Questa pagina introduce come eseguire la valutazione basata su coppie di modelli utilizzando AutoSxS, uno strumento che esegue il servizio di pipeline di valutazione. Spieghiamo come utilizzare AutoSxS tramite l'API Vertex AI, l'SDK Vertex AI per Python o la console Google Cloud .
AutoSxS
Automatic Side-by-Side (AutoSxS) è uno strumento di valutazione basato su modelli a coppie che viene eseguito tramite il servizio di pipeline di valutazione. AutoSxS può essere utilizzato per valutare le prestazioni dei modelli di AI generativa in Vertex AI Model Registry o delle previsioni pregenerate, il che consente di supportare i foundation model di Vertex AI, i modelli di AI generativa ottimizzati e i modelli linguistici di terze parti. AutoSxS utilizza uno strumento di valutazione automatica per decidere quale modello fornisce la risposta migliore a un prompt. È disponibile on demand e valuta i modelli linguistici con prestazioni paragonabili a quelle dei valutatori umani.
The autorater
A livello generale, il diagramma mostra come AutoSxS confronta le previsioni dei modelli A e B con un terzo modello, lo strumento di valutazione automatica.
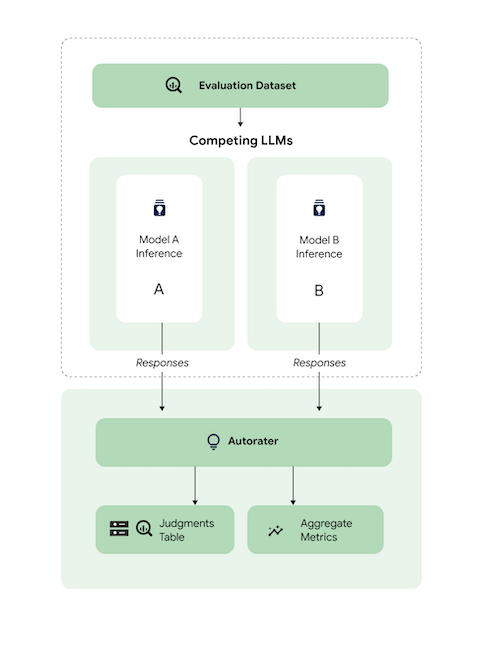
I modelli A e B ricevono i prompt di input e ciascun modello genera risposte che vengono inviate allo strumento di valutazione automatica. Analogamente a un valutatore umano, uno strumento di valutazione automatica è un modello linguistico che giudica la qualità delle risposte del modello dato un prompt di inferenza originale. Con AutoSxS, lo strumento di valutazione automatica confronta la qualità di due risposte del modello data l'istruzione di inferenza utilizzando un insieme di criteri. I criteri vengono utilizzati per determinare quale modello ha avuto le prestazioni migliori confrontando i risultati del modello A con quelli del modello B. Il modello di valutazione automatica restituisce le preferenze di risposta come metriche aggregate e restituisce spiegazioni delle preferenze e punteggi di affidabilità per ogni esempio. Per ulteriori informazioni, consulta la tabella dei giudizi.
Modelli supportati
AutoSxS supporta la valutazione di qualsiasi modello quando vengono fornite previsioni pregenerate. AutoSxS supporta anche la generazione automatica di risposte per qualsiasi modello nel registro dei modelli di Vertex AI che supporta la previsione batch su Vertex AI.
Se il tuo modello di testo non è supportato da Vertex AI Model Registry, AutoSxS accetta anche previsioni pregenerate archiviate come JSONL in Cloud Storage o in una tabella BigQuery. Per i prezzi, vedi Generazione di testo.
Attività e criteri supportati
AutoSxS supporta la valutazione dei modelli per le attività di riepilogo e risposta alle domande. I criteri di valutazione sono predefiniti per ogni attività, il che rende la valutazione linguistica più oggettiva e migliora la qualità delle risposte.
I criteri sono elencati per attività.
Riassunto
L'attività summarization ha un limite di token
di input di 4096.
Di seguito è riportato l'elenco dei criteri di valutazione per summarization:
| Criteri | |
|---|---|
| 1. Segue le istruzioni | In che misura la risposta del modello dimostra di comprendere l'istruzione del prompt? |
| 2. Grounded | La risposta include solo informazioni dal contesto di inferenza e dalle istruzioni di inferenza? |
| 3. Completo | In che misura il modello acquisisce i dettagli chiave nel riepilogo? |
| 4. Breve | Il riepilogo è prolisso? Include un linguaggio ricercato? È eccessivamente conciso? |
Risposta alla domanda
L'attività question_answering ha un limite di token
di input di 4096.
Di seguito è riportato l'elenco dei criteri di valutazione per question_answering:
| Criteri | |
|---|---|
| 1. Risponde completamente alla domanda | La risposta risponde completamente alla domanda. |
| 2. Grounded | La risposta include solo informazioni dal contesto delle istruzioni e dalle istruzioni di inferenza? |
| 3. Pertinenza | Il contenuto della risposta è pertinente alla domanda? |
| 4. Completo | In che misura il modello acquisisce i dettagli chiave della domanda? |
Prepara il set di dati di valutazione per AutoSxS
Questa sezione descrive in dettaglio i dati che devi fornire nel set di dati di valutazione AutoSxS e le best practice per la creazione del set di dati. Gli esempi devono rispecchiare gli input reali che i tuoi modelli potrebbero incontrare in produzione e mostrare al meglio il comportamento dei tuoi modelli live.
Formato del set di dati
AutoSxS accetta un unico set di dati di valutazione con uno schema flessibile. Il set di dati può essere una tabella BigQuery o archiviato come JSON Lines in Cloud Storage.
Ogni riga del set di dati di valutazione rappresenta un singolo esempio e le colonne sono una delle seguenti:
- Colonne ID: utilizzate per identificare ogni esempio univoco.
- Colonne di dati: utilizzate per compilare i modelli di prompt. Consulta Parametri del prompt
- Previsioni pregenerate: previsioni effettuate dallo stesso modello utilizzando lo stesso prompt. L'utilizzo di previsioni pregenerate consente di risparmiare tempo e risorse.
- Preferenze umane basate su dati di fatto: vengono utilizzate per confrontare AutoSxS con le tue preferenze per i dati di fatto quando vengono fornite previsioni pregenerate per entrambi i modelli.
Ecco un esempio di set di dati di valutazione in cui context e question sono colonne di dati e model_b_response contiene previsioni pregenerate.
context |
question |
model_b_response |
|---|---|---|
| Alcuni potrebbero pensare che l'acciaio o il titanio siano i materiali più duri, ma in realtà è il diamante. | Qual è il materiale più duro? | Il diamante è il materiale più duro. È più duro dell'acciaio o del titanio. |
Per saperne di più su come chiamare AutoSxS, consulta Eseguire la valutazione del modello. Per informazioni dettagliate sulla lunghezza del token, vedi Attività e criteri supportati. Per caricare i dati in Cloud Storage, consulta Caricare il set di dati di valutazione in Cloud Storage.
Parametri del prompt
Molti modelli linguistici accettano i parametri del prompt come input anziché una singola stringa di prompt. Ad esempio,
chat-bison accetta
diversi parametri del prompt (messaggi, esempi, contesto), che costituiscono parti
del prompt. Tuttavia, text-bison
ha un solo parametro di prompt, denominato prompt, che contiene l'intero
prompt.
Descriviamo come specificare in modo flessibile i parametri del prompt del modello durante l'inferenza e la valutazione. AutoSxS ti offre la flessibilità di chiamare modelli linguistici con input previsti variabili tramite parametri di prompt basati su modelli.
Inferenza
Se nessuno dei modelli ha previsioni pregenerate, AutoSxS utilizza la previsione batch di Vertex AI per generare le risposte. Devono essere specificati i parametri del prompt di ogni modello.
In AutoSxS, puoi fornire una singola colonna nel set di dati di valutazione come parametro del prompt.
{'some_parameter': {'column': 'my_column'}}
In alternativa, puoi definire modelli utilizzando le colonne del set di dati di valutazione come variabili per specificare i parametri del prompt:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Quando forniscono i parametri del prompt del modello per l'inferenza, gli utenti possono utilizzare la parola chiave
default_instruction protetta come argomento del modello, che viene
sostituita dall'istruzione di inferenza predefinita per l'attività specificata:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Se generi previsioni, fornisci i parametri del prompt del modello e una colonna di output. Vedi i seguenti esempi:
Gemini
Per i modelli Gemini, le chiavi per i parametri del prompt del modello sono
contents (obbligatorio) e system_instruction (facoltativo), che sono in linea con
lo schema del corpo della richiesta Gemini.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Ad esempio, text-bison utilizza "prompt" per l'input e "contenuto" per
l'output. Segui questi
passaggi:
- Identifica gli input e gli output necessari per i modelli in fase di valutazione.
- Definisci gli input come parametri del prompt del modello.
- Passa l'output alla colonna di risposta.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Valutazione
Proprio come devi fornire i parametri del prompt per l'inferenza, devi fornire anche i parametri del prompt per la valutazione. autorater richiede i seguenti parametri del prompt:
| Parametro del prompt dello strumento di valutazione automatica | Configurabile dall'utente? | Descrizione | Esempio |
|---|---|---|---|
| Istruzioni per lo strumento di valutazione automatica | No | Un'istruzione calibrata che descrive i criteri che lo strumento di valutazione automatica deve utilizzare per giudicare le risposte fornite. | Scegli la risposta che risponde alla domanda e segue meglio le istruzioni. |
| Istruzioni per l'inferenza | Sì | Una descrizione dell'attività che ogni modello candidato dovrebbe eseguire. | Rispondi con precisione alla domanda: qual è il materiale più duro? |
| Contesto dell'inferenza | Sì | Contesto aggiuntivo per l'attività che viene eseguita. | Mentre il titanio e il diamante sono entrambi più duri del rame: il diamante ha una durezza di 98, mentre il titanio ha una classificazione di 36. Una classificazione più elevata indica una durezza maggiore. |
| Risposte | No1 | Una coppia di risposte da valutare, una per ogni modello candidato. | Diamante |
1Puoi configurare il parametro del prompt solo tramite risposte pregenerate.
Codice di esempio che utilizza i parametri:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
I modelli A e B possono avere istruzioni di inferenza e contesto formattati in modo diverso, indipendentemente dal fatto che vengano fornite le stesse informazioni. Ciò significa che il sistema di classificazione automatica prende un'istruzione e un contesto di inferenza separati, ma singoli.
Esempio di set di dati di valutazione
Questa sezione fornisce un esempio di set di dati di valutazione per l'attività di domande e risposte,
incluse le previsioni pregenerate per il modello B. In questo esempio, AutoSxS
esegue l'inferenza solo per il modello A. Forniamo una colonna id per distinguere
gli esempi con la stessa domanda e lo stesso contesto.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Best practice
Segui queste best practice quando definisci il set di dati di valutazione:
- Fornisci esempi che rappresentino i tipi di input elaborati dai tuoi modelli in produzione.
- Il set di dati deve includere almeno un esempio di valutazione. Consigliamo circa 100 esempi per garantire metriche aggregate di alta qualità. Il tasso di miglioramenti della qualità delle metriche aggregate tende a diminuire quando vengono forniti più di 400 esempi.
- Per una guida alla scrittura dei prompt, consulta Progettare prompt di testo.
- Se utilizzi previsioni pregenerate per uno dei due modelli, includile in una colonna del set di dati di valutazione. Fornire previsioni pregenerate è utile perché ti consente di confrontare l'output dei modelli che non si trovano in Vertex Model Registry e di riutilizzare le risposte.
Esegui la valutazione del modello
Puoi valutare i modelli utilizzando l'API REST, l'SDK Vertex AI per Python o la consoleGoogle Cloud .
Utilizza questa sintassi per specificare il percorso del modello:
- Modello del publisher:
publishers/PUBLISHER/models/MODELEsempio:publishers/google/models/text-bison Modello ottimizzato:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONEsempio:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Per creare un job di valutazione del modello, invia una richiesta POST utilizzando il metodo
pipelineJobs.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- PIPELINEJOB_DISPLAYNAME : il nome visualizzato per
pipelineJob. - PROJECT_ID : Google Cloud progetto che esegue i componenti della pipeline.
- LOCATION : la regione in cui eseguire i componenti della pipeline.
us-central1è supportato. - OUTPUT_DIR : URI Cloud Storage per archiviare l'output della valutazione.
- EVALUATION_DATASET : tabella BigQuery o elenco separato da virgole di percorsi Cloud Storage a un set di dati JSONL contenente esempi di valutazione.
- TASK : attività di valutazione, che può essere una delle seguenti:
[summarization, question_answering]. - ID_COLUMNS : le colonne che distinguono gli esempi di valutazione univoci.
- AUTORATER_PROMPT_PARAMETERS : parametri del prompt di valutazione automatica mappati su colonne o modelli. I parametri previsti sono:
inference_instruction(dettagli su come eseguire un'attività) einference_context(contenuti a cui fare riferimento per eseguire l'attività). Ad esempio,{'inference_context': {'column': 'my_prompt'}}utilizza la colonna `my_prompt` del set di dati di valutazione per il contesto dell'autorater. - RESPONSE_COLUMN_A : il nome di una colonna nel set di dati di valutazione contenente previsioni predefinite o il nome della colonna nell'output del modello A contenente le previsioni. Se non viene fornito alcun valore, il sistema tenterà di dedurre il nome corretto della colonna di output del modello.
- RESPONSE_COLUMN_B : il nome di una colonna nel set di dati di valutazione contenente previsioni predefinite o il nome della colonna nell'output del modello B contenente previsioni. Se non viene fornito alcun valore, il sistema tenterà di dedurre il nome corretto della colonna di output del modello.
- MODEL_A (facoltativo): un nome della risorsa del modello completo (
projects/{project}/locations/{location}/models/{model}@{version}) o un nome della risorsa del modello del publisher (publishers/{publisher}/models/{model}). Se vengono specificate le risposte del modello A, questo parametro non deve essere fornito. - MODEL_B (Facoltativo): il nome della risorsa del modello completo (
projects/{project}/locations/{location}/models/{model}@{version}) o il nome della risorsa del modello dell'editore (publishers/{publisher}/models/{model}). Se vengono specificate le risposte del modello B, questo parametro non deve essere fornito. - (Facoltativo) MODEL_A_PROMPT_PARAMETERS: parametri del modello di prompt del modello A mappati a colonne o modelli. Se le risposte del modello A sono predefinite, questo parametro non deve essere fornito. Esempio:
{'prompt': {'column': 'my_prompt'}}utilizza la colonnamy_promptdel set di dati di valutazione per il parametro del prompt denominatoprompt. - MODEL_B_PROMPT_PARAMETERS (Facoltativo): parametri del modello di prompt del modello B mappati a colonne o modelli. Se le risposte del modello B sono predefinite, questo parametro non deve essere fornito. Esempio:
{'prompt': {'column': 'my_prompt'}}utilizza la colonnamy_promptdel set di dati di valutazione per il parametro del prompt denominatoprompt. - JUDGMENTS_FORMAT
(facoltativo): il formato in cui scrivere i giudizi. Può essere
jsonl(valore predefinito),jsonobigquery. - BIGQUERY_DESTINATION_PREFIX: tabella BigQuery in cui scrivere i giudizi se il formato specificato è
bigquery.
Corpo JSON della richiesta
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Utilizza curl per inviare la richiesta.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Risposta
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
SDK Vertex AI per Python
Per scoprire come installare o aggiornare l'SDK Vertex AI Python, consulta Installare l'SDK Vertex AI per Python. Per ulteriori informazioni sull'API Python, consulta l'API SDK Vertex AI per Python.
Per saperne di più sui parametri della pipeline, consulta la documentazione di riferimento di Google Cloud Pipeline Components.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- PIPELINEJOB_DISPLAYNAME : il nome visualizzato per
pipelineJob. - PROJECT_ID : Google Cloud progetto che esegue i componenti della pipeline.
- LOCATION : la regione in cui eseguire i componenti della pipeline.
us-central1è supportato. - OUTPUT_DIR : URI Cloud Storage per archiviare l'output della valutazione.
- EVALUATION_DATASET : tabella BigQuery o elenco separato da virgole di percorsi Cloud Storage a un set di dati JSONL contenente esempi di valutazione.
- TASK : attività di valutazione, che può essere una delle seguenti:
[summarization, question_answering]. - ID_COLUMNS : le colonne che distinguono gli esempi di valutazione univoci.
- AUTORATER_PROMPT_PARAMETERS : parametri del prompt di valutazione automatica mappati su colonne o modelli. I parametri previsti sono:
inference_instruction(dettagli su come eseguire un'attività) einference_context(contenuti a cui fare riferimento per eseguire l'attività). Ad esempio,{'inference_context': {'column': 'my_prompt'}}utilizza la colonna `my_prompt` del set di dati di valutazione per il contesto dell'autorater. - RESPONSE_COLUMN_A : il nome di una colonna nel set di dati di valutazione contenente previsioni predefinite o il nome della colonna nell'output del modello A contenente le previsioni. Se non viene fornito alcun valore, il sistema tenterà di dedurre il nome corretto della colonna di output del modello.
- RESPONSE_COLUMN_B : il nome di una colonna nel set di dati di valutazione contenente previsioni predefinite o il nome della colonna nell'output del modello B contenente previsioni. Se non viene fornito alcun valore, il sistema tenterà di dedurre il nome corretto della colonna di output del modello.
- MODEL_A (Facoltativo): il nome della risorsa del modello completo (
projects/{project}/locations/{location}/models/{model}@{version}) o il nome della risorsa del modello del publisher (publishers/{publisher}/models/{model}). Se vengono specificate le risposte del modello A, questo parametro non deve essere fornito. - MODEL_B (Facoltativo): il nome della risorsa del modello completo (
projects/{project}/locations/{location}/models/{model}@{version}) o il nome della risorsa del modello dell'editore (publishers/{publisher}/models/{model}). Se vengono specificate le risposte del modello B, questo parametro non deve essere fornito. - (Facoltativo) MODEL_A_PROMPT_PARAMETERS: parametri del modello di prompt del modello A mappati a colonne o modelli. Se le risposte del modello A sono predefinite, questo parametro non deve essere fornito. Esempio:
{'prompt': {'column': 'my_prompt'}}utilizza la colonnamy_promptdel set di dati di valutazione per il parametro del prompt denominatoprompt. - MODEL_B_PROMPT_PARAMETERS (Facoltativo): parametri del modello di prompt del modello B mappati a colonne o modelli. Se le risposte del modello B sono predefinite, questo parametro non deve essere fornito. Esempio:
{'prompt': {'column': 'my_prompt'}}utilizza la colonnamy_promptdel set di dati di valutazione per il parametro del prompt denominatoprompt. - JUDGMENTS_FORMAT
(facoltativo): il formato in cui scrivere i giudizi. Può essere
jsonl(valore predefinito),jsonobigquery. - BIGQUERY_DESTINATION_PREFIX: tabella BigQuery in cui scrivere i giudizi se il formato specificato è
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Console
Per creare un job di valutazione del modello pairwise utilizzando la console Google Cloud , segui questi passaggi:
Inizia con un modello di base di Google o utilizza un modello già esistente in Vertex AI Model Registry:
Per valutare un modello di base di Google:
Vai a Vertex AI Model Garden e seleziona un modello che supporti la valutazione a coppie, ad esempio
text-bison.Fai clic su Valuta.
Nel menu visualizzato, fai clic su Seleziona per selezionare una versione del modello.
Un riquadro Salva modello potrebbe chiederti di salvare una copia del modello in Vertex AI Model Registry se non ne hai già una. Inserisci un Nome modello e fai clic su Salva.
Viene visualizzata la pagina Crea valutazione. Per il passaggio Metodo di valutazione, seleziona Valuta questo modello rispetto a un altro modello.
Fai clic su Continua.
Per valutare un modello esistente in Vertex AI Model Registry:
Vai alla pagina Vertex AI Model Registry:
Fai clic sul nome del modello da valutare. Assicurati che il tipo di modello supporti la valutazione a coppie. Ad esempio,
text-bison.Nella scheda Valuta, fai clic su SxS.
Fai clic su Crea valutazione affiancata.
Per ogni passaggio della pagina di creazione della valutazione, inserisci le informazioni richieste e fai clic su Continua:
Per il passaggio Set di dati di valutazione, seleziona un obiettivo di valutazione e un modello da confrontare con quello selezionato. Seleziona un set di dati di valutazione e inserisci le colonne ID (colonne di risposta).
Per il passaggio Impostazioni modello, specifica se vuoi utilizzare le risposte del modello già presenti nel set di dati o se vuoi utilizzare la previsione batch di Vertex AI per generare le risposte. Specifica le colonne di risposta per entrambi i modelli. Per l'opzione Vertex AI Batch Prediction, puoi specificare i parametri del prompt del modello di inferenza.
Per il passaggio Impostazioni di Autorater, inserisci i parametri del prompt di Autorater e una posizione di output per le valutazioni.
Fai clic su Inizia valutazione.
Visualizza i risultati di una valutazione
Puoi trovare i risultati della valutazione in Vertex AI Pipelines esaminando i seguenti artefatti prodotti dalla pipeline AutoSxS:
- La tabella giudizi viene prodotta dall'arbitro AutoSxS.
- Le metriche aggregate vengono prodotte dal componente delle metriche AutoSxS.
- Le metriche di allineamento delle preferenze umane vengono prodotte dal componente delle metriche AutoSxS.
Giudizi
AutoSxS genera giudizi (metriche a livello di esempio) che aiutano gli utenti a comprendere il rendimento del modello a livello di esempio. Le sentenze includono le seguenti informazioni:
- Prompt di inferenza
- Risposte del modello
- Decisioni dello strumento di valutazione automatica
- Spiegazioni sulle valutazioni
- Punteggi di confidenza
I giudizi possono essere scritti in Cloud Storage in formato JSONL o in una tabella BigQuery con queste colonne:
| Colonna | Descrizione |
|---|---|
| Colonne ID | Le colonne che distinguono gli esempi di valutazione univoci. |
inference_instruction |
Istruzione utilizzata per generare le risposte del modello. |
inference_context |
Contesto utilizzato per generare le risposte del modello. |
response_a |
Risposta del modello A, date le istruzioni di inferenza e il contesto. |
response_b |
Risposta del modello B, date le istruzioni di inferenza e il contesto. |
choice |
Il modello con la risposta migliore. I valori possibili sono Model A, Model B o Error. Error indica che un errore ha impedito allo strumento di valutazione automatica di determinare se la risposta del modello A o del modello B fosse la migliore. |
confidence |
Un punteggio compreso tra 0 e 1, che indica il livello di confidenza dello strumento di valutazione automatica nella sua scelta. |
explanation |
Il motivo della scelta dell'autorater. |
Metriche aggregate
AutoSxS calcola le metriche aggregate (tasso di vittoria) utilizzando la tabella judgments. Se non vengono forniti dati con preferenze umane, vengono generate le seguenti metriche aggregate:
| Metrica | Descrizione |
|---|---|
| Tasso di vittorie del modello A di AutoRater | Percentuale di casi in cui lo strumento di valutazione automatica ha deciso che il Modello A forniva la risposta migliore. |
| Tasso di vittorie del modello B dello strumento di valutazione automatica | Percentuale di volte in cui lo strumento di valutazione automatica ha deciso che il modello B forniva la risposta migliore. |
Per comprendere meglio il tasso di vincita, esamina i risultati basati sulle righe e le spiegazioni dell'autorater per determinare se i risultati e le spiegazioni sono in linea con le tue aspettative.
Metriche di allineamento delle preferenze umane
Se vengono forniti dati con preferenza umana, AutoSxS restituisce le seguenti metriche:
| Metrica | Descrizione | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tasso di vittorie del modello A di AutoRater | Percentuale di casi in cui lo strumento di valutazione automatica ha deciso che il Modello A forniva la risposta migliore. | ||||||||||||||
| Tasso di vittorie del modello B dello strumento di valutazione automatica | Percentuale di volte in cui lo strumento di valutazione automatica ha deciso che il modello B forniva la risposta migliore. | ||||||||||||||
| Tasso di vittorie del modello A basato sulle preferenze umane | Percentuale di casi in cui i valutatori umani hanno ritenuto che il Modello A fornisse una risposta migliore. | ||||||||||||||
| Percentuale di vincite del modello B con preferenze umane | Percentuale di casi in cui i valutatori umani hanno ritenuto che il Modello B fornisse una risposta migliore. | ||||||||||||||
| VP | Numero di esempi in cui sia lo strumento di valutazione automatica che i valutatori umani hanno indicato che il Modello A forniva la risposta migliore. | ||||||||||||||
| FP | Numero di esempi in cui lo strumento di valutazione automatica ha indicato che il Modello A forniva la risposta migliore, mentre i valutatori umani hanno indicato che il Modello B forniva la risposta migliore. | ||||||||||||||
| VN | Numero di esempi in cui sia lo strumento di valutazione automatica che i valutatori umani hanno indicato che il Modello B forniva la risposta migliore. | ||||||||||||||
| FN | Numero di esempi in cui lo strumento di valutazione automatica ha indicato che il Modello B forniva la risposta migliore, mentre i valutatori umani hanno indicato che il Modello A forniva la risposta migliore. | ||||||||||||||
| Accuratezza | Percentuale di casi in cui lo strumento di valutazione automatica e i valutatori umani erano in accordo. | ||||||||||||||
| Precisione | Percentuale di casi in cui sia lo strumento di valutazione automatica che i valutatori umani hanno ritenuto che il Modello A fornisse una risposta migliore, in rapporto a tutti i casi in cui lo strumento di valutazione automatica pensava che il Modello A fornisse una risposta migliore. | ||||||||||||||
| Richiamo | Percentuale di casi in cui sia lo strumento di valutazione automatica che i valutatori umani hanno ritenuto che il Modello A fornisse una risposta migliore, in rapporto a tutti i casi in cui i valutatori umani pensavano che il Modello A fornisse una risposta migliore. | ||||||||||||||
| F1 | Media armonica di precisione e richiamo. | ||||||||||||||
| Kappa di Cohen | Una misura del grado di concordanza tra lo strumento di valutazione automatica e i valutatori umani che tiene conto della probabilità di una concordanza casuale. Cohen suggerisce la seguente interpretazione:
|
Casi d'uso di AutoSxS
Puoi scoprire come utilizzare AutoSxS con tre scenari di casi d'uso.
Confrontare i modelli
Valuta un modello proprietario (1p) ottimizzato rispetto a un modello proprietario di riferimento.
Puoi specificare che l'inferenza venga eseguita su entrambi i modelli contemporaneamente.
Questo esempio di codice valuta un modello ottimizzato da Vertex Model Registry rispetto a un modello di riferimento dello stesso registro.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Confronta previsioni
Valuta un modello ottimizzato di terze parti rispetto a un modello di riferimento di terze parti.
Puoi saltare l'inferenza fornendo direttamente le risposte del modello.
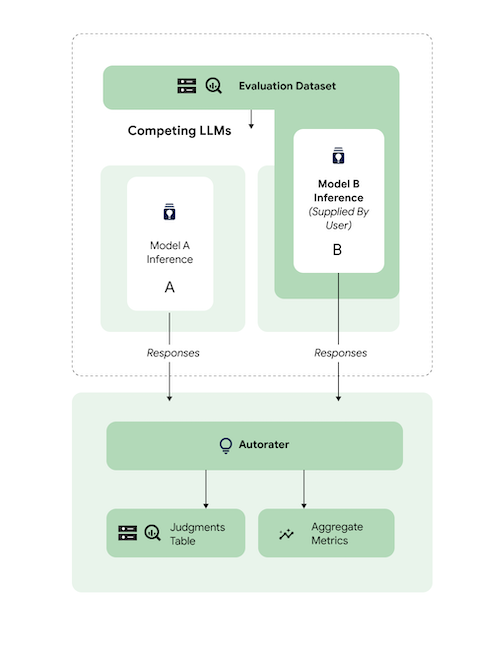
Questo esempio di codice valuta un modello di terze parti ottimizzato rispetto a un modello di terze parti di riferimento.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Controllare l'allineamento
Tutte le attività supportate sono state sottoposte a benchmark utilizzando i dati dei valutatori umani per garantire che le risposte dello strumento di valutazione automatica siano in linea con le preferenze umane. Se vuoi confrontare AutoSxS per i tuoi casi d'uso, fornisci i dati delle preferenze umane direttamente ad AutoSxS, che restituisce statistiche aggregate di allineamento.
Per verificare l'allineamento rispetto a un set di dati con le preferenze umane, puoi specificare entrambi gli output (risultati della previsione) per l'autorater. Puoi anche fornire i risultati dell'inferenza.
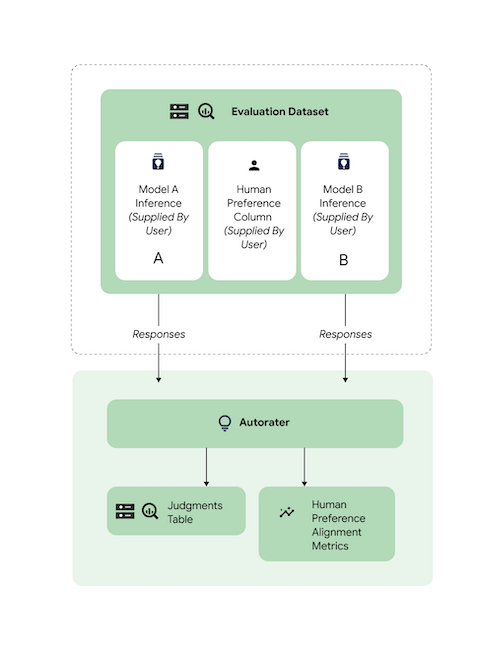
Questo esempio di codice verifica che i risultati e le spiegazioni dell'autorater corrispondano alle tue aspettative.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
Passaggi successivi
- Scopri di più sulla valutazione dell'AI generativa.
- Scopri di più sulla valutazione online con Gen AI Evaluation Service.
- Scopri come ottimizzare i modelli di base del linguaggio.