Nachdem Sie einen Agent entwickelt haben, können Sie mit dem Bewertungsdienst basierend auf generativer KI die Fähigkeit des Agents bewerten, Aufgaben und Ziele für einen bestimmten Anwendungsfall zu erfüllen.
Bewertungsmesswerte definieren
Beginnen Sie mit einer leeren Liste von Messwerten (d.h. metrics = []) und fügen Sie die relevanten Messwerte hinzu. So fügen Sie weitere Messwerte hinzu:
Endgültige Antwort
Die endgültige Reaktionsbewertung folgt demselben Prozess wie die modellbasierte Bewertung. Weitere Informationen finden Sie unter Bewertungsmesswerte definieren.
Genaue Übereinstimmung
metrics.append("trajectory_exact_match")
Wenn die vorhergesagte Trajektorie mit der Referenz-Trajektorie identisch ist und die Tool-Aufrufe in derselben Reihenfolge erfolgen, gibt der Messwert trajectory_exact_match den Wert 1 zurück, andernfalls 0.
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Übereinstimmung in der richtigen Reihenfolge
metrics.append("trajectory_in_order_match")
Wenn der vorhergesagte Pfad alle Tool-Aufrufe aus dem Referenzpfad in derselben Reihenfolge enthält und möglicherweise zusätzliche Tool-Aufrufe vorhanden sind, wird für den trajectory_in_order_match-Messwert der Wert 1 zurückgegeben, andernfalls 0.
Eingabeparameter:
predicted_trajectory: Die vom Agent verwendete vorhergesagte Entwicklung, um die endgültige Antwort zu erreichen.reference_trajectory: Die erwartete vorhergesagte Trajektorie für den Agenten, um die Anfrage zu erfüllen.
Übereinstimmung in beliebiger Reihenfolge
metrics.append("trajectory_any_order_match")
Wenn der vorhergesagte Pfad alle Tool-Aufrufe aus dem Referenzpfad enthält, die Reihenfolge jedoch keine Rolle spielt und zusätzliche Tool-Aufrufe enthalten sein können, gibt die Messwert trajectory_any_order_match den Wert 1 zurück, andernfalls 0.
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Precision
metrics.append("trajectory_precision")
Der Messwert trajectory_precision gibt an, wie viele der Tool-Aufrufe im vorhergesagten Pfad gemäß dem Referenzpfad tatsächlich relevant oder korrekt sind. Es handelt sich um einen float-Wert im Bereich von [0, 1]. Je höher der Wert, desto genauer ist die vorhergesagte Flugbahn.
Die Genauigkeit wird so berechnet: Zählen Sie, wie viele Aktionen im vorhergesagten Pfad auch im Referenzpfad vorkommen. Teilen Sie diese Anzahl durch die Gesamtzahl der Aktionen im vorhergesagten Verlauf.
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Recall
metrics.append("trajectory_recall")
Der Messwert trajectory_recall gibt an, wie viele der wichtigen Tool-Aufrufe aus dem Referenzpfad tatsächlich im vorhergesagten Pfad erfasst werden. Es handelt sich um einen float-Wert im Bereich von [0, 1]. Je höher der Wert, desto besser der Recall der vorhergesagten Flugbahn.
Der Recall wird so berechnet: Zählen Sie, wie viele Aktionen im Referenz-Trajekt auch im vorhergesagten Trajekt vorkommen. Teilen Sie diese Anzahl durch die Gesamtzahl der Aktionen im Referenzpfad.
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Verwendung eines einzelnen Tools
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
Mit dem Messwert trajectory_single_tool_use wird geprüft, ob ein bestimmtes Tool, das in der Messwertspezifikation angegeben ist, im vorhergesagten Verlauf verwendet wird. Es wird nicht geprüft, in welcher Reihenfolge die Tool-Aufrufe erfolgen oder wie oft das Tool verwendet wird, sondern nur, ob es vorhanden ist. Der Wert ist 0, wenn das Tool nicht vorhanden ist, andernfalls 1.
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.
Benutzerdefiniert
So definieren Sie einen benutzerdefinierten Messwert:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
Die folgenden beiden Leistungsmesswerte sind immer in den Ergebnissen enthalten. Sie müssen sie nicht in EvalTask angeben:
latency(float): Zeit, die der Agent für die Antwort benötigt hat (in Sekunden).failure(bool):0, wenn der Agent-Aufruf erfolgreich war, andernfalls1.
Bewertungs-Dataset vorbereiten
So bereiten Sie Ihr Dataset für die Bewertung der endgültigen Antwort oder des Pfads vor:
Endgültige Antwort
Das Datenschema für die Bewertung der endgültigen Antwort ähnelt dem für die Bewertung der Modellantwort.
Genaue Übereinstimmung
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Übereinstimmung in der richtigen Reihenfolge
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die vom Agent verwendete vorhergesagte Entwicklung, um die endgültige Antwort zu erreichen.reference_trajectory: Die erwartete vorhergesagte Trajektorie für den Agenten, um die Anfrage zu erfüllen.
Übereinstimmung in beliebiger Reihenfolge
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Precision
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Recall
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.reference_trajectory: Die erwartete Tool-Nutzung des KI-Agents, um die Anfrage zu erfüllen.
Verwendung eines einzelnen Tools
Das Bewertungs-Dataset muss die folgenden Eingaben enthalten:
Eingabeparameter:
predicted_trajectory: Die Liste der Toolaufrufe, die vom KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten.
Im Folgenden finden Sie ein Beispiel für ein Bewertungs-Dataset.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Beispieldatasets
Wir haben die folgenden Beispieldatasets bereitgestellt, um zu zeigen, wie Sie Agents bewerten können:
"on-device": Bewertungs-Dataset für einen On-Device Home Assistant. Der Agent hilft bei Anfragen wie „Stelle die Klimaanlage im Schlafzimmer so ein, dass sie zwischen 23:00 Uhr und 8:00 Uhr eingeschaltet und die restliche Zeit ausgeschaltet ist.“"customer-support": Bewertungs-Dataset für einen Kundensupport-Agenten. Der Kundenservicemitarbeiter hilft bei Anfragen wie „Kannst du alle ausstehenden Bestellungen stornieren und alle offenen Support-Tickets eskalieren?“"content-creation": Evaluationsdataset für einen Agenten zur Erstellung von Marketinginhalten. Der Agent kann bei Anfragen wie „Verschiebe Kampagne X auf den 25. Dezember 2024 und richte sie als einmalige Kampagne auf der Social-Media-Website Y mit einem um 50% reduzierten Budget ein.“ helfen.
So importieren Sie die Beispiel-Datasets:
Installieren und initialisieren Sie die
gcloud-Befehlszeile.Laden Sie das Bewertungs-Dataset herunter.
Auf dem Gerät
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Kundensupport
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Erstellung von Inhalten
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Dataset-Beispiele laden
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Bewertungsergebnisse generieren
Führen Sie den folgenden Code aus, um die Bewertungsergebnisse zu generieren:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
Ergebnisse ansehen und interpretieren
Die Bewertungsergebnisse werden so angezeigt:
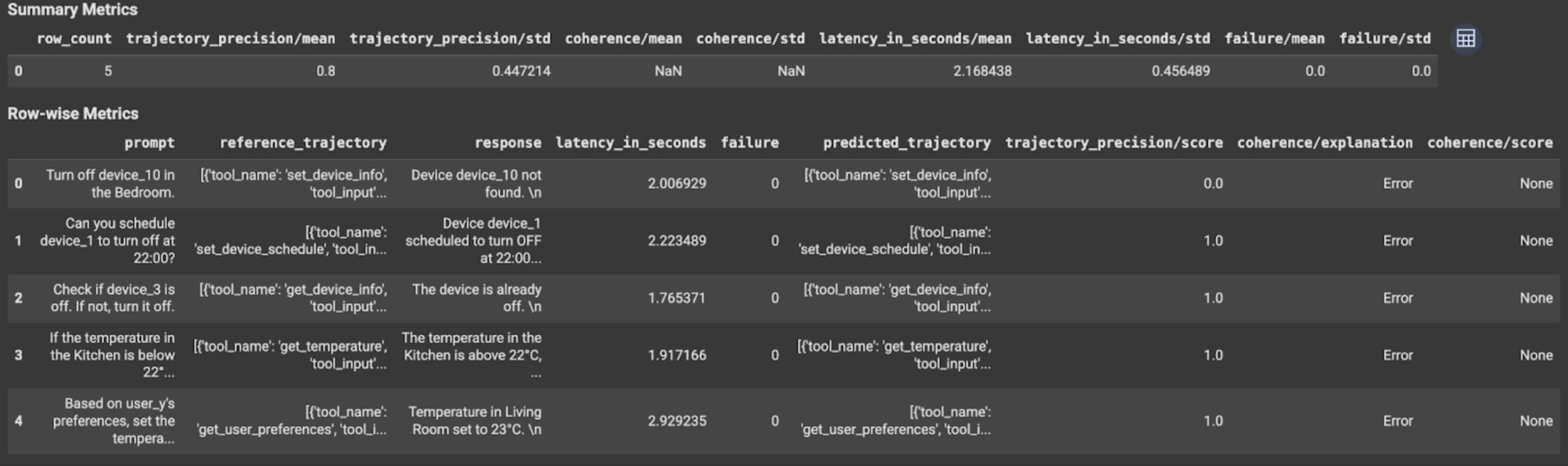
Die Auswertungsergebnisse enthalten die folgenden Informationen:
Messwerte für die endgültige Antwort
Messwerte auf Zeilenebene:
response: Die endgültige Antwort, die vom Agent generiert wurde.latency_in_seconds: Die Zeit, die zum Generieren der Antwort benötigt wurde (in Sekunden).failure: Gibt an, ob eine gültige Antwort generiert wurde oder nicht.score: Ein Wert, der für die in der Messwertspezifikation angegebene Antwort berechnet wird.explanation: Die Erklärung für den in der Messwertspezifikation angegebenen Wert.
Zusammenfassende Messwerte:
mean: Durchschnittliche Punktzahl für alle Instanzen.standard deviation: Standardabweichung aller Punktzahlen.
Messwerte für den Verlauf
Messwerte auf Zeilenebene:
predicted_trajectory: Sequenz von Toolaufrufen, die vom KI-Agenten ausgeführt werden, um die endgültige Antwort zu erhalten.reference_trajectory: Sequenz der erwarteten Tool-Aufrufe.score: Ein Wert, der für die in der Messwertspezifikation angegebene vorhergesagte und Referenztrajektorie berechnet wird.latency_in_seconds: Die Zeit, die zum Generieren der Antwort benötigt wurde (in Sekunden).failure: Gibt an, ob eine gültige Antwort generiert wurde oder nicht.
Zusammenfassende Messwerte:
mean: Durchschnittliche Punktzahl für alle Instanzen.standard deviation: Standardabweichung aller Punktzahlen.
Nächste Schritte
Probieren Sie die folgenden Notebooks aus: