en el rango de [0, 1]: cuanto mayor sea la puntuación, más precisa será la trayectoria predicha.
La precisión se calcula de la siguiente manera: Cuenta cuántas acciones en la trayectoria predicha también aparecen en la trayectoria de referencia. Divide ese recuento por la cantidad total de acciones en la trayectoria predicha.
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Recuperación
metrics.append("trajectory_recall")
La métrica trajectory_recall mide cuántas de las llamadas a herramientas esenciales de la trayectoria de referencia se capturan realmente en la trayectoria predicha. Es un valor de float en el rango de [0, 1]: Cuanto mayor sea la puntuación, mejor será la recuperación de la trayectoria predicha.
El recuento se calcula de la siguiente manera: Cuenta cuántas acciones en la trayectoria de referencia también aparecen en la trayectoria predicha. Divide ese recuento por la cantidad total de acciones en la trayectoria de referencia.
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Uso de una sola herramienta
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
La métrica trajectory_single_tool_use verifica si se usa una herramienta específica que se especifica en la especificación de la métrica en la trayectoria predicha. No verifica el orden de las llamadas a herramientas ni cuántas veces se usa la herramienta, solo si está presente o no. Es un valor de 0 si la herramienta no está presente y 1 en caso contrario.
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.
Personalizado
Puedes definir una métrica personalizada de la siguiente manera:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
Las siguientes dos métricas de rendimiento siempre se incluyen en los resultados. No es necesario que los especifiques en EvalTask:
latency(float): Tiempo que tardó el agente en responder (en segundos).failure(bool):0si la invocación del agente se realizó correctamente; de lo contrario,1.
Prepara el conjunto de datos de evaluación
Para preparar tu conjunto de datos para la evaluación final de la respuesta o la trayectoria, haz lo siguiente:
Respuesta final
El esquema de datos para la evaluación de la respuesta final es similar al de la evaluación de la respuesta del modelo.
Concordancia exacta
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Coincidencia en orden
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la trayectoria predicha que usa el agente para llegar a la respuesta final.reference_trajectory: Es la trayectoria prevista esperada para que el agente satisfaga la búsqueda.
Coincidencia en cualquier orden
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Precisión
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Recuperación
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.reference_trajectory: Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda.
Uso de una sola herramienta
El conjunto de datos de evaluación debe proporcionar las siguientes entradas:
Parámetros de entrada:
predicted_trajectory: Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final.
A modo de ilustración, a continuación, se muestra un ejemplo de un conjunto de datos de evaluación.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Conjuntos de datos de ejemplo
Proporcionamos los siguientes conjuntos de datos de ejemplo para demostrar cómo puedes evaluar agentes:
"on-device": Es el conjunto de datos de evaluación para un Asistente de la casa integrado en el dispositivo. El agente ayuda con consultas como "Programa el aire acondicionado de la habitación para que esté encendido entre las 11 p.m. y las 8 a.m., y apagado el resto del tiempo"."customer-support": Es el conjunto de datos de evaluación para un agente de asistencia al cliente. El agente ayuda con consultas como "¿Puedes cancelar los pedidos pendientes y derivar los tickets de asistencia abiertos?"."content-creation": Es el conjunto de datos de evaluación para un agente de creación de contenido de marketing. El agente ayuda con consultas como "Reprograma la campaña X para que sea una campaña única en el sitio de redes sociales Y con un presupuesto reducido en un 50%, solo el 25 de diciembre de 2024".
Para importar los conjuntos de datos de ejemplo, sigue estos pasos:
Instala e inicializa la CLI de
gcloud.Descarga el conjunto de datos de evaluación.
En el dispositivo
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Asistencia al cliente
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Creación de contenido
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Carga los ejemplos del conjunto de datos
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Genera resultados de la evaluación
Para generar los resultados de la evaluación, ejecuta el siguiente código:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
Visualiza e interpreta los resultados
Los resultados de la evaluación se muestran de la siguiente manera:
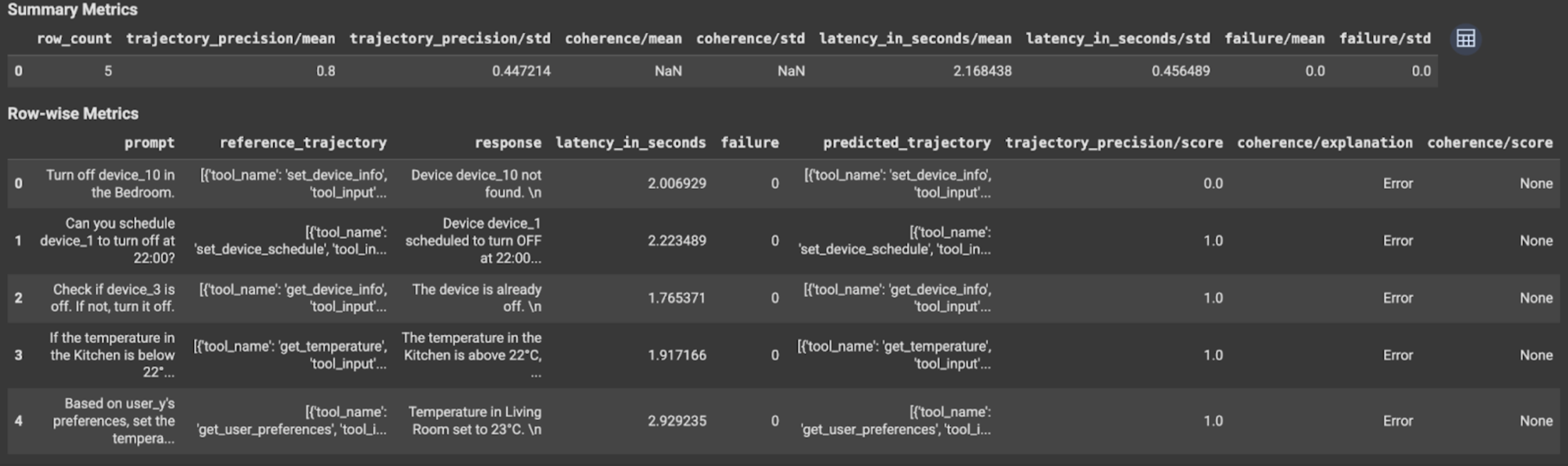
Los resultados de la evaluación contienen la siguiente información:
Métricas de respuesta final
Métricas por fila:
response: Es la respuesta final que generó el agente.latency_in_seconds: Tiempo que tardó en generarse la respuesta (en segundos).failure: Indica si se generó una respuesta válida o no.score: Es una puntuación calculada para la respuesta especificada en la especificación de la métrica.explanation: Es la explicación de la puntuación especificada en la especificación de la métrica.
Métricas de resumen:
mean: Es la puntuación promedio de todas las instancias.standard deviation: Desviación estándar de todas las puntuaciones.
Métricas de trayectoria
Métricas por fila:
predicted_trajectory: Es la secuencia de llamadas a herramientas que sigue el agente para llegar a la respuesta final.reference_trajectory: Es la secuencia de llamadas a herramientas esperadas.score: Es una puntuación calculada para la trayectoria predicha y la trayectoria de referencia especificadas en la especificación de la métrica.latency_in_seconds: Tiempo que tardó en generarse la respuesta (en segundos).failure: Indica si se generó una respuesta válida o no.
Métricas de resumen:
mean: Es la puntuación promedio de todas las instancias.standard deviation: Desviación estándar de todas las puntuaciones.
¿Qué sigue?
Prueba los siguientes notebooks: