Ringkasan
Tutorial ini memandu Anda melalui proses men-deploy dan menayangkan model Llama 3.1 dan 3.2 menggunakan vLLM di Vertex AI. Dirancang untuk digunakan bersama dengan dua notebook terpisah: Menayangkan Llama 3.1 dengan vLLM untuk men-deploy model Llama 3.1 khusus teks, dan Menayangkan Multimodal Llama 3.2 dengan vLLM untuk men-deploy model Llama 3.2 multimodal yang menangani input teks dan gambar. Langkah-langkah yang diuraikan di halaman ini menunjukkan cara menangani inferensi model secara efisien di GPU dan menyesuaikan model untuk berbagai aplikasi, sehingga Anda memiliki alat untuk mengintegrasikan model bahasa tingkat lanjut ke dalam project Anda.
Setelah membaca panduan ini, Anda akan memahami cara:
- Download model Llama bawaan dari Hugging Face dengan container vLLM.
- Gunakan vLLM untuk men-deploy model ini di instance GPU dalam Google Cloud Vertex AI Model Garden.
- Menayangkan model secara efisien untuk menangani permintaan inferensi dalam skala besar.
- Menjalankan inferensi pada permintaan hanya teks dan permintaan teks + gambar.
- Pembersihan.
- Men-debug deployment.
Fitur Utama vLLM
| Fitur | Deskripsi |
|---|---|
| PagedAttention | Mekanisme perhatian yang dioptimalkan yang mengelola memori secara efisien selama inferensi. Mendukung pembuatan teks dengan throughput tinggi dengan mengalokasikan resource memori secara dinamis, sehingga memungkinkan skalabilitas untuk beberapa permintaan serentak. |
| Pengelompokan berkelanjutan | Menggabungkan beberapa permintaan input ke dalam satu batch untuk pemrosesan paralel, sehingga memaksimalkan penggunaan dan throughput GPU. |
| Streaming token | Mengaktifkan output token demi token secara real-time selama pembuatan teks. Ideal untuk aplikasi yang memerlukan latensi rendah, seperti chatbot atau sistem AI interaktif. |
| Kompatibilitas model | Mendukung berbagai model terlatih di seluruh framework populer seperti Hugging Face Transformers. Mempermudah integrasi dan eksperimen dengan berbagai LLM. |
| Multi-GPU & multi-host | Memungkinkan penayangan model yang efisien dengan mendistribusikan workload di beberapa GPU dalam satu mesin dan di beberapa mesin dalam cluster, sehingga meningkatkan throughput dan skalabilitas secara signifikan. |
| Deployment yang efisien | Menawarkan integrasi yang lancar dengan API, seperti penyelesaian chat OpenAI, sehingga memudahkan deployment untuk kasus penggunaan produksi. |
| Integrasi yang lancar dengan model Hugging Face | vLLM kompatibel dengan format artefak model Hugging Face dan mendukung pemuatan dari HF, sehingga memudahkan deployment model Llama bersama model populer lainnya seperti Gemma, Phi, dan Qwen dalam setelan yang dioptimalkan. |
| Project open source yang didorong komunitas | vLLM bersifat open source dan mendorong kontribusi komunitas, sehingga meningkatkan efisiensi penayangan LLM secara berkelanjutan. |
Penyesuaian vLLM Vertex AI Google: Meningkatkan performa dan integrasi
Implementasi vLLM dalam Google Vertex AI Model Garden bukan merupakan integrasi langsung dari library open source. Vertex AI mempertahankan versi vLLM yang disesuaikan dan dioptimalkan yang secara khusus disesuaikan untuk meningkatkan performa, keandalan, dan integrasi yang lancar dalam Google Cloud.
- Pengoptimalan performa:
- Download paralel dari Cloud Storage: Mempercepat waktu pemuatan dan deployment model secara signifikan dengan mengaktifkan pengambilan data paralel dari Cloud Storage, sehingga mengurangi latensi dan meningkatkan kecepatan startup.
- Peningkatan fitur:
- LoRA Dinamis dengan peningkatan penyiapan cache dan dukungan Cloud Storage: Memperluas kemampuan LoRA dinamis dengan mekanisme penyiapan cache disk lokal dan penanganan error yang andal, serta dukungan untuk memuat bobot LoRA langsung dari jalur Cloud Storage dan URL bertanda tangan. Hal ini menyederhanakan pengelolaan dan deployment model yang disesuaikan.
- Penguraian panggilan fungsi Llama 3.1/3.2: Menerapkan penguraian khusus untuk panggilan fungsi Llama 3.1/3.2, sehingga meningkatkan keandalan dalam penguraian.
- Caching awalan memori host: vLLM eksternal hanya mendukung caching awalan memori GPU.
- Dekode spekulatif: Ini adalah fitur vLLM yang sudah ada, tetapi Vertex AI menjalankan eksperimen untuk menemukan penyiapan model berperforma tinggi.
Penyesuaian khusus Vertex AI ini, meskipun sering kali transparan bagi pengguna akhir, memungkinkan Anda memaksimalkan performa dan efisiensi deployment Llama 3.1 di Vertex AI Model Garden.
- Integrasi ekosistem Vertex AI:
- Dukungan format input/output prediksi Vertex AI: Memastikan kompatibilitas yang lancar dengan format input dan output prediksi Vertex AI, sehingga menyederhanakan penanganan data dan integrasi dengan layanan Vertex AI lainnya.
- Pengenalan variabel lingkungan Vertex: Mematuhi dan memanfaatkan variabel lingkungan Vertex AI (
AIP_*) untuk konfigurasi dan pengelolaan resource, menyederhanakan deployment dan memastikan perilaku yang konsisten dalam lingkungan Vertex AI. - Penanganan error dan keandalan yang ditingkatkan: Menerapkan penanganan error yang komprehensif, validasi input/output, dan mekanisme penghentian server untuk memastikan stabilitas, keandalan, dan operasi yang lancar dalam lingkungan Vertex AI yang dikelola.
- Server Nginx untuk kemampuan: Mengintegrasikan server Nginx di atas server vLLM, memfasilitasi deployment beberapa replika, serta meningkatkan skalabilitas dan ketersediaan tinggi infrastruktur penayangan.
Manfaat tambahan vLLM
- Performa tolok ukur: vLLM menawarkan performa yang kompetitif jika dibandingkan dengan sistem penayangan lainnya seperti text-generation-inference Hugging Face dan FasterTransformer NVIDIA dalam hal throughput dan latensi.
- Kemudahan penggunaan: Library ini menyediakan API yang mudah untuk diintegrasikan dengan alur kerja yang ada, sehingga Anda dapat men-deploy model Llama 3.1 dan 3.2 dengan penyiapan minimal.
- Fitur lanjutan: vLLM mendukung output streaming (membuat respons token demi token) dan menangani perintah dengan panjang yang bervariasi secara efisien, sehingga meningkatkan interaktivitas dan responsivitas dalam aplikasi.
Untuk ringkasan sistem vLLM, lihat kertas kerja.
Model yang Didukung
vLLM memberikan dukungan untuk berbagai pilihan model canggih, sehingga Anda dapat memilih model yang paling sesuai dengan kebutuhan Anda. Tabel berikut menawarkan pilihan model ini. Namun, untuk mengakses daftar lengkap model yang didukung, termasuk model untuk inferensi multimodal dan hanya teks, Anda dapat melihat situs vLLM resmi.
| Kategori | Model |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B, dan variasinya (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) dan varian (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B, dan variannya (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Model Terkemuka Lainnya | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Mulai menggunakan Model Garden
Container penayangan GPU vLLM Cloud terintegrasi ke dalam Model Garden, yaitu playground, deployment sekali klik, dan contoh notebook Colab Enterprise. Tutorial ini berfokus pada rangkaian model Llama dari Meta AI sebagai contoh.
Menggunakan notebook Colab Enterprise
Deployment Playground dan sekali klik juga tersedia, tetapi tidak diuraikan dalam tutorial ini.
- Buka halaman kartu model lalu klik Buka notebook.
- Pilih notebook Vertex Serving. Notebook akan dibuka di Colab Enterprise.
- Jalankan notebook untuk men-deploy model menggunakan vLLM dan mengirim permintaan prediksi ke endpoint.
Penyiapan dan persyaratan
Bagian ini menguraikan langkah-langkah yang diperlukan untuk menyiapkan Google Cloud project dan memastikan Anda memiliki resource yang diperlukan untuk men-deploy dan menyajikan model vLLM.
1. Penagihan
- Aktifkan Penagihan: Pastikan penagihan diaktifkan untuk project Anda. Anda dapat melihat Mengaktifkan, menonaktifkan, atau mengubah penagihan untuk project.
2. Ketersediaan dan kuota GPU
- Untuk menjalankan prediksi menggunakan GPU berperforma tinggi (NVIDIA A100 80 GB atau H100 80 GB), pastikan untuk memeriksa kuota GPU ini di region yang Anda pilih:
| Jenis Mesin | Jenis Akselerator | Wilayah yang Direkomendasikan |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Menyiapkan Google Cloud Project
Jalankan contoh kode berikut untuk memastikan lingkungan Anda telah disiapkan dengan benar. Google Cloud Langkah ini menginstal library Python yang diperlukan dan menyiapkan akses ke Google Cloud resource. Tindakannya meliputi:
- Penginstalan: Upgrade library
google-cloud-aiplatformdan clone repositori yang berisi fungsi utilitas. - Penyiapan Lingkungan: Menentukan variabel untuk Google Cloud Project ID, region, dan bucket Cloud Storage unik untuk menyimpan artefak model.
- Pengaktifan API: Aktifkan Vertex AI API dan Compute Engine API, yang penting untuk men-deploy dan mengelola model AI.
- Konfigurasi bucket: Buat bucket Cloud Storage baru atau periksa bucket yang ada untuk memastikan bucket tersebut berada di region yang benar.
- Inisialisasi Vertex AI: Lakukan inisialisasi library klien Vertex AI dengan setelan project, lokasi, dan bucket staging.
- Penyiapan akun layanan: Identifikasi akun layanan default untuk menjalankan tugas Vertex AI dan berikan izin yang diperlukan.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Menggunakan Hugging Face dengan Meta Llama 3.1, 3.2, dan vLLM
Koleksi Llama 3.1 dan 3.2 Meta menyediakan berbagai model bahasa besar (LLM) multibahasa yang dirancang untuk pembuatan teks berkualitas tinggi di berbagai kasus penggunaan. Model ini telah dilatih dan dioptimalkan untuk mengikuti perintah, sehingga unggul dalam tugas seperti dialog multibahasa, ringkasan, dan pengambilan berbasis agen. Sebelum menggunakan model Llama 3.1 dan 3.2, Anda harus menyetujui persyaratan penggunaannya, seperti yang ditunjukkan dalam screenshot. Library vLLM menawarkan lingkungan penayangan yang disederhanakan dan open source dengan pengoptimalan untuk latensi, efisiensi memori, dan skalabilitas.
 Gambar 1: Perjanjian Lisensi Komunitas Meta LLama 3
Gambar 1: Perjanjian Lisensi Komunitas Meta LLama 3
Ringkasan Koleksi Meta Llama 3.1 dan 3.2
Koleksi Llama 3.1 dan 3.2 masing-masing ditujukan untuk skala deployment dan ukuran model yang berbeda, sehingga memberi Anda opsi fleksibel untuk tugas dialog multibahasa dan lainnya. Lihat halaman ringkasan Llama untuk mengetahui informasi selengkapnya.
- Khusus teks: Kumpulan model bahasa besar (LLM) multilingue Llama 3.2 adalah kumpulan model generatif yang telah dilatih awal dan disesuaikan untuk mengikuti perintah dalam ukuran 1B dan 3B (teks masuk, teks keluar).
- Vision dan Vision Instruct: Kumpulan model bahasa besar (LLM) multimodal Llama 3.2-Vision adalah kumpulan model generatif penalaran gambar yang telah dilatih sebelumnya dan disesuaikan untuk mengikuti perintah dalam ukuran 11B dan 90B (input teks + gambar, output teks). Pengoptimalan: Seperti Llama 3.1, model 3.2 disesuaikan untuk dialog multibahasa dan berperforma baik dalam tugas pengambilan dan peringkasan, serta mencapai hasil terbaik pada tolok ukur standar.
- Arsitektur Model: Llama 3.2 juga menampilkan framework transformer autoregresif, dengan SFT dan RLHF diterapkan untuk menyelaraskan model agar bermanfaat dan aman.
Token akses pengguna Hugging Face
Tutorial ini memerlukan token akses baca dari Hugging Face Hub untuk mengakses resource yang diperlukan. Ikuti langkah-langkah berikut untuk menyiapkan autentikasi Anda:
 Gambar 2: Setelan Token Akses Hugging Face
Gambar 2: Setelan Token Akses Hugging Face
Buat token akses baca:
- Buka setelan akun Hugging Face Anda.
- Buat token baru, tetapkan peran Baca untuk token tersebut, dan simpan token dengan aman.
Gunakan token:
- Gunakan token yang dibuat untuk mengautentikasi dan mengakses repositori publik atau pribadi sesuai kebutuhan untuk tutorial.
 Gambar 3: Mengelola Token Akses Hugging Face
Gambar 3: Mengelola Token Akses Hugging Face
Penyiapan ini memastikan Anda memiliki tingkat akses yang sesuai tanpa izin yang tidak perlu. Praktik ini meningkatkan keamanan dan mencegah token terekspos secara tidak sengaja. Untuk mengetahui informasi selengkapnya tentang cara menyiapkan token akses, buka halaman Token Akses Hugging Face.
Jangan membagikan atau mengekspos token Anda secara publik atau online. Saat Anda menyetel token sebagai variabel lingkungan selama deployment, token tersebut tetap bersifat pribadi untuk project Anda. Vertex AI memastikan keamanannya dengan mencegah pengguna lain mengakses model dan endpoint Anda.
Untuk mengetahui informasi selengkapnya tentang cara melindungi token akses Anda, lihat Token Akses Hugging Face - Praktik Terbaik.
Men-deploy Model Llama 3.1 Khusus Teks dengan vLLM
Untuk deployment model bahasa besar tingkat produksi, vLLM menyediakan solusi penayangan yang efisien yang mengoptimalkan penggunaan memori, menurunkan latensi, dan meningkatkan throughput. Hal ini membuatnya sangat cocok untuk menangani model Llama 3.1 yang lebih besar serta model Llama 3.2 multimodal.
Langkah 1: Pilih model yang akan di-deploy
Pilih varian model Llama 3.1 yang akan di-deploy. Opsi yang tersedia mencakup berbagai ukuran dan versi yang dioptimalkan untuk mengikuti perintah:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Langkah 2: Periksa hardware dan kuota deployment
Fungsi deploy menetapkan GPU dan jenis mesin yang sesuai berdasarkan ukuran model dan memeriksa kuota di region tersebut untuk project tertentu:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Verifikasi ketersediaan kuota GPU di region yang Anda tentukan:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Langkah 3: Periksa model menggunakan vLLM
Fungsi berikut mengupload model ke Vertex AI, mengonfigurasi setelan deployment, dan men-deploy-nya ke endpoint menggunakan vLLM.
- Image Docker: Deployment menggunakan image Docker vLLM yang telah dibuat sebelumnya untuk penayangan yang efisien.
- Konfigurasi: Konfigurasi penggunaan memori, panjang model, dan setelan vLLM lainnya. Untuk mengetahui informasi selengkapnya tentang argumen yang didukung oleh server, buka halaman dokumentasi vLLM resmi.
- Variabel Lingkungan: Tetapkan variabel lingkungan untuk autentikasi dan sumber deployment.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Langkah 4: Jalankan deployment
Jalankan fungsi deployment dengan model dan konfigurasi yang dipilih. Langkah ini men-deploy model dan menampilkan instance model dan endpoint:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Setelah menjalankan contoh kode ini, model Llama 3.1 Anda akan di-deploy di Vertex AI dan dapat diakses melalui endpoint yang ditentukan. Anda dapat berinteraksi dengannya untuk tugas inferensi seperti pembuatan teks, peringkasan, dan dialog. Bergantung pada ukuran model, deployment model baru dapat memerlukan waktu hingga satu jam. Anda dapat memeriksa progresnya di prediksi online.
 Gambar 4: Endpoint Deployment Llama 3.1 di Dasbor Vertex
Gambar 4: Endpoint Deployment Llama 3.1 di Dasbor Vertex
Membuat prediksi dengan Llama 3.1 di Vertex AI
Setelah berhasil men-deploy model Llama 3.1 ke Vertex AI, Anda dapat mulai membuat prediksi dengan mengirimkan perintah teks ke endpoint. Bagian ini memberikan contoh pembuatan respons dengan berbagai parameter yang dapat disesuaikan untuk mengontrol output.
Langkah 1: Tentukan perintah dan parameter Anda
Mulailah dengan menyiapkan perintah teks dan parameter pengambilan sampel untuk memandu respons model. Berikut adalah parameter utamanya:
prompt: Teks input yang ingin Anda gunakan untuk membuat respons model. Misalnya, perintah = "Apa itu mobil?".max_tokens: Jumlah maksimum token dalam output yang dihasilkan. Mengurangi nilai ini dapat membantu mencegah masalah waktu tunggu.temperature: Mengontrol keacakan prediksi. Nilai yang lebih tinggi (misalnya, 1.0) meningkatkan keragaman, sedangkan nilai yang lebih rendah (misalnya, 0.5) membuat output lebih terfokus.top_p: Membatasi kumpulan sampling ke probabilitas kumulatif teratas. Misalnya, menyetel top_p = 0,9 hanya akan mempertimbangkan token dalam 90% massa probabilitas teratas.top_k: Membatasi pengambilan sampel ke k token teratas yang paling mungkin. Misalnya, menetapkan top_k = 50 hanya akan mengambil sampel dari 50 token teratas.raw_response: Jika Benar (True), menampilkan output model mentah. Jika False, terapkan pemformatan tambahan dengan struktur "Perintah:\n{prompt}\nOutput:\n{output}".lora_id(opsional): Jalur ke file bobot LoRA untuk menerapkan bobot Low-Rank Adaptation (LoRA). Ini dapat berupa bucket Cloud Storage atau URL repositori Hugging Face. Perhatikan bahwa ini hanya berfungsi jika--enable-loradisetel di argumen deployment. LoRA dinamis tidak didukung untuk model multimodal.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Langkah 2: Kirim permintaan prediksi
Setelah instance dikonfigurasi, Anda dapat mengirim permintaan prediksi ke endpoint Vertex AI yang di-deploy. Contoh ini menunjukkan cara membuat prediksi dan mencetak hasilnya:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Contoh output
Berikut adalah contoh cara model merespons perintah "Apa itu mobil?":
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Catatan tambahan
- Moderasi: Untuk memastikan konten yang aman, Anda dapat memoderasi teks yang dihasilkan dengan kemampuan moderasi teks Vertex AI.
- Menangani waktu tunggu: Jika Anda mengalami masalah seperti
ServiceUnavailable: 503, coba kurangi parametermax_tokens.
Pendekatan ini memberikan cara yang fleksibel untuk berinteraksi dengan model Llama 3.1 menggunakan teknik pengambilan sampel dan adaptor LoRA yang berbeda, sehingga cocok untuk berbagai kasus penggunaan mulai dari pembuatan teks tujuan umum hingga respons khusus tugas.
Men-deploy model Llama 3.2 multimodal dengan vLLM
Bagian ini memandu Anda melalui proses mengupload model Llama 3.2 yang telah dibuat sebelumnya ke Model Registry dan men-deploy-nya ke endpoint Vertex AI. Waktu deployment dapat memakan waktu hingga satu jam, bergantung pada ukuran model. Model Llama 3.2 tersedia dalam versi multimodal yang mendukung input teks dan gambar. vLLM mendukung:
- Format hanya teks
- Format satu gambar + teks
Format ini membuat Llama 3.2 cocok untuk aplikasi yang memerlukan pemrosesan visual dan teks.
Langkah 1: Pilih model yang akan di-deploy
Tentukan varian model Llama 3.2 yang ingin Anda deploy. Contoh berikut menggunakan Llama-3.2-11B-Vision sebagai model yang dipilih, tetapi Anda dapat memilih dari opsi lain yang tersedia berdasarkan persyaratan Anda.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Langkah 2: Konfigurasi hardware dan resource
Pilih hardware yang sesuai untuk ukuran model. vLLM dapat menggunakan GPU yang berbeda, bergantung pada kebutuhan komputasi model:
- Model 1B dan 3B: Gunakan GPU NVIDIA L4.
- Model 11B: Gunakan GPU NVIDIA A100.
- Model 90B: Gunakan GPU NVIDIA H100.
Contoh ini mengonfigurasi deployment berdasarkan pemilihan model:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Pastikan Anda memiliki kuota GPU yang diperlukan:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Langkah 3: Deploy model menggunakan vLLM
Fungsi berikut menangani deployment model Llama 3.2 di Vertex AI. Hal ini mengonfigurasi lingkungan model, penggunaan memori, dan setelan vLLM untuk penayangan yang efisien.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Langkah 4: Jalankan deployment
Jalankan fungsi deployment dengan model dan setelan yang dikonfigurasi. Fungsi ini akan menampilkan instance model dan endpoint, yang dapat Anda gunakan untuk inferensi.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
 Gambar 5: Endpoint Deployment Llama 3.2 di Dasbor Vertex
Gambar 5: Endpoint Deployment Llama 3.2 di Dasbor Vertex
Bergantung pada ukuran model, deployment model baru dapat memerlukan waktu hingga satu jam untuk selesai. Anda dapat memeriksa progresnya di prediksi online.
Inferensi dengan vLLM di Vertex AI menggunakan rute prediksi default
Bagian ini memandu Anda menyiapkan inferensi untuk model Llama 3.2 Vision di Vertex AI menggunakan rute prediksi default. Anda akan menggunakan library vLLM untuk penayangan yang efisien dan berinteraksi dengan model dengan mengirimkan perintah visual bersama dengan teks.
Untuk memulai, pastikan endpoint model Anda di-deploy dan siap untuk prediksi.
Langkah 1: Tentukan perintah dan parameter Anda
Contoh ini memberikan URL gambar dan perintah teks, yang akan diproses oleh model untuk menghasilkan respons.
 Gambar 6: Contoh Input Gambar untuk memberikan perintah ke Llama 3.2
Gambar 6: Contoh Input Gambar untuk memberikan perintah ke Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Langkah 2: Konfigurasi parameter prediksi
Sesuaikan parameter berikut untuk mengontrol respons model:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Langkah 3: Siapkan permintaan prediksi
Siapkan permintaan prediksi dengan URL gambar, perintah, dan parameter lainnya.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Langkah 4: Buat prediksi
Kirim permintaan ke endpoint Vertex AI Anda dan proses respons:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Jika Anda mengalami masalah waktu tunggu (misalnya, ServiceUnavailable: 503 Took too
long to respond when processing), coba kurangi nilai max_tokens ke angka yang lebih rendah, seperti 20, untuk mengurangi waktu respons.
Inferensi dengan vLLM di Vertex AI menggunakan Penyelesaian Chat OpenAI
Bagian ini membahas cara melakukan inferensi pada model Llama 3.2 Vision menggunakan OpenAI Chat Completions API di Vertex AI. Dengan pendekatan ini, Anda dapat menggunakan kemampuan multimodal dengan mengirimkan perintah gambar dan teks ke model untuk mendapatkan respons yang lebih interaktif.
Langkah 1: Lakukan deployment model Llama 3.2 Vision Instruct
Jalankan fungsi deployment dengan model dan setelan yang dikonfigurasi. Fungsi ini akan menampilkan instance model dan endpoint, yang dapat Anda gunakan untuk inferensi.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Langkah 2: Konfigurasi resource endpoint
Mulai dengan menyiapkan nama resource endpoint untuk deployment Vertex AI Anda.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Langkah 3: Instal OpenAI SDK dan library autentikasi
Untuk mengirim permintaan menggunakan SDK OpenAI, pastikan library yang diperlukan telah diinstal:
!pip install -qU openai google-auth requests
Langkah 4: Tentukan parameter input untuk penyelesaian chat
Siapkan URL gambar dan perintah teks yang akan dikirim ke model. Sesuaikan
max_tokens dan temperature untuk mengontrol panjang respons dan keacakan,
masing-masing.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Langkah 5: Siapkan autentikasi dan URL dasar
Ambil kredensial Anda dan tetapkan URL dasar untuk permintaan API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Langkah 6: Kirim permintaan Penyelesaian Chat
Dengan menggunakan Chat Completions API OpenAI, kirim perintah gambar dan teks ke endpoint Vertex AI Anda:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(Opsional) Langkah 7: Menghubungkan kembali ke endpoint yang ada
Untuk terhubung kembali ke endpoint yang dibuat sebelumnya, gunakan ID endpoint. Langkah ini berguna jika Anda ingin menggunakan kembali endpoint, bukan membuat endpoint baru.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Konfigurasi ini memberikan fleksibilitas untuk beralih antara endpoint yang baru dibuat dan yang sudah ada sesuai kebutuhan, sehingga memungkinkan pengujian dan deployment yang disederhanakan.
Pembersihan
Untuk menghindari biaya berkelanjutan dan mengosongkan resource, pastikan untuk menghapus model dan endpoint yang di-deploy, serta secara opsional bucket penyimpanan yang digunakan untuk eksperimen ini.
Langkah 1: Hapus Endpoint dan Model
Kode berikut akan membatalkan deployment setiap model dan menghapus endpoint terkait:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Langkah 2: (Opsional) Hapus Bucket Cloud Storage
Jika membuat bucket Cloud Storage khusus untuk eksperimen ini, Anda dapat menghapusnya dengan menyetel delete_bucket ke True. Langkah ini bersifat opsional, tetapi direkomendasikan jika bucket tidak lagi diperlukan.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Dengan mengikuti langkah-langkah ini, Anda memastikan bahwa semua resource yang digunakan dalam tutorial ini telah dibersihkan, sehingga mengurangi biaya yang tidak perlu terkait dengan eksperimen.
Proses debug masalah umum
Bagian ini memberikan panduan untuk mengidentifikasi dan menyelesaikan masalah umum yang terjadi selama deployment dan inferensi model vLLM di Vertex AI.
Memeriksa log
Periksa log untuk mengidentifikasi penyebab utama kegagalan deployment atau perilaku yang tidak terduga:
- Buka Konsol Prediksi Vertex AI: Buka Konsol Prediksi Vertex AI di konsol Google Cloud .
- Pilih Endpoint: Klik endpoint yang mengalami masalah. Status harus menunjukkan apakah deployment telah gagal.
- Lihat Log: Klik endpoint, lalu buka tab Logs atau klik Lihat log. Tindakan ini akan mengarahkan Anda ke Cloud Logging, yang difilter untuk menampilkan log khusus untuk endpoint dan deployment model tersebut. Anda juga dapat mengakses log langsung melalui layanan Cloud Logging.
- Analisis Log: Tinjau entri log untuk melihat pesan error, peringatan, dan informasi relevan lainnya. Lihat stempel waktu untuk mengorelasikan entri log dengan tindakan tertentu. Cari masalah terkait batasan resource (memori dan CPU), masalah autentikasi, atau error konfigurasi.
Masalah Umum 1: CUDA Out of Memory (OOM) selama deployment
Error CUDA Out of Memory (OOM) terjadi saat penggunaan memori model melebihi kapasitas GPU yang tersedia.
Untuk model khusus teks, kami menggunakan argumen mesin berikut:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
Untuk model multimodal, kami menggunakan argumen mesin berikut:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
Men-deploy model multimodal dengan max_num_seqs = 256, seperti yang kita lakukan pada kasus model hanya teks, dapat menyebabkan error berikut:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
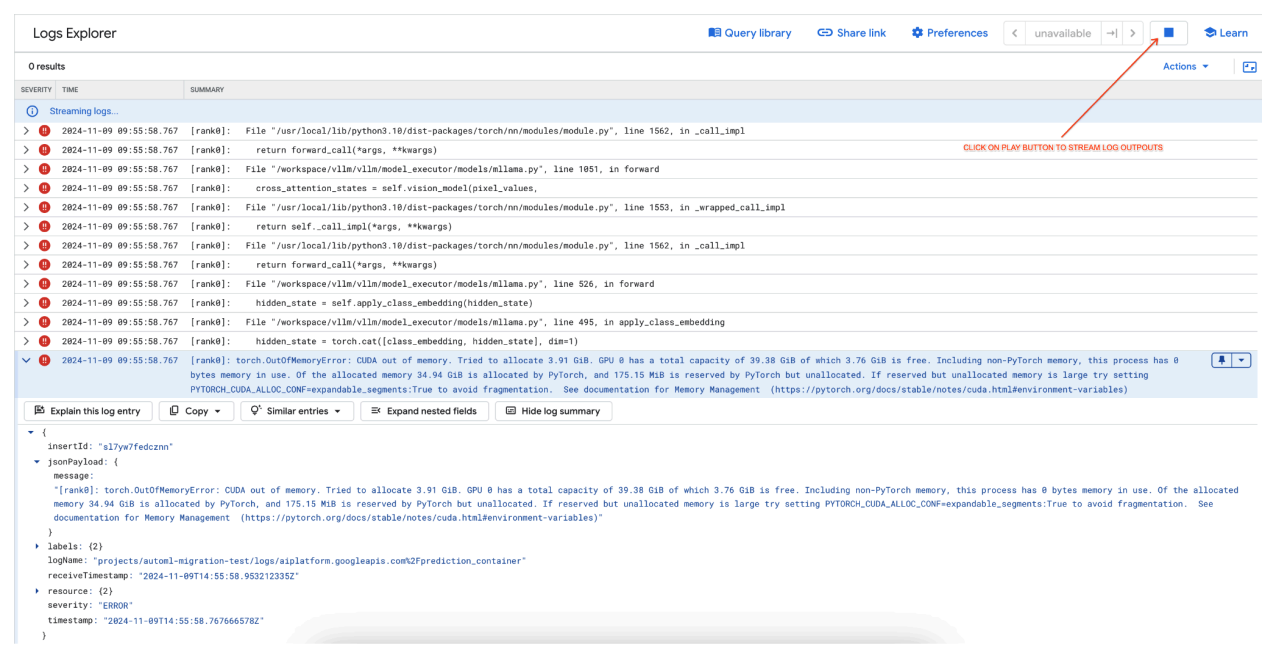 Gambar 7: Log Error GPU Kehabisan Memori (OOM)
Gambar 7: Log Error GPU Kehabisan Memori (OOM)
Memahami max_num_seqs dan Memori GPU:
- Parameter
max_num_seqsmenentukan jumlah maksimum permintaan serentak yang dapat ditangani model. - Setiap urutan yang diproses oleh model menggunakan memori GPU. Total penggunaan memori sebanding dengan
max_num_seqskali memori per urutan. - Model khusus teks (seperti Meta-Llama-3.1-8B) umumnya menggunakan lebih sedikit memori per urutan daripada model multimodal (seperti Llama-3.2-11B-Vision-Instruct), yang memproses teks dan gambar.
Tinjau Log Error (gambar 8):
- Log menampilkan
torch.OutOfMemoryErrorsaat mencoba mengalokasikan memori di GPU. - Error terjadi karena penggunaan memori model melebihi kapasitas GPU yang tersedia. GPU NVIDIA L4 memiliki 24 GB, dan menyetel parameter
max_num_seqsterlalu tinggi untuk model multimodal akan menyebabkan overflow. - Log menyarankan untuk menyetel
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Trueguna meningkatkan pengelolaan memori, meskipun masalah utamanya di sini adalah penggunaan memori yang tinggi.
 Gambar 8: Deployment Llama 3.2 Gagal
Gambar 8: Deployment Llama 3.2 Gagal
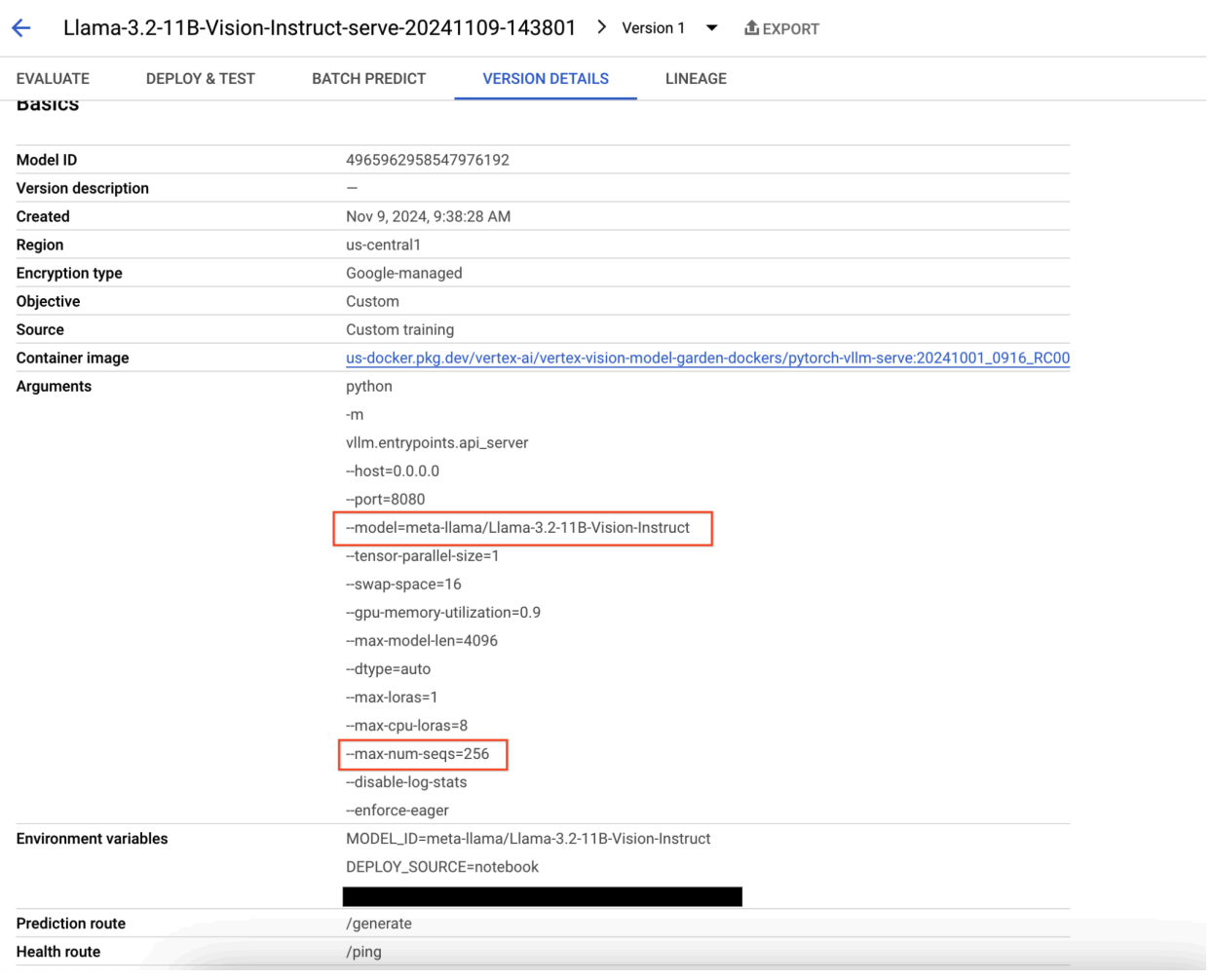 Gambar 9: Panel Detail Versi Model
Gambar 9: Panel Detail Versi Model
Untuk mengatasi masalah ini, buka Konsol Prediksi Vertex AI, lalu klik endpoint. Status harus menunjukkan bahwa deployment telah gagal. Klik untuk melihat log. Pastikan max-num-seqs = 256. Nilai ini terlalu tinggi untuk Llama-3.2-11B-Vision-Instruct. Nilai yang lebih memadai adalah 12.
Masalah Umum 2: Token Hugging Face diperlukan
Error token Hugging Face terjadi saat model dibatasi dan memerlukan kredensial autentikasi yang tepat untuk diakses.
Screenshot berikut menampilkan entri log di Log Explorer Google Cloud yang menampilkan pesan error terkait akses ke model Meta LLaMA-3.2-11B-Vision yang dihosting di Hugging Face. Error ini menunjukkan bahwa akses ke model dibatasi, sehingga memerlukan autentikasi untuk melanjutkan. Pesan tersebut secara khusus menyatakan, "Tidak dapat mengakses repositori yang dibatasi untuk URL", yang menunjukkan bahwa model tersebut dibatasi dan memerlukan kredensial autentikasi yang tepat untuk diakses. Entri log ini dapat membantu memecahkan masalah autentikasi saat bekerja dengan resource terbatas di repositori eksternal.
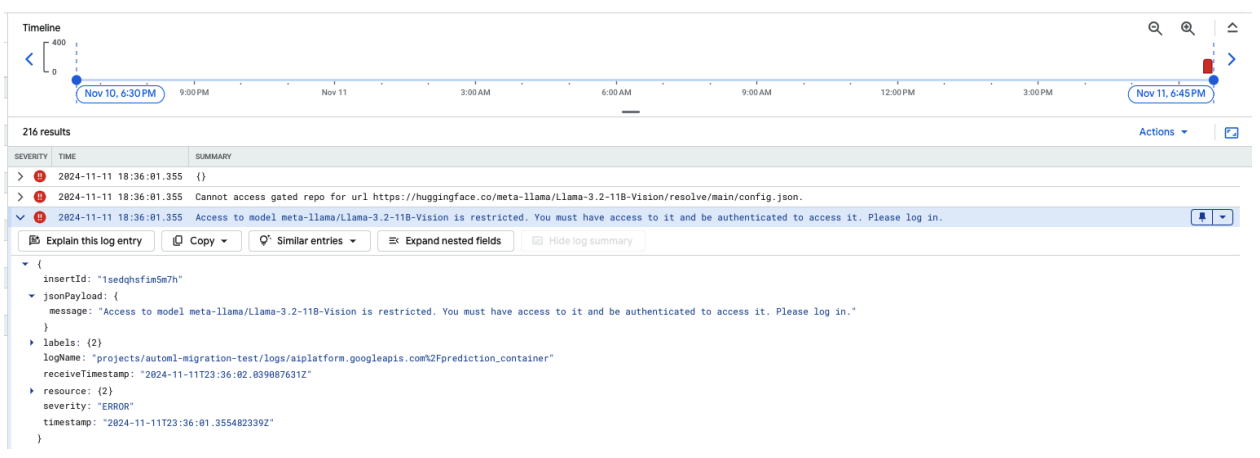 Gambar 10: Error Token Hugging Face
Gambar 10: Error Token Hugging Face
Untuk mengatasi masalah ini, verifikasi izin token akses Hugging Face Anda. Salin token terbaru dan deploy endpoint baru.
Masalah Umum 3: Template chat diperlukan
Error template chat terjadi saat template chat default tidak diizinkan lagi, dan template chat kustom harus diberikan jika tokenizer tidak menentukan salah satunya.
Screenshot ini menampilkan entri log di Log Explorer Google Cloud, tempat ValueError terjadi karena template chat tidak ada di library transformers versi 4.44. Pesan error menunjukkan bahwa template chat default tidak diizinkan lagi, dan template chat kustom harus disediakan jika tokenizer tidak menentukannya. Error ini menyoroti perubahan terbaru dalam library yang memerlukan definisi eksplisit template chat, yang berguna untuk mendebug masalah saat men-deploy aplikasi berbasis chat.
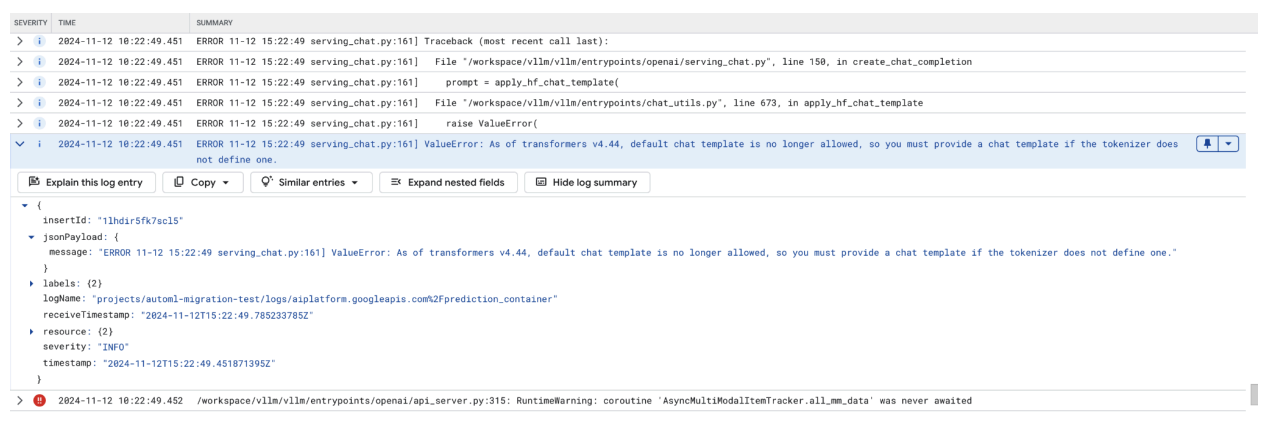 Gambar 11: Template Chat Diperlukan
Gambar 11: Template Chat Diperlukan
Untuk melewati hal ini, pastikan Anda memberikan template chat selama deployment menggunakan
argumen input --chat-template. Contoh template dapat ditemukan di repositori contoh vLLM.
Masalah Umum 4: Panjang Urutan Maksimum Model
Error panjang urutan maksimum model terjadi saat panjang urutan maksimum model (4096) lebih besar daripada jumlah token maksimum yang dapat disimpan dalam cache KV (2256).
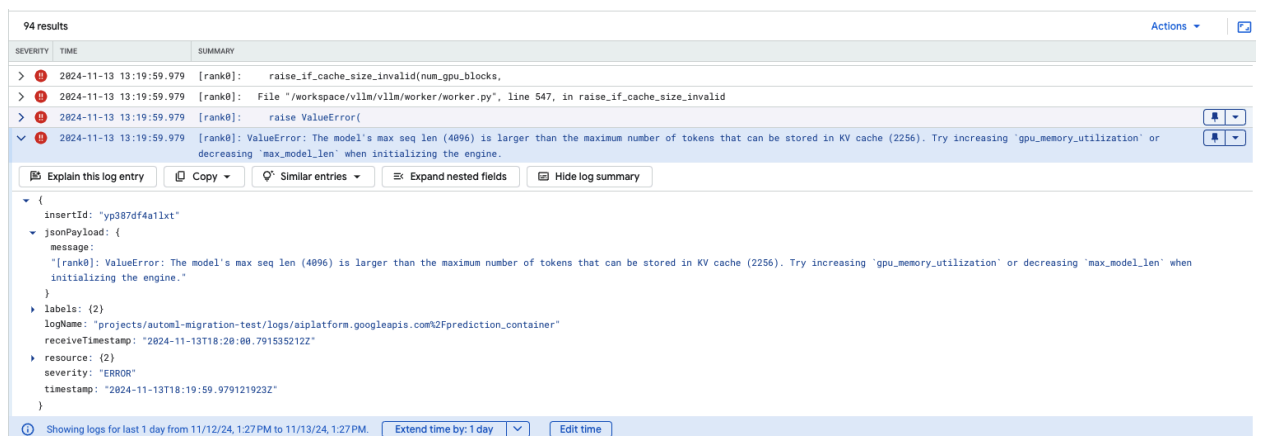 Gambar 12: Panjang Urutan Maks Terlalu Besar
Gambar 12: Panjang Urutan Maks Terlalu Besar
ValueError: Panjang urutan maks model (4096) lebih besar daripada jumlah maksimum token yang dapat disimpan dalam cache KV (2256). Coba naikkan
gpu_memory_utilization atau turunkan max_model_len saat melakukan inisialisasi
mesin.
Untuk mengatasi masalah ini, tetapkan max_model_len 2048, yang kurang dari 2256. Resolusi lain untuk masalah ini adalah dengan menggunakan GPU yang lebih banyak atau lebih besar. tensor-parallel-size harus ditetapkan dengan tepat jika memilih untuk menggunakan lebih banyak GPU.
Catatan rilis container vLLM Model Garden
Rilis utama
vLLM Standar
Tanggal rilis |
Arsitektur |
Versi vLLM |
URI Container |
|---|---|---|---|
| 17 Juli 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 Juli 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 Jun 2025 | x86 |
Setelah v0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 Jun 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 Jun 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 Mei 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 29 April 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17 Apr 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| Apr 10, 2025 | x86 |
Setelah v0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| 7 Apr 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| 7 Apr 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5 April 2025 | x86 |
Setelah v0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 Maret 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 Mar 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23 Mar 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 Maret 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11 Mar 2025 | x86 |
Setelah v0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3 Mar 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 Jan 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 Des 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 Nov 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 Oktober 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM yang dioptimalkan
Tanggal rilis |
Arsitektur |
URI Container |
|---|---|---|
| 21 Jan 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 Okt 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Rilis tambahan
Daftar lengkap rilis penampung vLLM standar VMG dapat ditemukan di halaman Artifact Registry.
Rilis untuk vLLM-TPU dalam status eksperimental diberi tag <yyyymmdd_hhmm_tpu_experimental_RC00>.