Halaman ini menjelaskan cara mengimpor database Spanner ke Spanner menggunakan konsol Google Cloud . Untuk mengimpor file Avro dari sumber lain, lihat Mengimpor data dari database non-Spanner.
Proses ini menggunakan Dataflow; proses ini mengimpor data dari folder bucket Cloud Storage yang berisi serangkaian file Avro dan file manifes JSON. Proses impor hanya mendukung file Avro yang diekspor dari Spanner.
Untuk mengimpor database Spanner menggunakan REST API atau gcloud CLI,
selesaikan langkah-langkah di bagian Sebelum memulai di halaman ini, lalu lihat petunjuk mendetail di Cloud Storage Avro ke Spanner.
Sebelum memulai
Untuk mengimpor database Spanner, pertama-tama Anda harus mengaktifkan Spanner, Cloud Storage, Compute Engine, dan Dataflow API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Anda juga memerlukan kuota yang cukup dan izin IAM yang diperlukan.
Persyaratan kuota
Persyaratan kuota untuk tugas impor adalah sebagai berikut:
- Spanner: Anda harus memiliki kapasitas komputasi yang cukup untuk mendukung jumlah data yang Anda impor. Tidak ada kapasitas komputasi tambahan yang diperlukan untuk mengimpor database, meskipun Anda mungkin perlu menambahkan kapasitas komputasi agar tugas Anda selesai dalam waktu yang wajar. Lihat Mengoptimalkan tugas untuk mengetahui detail selengkapnya.
- Cloud Storage: Untuk mengimpor, Anda harus memiliki bucket yang berisi file yang sebelumnya diekspor. Anda tidak perlu menetapkan ukuran untuk bucket.
- Dataflow: Tugas impor tunduk pada CPU, penggunaan disk, dan kuota Compute Engine alamat IP yang sama dengan tugas Dataflow lainnya.
Compute Engine: Sebelum menjalankan tugas impor, Anda harus menyiapkan kuota awal untuk Compute Engine, yang digunakan oleh Dataflow. Kuota ini mewakili jumlah maksimum resource yang Anda izinkan Dataflow untuk digunakan bagi tugas Anda. Nilai awal yang direkomendasikan adalah:
- CPU: 200
- Alamat IP yang sedang digunakan: 200
- Persistent disk standar: 50 TB
Umumnya, Anda tidak perlu melakukan penyesuaian lain. Dataflow menyediakan penskalaan otomatis sehingga Anda hanya membayar resource aktual yang digunakan selama impor. Jika tugas Anda dapat menggunakan lebih banyak resource, UI Dataflow akan menampilkan ikon peringatan. Tugas akan selesai meskipun ada ikon peringatan.
Peran yang diperlukan
Untuk mendapatkan izin yang diperlukan untuk mengekspor database, minta administrator untuk memberi Anda peran IAM berikut pada akun layanan worker Dataflow:
-
Cloud Spanner Viewer (
roles/spanner.viewer) -
Dataflow Worker (
roles/dataflow.worker) -
Storage Admin (
roles/storage.admin) -
Spanner Database Reader (
roles/spanner.databaseReader) -
Database Admin (
roles/spanner.databaseAdmin)
Opsional: Temukan folder database Anda di Cloud Storage
Untuk menemukan folder yang berisi database yang diekspor di konsolGoogle Cloud , buka browser Cloud Storage, lalu klik bucket yang berisi folder yang diekspor.
Nama folder yang berisi data yang diekspor dimulai dengan ID instance, nama database, dan stempel waktu tugas ekspor Anda. Folder berisi:
- File
spanner-export.json - File
TableName-manifest.jsonuntuk setiap tabel dalam database yang Anda ekspor. Satu atau beberapa file
TableName.avro-#####-of-#####. Angka pertama dalam ekstensi.avro-#####-of-#####mewakili indeks file Avro, dimulai dari nol, dan angka kedua mewakili jumlah file Avro yang dibuat untuk setiap tabel.Misalnya,
Songs.avro-00001-of-00002adalah file kedua dari dua file yang berisi data untuk tabelSongs.File
ChangeStreamName-manifest.jsonuntuk setiap aliran perubahan dalam database yang Anda ekspor.File
ChangeStreamName.avro-00000-of-00001untuk setiap aliran perubahan. File ini berisi data kosong dengan hanya skema Avro dari aliran perubahan.
Mengimpor database
Untuk mengimpor database Spanner dari Cloud Storage ke instance Anda, ikuti langkah-langkah berikut.
Buka halaman Instances Spanner.
Klik nama instance yang akan berisi database yang diimpor.
Klik item menu Impor/Ekspor di panel kiri, lalu klik tombol Impor.
Di bagian Pilih folder sumber, klik Browse.
Temukan bucket yang berisi ekspor Anda dalam daftar awal, atau klik Telusuri
 untuk memfilter daftar dan menemukan bucket. Klik dua kali bucket untuk melihat folder yang ada di dalamnya.
untuk memfilter daftar dan menemukan bucket. Klik dua kali bucket untuk melihat folder yang ada di dalamnya.Temukan folder berisi file yang diekspor, lalu klik untuk memilihnya.
Klik Pilih.
Masukkan nama untuk database baru, yang dibuat Spanner selama proses impor. Nama database tidak boleh sudah ada di instance Anda.
Pilih dialek untuk database baru (GoogleSQL atau PostgreSQL).
(Opsional) Untuk melindungi database baru dengan kunci enkripsi yang dikelola pelanggan, klik Tampilkan opsi enkripsi, lalu pilih Gunakan kunci enkripsi yang dikelola pelanggan (CMEK). Kemudian, pilih kunci dari daftar drop-down.
Pilih region di menu drop-down Pilih region untuk tugas impor.
(Opsional) Untuk mengenkripsi status pipeline Dataflow dengan kunci enkripsi yang dikelola pelanggan, klik Show encryption options dan pilih Use a customer-managed encryption key (CMEK). Kemudian, pilih kunci dari daftar drop-down.
Centang kotak di bagian Konfirmasi biaya untuk mengonfirmasi bahwa ada biaya selain yang ditanggung oleh instance Spanner yang ada.
Klik Import.
Konsol Google Cloud menampilkan halaman Detail database, yang kini menampilkan kotak yang menjelaskan tugas impor Anda, termasuk waktu yang telah berlalu untuk tugas tersebut:

Saat tugas selesai atau dihentikan, konsol Google Cloud akan menampilkan pesan di halaman Detail database. Jika tugas berhasil, pesan berhasil akan muncul:

Jika tugas tidak berhasil, pesan kegagalan akan muncul:

Jika tugas Anda gagal, periksa log Dataflow tugas untuk mengetahui detail error dan lihat Memecahkan masalah tugas impor yang gagal.
Catatan tentang mengimpor kolom yang dibuat dan aliran perubahan
Spanner menggunakan definisi setiap kolom yang dihasilkan dalam skema Avro untuk membuat ulang kolom tersebut. Spanner menghitung nilai kolom yang dihasilkan secara otomatis selama impor.
Demikian pula, Spanner menggunakan definisi setiap aliran perubahan dalam skema Avro untuk membuatnya ulang selama impor. Data streaming perubahan tidak diekspor maupun diimpor melalui Avro, sehingga semua streaming perubahan yang terkait dengan database yang baru diimpor tidak akan memiliki rekaman data perubahan.
Catatan tentang mengimpor urutan
Setiap urutan (GoogleSQL,
PostgreSQL)
yang diekspor Spanner menggunakan fungsi GET_INTERNAL_SEQUENCE_STATE()
(GoogleSQL,
PostgreSQL)
untuk merekam statusnya saat ini.
Spanner menambahkan buffer 1.000 ke penghitung, dan menulis nilai penghitung baru ke properti kolom rekaman. Perhatikan bahwa ini hanyalah pendekatan upaya terbaik untuk menghindari error nilai duplikat yang mungkin terjadi setelah impor.
Sesuaikan penghitung urutan sebenarnya jika ada lebih banyak penulisan ke
database sumber selama ekspor data.
Saat diimpor, urutan dimulai dari penghitung baru ini, bukan penghitung yang ditemukan dalam skema. Jika perlu, Anda dapat menggunakan pernyataan ALTER SEQUENCE (GoogleSQL, PostgreSQL) untuk memperbarui ke penghitung baru.
Catatan tentang mengimpor tabel sisipan dan kunci asing
Tugas Dataflow dapat mengimpor tabel yang disisipkan, sehingga Anda dapat mempertahankan hubungan induk-turunan dari file sumber. Namun, batasan kunci asing tidak diterapkan selama pemuatan data. Pekerjaan Dataflow membuat semua kunci asing yang diperlukan setelah pemuatan data selesai.
Jika Anda memiliki batasan kunci asing pada database Spanner sebelum impor dimulai, Anda mungkin mengalami error penulisan karena pelanggaran integritas referensial. Untuk menghindari error penulisan, pertimbangkan untuk menghapus kunci asing yang ada sebelum memulai proses impor.
Pilih region untuk tugas impor Anda
Anda mungkin ingin memilih region lain berdasarkan lokasi bucket Cloud Storage Anda. Untuk menghindari biaya transfer data keluar, pilih region yang cocok dengan lokasi bucket Cloud Storage Anda.
Jika lokasi bucket Cloud Storage Anda adalah region, Anda dapat memanfaatkan penggunaan jaringan gratis dengan memilih region yang sama untuk tugas impor, dengan asumsi region tersebut tersedia.
Jika lokasi bucket Cloud Storage Anda adalah region ganda, Anda dapat memanfaatkan penggunaan jaringan gratis dengan memilih salah satu dari dua region yang membentuk region ganda untuk tugas impor Anda, dengan asumsi salah satu region tersedia.
- Jika region yang ditempatkan bersama tidak tersedia untuk tugas impor Anda, atau jika lokasi bucket Cloud Storage Anda adalah multi-region, biaya transfer data keluar akan berlaku. Lihat harga transfer data Cloud Storage untuk memilih region yang menimbulkan biaya transfer data terendah.
Melihat atau memecahkan masalah tugas di UI Dataflow
Setelah memulai tugas impor, Anda dapat melihat detail tugas, termasuk log, di bagian Dataflow pada konsol Google Cloud .
Melihat detail tugas Dataflow
Untuk melihat detail tugas impor atau ekspor yang Anda jalankan dalam seminggu terakhir, termasuk tugas yang sedang berjalan:
- Buka halaman Ringkasan database untuk database.
- Klik item menu panel kiri Impor/Ekspor. Halaman Import/Export database menampilkan daftar tugas terbaru.
Di halaman Import/Export database, klik nama tugas di kolom Dataflow job name:
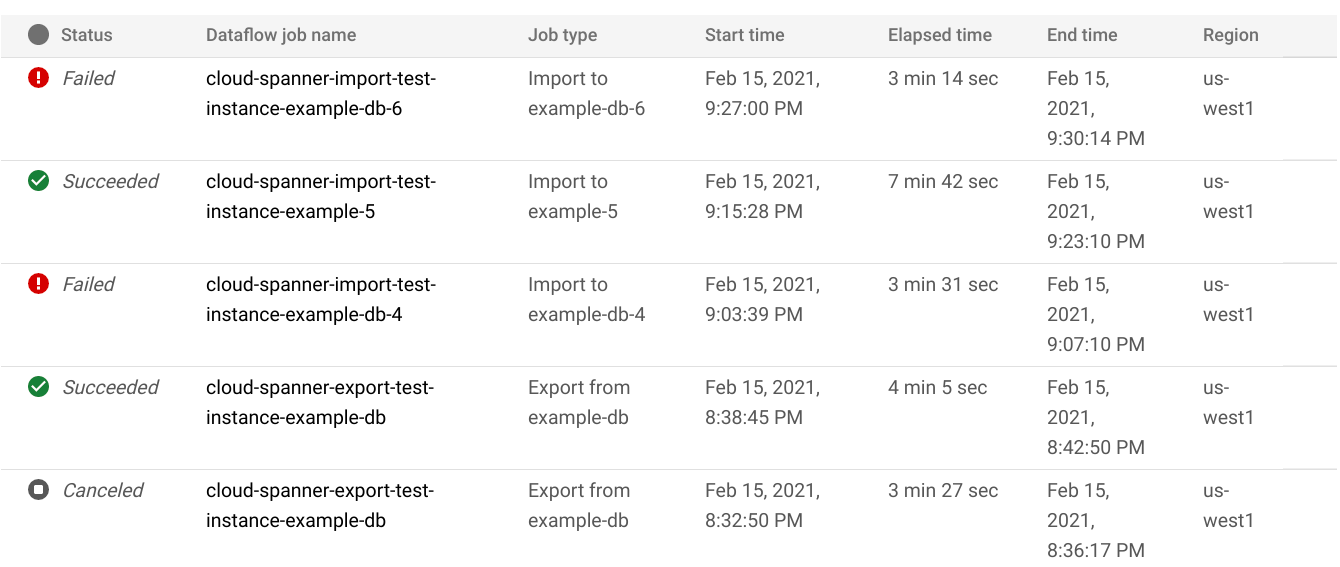
Konsol Google Cloud menampilkan detail tugas Dataflow.
Untuk melihat tugas yang Anda jalankan lebih dari satu minggu yang lalu:
Buka halaman tugas Dataflow di konsol Google Cloud .
Temukan tugas Anda dalam daftar, lalu klik namanya.
Konsol Google Cloud menampilkan detail tugas Dataflow.
Melihat log Dataflow untuk tugas Anda
Untuk melihat log tugas Dataflow, buka halaman detail tugas, lalu klik Log di sebelah kanan nama tugas.
Jika tugas gagal, cari error di log. Jika ada error, jumlah error akan ditampilkan di samping Log:

Untuk melihat error tugas:
Klik jumlah error di samping Log.
Konsol Google Cloud menampilkan log tugas. Anda mungkin perlu men-scroll untuk melihat error.
Temukan entri dengan ikon error
 .
.Klik setiap entri log untuk meluaskan isinya.
Untuk mengetahui informasi selengkapnya tentang cara memecahkan masalah tugas Dataflow, lihat Memecahkan masalah pipeline.
Memecahkan masalah tugas impor yang gagal
Jika Anda melihat error berikut di log tugas:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Periksa Latensi penulisan 99% di tab Monitoring database Spanner Anda di konsol Google Cloud . Jika menunjukkan nilai yang tinggi (beberapa detik), berarti instance kelebihan beban, sehingga penulisan akan mengalami waktu tunggu habis dan gagal.
Salah satu penyebab latensi tinggi adalah tugas Dataflow berjalan menggunakan terlalu banyak pekerja, sehingga memberikan terlalu banyak beban pada instance Spanner.
Untuk menentukan batas jumlah pekerja Dataflow, alih-alih menggunakan tab Impor/Ekspor di halaman detail instance database Spanner Anda di konsol Google Cloud , Anda harus memulai impor menggunakan template Cloud Storage Avro ke Spanner Dataflow dan menentukan jumlah maksimum pekerja seperti yang dijelaskan:Konsol
Jika Anda menggunakan konsol Dataflow, parameter Pekerja maks berada di bagian Parameter opsional pada halaman Buat tugas dari template.
gcloud
Jalankan perintah gcloud dataflow jobs run
dan tentukan argumen max-workers. Contoh:
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Memecahkan masalah error jaringan
Error berikut mungkin terjadi saat Anda mengekspor database Spanner:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Error ini terjadi karena Spanner mengasumsikan bahwa Anda ingin menggunakan jaringan VPC mode otomatis bernama default dalam project yang sama dengan tugas Dataflow. Jika Anda tidak memiliki jaringan VPC default di project, atau jika jaringan VPC Anda berada di jaringan VPC mode kustom, Anda harus membuat tugas Dataflow dan menentukan jaringan atau subnetwork alternatif.
Mengoptimalkan tugas impor yang berjalan lambat
Jika telah mengikuti saran di setelan awal, Anda umumnya tidak perlu melakukan penyesuaian lain. Jika tugas Anda berjalan lambat, ada beberapa pengoptimalan lain yang dapat Anda coba:
Mengoptimalkan lokasi tugas dan data: Jalankan tugas Dataflow di region yang sama dengan lokasi instance Spanner dan bucket Cloud Storage Anda.
Pastikan resource Dataflow mencukupi: Jika kuota Compute Engine yang relevan membatasi resource tugas Dataflow Anda, halaman Dataflow tugas di Google Cloud konsol akan menampilkan ikon peringatan
 dan pesan
log:
dan pesan
log: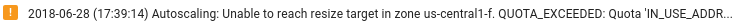
Dalam situasi ini, meningkatkan kuota untuk CPU, alamat IP yang sedang digunakan, dan persistent disk standar dapat memperpendek waktu berjalan tugas, tetapi Anda mungkin dikenai lebih banyak biaya Compute Engine.
Periksa pemakaian CPU Spanner: Jika Anda melihat bahwa pemakaian CPU untuk instance melebihi 65%, Anda dapat meningkatkan kapasitas komputasi di instance tersebut. Kapasitas akan menambahkan lebih banyak resource Spanner dan tugas akan berjalan lebih cepat, tetapi Anda akan dikenai lebih banyak biaya Spanner.
Faktor yang memengaruhi performa tugas impor
Beberapa faktor memengaruhi waktu yang diperlukan untuk menyelesaikan tugas impor.
Ukuran database Spanner: Memproses lebih banyak data memerlukan lebih banyak waktu dan resource.
Skema database Spanner, termasuk:
- Jumlah tabel
- Ukuran baris
- Jumlah indeks sekunder
- Jumlah kunci asing
- Jumlah aliran data perubahan
Perhatikan bahwa pembuatan indeks dan kunci asing berlanjut setelah tugas impor Dataflow selesai. Aliran perubahan dibuat sebelum tugas impor selesai, tetapi setelah semua data diimpor.
Lokasi data: Data ditransfer antara Spanner dan Cloud Storage menggunakan Dataflow. Idealnya, ketiga komponen tersebut berada di region yang sama. Jika komponen tidak berada di region yang sama, pemindahan data antar-region akan memperlambat tugas.
Jumlah worker Dataflow: Worker Dataflow yang optimal diperlukan untuk performa yang baik. Dengan menggunakan penskalaan otomatis, Dataflow memilih jumlah pekerja untuk tugas bergantung pada jumlah pekerjaan yang perlu dilakukan. Namun, jumlah pekerja akan dibatasi oleh kuota untuk CPU, alamat IP yang sedang digunakan, dan persistent disk standar. UI Dataflow menampilkan ikon peringatan jika menemukan batas kuota. Dalam situasi ini, progres lebih lambat, tetapi tugas akan tetap selesai. Penskalaan otomatis dapat membebani Spanner secara berlebihan sehingga menyebabkan error saat ada banyak data yang akan diimpor.
Beban yang ada di Spanner: Tugas impor menambahkan beban CPU yang signifikan pada instance Spanner. Jika instance sudah memiliki beban yang cukup besar, tugas akan berjalan lebih lambat.
Jumlah kapasitas komputasi Spanner: Jika penggunaan CPU untuk instance lebih dari 65%, maka tugas akan berjalan lebih lambat.
Menyesuaikan pekerja untuk performa impor yang baik
Saat memulai tugas impor Spanner, pekerja Dataflow harus ditetapkan ke nilai yang optimal untuk performa yang baik. Terlalu banyak pekerja akan membebani Spanner secara berlebihan dan terlalu sedikit pekerja akan menghasilkan performa impor yang kurang memuaskan.
Jumlah maksimum pekerja sangat bergantung pada ukuran data, tetapi idealnya, total pemakaian CPU Spanner harus antara 70% hingga 90%. Hal ini memberikan keseimbangan yang baik antara efisiensi Spanner dan penyelesaian tugas tanpa error.
Untuk mencapai target pemanfaatan tersebut di sebagian besar skema dan skenario, sebaiknya gunakan jumlah vCPU pekerja maksimum antara 4-6x jumlah node Spanner.
Misalnya, untuk instance Spanner 10 node, menggunakan pekerja n1-standard-2, Anda akan menetapkan pekerja maks ke 25, sehingga memberikan 50 vCPU.