Model embedding Vertex AI dapat menghasilkan embedding yang dioptimalkan untuk berbagai jenis tugas, seperti pengambilan dokumen, tanya jawab, dan verifikasi fakta. Jenis tugas adalah label yang mengoptimalkan embedding yang dihasilkan model berdasarkan kasus penggunaan yang Anda inginkan. Dokumen ini menjelaskan cara memilih jenis tugas yang optimal untuk penyematan Anda.
Model yang didukung
Jenis tugas didukung oleh model berikut:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Manfaat jenis tugas
Jenis tugas dapat meningkatkan kualitas embedding yang dihasilkan oleh model embedding.
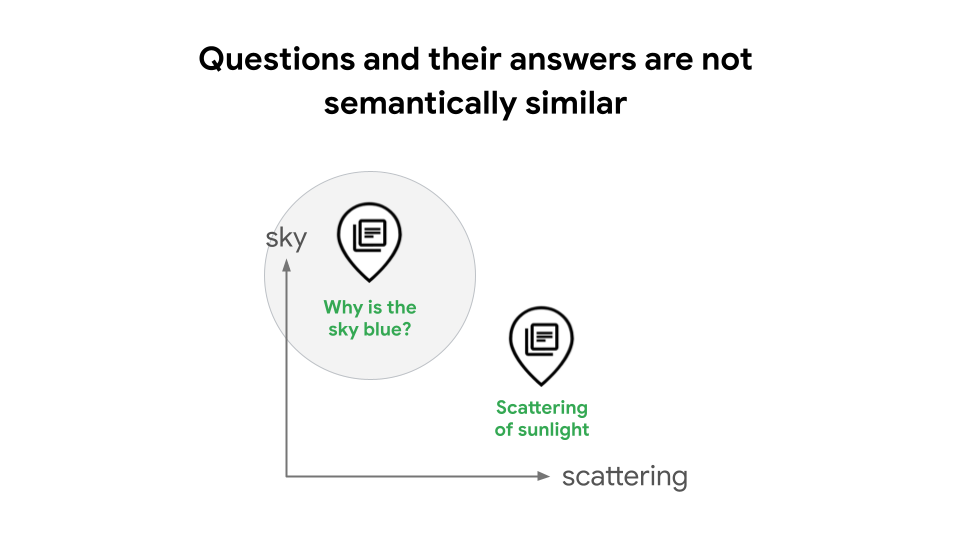
Misalnya, saat membangun sistem Retrieval Augmented Generation (RAG), desain umum adalah menggunakan penyematan teks dan Vector Search untuk melakukan penelusuran kesamaan. Dalam beberapa kasus, hal ini dapat menurunkan kualitas penelusuran, karena pertanyaan dan jawabannya tidak serupa secara semantik. Misalnya, pertanyaan seperti "Mengapa langit berwarna biru?" dan jawabannya "Hamburan sinar matahari menyebabkan warna biru", memiliki makna yang sangat berbeda sebagai pernyataan, yang berarti bahwa sistem RAG tidak akan otomatis mengenali hubungannya, seperti yang ditunjukkan pada gambar 1. Tanpa jenis tugas, developer RAG harus melatih modelnya untuk mempelajari hubungan antara kueri dan jawaban yang memerlukan keterampilan dan pengalaman ilmu data tingkat lanjut, atau menggunakan perluasan kueri berbasis LLM atau HyDE yang dapat menyebabkan latensi dan biaya yang tinggi.
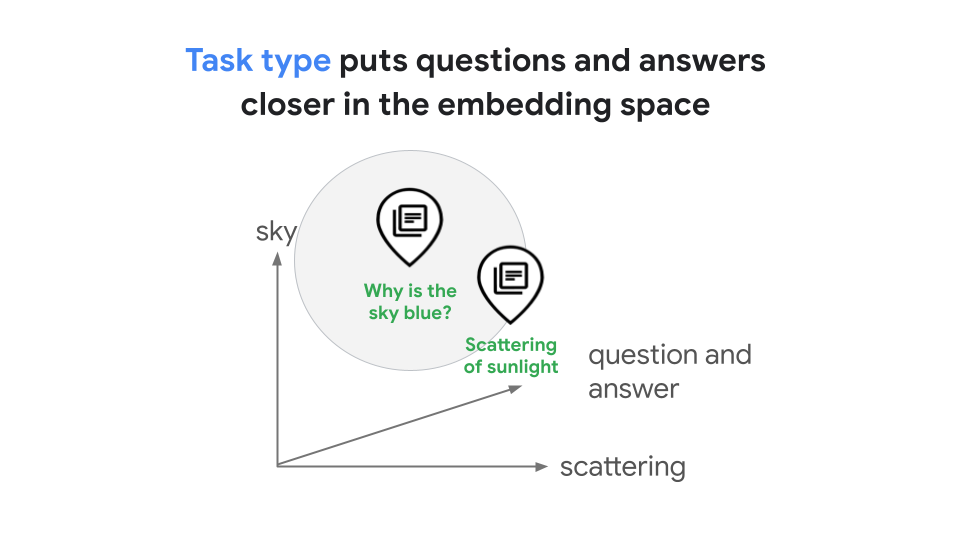
Jenis tugas memungkinkan Anda membuat embedding yang dioptimalkan untuk tugas tertentu, sehingga menghemat waktu dan biaya yang diperlukan untuk mengembangkan embedding khusus tugas Anda sendiri. Penyematan yang dihasilkan untuk kueri "Mengapa langit berwarna biru?" dan jawabannya "Hamburan sinar matahari menyebabkan warna biru" akan berada di ruang penyematan bersama yang merepresentasikan hubungan di antara keduanya, seperti yang ditunjukkan pada gambar 2. Dalam contoh RAG ini, embedding yang dioptimalkan akan menghasilkan penelusuran kesamaan yang lebih baik.
Selain kasus penggunaan kueri dan jawaban, jenis tugas juga menyediakan ruang penyematan yang dioptimalkan untuk tugas seperti klasifikasi, pengelompokan, dan verifikasi fakta.
Jenis tugas yang didukung
Model embedding yang menggunakan jenis tugas mendukung jenis tugas berikut:
| Jenis tugas | Deskripsi |
|---|---|
CLASSIFICATION |
Digunakan untuk membuat embedding yang dioptimalkan untuk mengklasifikasikan teks menurut label preset |
CLUSTERING |
Digunakan untuk membuat embedding yang dioptimalkan untuk mengelompokkan teks berdasarkan kemiripannya |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING, dan FACT_VERIFICATION |
Digunakan untuk membuat embedding yang dioptimalkan untuk penelusuran dokumen atau pengambilan informasi |
CODE_RETRIEVAL_QUERY |
Digunakan untuk mengambil blok kode berdasarkan kueri natural language, seperti mengurutkan array atau membalikkan daftar tertaut. Embedding blok kode dihitung menggunakan RETRIEVAL_DOCUMENT. |
SEMANTIC_SIMILARITY |
Digunakan untuk membuat embedding yang dioptimalkan untuk menilai kesamaan teks. Fitur ini tidak ditujukan untuk kasus penggunaan pengambilan. |
Jenis tugas terbaik untuk tugas penyematan Anda bergantung pada kasus penggunaan yang Anda miliki untuk penyematan Anda. Sebelum memilih jenis tugas, tentukan kasus penggunaan sematan Anda.
Menentukan kasus penggunaan sematan Anda
Kasus penggunaan embedding biasanya termasuk dalam salah satu dari empat kategori: menilai kesamaan teks, mengklasifikasikan teks, mengelompokkan teks, atau mengambil informasi dari teks. Jika kasus penggunaan Anda tidak termasuk dalam salah satu kategori di atas,
gunakan jenis tugas RETRIEVAL_QUERY secara default.
Ada 2 jenis format petunjuk tugas, format asimetris dan format simetris. Anda harus menggunakan yang benar berdasarkan kasus penggunaan Anda.
| Kasus penggunaan pengambilan (Format Asimetris) |
Jenis tugas kueri | Jenis tugas dokumen |
|---|---|---|
| Kueri Penelusuran | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Penjawaban Pertanyaan | QUESTION_ANSWERING | |
| Pengecekan Fakta | FACT_VERIFICATION | |
| Pengambilan Kode | CODE_RETRIEVAL_QUERY |
| Kasus Penggunaan Input Tunggal (Format Simetris) |
Jenis tugas input |
|---|---|
| Klasifikasi | KLASIFIKASI |
| Pengelompokan | PENGELOMPOKAN |
| Kemiripan Semantik (Jangan gunakan untuk kasus penggunaan pengambilan; ditujukan untuk STS) |
SEMANTIC_SIMILARITY |
Mengklasifikasikan teks
Jika Anda ingin menggunakan embedding untuk mengklasifikasikan teks menurut label preset, gunakan
jenis tugas CLASSIFICATION. Jenis tugas ini menghasilkan embedding di ruang embedding yang dioptimalkan untuk klasifikasi.
Misalnya, Anda ingin membuat penyematan untuk postingan media sosial yang kemudian dapat Anda gunakan untuk mengklasifikasikan sentimennya sebagai positif, negatif, atau netral. Saat sematan untuk postingan media sosial yang berbunyi "Saya tidak suka bepergian dengan pesawat" diklasifikasikan, sentimennya akan diklasifikasikan sebagai negatif.
Teks cluster
Jika Anda ingin menggunakan embedding untuk mengelompokkan teks berdasarkan kesamaannya, gunakan jenis tugas CLUSTERING. Jenis tugas ini menghasilkan penyematan yang dioptimalkan untuk dikelompokkan berdasarkan kesamaannya.
Misalnya, Anda ingin membuat penyematan untuk artikel berita sehingga Anda dapat menampilkan artikel yang terkait secara topikal dengan artikel yang sebelumnya dibaca pengguna. Setelah penyematan dibuat dan dikelompokkan, Anda dapat menyarankan artikel terkait olahraga tambahan kepada pengguna yang banyak membaca artikel tentang olahraga.
Kasus penggunaan tambahan untuk pengelompokan mencakup hal berikut:
- Segmentasi pelanggan: mengelompokkan pelanggan dengan sematan serupa yang dihasilkan dari profil atau aktivitas mereka untuk pemasaran yang ditargetkan dan pengalaman yang dipersonalisasi.
- Segmentasi produk: mengelompokkan sematan produk berdasarkan judul dan deskripsi produk, gambar produk, atau ulasan pelanggan dapat membantu bisnis melakukan analisis segmen pada produk mereka.
- Riset pasar: pengelompokan respons survei konsumen atau data media sosial dapat mengungkapkan pola dan tren tersembunyi dalam pendapat, preferensi, dan perilaku konsumen, sehingga membantu upaya riset pasar dan mendasari strategi pengembangan produk.
- Layanan kesehatan: pengelompokan sematan pasien yang berasal dari data medis dapat membantu mengidentifikasi kelompok dengan kondisi atau respons pengobatan yang serupa, sehingga menghasilkan rencana perawatan kesehatan yang lebih dipersonalisasi dan terapi yang ditargetkan.
- Tren masukan pelanggan: mengelompokkan masukan pelanggan dari berbagai saluran (survei, media sosial, tiket dukungan) ke dalam grup dapat membantu mengidentifikasi kesulitan umum, permintaan fitur, dan area untuk peningkatan produk.
Mengambil informasi dari teks
Saat membangun sistem penelusuran atau pengambilan, Anda bekerja dengan dua jenis teks:
- Corpus: Kumpulan dokumen yang ingin Anda telusuri.
- Kueri: Teks yang diberikan pengguna untuk menelusuri informasi dalam korpus.
Untuk mendapatkan performa terbaik, Anda harus menggunakan berbagai jenis tugas untuk membuat sematan untuk korpus dan kueri Anda.
Pertama, buat embedding untuk seluruh koleksi dokumen Anda. Ini adalah
konten yang akan diambil oleh kueri pengguna. Saat menyematkan dokumen ini,
gunakan jenis tugas RETRIEVAL_DOCUMENT. Biasanya Anda melakukan langkah ini satu kali untuk mengindeks seluruh korpus, lalu menyimpan embedding yang dihasilkan dalam database vektor.
Selanjutnya, saat pengguna mengirimkan penelusuran, Anda akan membuat penyematan untuk teks kueri mereka secara real time. Untuk itu, Anda harus menggunakan jenis tugas yang sesuai dengan maksud pengguna. Sistem Anda kemudian akan menggunakan embedding kueri ini untuk menemukan embedding dokumen yang paling mirip dalam database vektor Anda.
Jenis tugas berikut digunakan untuk kueri:
RETRIEVAL_QUERY: Gunakan ini untuk kueri penelusuran standar jika Anda ingin menemukan dokumen yang relevan. Model mencari embedding dokumen yang secara semantik dekat dengan embedding kueri.QUESTION_ANSWERING: Gunakan ini jika semua kueri diharapkan berupa pertanyaan yang tepat, seperti "Mengapa langit berwarna biru?" atau "Bagaimana cara mengikat tali sepatu?".FACT_VERIFICATION: Gunakan ini saat Anda ingin mengambil dokumen dari korpus yang membuktikan atau menyangkal pernyataan. Misalnya, kueri "apel tumbuh di bawah tanah" dapat mengambil artikel tentang apel yang pada akhirnya akan menyangkal pernyataan tersebut.
Pertimbangkan skenario dunia nyata berikut yang menunjukkan kegunaan kueri pengambilan:
- Untuk platform e-commerce, Anda ingin menggunakan sematan untuk memungkinkan pengguna menelusuri produk menggunakan kueri teks dan gambar, sehingga memberikan pengalaman berbelanja yang lebih intuitif dan menarik.
- Untuk platform pendidikan, Anda ingin membangun sistem tanya jawab yang dapat menjawab pertanyaan siswa berdasarkan konten buku teks atau sumber daya pendidikan, memberikan pengalaman belajar yang dipersonalisasi, dan membantu siswa memahami konsep yang kompleks.
Pengambilan Kode
text-embedding-005 mendukung jenis tugas baru CODE_RETRIEVAL_QUERY,
yang dapat digunakan untuk mengambil blok kode yang relevan menggunakan kueri teks biasa. Untuk menggunakan fitur ini, blok kode harus disematkan menggunakan jenis tugas RETRIEVAL_DOCUMENT, sedangkan kueri teks disematkan menggunakan CODE_RETRIEVAL_QUERY.
Untuk mempelajari semua jenis tugas, lihat referensi model.
Berikut ini contohnya:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
Untuk mempelajari cara menginstal atau mengupdate Vertex AI SDK untuk Python, lihat Menginstal Vertex AI SDK untuk Python. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python.
Menilai kemiripan teks
Jika Anda ingin menggunakan embedding untuk menilai kemiripan teks, gunakan jenis tugas
SEMANTIC_SIMILARITY. Jenis tugas ini menghasilkan sematan yang dioptimalkan untuk menghasilkan skor kesamaan.
Misalnya, Anda ingin membuat embedding untuk digunakan dalam membandingkan kemiripan teks berikut:
- Kucing sedang tidur
- Kucing sedang tidur siang
Saat embedding digunakan untuk membuat skor kesamaan, skor kesamaan akan tinggi, karena kedua teks memiliki makna yang hampir sama.
Pertimbangkan skenario dunia nyata berikut yang menunjukkan manfaat penilaian kesamaan input:
- Untuk sistem rekomendasi, Anda ingin mengidentifikasi item (misalnya, produk, artikel, film) yang mirip secara semantik dengan item pilihan pengguna, memberikan rekomendasi yang dipersonalisasi, dan meningkatkan kepuasan pengguna.
Batasan berikut berlaku saat menggunakan model ini:
- Jangan gunakan model pratinjau ini pada sistem produksi atau yang penting.
- Model ini hanya tersedia dalam bahasa
us-central1. - Prediksi batch tidak didukung.
- Penyesuaian tidak didukung.
Langkah berikutnya
- Pelajari cara mendapatkan embedding teks.