Para comprobar el estado de un volumen de disco persistente o de Google Cloud Hyperdisk, consulta la métrica Estado del rendimiento del disco. Esta métrica indica si el rendimiento del disco se ve afectado por eventos adversos en Compute Engine.
Un problema que afecte al estado del rendimiento del disco también puede aparecer en el panel de control Personal Service Health (PSH) de tu proyecto o en el panel de control Google Cloud Service Health.
En este documento se describe el estado del rendimiento del disco y cómo usarlo para solucionar problemas de rendimiento.
Cuándo comprobar el estado de un disco
Si detectas un problema de rendimiento en un disco, comprueba su estado consultando la métrica de estado del rendimiento del disco. La métrica de estado del rendimiento del disco se actualiza cada minuto y representa el rendimiento del disco durante el minuto anterior. Para consultar los pasos que debe seguir para comprobar el estado del disco, consulte Ver el estado del rendimiento del disco.
En la siguiente tabla se resumen los valores posibles del estado del rendimiento del disco.
| Estado | Significado |
|---|---|
Healthy |
El rendimiento del disco es el esperado. |
Degraded |
Es posible que observes temporalmente una latencia de E/S superior a la esperada. |
Severely degraded |
Se produce una latencia de E/S alta u otros errores. |
Si el estado del rendimiento no es Healthy, consulta Información sobre cada estado para saber qué hacer a continuación.
Si el estado del rendimiento es Healthy, el disco funciona con normalidad y debes buscar otras causas del problema de rendimiento.
Deberías comprobar si hay errores en la aplicación o en el sistema operativo y asegurarte de que el disco esté optimizado correctamente. Para consultar las directrices de optimización, consulte Optimizar Hyperdisk y Optimizar Persistent Disk.
Cómo se relaciona el estado del disco con otras métricas de rendimiento del disco
El estado del disco, indicado por la métrica de estado de rendimiento, muestra el estado interno del disco desde el punto de vista de Google. Si el estado de un disco es Degraded o Severely Degraded, la causa principal siempre se encuentra en la infraestructura de Compute Engine.
Por lo general, no puedes cambiar el estado de un disco modificando la carga de trabajo. Sin embargo, en raras ocasiones, un cambio en la carga de trabajo puede provocar un problema interno, por lo que es posible que se pueda mitigar modificando la carga de trabajo.
Para obtener información sobre otras métricas de rendimiento de disco disponibles, consulta Revisar las métricas de rendimiento del disco.
Situaciones que no afectan al estado del rendimiento del disco
El estado del rendimiento del disco no está relacionado con los problemas de rendimiento causados por los siguientes factores:
- Optimización de disco incompleta o insuficiente
- Límite de rendimiento asociado al tipo de disco y de máquina (si el tipo de máquina elegido no puede cumplir los requisitos de rendimiento de tu carga de trabajo)
- Aumento de la carga en el disco debido al tráfico de la carga de trabajo
- Error del usuario, de la aplicación o del sistema operativo
- Discos llenos o dañados
- En el caso de los volúmenes de hiperdisco y de disco persistente extremo, las IOPS o el rendimiento no se han aprovisionado correctamente.
En estas situaciones, es tu responsabilidad mejorar el rendimiento, por ejemplo, optimizando el disco, aumentando la carga de trabajo, cambiando el tipo de máquina y aprovisionando más capacidad, IOPS o rendimiento.
Ver el estado de un disco en Cloud Monitoring
Para ver el estado de un disco, crea un gráfico en el explorador de métricas.
Roles y permisos necesarios
Para obtener los permisos que necesitas para comprobar la métrica de estado del rendimiento del disco, pide a tu administrador que te conceda las siguientes funciones de IAM en el proyecto:
-
Lector de monitorización (
roles/monitoring.viewer) -
Para guardar un gráfico en un panel de control, sigue estos pasos:
Editor de monitorización (
roles/monitoring.editor)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.
También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Crear un gráfico en Explorador de métricas
Para crear un gráfico, crea una consulta con la interfaz basada en menús o con PromQL.
Interfaz basada en menús
Para ver el estado de uno o varios discos en un gráfico, sigue estas instrucciones.
-
En la Google Cloud consola, ve a la página leaderboard Explorador de métricas:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Monitorización.
- En la barra de herramientas de la Google Cloud consola, selecciona tu Google Cloud proyecto. En las configuraciones de App Hub, selecciona el proyecto host de App Hub o el proyecto de gestión de la carpeta habilitada para aplicaciones.
- En el elemento Métrica, despliega el menú Seleccionar una métrica,
introduce
VM Instanceen la barra de filtros y, a continuación, usa los submenús para seleccionar un tipo de recurso y una métrica específicos:- En el menú Recursos activos, selecciona Instancia de VM.
- En el menú Categorías de métricas activas, selecciona Instancia.
- En el menú Métricas activas, selecciona Estado del rendimiento del disco.
- Haz clic en Aplicar.
compute.googleapis.com/instance/disk/performance_status. Para añadir filtros que eliminen series temporales de los resultados de la consulta, usa el elemento Filter.
- Configura cómo se ven los datos.
Inhabilita la agregación. Asegúrate de que, en el elemento Agregación, el primer menú esté configurado como Sin agregar y el segundo como Ninguno.
Para ver el estado de un disco concreto, filtra pordevice_name.
Para obtener más información sobre cómo configurar un gráfico, consulta el artículo Seleccionar métricas al utilizar el explorador de métricas.
PromQL
Abre el editor de consultas siguiendo los pasos que se indican en Escribir consultas de PromQL.
Escribe tu consulta en el editor de consultas. Por ejemplo, para ver el estado del rendimiento de un disco concreto, introduce la siguiente consulta:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
Sustituye DISK_NAME por el nombre del disco. Por ejemplo, disk-1.
Si ves los resultados en un gráfico, habrá tres líneas por cada disco, una por cada estado posible. Del mismo modo, si ves el resultado de la consulta en una tabla, esta tendrá 3 filas por cada disco.
Si has creado la consulta con PromQL, cada fila o línea tendrá un valor de 1 o 0. En las consultas creadas con los menús, los valores de
serán 100% o 0.
El estado actual del disco se representa mediante la fila o la línea cuyo valor es 100%
o 1.
Por ejemplo, en la siguiente captura de pantalla se muestra el gráfico de un disco llamado a-test-VM, cuyo estado es Healthy:
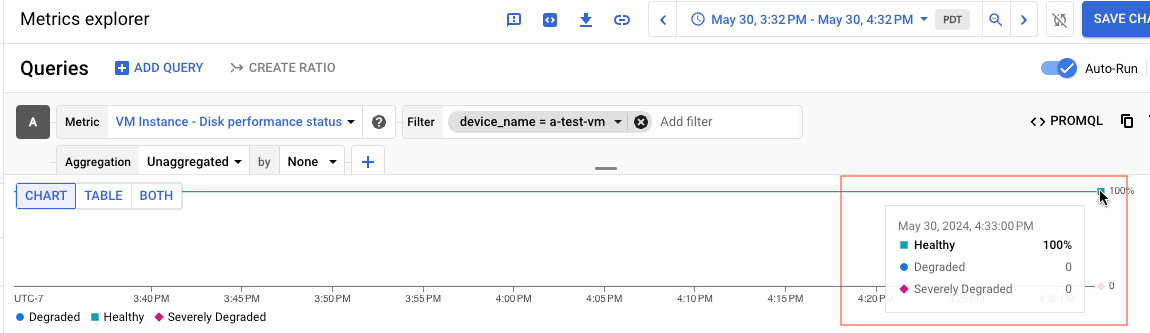
Si ves los resultados de la consulta en forma de tabla, la siguiente tabla es un ejemplo de los resultados de un disco que está Healthy:
| performance_status | valor |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
En la siguiente captura de pantalla se muestra el gráfico de un disco llamado replica-23509 cuyo estado es Degradado:
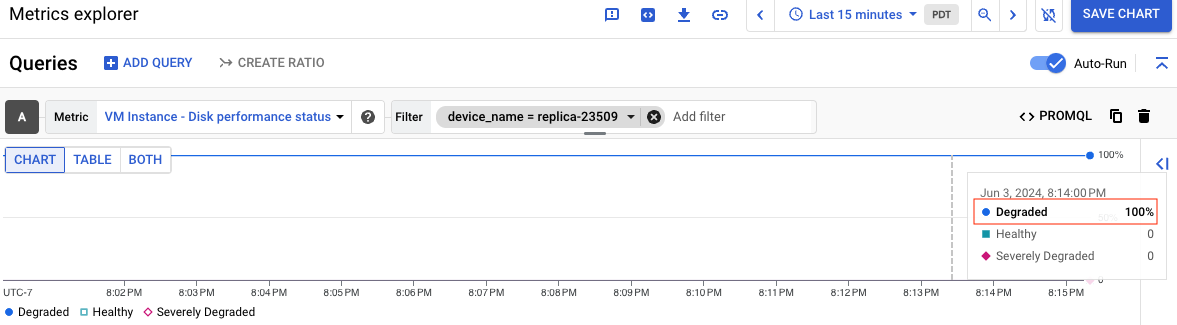
Para obtener información sobre el significado de cada estado de rendimiento, consulta el artículo Significado de cada estado. Una vez que hayas creado el gráfico, puedes guardarlo en un panel de control para usarlo más adelante.
Resultados fraccionarios
Si tu consulta incluye resultados fraccionarios, como en la siguiente tabla, suele deberse a que el periodo de visualización seleccionado era largo. Como resultado, Cloud Monitoring agregó los datos a lo largo del tiempo.
El valor 77% del estado Healthy significa que el estado del disco fue Healthy
el 77% del periodo de visualización seleccionado.
| performance_status | valor |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
Para obtener una vista más detallada del estado de un disco, usa un periodo de visualización de unas horas o de un número de minutos.
Información sobre cada estado
En esta sección se explica qué significa cada estado y cuándo puede que tengas que tomar medidas adicionales.
Healthy
El estado Healthy indica que, desde la perspectiva de Google, el disco funciona correctamente.
Si un disco Healthy tiene problemas de rendimiento, no te pongas en contacto con el equipo de Asistencia. En su lugar, prueba a solucionar el problema del disco con alguna de las siguientes sugerencias:
- Revisa las métricas de rendimiento del disco, como la latencia y la profundidad de la cola.
- Consulta los registros y las métricas de tu carga de trabajo para detectar anomalías y cuellos de botella.
- Si usas un disco persistente, asegúrate de que la capacidad aprovisionada pueda satisfacer las necesidades de rendimiento del disco. Si usas volúmenes de Hyperdisk o de disco persistente Extreme, comprueba que hayas aprovisionado suficientes IOPS y capacidad de procesamiento.
- Asegúrate de haber seguido las directrices para optimizar el disco. Para obtener más información, consulta Optimizar Hyperdisk y Optimizar disco persistente.
Degraded
Por lo general, no es necesario que te pongas en contacto con el equipo de Asistencia si el estado de tu disco es Degraded. Un Degraded status suele deberse a tareas de mantenimiento internas normales en la infraestructura de Compute Engine.
Puede que no notes ningún impacto en el rendimiento del disco mientras su estado sea Degraded. Si el problema de rendimiento y el estado Degraded se producen al mismo tiempo, es posible que el problema de rendimiento no esté relacionado con el estado Degraded.
En el improbable caso de que un problema de rendimiento se deba al estado Degraded, el impacto suele ser temporal. El estado del disco debería volver a Healthy en unos minutos.
Puedes ignorar el estado Degraded si no hay problemas de rendimiento con el disco.
Qué hacer si hay un problema de rendimiento
Si el estado del rendimiento de tu disco es Degraded y observas un problema de rendimiento, sigue estos pasos:
- Consulta el panel de control de PSH para ver si hay algún incidente que afecte al disco. Si se produce un incidente, no te pongas en contacto con el equipo de Asistencia, ya que Google es consciente del problema y está trabajando para resolverlo.
- Si no hay ningún problema conocido, espera al menos 5 minutos para que el problema de rendimiento se resuelva solo.
Si, después de 5 minutos, el problema de rendimiento sigue sin resolverse y el estado sigue siendo
Degraded, asegúrate de que el problema de rendimiento no se deba a que el disco no esté lo suficientemente optimizado. Por ejemplo, comprueba la latencia y la profundidad de la cola del disco. Es posible que el problema de rendimiento y el estadoDegradedno estén relacionados y que solo sea una coincidencia. Para ello, consulta las métricas del disco y las directrices de optimización del rendimiento.Si los problemas de rendimiento continúan y se cumplen todas las condiciones siguientes, puedes ponerte en contacto con el equipo de Asistencia para obtener ayuda:
- El estado del disco es
Degradeddesde hace más de 5 minutos - Estás razonablemente seguro de que no se trata de un problema de carga de trabajo porque has optimizado el disco y has verificado que no hay otros problemas, como un cuello de botella o una aplicación sobrecargada.
- No hay alertas en el panel de control de PSH
- El estado del disco es
Google no recomienda crear una alerta para el estado Degraded directamente, sino crear alertas sobre el estado de la aplicación de nivel superior y usar esta métrica para depurar problemas.
Severely Degraded
Un disco cuyo estado de rendimiento es Severely Degraded tiene un problema de rendimiento. Este problema puede deberse a un incidente o a un error, y es posible que ya se muestre en el panel de control de PSH o en el panel de control de estado del servicio.Google Cloud
¿Qué debes hacer?
Si el estado del rendimiento de tu disco es Severely Degraded, sigue estos pasos:
- Consulta el panel de control de estado del servicio personalizado y el panel de control de estado general para ver si hay algún incidente que afecte al disco. Google Cloud Si se produce un incidente, no te pongas en contacto con el equipo de Asistencia, ya que Google es consciente del problema y está trabajando para resolverlo.
- Si no hay problemas conocidos en ninguno de los dos paneles de control, ponte en contacto con el equipo de Asistencia para obtener ayuda.
Árbol de decisión
En el siguiente diagrama se muestra cómo proceder si un disco tiene un problema de rendimiento y se resume la información de las secciones anteriores.

Como se muestra en el diagrama de flujo, solo debes ponerte en contacto con el equipo de Asistencia si no hay alertas conocidas en los paneles de PSH y del servicio en la nube, y el estado del disco es Severely Degraded. Si el disco está Degraded, ponte en contacto con el equipo de Asistencia solo si se cumplen todas las condiciones siguientes:
- El disco lleva
Degradedmás de 5 minutos - Has descartado que se trate de un error o una configuración incorrecta de la carga de trabajo (por ejemplo, problemas de red).
- No se pueden realizar optimizaciones adicionales a nivel de aplicación, carga de trabajo o disco.
- Has revisado todas las métricas del disco
- Has examinado los registros de tu carga de trabajo y de tu máquina virtual (VM)
Siguientes pasos
- Consulta más información sobre cómo crear gráficos con Explorador de métricas y cómo acotar los resultados de las consultas añadiendo filtros a un gráfico.
- Consulta los eventos de estado del servicio activos y anteriores en el panel de control Personalized Service Health y en Google Service Health.
- Para consultar las directrices de optimización del rendimiento, consulta Optimizar Hyperdisk y Optimizar discos persistentes.