Mit dem Ops-Agent, der von Google empfohlenen Lösung für Telemetrieerfassung für Compute Engine, können Sie Messwerte wie GPU-Auslastung und GPU-Arbeitsspeicher auf Ihren VM-Instanzen beobachten. Mit dem Ops-Agent können Sie Ihre GPU-VMs so verwalten:
- Visualisieren Sie den Zustand Ihrer NVIDIA-GPU-Flotte mit unseren vorkonfigurierten Dashboards.
- Optimieren Sie die Kosten, indem Sie nicht ausgelastete GPUs ermitteln und Arbeitslasten konsolidieren
- Planen Sie die Skalierung, indem Sie sich Trends ansehen, um zu entscheiden, wann Sie die GPU-Kapazität erweitern oder vorhandene GPUs aktualisieren müssen.
- Verwenden Sie Profilerstellungsmesswerte für NVIDIA Data Center GPU Manager (DCGM), um Engpässe und Leistungsprobleme in Ihren GPUs zu bestimmen.
- Verwaltete Instanzgruppen (MIGs) einrichten, um Ressourcen automatisch zu skalieren.
- Benachrichtigungen zu Messwerten von Ihren NVIDIA-GPUs erhalten
In diesem Dokument wird beschrieben, wie Sie GPUs auf Linux-VMs mit dem Ops-Agent überwachen. Alternativ steht auf GitHub ein Berichtsskript zur Verfügung, das auch für das Monitoring der GPU-Nutzung auf Linux-VMs eingerichtet werden kann. Siehe compute-gpu-monitoring-Monitoring-Skript.
Dieses Script wird nicht aktiv gewartet.
Informationen zum Überwachen von GPUs auf Windows-VMs finden Sie unter GPU-Leistung (Windows) überwachen.
Übersicht
Der Ops-Agent ab Version 2.38.0 kann die GPU-Auslastung und die Raten der GPU-Speichernutzung auf Ihren Linux-VMs, auf denen der Agent installiert ist, automatisch beobachten. Diese Messwerte, die aus der NVIDIA Management Library (NVML) abgerufen werden, werden pro GPU und pro Prozess für jeden Prozess erfasst, der GPUs verwendet. Informationen zu den vom Ops-Agent überwachten Messwerten finden Sie unter Agent-Messwerte: gpu.
Sie können auch die Integration von NVIDIA Data Center GPU Manager (DCGM) mit dem Ops-Agent einrichten. Durch diese Integration kann der Ops-Agent Messwerte mithilfe der Hardwarezähler auf der GPU verfolgen. DCGM bietet Zugriff auf die GPU-Gerätemesswerte. Dazu gehören Streaming-Multiprozessor-Blockade (SM-Blockauslastung), SM-Belegung, SM-Pipe-Auslastung, PCIe-Trafficrate und NVLink-Traffic-Rate. Informationen zu den vom Ops-Agent überwachten Messwerten finden Sie unter Messwerte von Drittanbieter-Anwendungen: NVIDIA Data Center GPU Manager (DCGM).
Führen Sie die folgenden Schritte aus, um die GPU-Messwerte mit dem Ops-Agent zu prüfen:
- Prüfen Sie auf jeder VM, ob Sie die Anforderungen erfüllen.
- Installieren Sie auf jeder VM den Ops-Agent.
- Optional: Richten Sie auf jeder VM die NVIDIA Data Center GPU Manager-Integration (DCGM) ein.
- Messwerte in Cloud Monitoring prüfen.
Beschränkungen
- Der Ops-Agent beobachtet nicht die GPU-Auslastung auf VMs, die Container-Optimized OS verwenden.
Voraussetzungen
Prüfen Sie auf allen VMs, ob die folgenden Anforderungen erfüllt werden:
- An jede VM müssen GPUs angehängt sein.
- Auf jeder VM-Instanz muss ein GPU-Treiber installiert sein.
- Das Linux-Betriebssystem und die Version für jede VM müssen den Ops-Agent unterstützen. Siehe die Liste der Linux-Betriebssysteme, die den Ops-Agent unterstützen.
- Sie benötigen
sudo-Zugriff auf die einzelnen VMs.
Ops-Agent installieren
Führen Sie die folgenden Schritte aus, um den Ops-Agent zu installieren:
Wenn Sie zuvor das
compute-gpu-monitoring-Monitoring-Skript verwendet haben, um die GPU-Auslastung zu verfolgen, deaktivieren Sie den Dienst, bevor Sie den Ops-Agent installieren. Führen Sie den folgenden Befehl aus, um das Monitoring-Skript zu deaktivieren:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Installieren Sie die neueste Version des Ops-Agents. Eine ausführliche Anleitung finden Sie unter Ops-Agent installieren.
Wenn Sie den Ops-Agent installiert haben und Ihre GPU-Treiber mithilfe der von Compute Engine bereitgestellten Installationsskripts installieren oder aktualisieren müssen, lesen Sie die Einschränkungen.
NVML-Messwerte in Compute Engine ansehen
Sie können die NVML-Messwerte, die der Ops-Agent erfasst, auf den Tabs Beobachtbarkeit für Linux-VM-Instanzen von Compute Engine überprüfen.
So rufen Sie die Messwerte für eine einzelne VM auf:
Rufen Sie in der Google Cloud Console die Seite VM-Instanzen auf:
Wählen Sie eine VM aus, um die Seite Details zu öffnen.
Klicken Sie auf den Tab Beobachtbarkeit, um Informationen zur VM aufzurufen.
Wählen Sie den Schnellfilter GPU aus.
So rufen Sie die Messwerte für mehrere VMs auf:
Rufen Sie in der Google Cloud Console die Seite VM-Instanzen auf:
Klicken Sie auf den Tab Beobachtbarkeit.
Wählen Sie den Schnellfilter GPU aus.
Optional: Einbindung von NVIDIA Data Center GPU Manager (DCGM) einrichten
Der Ops-Agent bietet auch eine Einbindung für NVIDIA Data Center GPU Manager (DCGM), um wichtige GPU-Messwerte wie Streaming Multiprocessor (SM)-Blockauslastung, SM-Belegung, SM-Pipe-Auslastung, PCIe-Traffic-Rate, und NVLink-Traffic-Rate zu erfassen.
Diese erweiterten GPU-Messwerte werden nicht von den NVIDIA P100- und P4-Modellen erfasst.
Eine ausführliche Anleitung zum Einrichten und Verwenden dieser Integration auf den einzelnen VMs finden Sie unter NVIDIA Data Center GPU Manager (DCGM).
DCGM-Messwerte in Cloud Monitoring prüfen
Rufen Sie in der Google Cloud Console die Seite Monitoring > Dashboards auf.
Wählen Sie den Tab Beispielbibliothek aus.
Geben Sie im Feld Filter NVIDIA ein. Das Dashboard NVIDIA GPU Monitoring Overview (GCE and GKE) wird angezeigt.
Wenn Sie die Einbindung von NVIDIA Data Center GPU Manager (DCGM) eingerichtet haben, wird auch das Dashboard NVIDIA GPU Monitoring Advanced DCGM-Messwerte (nur GCE) angezeigt.
Klicken Sie im erforderlichen Dashboard auf Vorschau. Die Seite Beispiel-Dashboard-Vorschau wird angezeigt.
Klicken Sie auf der Seite Beispiel für die Dashboard-Vorschau auf Beispiel-Dashboard importieren.
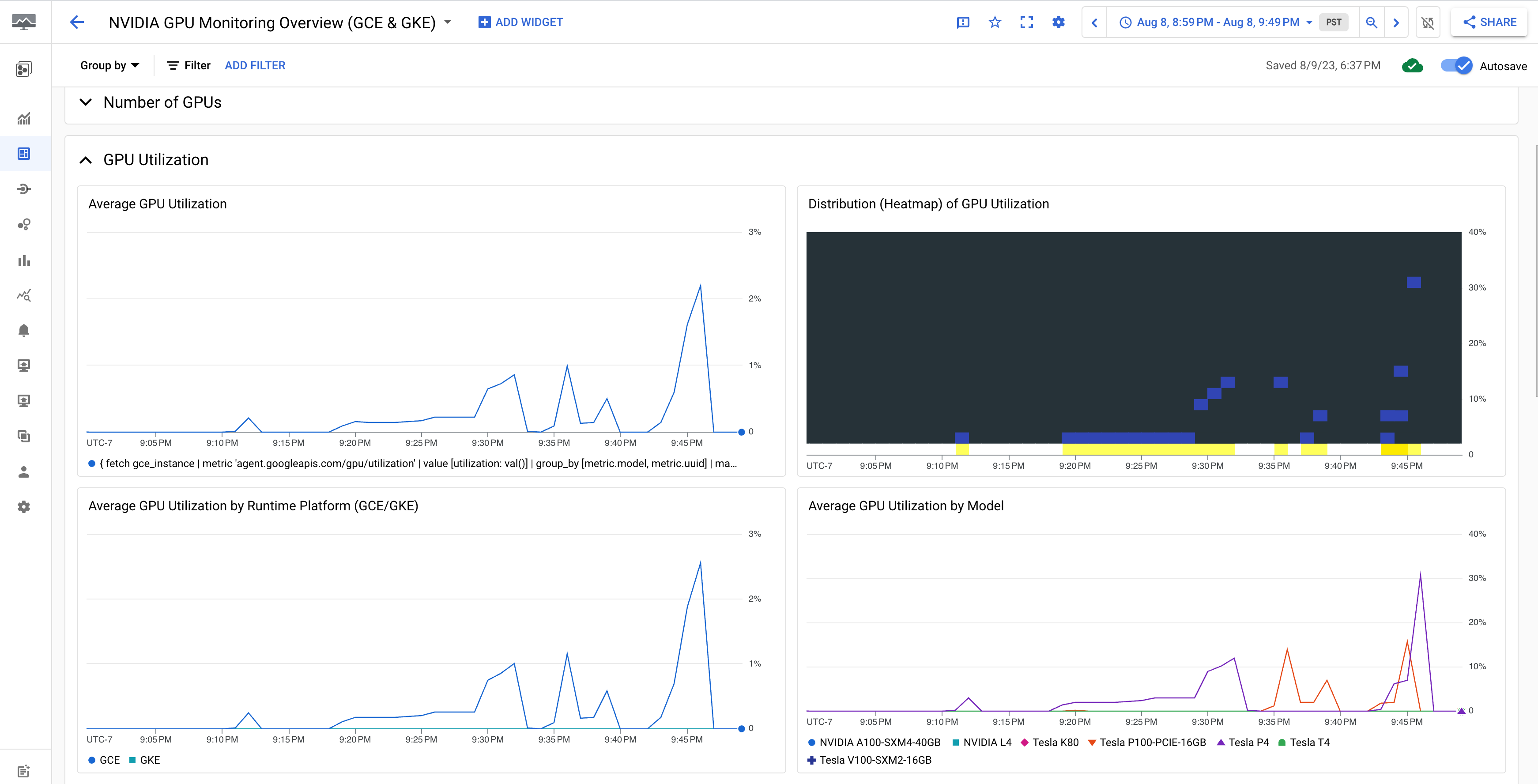
Im Dashboard NVIDIA GPU Monitoring Overview (GCE and GKE) (Übersicht zur NVIDIA-GPU-Überwachung (GCE und GKE)) werden die GPU-Messwerte wie GPU-Auslastung, NIC-Traffic-Rate und GPU-Speichernutzung angezeigt.
Die Anzeige der GPU-Auslastung sieht in etwa so aus:
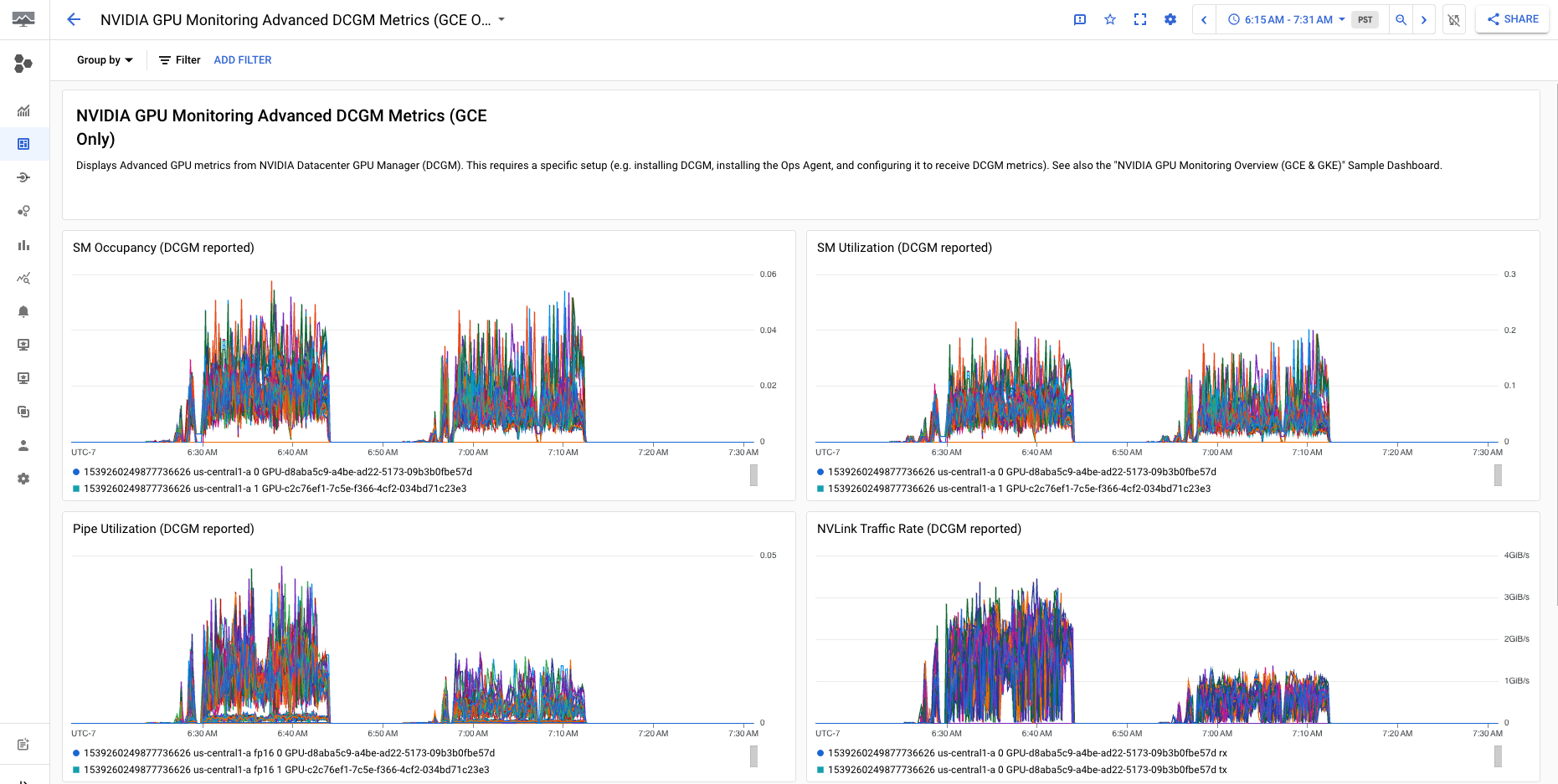
Im Dashboard Erweiterte DCGM-Messwerte der NVIDIA-GPU (nur GCE) werden wichtige erweiterte Messwerte angezeigt, z. B. die SM-Auslastung, SM-Belegung, senkrechte Pipe-Auslastung, PCIe-Trafficrate und NVLink Traffic-Rate.
Die Anzeige der erweiterten DCGM-Messwerte sieht in etwa so aus:
Nächste Schritte
- GPU-Hostwartungen
- Informationen zum Verbessern der Netzwerkleistung finden Sie unter Höhere Netzwerkbandbreite verwenden.