Después de compilar y evaluar tu modelo de IA generativa, puedes usarlo para crear un agente, como un chatbot. El servicio de evaluación de IA generativa te permite medir la capacidad de tu agente para completar tareas y objetivos en tu caso de uso.
Descripción general
Tienes las siguientes opciones para evaluar tu agente:
Evaluación de la respuesta final: Evalúa el resultado final de un agente (independientemente de si el agente logró su objetivo).
Evaluación de la trayectoria: Evalúa la ruta (secuencia de llamadas a herramientas) que siguió el agente para llegar a la respuesta final.
Con el servicio de evaluación de IA generativa, puedes activar la ejecución de un agente y obtener métricas para la evaluación de la trayectoria y la evaluación de la respuesta final en una sola consulta del SDK de Vertex AI.
Agentes admitidos
El servicio de evaluación de IA generativa admite las siguientes categorías de agentes:
| Agentes admitidos | Descripción |
|---|---|
| Agente creado con la plantilla de Agent Engine | Agent Engine (LangChain en Vertex AI) es una plataforma Google Cloud en la que puedes implementar y administrar agentes. |
| Agentes de LangChain creados con la plantilla personalizable de Agent Engine | LangChain es una plataforma de código abierto. |
| Función personalizada del agente | La función del agente personalizada es una función flexible que toma una instrucción para el agente y devuelve una respuesta y una trayectoria en un diccionario. |
Cómo definir métricas para la evaluación de agentes
Define tus métricas para la evaluación de la respuesta final o la trayectoria:
Evaluación de la respuesta final
La evaluación de la respuesta final sigue el mismo proceso que la evaluación de la respuesta del modelo. Para obtener más información, consulta Define tus métricas de evaluación.
Evaluación de la trayectoria
Las siguientes métricas te ayudan a evaluar la capacidad del modelo para seguir la trayectoria esperada:
Concordancia exacta
Si la trayectoria predicha es idéntica a la trayectoria de referencia, con las mismas llamadas a herramientas en el mismo orden, la métrica trajectory_exact_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final. |
reference_trajectory |
Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| 0 | La trayectoria predicha no coincide con la referencia. |
| 1 | La trayectoria predicha coincide con la referencia. |
Coincidencia en orden
Si la trayectoria predicha contiene todas las llamadas a herramientas de la trayectoria de referencia en el mismo orden y también puede tener llamadas a herramientas adicionales, la métrica trajectory_in_order_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la trayectoria predicha que usa el agente para llegar a la respuesta final. |
reference_trajectory |
Es la trayectoria prevista esperada para que el agente satisfaga la búsqueda. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| 0 | Las llamadas a herramientas en la trayectoria predicha no coinciden con el orden en la trayectoria de referencia. |
| 1 | La trayectoria predicha coincide con la referencia. |
Coincidencia en cualquier orden
Si la trayectoria predicha contiene todas las llamadas a herramientas de la trayectoria de referencia, pero el orden no importa y puede contener llamadas a herramientas adicionales, la métrica trajectory_any_order_match devuelve una puntuación de 1; de lo contrario, devuelve 0.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final. |
reference_trajectory |
Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| 0 | La trayectoria predicha no contiene todas las llamadas a herramientas de la trayectoria de referencia. |
| 1 | La trayectoria predicha coincide con la referencia. |
Precisión
La métrica trajectory_precision mide cuántas de las llamadas a herramientas en la trayectoria predicha son realmente relevantes o correctas según la trayectoria de referencia.
La precisión se calcula de la siguiente manera: Cuenta cuántas acciones en la trayectoria predicha también aparecen en la trayectoria de referencia. Divide ese recuento por la cantidad total de acciones en la trayectoria predicha.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final. |
reference_trajectory |
Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| Número de punto flotante en el rango de [0,1] | Cuanto más alta sea la puntuación, más precisa será la trayectoria predicha. |
Recuperación
La métrica trajectory_recall mide cuántas de las llamadas a herramientas esenciales de la trayectoria de referencia se capturan realmente en la trayectoria predicha.
La recuperación se calcula de la siguiente manera: Cuenta cuántas acciones de la trayectoria de referencia también aparecen en la trayectoria predicha. Divide ese recuento por la cantidad total de acciones en la trayectoria de referencia.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final. |
reference_trajectory |
Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| Número de punto flotante en el rango de [0,1] | Cuanto más alta sea la puntuación, mejor será la recuperación de la trayectoria predicha. |
Uso de una sola herramienta
La métrica trajectory_single_tool_use verifica si se usa una herramienta específica que se especifica en la especificación de la métrica en la trayectoria predicha. No verifica el orden de las llamadas a herramientas ni cuántas veces se usa la herramienta, solo si está presente o no.
Parámetros de entrada de métricas
| Parámetro de entrada | Descripción |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usa el agente para llegar a la respuesta final. |
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| 0 | La herramienta no está presente |
| 1 | La herramienta está presente. |
Además, las siguientes dos métricas de rendimiento del agente se agregan a los resultados de la evaluación de forma predeterminada. No es necesario que los especifiques en EvalTask.
latency
Es el tiempo que tarda el agente en devolver una respuesta.
| Valor | Descripción |
|---|---|
| Un número de punto flotante | Se calcula en segundos. |
failure
Es un valor booleano que describe si la invocación del agente generó un error o se realizó correctamente.
Puntuaciones de salida
| Valor | Descripción |
|---|---|
| 1 | Error |
| 0 | Se devolvió una respuesta válida |
Prepara tu conjunto de datos para la evaluación del agente
Prepara tu conjunto de datos para la evaluación final de la respuesta o la trayectoria.
El esquema de datos para la evaluación de la respuesta final es similar al de la evaluación de la respuesta del modelo.
Para la evaluación de la trayectoria basada en el cálculo, tu conjunto de datos debe proporcionar la siguiente información:
| Tipo de entrada | Contenido del campo de entrada |
|---|---|
predicted_trajectory |
Es la lista de llamadas a herramientas que usan los agentes para llegar a la respuesta final. |
reference_trajectory (no se requiere para trajectory_single_tool_use metric) |
Es el uso esperado de la herramienta para que el agente satisfaga la búsqueda. |
Ejemplos de conjuntos de datos de evaluación
En los siguientes ejemplos, se muestran conjuntos de datos para la evaluación de la trayectoria. Ten en cuenta que reference_trajectory es obligatorio para todas las métricas, excepto trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Importa tu conjunto de datos de evaluación
Puedes importar tu conjunto de datos en los siguientes formatos:
Archivo JSONL o CSV almacenado en Cloud Storage
Tabla de BigQuery
DataFrame de Pandas
El servicio de evaluación de IA generativa proporciona conjuntos de datos públicos de ejemplo para demostrar cómo puedes evaluar tus agentes. En el siguiente código, se muestra cómo importar los conjuntos de datos públicos desde un bucket de Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
En el ejemplo anterior, dataset es uno de los siguientes conjuntos de datos públicos:
"on-device"para un asistente de casa integrado en el dispositivo, que controla los dispositivos de la casa El agente ayuda con consultas como "Programa el aire acondicionado de la habitación para que esté encendido entre las 11 p.m. y las 8 a.m., y apagado el resto del tiempo"."customer-support"para un agente de asistencia al cliente. El agente ayuda con preguntas como "¿Puedes cancelar los pedidos pendientes y derivar los tickets de asistencia abiertos?"."content-creation"para un agente de creación de contenido de marketing El agente ayuda con consultas como "Reprograma la campaña X para que sea una campaña única en el sitio de redes sociales Y con un presupuesto reducido en un 50%, solo el 25 de diciembre de 2024".
Ejecuta la evaluación del agente
Ejecuta una evaluación para la evaluación de la trayectoria o la respuesta final:
Para la evaluación del agente, puedes combinar métricas de evaluación de respuestas y métricas de evaluación de la trayectoria, como en el siguiente código:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Personalización de métricas
Puedes personalizar una métrica basada en un modelo de lenguaje grande para la evaluación de la trayectoria con una interfaz basada en plantillas o desde cero. Para obtener más detalles, consulta la sección sobre métricas basadas en modelos. A continuación, se muestra un ejemplo de plantilla:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
También puedes definir una métrica personalizada basada en el cálculo para la evaluación de la trayectoria o la evaluación de la respuesta de la siguiente manera:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Visualiza e interpreta los resultados
En el caso de la evaluación de la trayectoria o de la respuesta final, los resultados de la evaluación se muestran de la siguiente manera:
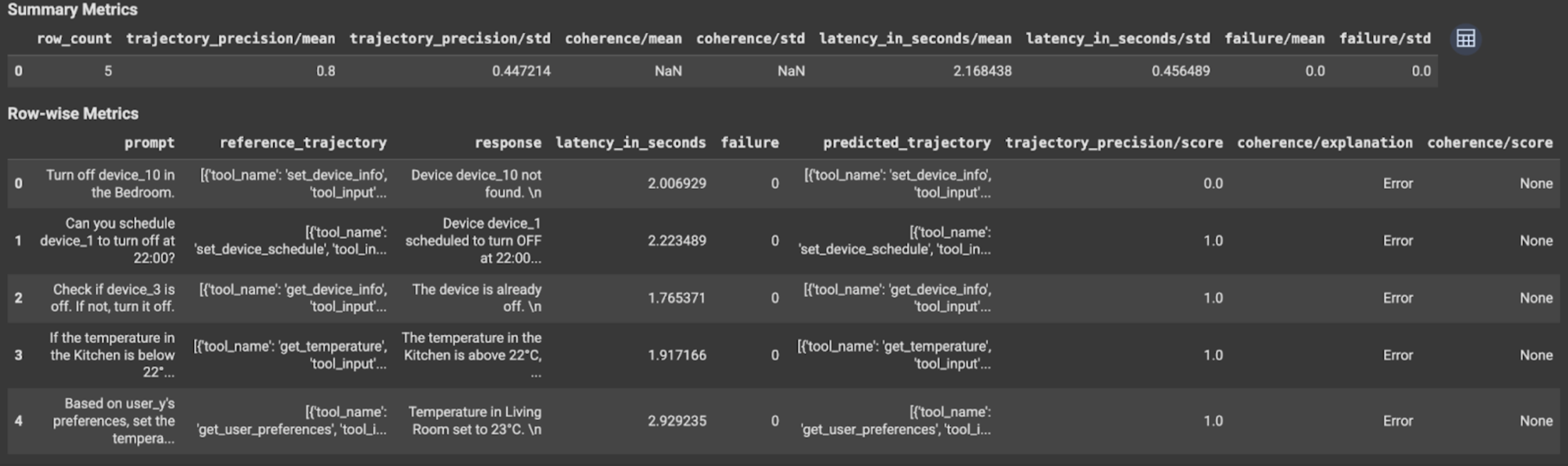
Los resultados de la evaluación contienen la siguiente información:
Métricas de respuesta final
Resultados a nivel de la instancia
| Columna | Descripción |
|---|---|
| respuesta | Es la respuesta final que genera el agente. |
| latency_in_seconds | Es el tiempo que se tardó en generar la respuesta. |
| falla | Indica si se generó una respuesta válida. |
| puntuación | Es una puntuación calculada para la respuesta especificada en la especificación de la métrica. |
| explanation | Es la explicación de la puntuación especificada en la especificación de la métrica. |
Resultados agregados
| Columna | Descripción |
|---|---|
| media | Es la puntuación promedio de todas las instancias. |
| standard deviation | Desviación estándar de todas las puntuaciones. |
Métricas de trayectoria
Resultados a nivel de la instancia
| Columna | Descripción |
|---|---|
| predicted_trajectory | Secuencia de llamadas a herramientas que sigue el agente para llegar a la respuesta final. |
| reference_trajectory | Es la secuencia de llamadas a herramientas esperadas. |
| puntuación | Es una puntuación calculada para la trayectoria predicha y la trayectoria de referencia especificadas en la especificación de la métrica. |
| latency_in_seconds | Es el tiempo que se tardó en generar la respuesta. |
| falla | Indica si se generó una respuesta válida. |
Resultados agregados
| Columna | Descripción |
|---|---|
| media | Es la puntuación promedio de todas las instancias. |
| standard deviation | Desviación estándar de todas las puntuaciones. |
Protocolo Agent2Agent (A2A)
Si estás creando un sistema multiagente, te recomendamos que revises el protocolo A2A. El protocolo A2A es un estándar abierto que permite la comunicación y colaboración fluidas entre agentes de IA, independientemente de sus frameworks subyacentes. La Linux Foundation recibió la donación de Google Cloud en junio de 2025. Para usar los SDKs de A2A o probar las muestras, consulta el repositorio de GitHub.
¿Qué sigue?
Prueba los siguientes notebooks de evaluación de agentes: