Dokumen ini adalah bagian ketiga dari rangkaian yang membahas pemulihan bencana (DR) di Google Cloud. Bagian ini membahas skenario untuk mencadangkan dan memulihkan data.
Seri ini terdiri dari bagian-bagian berikut:
- Panduan perencanaan pemulihan dari bencana
- Elemen penyusun pemulihan dari bencana
- Skenario pemulihan dari bencana untuk data (dokumen ini)
- Skenario pemulihan dari bencana untuk aplikasi
- Merancang pemulihan dari bencana untuk workload yang dibatasi lokalitas
- Kasus penggunaan pemulihan dari bencana: aplikasi analisis data yang dibatasi lokalitas
- Merancang pemulihan dari bencana untuk pemadaman infrastruktur cloud
Pengantar
Rencana pemulihan dari bencana Anda harus menentukan cara menghindari kehilangan data selama bencana. Istilah data di sini mencakup dua skenario. Mencadangkan lalu memulihkan database, data log, dan jenis data lainnya sesuai dengan salah satu skenario berikut:
- Pencadangan data. Mencadangkan data saja melibatkan penyalinan sejumlah data berbeda dari satu tempat ke tempat lain. Cadangan dibuat sebagai bagian dari rencana pemulihan, baik untuk pemulihan dari kerusakan data sehingga Anda dapat memulihkannya ke keadaan baik yang telah diketahui langsung di lingkungan produksi, atau sehingga Anda dapat memulihkan data di lingkungan DR jika lingkungan produksi Anda sedang tidak beroperasi. Biasanya, cadangan data memiliki RTO kecil hingga sedang dan RPO yang kecil.
- Pencadangan database. Pencadangan database sedikit lebih kompleks, karena biasanya melibatkan pemulihan ke titik waktu tertentu. Oleh karena itu, selain mempertimbangkan cara mencadangkan dan memulihkan cadangan database dan memastikan pemulihan sistem database mencerminkan konfigurasi produksi (versi yang sama, konfigurasi disk yang diduplikasi), Anda juga harus mempertimbangkan cara mencadangkan log transaksi. Selama pemulihan, setelah memulihkan fungsi database, Anda harus menerapkan pencadangan database terbaru, lalu log transaksi yang telah dipulihkan, yang dicadangkan setelah pencadangan terakhir. Karena faktor-faktor yang memperumit yang melekat pada sistem database (misalnya, harus mencocokkan versi antara sistem produksi dan pemulihan), mengadopsi pendekatan yang mengutamakan ketersediaan tinggi untuk meminimalkan waktu pemulihan dari situasi yang dapat menyebabkan server database tidak tersedia memungkinkan Anda mencapai nilai RTO dan RPO yang lebih kecil.
Saat menjalankan workload produksi di Google Cloud, Anda dapat menggunakan sistem yang didistribusikan secara global. Jadi, jika terjadi masalah di satu region, aplikasi akan terus menyediakan layanan meskipun layanannya kurang luas. Intinya, aplikasi tersebut memanggil rencana DR-nya.
Bagian selanjutnya dari dokumen ini membahas contoh cara mendesain beberapa skenario untuk data dan database yang dapat membantu Anda memenuhi sasaran RTO dan RPO.
Lingkungan produksi tersedia di infrastruktur lokal
Dalam skenario ini, lingkungan produksi Anda tersedia di infrastruktur lokal, dan rencana pemulihan dari bencana Anda melibatkan penggunaan Google Cloud sebagai situs pemulihan.
Pencadangan dan pemulihan data
Anda dapat menggunakan sejumlah strategi untuk menerapkan proses pencadangan data secara rutin dari infrastruktur lokal ke Google Cloud. Bagian ini membahas dua solusi yang paling umum.
Solusi 1: Cadangkan data ke Cloud Storage menggunakan tugas terjadwal
Pola ini menggunakan komponen penyusun DR berikut:
- Cloud Storage
Salah satu opsi untuk mencadangkan data adalah membuat tugas terjadwal yang menjalankan skrip atau aplikasi untuk mentransfer data ke Cloud Storage. Anda dapat mengotomatiskan proses pencadangan ke Cloud Storage menggunakan perintah Google Cloud CLI gcloud storage atau menggunakan salah satu library klien Cloud Storage.
Misalnya, perintah gcloud storage berikut menyalin semua file dari direktori sumber ke bucket yang telah ditentukan.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Ganti SOURCE_DIRECTORY dengan jalur ke direktori sumber Anda
dan BUCKET_NAME dengan nama pilihan Anda untuk bucket.
Nama harus memenuhi persyaratan nama bucket.
Langkah-langkah berikut menjelaskan cara menerapkan proses pencadangan dan pemulihan
menggunakan perintah gcloud storage.
- Instal
gcloud CLIdi komputer lokal tempat Anda mengupload file data. - Buat bucket sebagai target pencadangan data Anda.
- Membuat akun layanan
- Buat
kebijakan IAM
untuk membatasi siapa yang dapat mengakses bucket dan objeknya. Sertakan akun layanan yang dibuat khusus untuk tujuan ini. Untuk mengetahui detail tentang izin akses ke Cloud Storage, lihat Izin IAM untuk
gcloud storage. - Gunakan Peniruan identitas akun layanan untuk memberikan akses bagi pengguna (atau akun layanan) lokal Anda untuk meniru identitas akun layanan yang baru saja Anda buat sebelumnya. Google CloudAtau, Anda dapat membuat pengguna baru khusus untuk tujuan ini.
- Uji apakah Anda dapat mengupload dan mendownload file di bucket target.
- Siapkan jadwal untuk skrip yang Anda gunakan untuk mengupload cadangan menggunakan alat seperti
crontabLinux dan Task Scheduler Windows. - Konfigurasi proses pemulihan yang menggunakan perintah
gcloud storageuntuk memulihkan data Anda ke lingkungan pemulihan DR di Google Cloud.
Anda juga dapat menggunakan perintah gcloud storage rsync untuk melakukan sinkronisasi bertahap secara real-time antara data Anda dan bucket Cloud Storage.
Misalnya, perintah gcloud storage rsync berikut membuat konten di bucket Cloud Storage menjadi sama dengan konten di direktori sumber dengan menyalin file atau objek yang hilang, atau yang datanya telah berubah. Jika volume data yang telah berubah di antara sesi pencadangan berurutan relatif kecil terhadap seluruh volume data sumber, maka penggunaan gcloud storage rsync dapat lebih efisien daripada perintah gcloud storage cp. Dengan menggunakan gcloud storage rsync, Anda dapat menerapkan jadwal pencadangan yang lebih sering dan mencapai RPO yang lebih rendah.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Untuk informasi selengkapnya, lihat
perintah gcloud storage untuk transfer data lokal yang lebih kecil.
Solusi 2: Cadangkan ke Cloud Storage menggunakan Transfer Service untuk data lokal
Pola ini menggunakan komponen penyusun DR berikut:
- Cloud Storage
- Transfer Service untuk data lokal
Mentransfer data dalam jumlah besar melalui jaringan sering kali memerlukan perencanaan yang cermat dan strategi eksekusi yang andal. Mengembangkan skrip khusus yang skalabel, andal, dan mudah dipelihara bukanlah tugas yang mudah. Skrip khusus sering kali dapat mengakibatkan penurunan nilai RPO dan bahkan peningkatan risiko kehilangan data.
Untuk mendapatkan panduan tentang cara memindahkan data dalam volume besar dari lokasi lokal ke Cloud Storage, lihat Memindahkan atau mencadangkan data dari penyimpanan lokal.
Solusi 3: Cadangkan ke Cloud Storage menggunakan solusi gateway partner
Pola ini menggunakan komponen penyusun DR berikut:
- Cloud Interconnect
- Penyimpanan bertingkat Cloud Storage
Aplikasi lokal sering kali terintegrasi dengan solusi pihak ketiga yang dapat digunakan sebagai bagian dari strategi pencadangan dan pemulihan data Anda. Solusinya sering menggunakan pola penyimpanan bertingkat di mana Anda menyimpan cadangan terbaru di penyimpanan yang lebih cepat, dan perlahan memindahkan cadangan lama ke penyimpanan yang lebih murah (lebih lambat). Saat menggunakan Google Cloud sebagai target, Anda memiliki beberapa opsi kelas penyimpanan yang tersedia untuk digunakan yang setara dengan tingkatan yang lebih lambat.
Salah satu cara untuk menerapkan pola ini adalah menggunakan gateway partner antara penyimpanan lokal Anda dan Google Cloud untuk memfasilitasi transfer data ke Cloud Storage. Diagram berikut menunjukkan pengaturan tersebut, dengan solusi partner yang mengelola transfer dari perangkat NAS lokal atau SAN.

Jika terjadi kegagalan, data yang sedang dicadangkan harus dipulihkan ke lingkungan DR Anda. Lingkungan DR digunakan untuk menyajikan traffic produksi hingga Anda dapat kembali ke lingkungan produksi. Cara mencapainya bergantung pada aplikasi Anda, serta solusi partner dan arsitekturnya. (Beberapa skenario yang menyeluruh dibahas dalam dokumen aplikasi DR.)
Anda juga dapat menggunakan database Google Cloud terkelola sebagai tujuan DR Anda. Misalnya, Cloud SQL untuk SQL Server mendukung impor log transaksi. Anda dapat mengekspor log transaksi dari instance SQL Server lokal, menguploadnya ke Cloud Storage, dan mengimpornya ke Cloud SQL untuk SQL Server.
Untuk panduan lebih lanjut mengenai cara mentransfer data dari infrastruktur lokal ke Google Cloud, lihat Mentransfer set data besar ke Google Cloud.
Untuk informasi selengkapnya tentang solusi partner, lihat halaman Partner di situs Google Cloud .
Pencadangan dan pemulihan database
Anda dapat menggunakan sejumlah strategi untuk menerapkan proses pemulihan sistem database dari infrastruktur lokal ke Google Cloud. Bagian ini membahas dua solusi yang paling umum.
Dokumen ini tidak mencakup pembahasan secara mendetail berbagai mekanisme pencadangan dan pemulihan bawaan yang disertakan dalam database pihak ketiga. Bagian ini memberikan panduan umum, yang diimplementasikan dalam solusi yang dibahas di sini.
Solusi 1: Pencadangan dan pemulihan menggunakan server pemulihan di Google Cloud
- Buat cadangan database menggunakan mekanisme pencadangan bawaan dari sistem pengelolaan database Anda.
- Hubungkan jaringan lokal dan Google Cloud jaringan Anda.
- Buat bucket Cloud Storage sebagai target untuk pencadangan data Anda.
- Salin file cadangan ke Cloud Storage menggunakan
gcloud storagegcloud CLI atau solusi gateway partner (lihat langkah-langkah yang telah dibahas sebelumnya di bagian pencadangan dan pemulihan data). Untuk mengetahui detailnya, lihat Bermigrasi ke Google Cloud: Mentransfer set data besar Anda. - Salin log transaksi ke situs pemulihan Anda di Google Cloud. Memiliki cadangan log transaksi membantu menjaga nilai RPO Anda tetap kecil.
Setelah mengonfigurasi topologi pencadangan ini, Anda harus memastikan bahwa Anda dapat melakukan pemulihan ke sistem yang ada di Google Cloud. Langkah ini biasanya tidak hanya melibatkan pemulihan file cadangan ke database target, tetapi juga memutar ulang log transaksi untuk mencapai nilai RTO terkecil. Urutan pemulihan umumnya terlihat seperti ini:
- Buat image kustom server database Anda di Google Cloud. Server database harus memiliki konfigurasi pada image yang sama dengan server database lokal Anda.
- Terapkan proses untuk menyalin file cadangan lokal dan log transaksi Anda ke Cloud Storage. Lihat solusi 1 untuk contoh implementasi.
- Mulai instance berukuran minimal dari image kustom dan pasang persistent disk yang diperlukan.
- Tetapkan flag hapus otomatis ke false untuk persistent disk.
- Terapkan file cadangan terbaru yang telah disalin sebelumnya ke Cloud Storage mengikuti petunjuk dari sistem database Anda untuk memulihkan file cadangan.
- Terapkan kumpulan file log transaksi terbaru yang telah disalin ke Cloud Storage.
- Ganti instance minimal dengan instance yang lebih besar yang mampu menerima traffic produksi.
- Alihkan klien untuk diarahkan ke database yang telah dipulihkan di Google Cloud.
Setelah lingkungan produksi berjalan dan dapat mendukung beban kerja produksi, Anda harus membalik langkah-langkah yang diikuti untuk beralih keGoogle Cloud lingkungan pemulihan. Urutan umum untuk kembali ke lingkungan produksi akan terlihat seperti ini:
- Lakukan pencadangan database yang berjalan di Google Cloud.
- Salin file cadangan ke lingkungan produksi Anda.
- Terapkan file cadangan ke sistem database produksi Anda.
- Cegah klien terhubung ke sistem database di Google Cloud; misalnya, dengan menghentikan layanan sistem database. Di titik ini, aplikasi Anda tidak akan tersedia sampai Anda selesai memulihkan lingkungan produksi.
- Salin file log transaksi apa pun ke lingkungan produksi dan terapkan.
- Alihkan koneksi klien ke lingkungan produksi.
Solusi 2: Replikasi ke server standby di Google Cloud
Salah satu cara untuk mencapai nilai RTO dan RPO yang sangat kecil adalah dengan mereplikasi (bukan hanya mencadangkan) data dan dalam beberapa kasus, status database secara real time ke replika server database Anda.
- Hubungkan jaringan lokal dan jaringan Google Cloud Anda.
- Buat image kustom server database Anda di Google Cloud. Server database harus memiliki konfigurasi pada image yang sama dengan konfigurasi server database lokal Anda.
- Mulai instance dari image kustom dan pasang persistent disk yang diperlukan.
- Tetapkan flag hapus otomatis ke false untuk persistent disk.
- Konfigurasikan replikasi antara server database lokal Anda dan server database target di Google Cloud dengan mengikuti petunjuk khusus untuk software database.
- Klien dikonfigurasi dalam operasi normal untuk mengarah ke server database di infrastruktur lokal.
Setelah mengonfigurasi topologi replikasi ini, alihkan klien untuk mengarah ke server standby yang berjalan di jaringan Google Cloud Anda.
Setelah lingkungan produksi Anda dicadangkan dan dapat mendukung beban kerja produksi, Anda harus menyinkronkan ulang server database produksi dengan server databaseGoogle Cloud , lalu mengalihkan klien untuk mengarah kembali ke lingkungan produksi
Lingkungan produksi adalah Google Cloud
Dalam skenario ini, lingkungan produksi dan lingkungan pemulihan dari bencana Anda dijalankan di Google Cloud.
Pencadangan dan pemulihan data
Pola umum untuk pencadangan data adalah menggunakan pola penyimpanan bertingkat. Saat beban kerja produksi Anda ada di Google Cloud, sistem penyimpanan bertingkat akan terlihat seperti diagram berikut. Anda memigrasikan data ke tingkat yang memiliki biaya penyimpanan lebih rendah, karena kemungkinkan persyaratan untuk mengakses data yang dicadangkan lebih kecil.
Pola ini menggunakan komponen penyusun DR berikut:
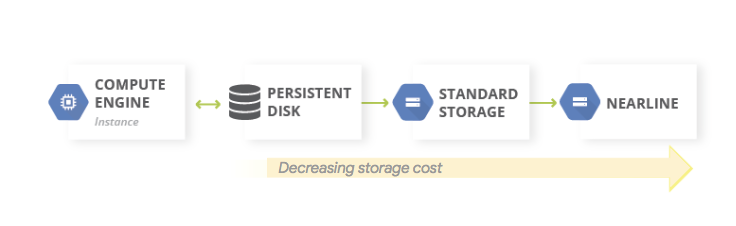
Karena kelas penyimpanan Nearline, Coldline, dan Archive ditujukan untuk menyimpan data yang jarang diakses, ada biaya tambahan yang terkait dengan pengambilan data atau metadata yang disimpan di kelas-kelas ini, serta durasi penyimpanan minimum yang ditagihkan kepada Anda.
Pencadangan dan pemulihan database
Saat Anda menggunakan database yang dikelola sendiri (misalnya, Anda telah menginstal MySQL, PostgreSQL, atau SQL Server pada instance Compute Engine), masalah operasional yang sama berlaku seperti pengelolaan database produksi secara lokal, tetapi Anda tidak perlu lagi mengelola infrastruktur yang mendasarinya.
Backup and DR Service adalah solusi berbasis cloud terpusat untuk mencadangkan dan memulihkan workload cloud dan hybrid. Layanan ini menawarkan pemulihan data yang cepat dan memfasilitasi kelanjutan cepat operasi bisnis penting.
Untuk mengetahui informasi selengkapnya tentang penggunaan Pencadangan dan DR untuk skenario database yang dikelola sendiri di Google Cloud, lihat artikel berikut:
Atau, Anda dapat menyiapkan konfigurasi HA menggunakan fitur komponen penyusun DR yang sesuai agar RTO tetap kecil. Anda dapat mendesain konfigurasi database untuk memudahkan pemulihan ke keadaan semirip mungkin dengan keadaan sebelum bencana terjadi; hal ini membantu menjaga nilai RPO Anda tetap kecil. Google Cloud menyediakan berbagai opsi untuk skenario ini.
Dua pendekatan umum dalam mendesain arsitektur pemulihan database untuk database yang dikelola sendiri di Google Cloud dibahas di bagian ini.
Memulihkan server database tanpa menyinkronkan status
Pola umumnya adalah dengan mengaktifkan pemulihan server database yang tidak memerlukan sinkronisasi status sistem dengan replika standby terbaru.
Pola ini menggunakan komponen penyusun DR berikut:
- Compute Engine
- Grup instance terkelola
- Cloud Load Balancing (load balancing internal)
Diagram berikut mengilustrasikan contoh arsitektur yang membahas skenario tersebut. Dengan menerapkan arsitektur ini, Anda memiliki rencana DR yang akan otomatis bereaksi terhadap kegagalan tanpa memerlukan pemulihan secara manual.

Langkah-langkah berikut menjelaskan cara mengonfigurasi skenario ini:
- Buat Jaringan VPC
Buat image kustom yang dikonfigurasi dengan server database dengan melakukan hal berikut:
- Konfigurasikan server agar file database dan file log ditulis ke persistent disk standar yang terpasang.
- Buat snapshot dari persistent disk yang terpasang.
- Konfigurasikan skrip startup untuk membuat persistent disk dari snapshot dan untuk memasang disk.
- Buat image kustom dari boot disk.
Buat template instance yang menggunakan image tersebut.
Menggunakan template instance, konfigurasikan grup instance terkelola dengan ukuran target 1.
Mengonfigurasi health check menggunakan metrik Cloud Monitoring.
Konfigurasikan load balancing internal menggunakan grup instance terkelola.
Konfigurasikan tugas terjadwal untuk membuat snapshot reguler dari persistent disk.
Jika instance database pengganti diperlukan, konfigurasi ini akan melakukan hal berikut secara otomatis:
- Memunculkan versi server database lain yang benar di zona yang sama.
- Memasang persistent disk yang memiliki file log transaksi dan cadangan terbaru ke instance server database yang baru dibuat.
- Meminimalkan kebutuhan untuk mengonfigurasi ulang klien yang berkomunikasi dengan server database Anda sebagai respons terhadap suatu peristiwa.
- Memastikan bahwa Google Cloud kontrol keamanan (kebijakan IAM, setelan firewall) yang berlaku untuk server database produksi berlaku untuk server database yang dipulihkan.
Karena instance pengganti dibuat dari template instance, kontrol pada instance asli akan diterapkan pada instance pengganti.
Skenario ini memanfaatkan beberapa fitur ketersediaan tinggi (HA) yang tersedia diGoogle Cloud; Anda tidak perlu melakukan langkah-langkah failover apa pun, karena langkah tersebut terjadi secara otomatis saat terjadi bencana. Load balancer internal memastikan bahwa meskipun instance pengganti diperlukan, alamat IP yang sama akan digunakan untuk server database. Template instance dan image kustom memastikan bahwa instance pengganti dikonfigurasi secara identik dengan instance yang diganti. Dengan mengambil snapshot persistent disk secara rutin, Anda memastikan bahwa saat disk dibuat ulang dari snapshot dan dipasang ke instance pengganti, instance pengganti akan menggunakan data yang dipulihkan sesuai dengan nilai RPO yang ditentukan sesuai frekuensi pengambilan snapshot. Dalam arsitektur ini, file log transaksi terbaru yang ditulis di persistent disk juga akan dipulihkan secara otomatis.
Grup instance terkelola menyediakan HA secara mendalam. Solusi ini menyediakan mekanisme untuk merespons kegagalan di tingkat aplikasi atau instance, dan Anda tidak perlu melakukan intervensi secara manual saat salah satu skenario tersebut terjadi. Menetapkan ukuran target sebesar satu akan memastikan Anda hanya memiliki satu instance aktif yang berjalan di grup instance terkelola dan menyajikan traffic.
Persistent disk standar bersifat sesuai zona, jadi jika terjadi kegagalan zona, snapshot diperlukan untuk membuat ulang disk. Snapshot juga tersedia di seluruh region, sehingga Anda dapat memulihkan disk tidak hanya dalam region yang sama, tetapi juga ke region yang berbeda.
Variasi pada konfigurasi ini adalah menggunakan persistent disk regional sebagai pengganti persistent disk standar. Dalam kasus ini, Anda tidak perlu memulihkan snapshot sebagai bagian dari langkah pemulihan.
Variasi yang Anda pilih ditentukan oleh anggaran serta nilai RTO dan RPO Anda.
Memulihkan dari kerusakan parsial dalam database yang sangat besar
Replikasi Asinkron Persistent Disk menawarkan replikasi block storage dengan RPO rendah dan RTO rendah untuk DR aktif-pasif lintas region. Opsi penyimpanan ini memungkinkan Anda mengelola replikasi untuk workload Compute Engine di tingkat infrastruktur, bukan di tingkat workload.
Jika Anda menggunakan database yang mampu menyimpan data berukuran petabyte, Anda mungkin mengalami pemadaman layanan yang akan memengaruhi beberapa data, tetapi tidak semuanya. Dalam kasus ini, Anda ingin meminimalkan jumlah data yang perlu dipulihkan; Anda tidak perlu (atau ingin) memulihkan seluruh database hanya untuk memulihkan sebagian datanya.
Ada sejumlah strategi mitigasi yang dapat Anda gunakan:
- Simpan data Anda dalam tabel yang berbeda untuk jangka waktu tertentu. Metode ini memastikan bahwa Anda hanya perlu memulihkan sebagian data ke tabel baru, bukan seluruh set data.
Simpan data asli di Cloud Storage. Pendekatan ini memungkinkan Anda membuat tabel baru dan memuat ulang data yang tidak rusak. Dari sana, Anda dapat menyesuaikan aplikasi untuk mengarah ke tabel baru.
Selain itu, jika RTO Anda memungkinkan, Anda dapat mencegah akses ke tabel yang memiliki data yang rusak dengan membiarkan aplikasi Anda offline hingga data yang tidak rusak telah dipulihkan ke tabel baru.
Layanan database terkelola di Google Cloud
Bagian ini membahas beberapa metode yang dapat Anda gunakan untuk menerapkan mekanisme pencadangan dan pemulihan yang sesuai untuk layanan database terkelola diGoogle Cloud.
Database terkelola dirancang untuk skala, sehingga mekanisme pencadangan dan pemulihan tradisional yang Anda dapati pada RDMBS tradisional biasanya tidak tersedia. Dalam kasus database yang dikelola sendiri, jika menggunakan database yang mampu menyimpan data berukuran petabyte, Anda ingin meminimalkan jumlah data yang perlu dipulihkan dalam skenario DR. Ada sejumlah strategi untuk setiap database terkelola untuk membantu Anda mencapai tujuan ini.
Bigtable menyediakan Replikasi Bigtable. Database Bigtable yang direplikasi dapat memberikan ketersediaan yang lebih tinggi daripada satu cluster, read throughput tambahan, serta durabilitas dan ketahanan yang lebih tinggi dalam menghadapi kegagalan zona atau regional.
Cadangan Bigtable adalah layanan terkelola sepenuhnya yang memungkinkan Anda menyimpan salinan skema dan data tabel, lalu memulihkannya dari cadangan ke tabel baru di lain waktu.
Anda juga dapat mengekspor tabel dari Bigtable sebagai serangkaian file berurutan Hadoop. Selanjutnya, Anda dapat menyimpan file ini di Cloud Storage atau menggunakannya untuk mengimpor kembali data ke instance Bigtable lain. Anda dapat mereplikasi set data Bigtable secara asinkron ke berbagai zona dalam region Google Cloud .
BigQuery. Jika ingin mengarsipkan data, Anda dapat memanfaatkan penyimpanan jangka panjang BigQuery. Jika tabel tidak diedit selama 90 hari berturut-turut, harga penyimpanan untuk tabel tersebut akan otomatis turun sebanyak 50 persen. Tidak ada penurunan performa, durabilitas, ketersediaan, atau fungsi lainnya jika tabel dianggap sebagai penyimpanan jangka panjang. Namun, jika diedit, tabel akan kembali ke harga penyimpanan reguler dan hitung mundur 90 hari akan dimulai kembali.
BigQuery direplikasi ke dua zona dalam satu region, tetapi hal ini tidak akan membantu mengatasi kerusakan di tabel Anda. Oleh karena itu, Anda harus memiliki rencana agar dapat memulihkan data dari skenario tersebut. Misalnya, Anda dapat melakukan hal berikut:
- Jika kerusakan terdeteksi dalam 7 hari, buat kueri tabel ke titik waktu di masa lalu untuk memulihkan tabel sebelum kerusakan terjadi menggunakan dekorator snapshot.
- Ekspor data dari BigQuery, dan buat tabel baru yang berisi data yang diekspor tanpa menyertakan data yang rusak.
- Simpan data Anda dalam tabel yang berbeda untuk jangka waktu tertentu. Metode ini memastikan bahwa Anda hanya perlu memulihkan sebagian data ke tabel baru, bukan seluruh set data.
- Buat salinan set data Anda pada jangka waktu tertentu. Anda dapat menggunakan salinan ini jika peristiwa kerusakan data terjadi melebihi waktu yang dapat dicatat oleh kueri point-in-time (misalnya, lebih dari 7 hari yang lalu). Anda juga dapat menyalin set data dari satu region ke region lain untuk memastikan ketersediaan data jika terjadi kegagalan region.
- Simpan data asli di Cloud Storage, yang memungkinkan Anda membuat tabel baru dan memuat ulang data yang tidak rusak. Dari sana, Anda dapat menyesuaikan aplikasi untuk mengarah ke tabel baru.
Firestore. Dengan layanan ekspor dan impor terkelola, Anda dapat mengimpor dan mengekspor entity Firestore menggunakan bucket Cloud Storage. Kemudian, Anda dapat menerapkan proses yang dapat digunakan untuk memulihkan data yang tidak sengaja terhapus.
Cloud SQL. Jika menggunakan Cloud SQL, database MySQL yang terkelola sepenuhnya, Anda harus mengaktifkan pencadangan otomatis dan logging biner untuk instance Cloud SQL Anda.Google Cloud Dengan pendekatan ini, Anda dapat melakukan pemulihan point-in-time, yang memulihkan database dari cadangan dan memulihkannya ke instance Cloud SQL baru. Untuk mengetahui informasi selengkapnya, lihat artikel Tentang pencadangan Cloud SQL dan Tentang pemulihan dari bencana (DR) di Cloud SQL
Anda juga dapat mengonfigurasi Cloud SQL dalam konfigurasi HA dan replika lintas region untuk memaksimalkan waktu beroperasi jika terjadi kegagalan zona atau regional.
Jika Anda mengaktifkan pemeliharaan terencana dengan periode nonaktif nyaris nol untuk Cloud SQL, Anda dapat mengevaluasi dampak peristiwa pemeliharaan pada instance dengan menyimulasikan peristiwa pemeliharaan terencana dengan periode nonaktif nyaris nol di Cloud SQL untuk MySQL dan di Cloud SQL untuk PostgreSQL.
Untuk edisi Cloud SQL Enterprise Plus, Anda dapat menggunakan pemulihan dari bencana (DR) tingkat lanjut untuk menyederhanakan proses pemulihan dan penggantian dengan nol kehilangan data setelah Anda melakukan failover lintas region.
Spanner. Anda dapat menggunakan template Dataflow untuk membuat ekspor database secara penuh ke set file Avro dalam bucket Cloud Storage, dan menggunakan template lain untuk mengimpor ulang file yang diekspor ke database Spanner baru.
Untuk pencadangan yang lebih terkontrol, konektor Dataflow memungkinkan Anda menulis kode untuk membaca dan menulis data ke Spanner di pipeline Dataflow. Misalnya, Anda dapat menggunakan konektor untuk menyalin data dari Spanner dan ke Cloud Storage sebagai target pencadangan. Seberapa cepat data yang dapat dibaca dari (atau ditulis kembali di) Spanner bergantung pada jumlah node yang dikonfigurasi. Hal ini berdampak langsung pada nilai RTO Anda.
Fitur commit timestamp Spanner dapat berguna untuk pencadangan inkremental, dengan memungkinkan Anda hanya memilih baris yang telah ditambahkan atau diubah sejak pencadangan penuh terakhir.
Untuk cadangan terkelola, Spanner Backup and Restore memungkinkan Anda membuat cadangan yang konsisten yang dapat disimpan hingga 1 tahun. Nilai RTO lebih rendah dibandingkan dengan ekspor karena operasi pemulihan akan langsung memasang cadangan tanpa menyalin data.
Untuk nilai RTO kecil, Anda dapat menyiapkan instance Spanner mode warm standby yang dikonfigurasi dengan jumlah minimum node yang diperlukan untuk memenuhi persyaratan throughput baca dan tulis penyimpanan Anda.
Pemulihan point-in-time (PITR) Spanner memungkinkan Anda memulihkan data dari titik waktu tertentu di masa lalu. Misalnya, jika operator tidak sengaja menulis data atau peluncuran sebuah aplikasi merusak database, Anda dapat memulihkan data dari satu titik waktu sebelumnya dengan PITR hingga maksimum 7 hari.
Cloud Composer Anda dapat menggunakan Cloud Composer (versi Apache Airflow yang terkelola) untuk menjadwalkan pencadangan rutin beberapa databaseGoogle Cloud . Anda dapat membuat directed acyclic graph (DAG) untuk dijalankan sesuai jadwal (misalnya, setiap hari) baik untuk menyalin data ke project, set data, atau tabel lain (bergantung pada solusi yang digunakan), atau untuk mengekspor data ke Cloud Storage.
Mengekspor atau menyalin data dapat dilakukan menggunakan berbagai macam operator Cloud Platform.
Misalnya, Anda dapat membuat DAG untuk melakukan hal berikut:
- Ekspor tabel BigQuery ke Cloud Storage menggunakan BigQueryToCloudStorageOperator.
- Mengekspor Firestore dalam mode Datastore (Datastore) ke Cloud Storage menggunakan DatastoreExportOperator.
- Ekspor tabel MySQL ke Cloud Storage menggunakan MySqlToGoogleCloudStorageOperator.
- Ekspor tabel Postgres ke Cloud Storage menggunakan PostgresToGoogleCloudStorageOperator.
Lingkungan produksi adalah cloud lainnya
Dalam skenario ini, lingkungan produksi Anda menggunakan penyedia cloud lain, dan rencana pemulihan dari bencana Anda melibatkan penggunaan Google Cloud sebagai situs pemulihan.
Pencadangan dan pemulihan data
Mentransfer data antar penyimpanan objek adalah kasus penggunaan umum untuk skenario DR. Storage Transfer Service kompatibel dengan Amazon S3 dan merupakan cara yang direkomendasikan untuk mentransfer objek dari Amazon S3 ke Cloud Storage.
Anda dapat mengonfigurasi tugas transfer untuk menjadwalkan sinkronisasi berkala dari sumber data ke sink data, dengan filter lanjutan berdasarkan tanggal pembuatan file, filter nama file, dan waktu yang Anda pilih untuk mentransfer data. Untuk mencapai RPO yang diinginkan, Anda harus mempertimbangkan faktor-faktor berikut:
Laju perubahan. Jumlah data yang dihasilkan atau diperbarui untuk jangka waktu tertentu. Semakin tinggi laju perubahan, semakin banyak resource yang diperlukan untuk mentransfer perubahan ke tujuan pada setiap periode transfer inkremental.
Performa transfer. Waktu yang diperlukan untuk mentransfer file. Untuk transfer file berukuran besar, hal ini biasanya ditentukan oleh bandwidth yang tersedia antara sumber dan tujuan. Namun, jika tugas transfer terdiri dari banyak file berukuran kecil, QPS dapat menjadi faktor pembatas. Jika demikian, Anda dapat menjadwalkan beberapa tugas serentak untuk menskalakan performa selama bandwidth yang memadai tersedia. Sebaiknya Anda mengukur performa transfer menggunakan subset representatif dari data nyata Anda.
Frekuensi. Interval di antara tugas pencadangan. Keaktualan data di tujuan adalah yang terbaru sejak terakhir kali tugas transfer dijadwalkan. Oleh karena itu,sangat penting untuk memastikan interval antara tugas transfer berurutan tidak lebih lama dari tujuan RPO Anda. Misalnya, jika tujuan RPO adalah 1 hari, tugas transfer harus dijadwalkan setidaknya sekali sehari.
Pemantauan dan peringatan. Storage Transfer Service menyediakan notifikasi Pub/Sub untuk berbagai peristiwa. Sebaiknya Anda berlangganan notifikasi ini untuk menangani kegagalan tak terduga atau perubahan dalam waktu penyelesaian tugas.
Pencadangan dan pemulihan database
Dokumen ini tidak mencakup pembahasan secara mendetail tentang berbagai mekanisme pencadangan dan pemulihan bawaan yang disertakan dengan database pihak ketiga atau teknik pencadangan dan pemulihan yang digunakan pada penyedia cloud lainnya. Jika mengoperasikan database tidak terkelola pada layanan komputasi, Anda dapat memanfaatkan fasilitas dengan ketersediaan tinggi (HA) yang disediakan oleh penyedia produksi cloud Anda. Anda dapat memperluasnya untuk menggabungkan deployment HA ke Google Cloud, atau menggunakan Cloud Storage sebagai tujuan akhir untuk cold storage file cadangan database Anda.
Apa langkah selanjutnya?
- Baca tentang Google Cloud geografi dan region.
Baca dokumen lain dalam rangkaian DR ini:
- Panduan perencanaan pemulihan dari bencana
- Komponen penyusun pemulihan dari bencana
- Skenario pemulihan dari bencana untuk aplikasi
- Merancang pemulihan dari bencana untuk workload yang dibatasi lokalitas
- Kasus penggunaan pemulihan dari bencana: aplikasi analisis data yang dibatasi lokalitas
- Merancang pemulihan dari bencana untuk pemadaman infrastruktur cloud
- Arsitektur untuk ketersediaan tinggi cluster MySQL di Compute Engine
Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.