Cet article fait partie d'une série qui traite de la reprise après sinistre (DR, Disaster Recovery) dans Google Cloud. Cette partie aborde le processus de conception de charges de travail à l'aide de Google Cloud et la création de composants résilients aux pannes d'infrastructure cloud.
La série comprend les éléments suivants :
- Guide de planification de reprise après sinistre
- Structure de la reprise après sinistre
- Scénarios de reprise après sinistre pour les données
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud (ce document)
Introduction
Pour migrer des charges de travail sur le cloud public, les entreprises doivent transposer leur savoir concernant la création de systèmes sur site résilients vers l'infrastructure hyperscale de fournisseurs cloud tels que Google Cloud. Cet article mappe les concepts de reprise après sinistre standards dans l'industrie, tels que l'objectif de temps de récupération (RTO) et l'objectif de point de récupération (RPO), à l'infrastructure Google Cloud.
Les conseils fournis dans ce document respectent l'un des principes clés de Google garantissant une très haute disponibilité des services : la planification contre les défaillances. Bien queGoogle Cloud fournisse un service extrêmement fiable, des sinistres peuvent survenir (catastrophes naturelles, ruptures de fibre et défaillances d'infrastructure imprévisibles et complexes), causant ainsi des pannes. La planification contre les pannes permet aux clientsGoogle Cloud de créer des applications qui fonctionnent de manière prévisible lors de ces événements inévitables, en utilisant des produits Google Cloud intégrant des mécanismes de reprise après sinistre.
La reprise après sinistre est un sujet vaste qui couvre bien plus que les défaillances d'infrastructure telles que les bugs logiciels ou la corruption de données. C'est pourquoi vous devez disposer d'un plan complet de bout en bout. Toutefois, cet article ne se concentre que sur une partie d'un plan de reprise après sinistre global, à savoir la conception d'applications résilientes aux pannes d'infrastructure cloud. Plus précisément, cet article décrit les éléments suivants :
- L'infrastructure Google Cloud , la façon dont les sinistres se manifestent en cas de pannesGoogle Cloud , ainsi que la manière dont Google Cloud est conçu pour minimiser la fréquence et l'étendue des pannes.
- Un guide de planification de l'architecture qui fournit un framework permettant de catégoriser et de concevoir des applications en fonction des résultats de fiabilité souhaités.
- La liste détaillée d'une sélection de produits Google Cloud proposant des fonctionnalités intégrées de reprise après sinistre que vous souhaiterez peut-être utiliser dans votre application.
Pour en savoir plus sur la planification générale de la reprise après sinistre et sur l'utilisation de Google Cloud en tant que composant de votre stratégie de reprise après sinistre sur site, consultez le guide de planification de reprise après sinistre. Bien que la haute disponibilité soit un concept étroitement lié à la reprise après sinistre, elle n'est pas traitée dans cet article. Pour en savoir plus sur la conception d'une architecture à haute disponibilité, consultez le framework Well-Architected.
Remarque sur la terminologie : dans cet article, le terme disponibilité désigne la capacité d'un produit à être accessible et utilisé de manière significative au fil du temps, tandis que le terme fiabilité désigne un ensemble d'attributs incluant la disponibilité ainsi que des éléments tels que la durabilité et l'exactitude.
Conception de Google Cloud pour la résilience
Centres de données Google
Les centres de données traditionnels visent à maximiser la disponibilité des composants individuels. Dans le cloud, le scaling permet à des opérateurs tels que Google de déployer des services sur de nombreux composants grâce à des technologies de virtualisation, allant ainsi au-delà de la fiabilité traditionnelle des composants. Cela signifie que vous pouvez changer votre approche en matière d'architecture de fiabilité et arrêter de vous focaliser sur les nombreux détails qui vous préoccupaient autrefois dans les environnements sur site. Plutôt que de vous soucier des différents modes de défaillance des composants (tels que le refroidissement et l'alimentation), vous pouvez baser votre planification sur les produits Google Cloud et leurs métriques de fiabilité annoncées. Ces métriques reflètent le risque de panne agrégé dans toute l'infrastructure sous-jacente. Vous pouvez ainsi vous concentrer davantage sur la conception, le déploiement et les opérations des applications plutôt que sur la gestion de l'infrastructure.
Google conçoit son infrastructure pour atteindre des objectifs de disponibilité ambitieux basés sur une vaste expérience dans les domaines de la création et de l'exploitation de centres de données modernes. Google est un leader mondial dans la conception de centres de données. De l'alimentation au refroidissement en passant par les réseaux, chaque technologie de centre de données dispose de ses propres redondances et mesures d'atténuation, y compris les plans FMEA. Les centres de données de Google sont conçus de manière à équilibrer ces nombreux risques différents et à présenter aux clients un niveau de disponibilité attendu cohérent pour les produits Google Cloud . Nous nous appuyons sur notre expérience pour modéliser la disponibilité de l'architecture globale du système physique et logique, et ainsi nous assurer que la conception des centres de données répond aux attentes. Les ingénieurs de Google déploient de nombreux efforts pour s'assurer que ces attentes sont satisfaites. La disponibilité réelle mesurée surpasse généralement de loin nos objectifs de conception.
En injectant l'ensemble de ces risques et mesures d'atténuation de centre de données dans les produits destinés aux utilisateurs, Google Cloud vous libère des responsabilités liées à la conception et à l'exploitation. À la place, vous pouvez vous concentrer sur la fiabilité intégrée aux régions et aux zonesGoogle Cloud .
Régions et zones
Les régions correspondent à des espaces géographiques indépendants qui sont constitués de zones. Les zones et les régions sont des abstractions logiques des ressources physiques sous-jacentes. Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
Les produitsGoogle Cloud sont divisés en ressources zonales, régionales ou multirégionales.
Les ressources zonales sont hébergées dans une seule zone. Une interruption de service dans la zone peut affecter toutes les ressources de cette zone. Prenons l'exemple d'une instance Compute Engine qui s'exécute dans une seule zone spécifiée. Si une défaillance matérielle cause l'arrêt du service dans cette zone, l'instance Compute Engine est indisponible pendant toute la durée de l'interruption.
Les ressources régionales sont déployées de façon redondante dans plusieurs zones d'une même région. Elles offrent ainsi une fiabilité plus élevée que les ressources zonales.
Les ressources multirégionales sont distribuées au sein des régions et entre elles. En général, les ressources multirégionales présentent une fiabilité plus élevée que les ressources régionales. À ce niveau, toutefois, les produits doivent optimiser la disponibilité, les performances et l'efficacité des ressources. Par conséquent, il est important de comprendre les compromis réalisés par chaque produit multirégional que vous décidez d'utiliser. Ces compromis sont décrits plus en détail dans la suite de ce document.
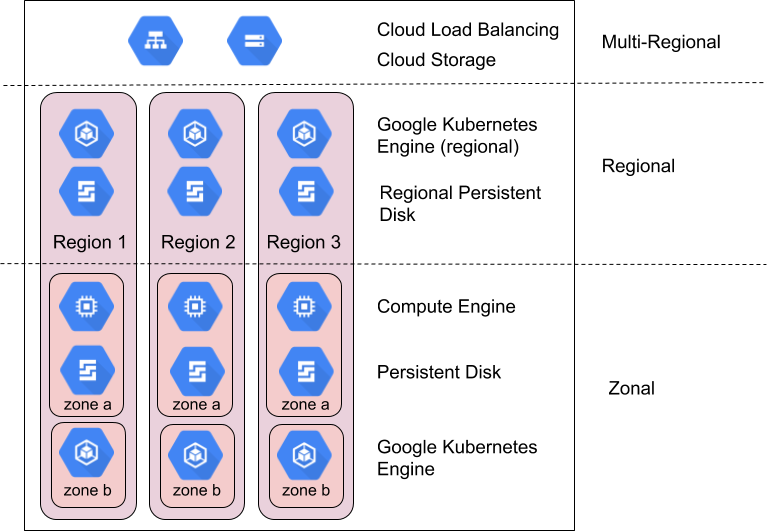
Exploiter les zones et les régions pour améliorer la fiabilité
Les ingénieurs SRE de Google gèrent et font évoluer des produits utilisateur hautement fiables et mondiaux, tels que Gmail et la recherche Google, à l'aide de diverses techniques et technologies qui exploitent de manière fluide l'infrastructure informatique du monde entier. Cela inclut la redirection du trafic depuis des emplacements indisponibles via l'équilibrage de charge global, l'exécution de plusieurs instances dupliquées dans de nombreux emplacements à travers le monde et la réplication des données entre les emplacements. Ces fonctionnalités sont disponibles pour les clients Google Cloudpar l'intermédiaire de produits tels que Cloud Load Balancing, Google Kubernetes Engine (GKE) et Spanner.
Google Cloud conçoit généralement les produits pour qu'ils offrent les niveaux de disponibilité suivants pour les zones et les régions :
| Ressource | Exemples | Objectif de conception de disponibilité | Temps d'arrêt implicite |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99,9 % | 8,75 heures/an |
| Régional | Cloud Storage régional, Persistent Disk (répliqué), GKE régional | 99,99 % | 52 minutes/an |
Comparez les objectifs de conception de disponibilité Google Cloud avec le temps d'arrêt que vous jugez acceptable pour identifier les ressources Google Cloud appropriées. Bien que les conceptions traditionnelles visent à améliorer la disponibilité au niveau des composants pour augmenter la disponibilité des applications résultantes, les modèles cloud se focalisent à la place sur la composition des composants pour atteindre cet objectif. De nombreux produits au sein deGoogle Cloud emploient cette technique. Par exemple, Spanner propose une base de données multirégionale qui compose plusieurs régions afin de fournir une disponibilité de 99,999 %.
La composition est importante, car sans elle, la disponibilité de votre application ne peut pas surpasser celle des produits Google Cloud que vous utilisez. En fait, à moins que votre application ne rencontre jamais de défaillance, sa disponibilité est inférieure à celle des produitsGoogle Cloud sous-jacents. Le reste de cette section explique de façon générale comment utiliser une composition de produits zonaux et régionaux pour obtenir une disponibilité d'application plus élevée qu'avec une seule zone ou région. La section suivante présente un guide pratique pour la mise en œuvre de ces principes dans vos applications.
Planification pour les pannes zonales
Les défaillances d'infrastructure entraînent généralement des interruptions de service dans une seule zone. Dans une région, les zones sont conçues pour minimiser le risque de pannes corrélées avec d'autres zones. Une interruption de service dans une zone n'affecte généralement pas le service d'une autre zone de la même région. Une panne limitée à une zone ne signifie pas nécessairement que la zone entière est indisponible ; cela définit simplement la limite de l'incident. Il est possible qu'une panne zonale n'ait aucun effet concret sur vos ressources spécifiques de cette zone.
Bien qu'il s'agisse d'un scénario plus rare, il est également essentiel de noter que plusieurs zones subiront à un moment donné une panne corrélée au sein d'une même région. Lorsque deux zones ou plus subissent une panne, la stratégie ci-dessous s'applique pour l'étendue de panne régionale.
Les ressources régionales sont conçues pour résister aux pannes zonales en distribuant le service à partir d'une composition de plusieurs zones. Si l'une des zones qui supportent la ressource régionale est interrompue, la ressource devient automatiquement disponible depuis une autre zone. Consultez attentivement la description des fonctionnalités produit dans l'annexe pour obtenir plus de détails.
Google Cloud ne propose que quelques ressources zonales, à savoir les machines virtuelles (VM) Compute Engine et les disques persistants. Si vous prévoyez d'utiliser des ressources zonales, vous devrez effectuer votre propre composition de ressources en concevant, en créant et en testant le basculement et la reprise entre des ressources zonales situées dans plusieurs zones. Voici quelques exemples de stratégies :
- Acheminez rapidement votre trafic vers des machines virtuelles d'une autre zone à l'aide de Cloud Load Balancing lorsqu'une vérification d'état détermine qu'une zone rencontre des problèmes.
- Utilisez des modèles d'instances Compute Engine et/ou des groupes d'instances gérés pour exécuter et faire évoluer des instances de VM identiques dans plusieurs zones.
- Utilisez un disque persistant régional pour répliquer les données de manière synchrone vers une autre zone d'une région. Consultez la page Options de haute disponibilité avec des disques persistants régionaux pour en savoir plus.
Planifier l'étendue des défaillances régionales
Une panne régionale est une interruption de service qui affecte plusieurs zones d'une même région. Ces pannes sont plus importantes et moins fréquentes, et peuvent être causées par des catastrophes naturelles ou des défaillances d'infrastructure à grande échelle.
Pour un produit régional conçu pour offrir une disponibilité de 99,99 %, une panne peut tout de même provoquer presque une heure de temps d'arrêt chaque année pour un produit donné. Par conséquent, vos applications critiques peuvent nécessiter la mise en œuvre d'un plan de reprise après sinistre multirégional si cette durée d'interruption est inacceptable.
Les ressources multirégionales sont conçues pour résister aux pannes régionales en distribuant le service à partir de plusieurs régions. Comme décrit ci-dessus, les produits multirégionaux offrent un compromis entre la latence, la cohérence et les coûts. Le compromis le plus courant se situe au niveau des réplications synchrone et asynchrone des données. La réplication asynchrone fournit une latence inférieure, mais inclut un risque de perte de données en cas de panne. Il est donc important de consulter la description des fonctionnalités produit dans l'annexe pour plus de détails.
Si vous souhaitez utiliser des ressources régionales tout en conservant une résilience aux pannes régionales, vous devez effectuer votre propre composition de ressources en concevant, en créant et en testant leur basculement et leur reprise entre des ressources régionales situées dans plusieurs régions. Outre les stratégies zonales décrites ci-dessus, que vous pouvez également appliquer aux régions, tenez compte des points suivants :
- Les ressources régionales doivent répliquer les données dans une région secondaire, dans une option de stockage multirégional telle que Cloud Storage, ou dans une option de cloud hybride telle que GKE Entreprise.
- Une fois que vous avez mis en place un système d'atténuation des pannes régionales, testez-le régulièrement. En effet, il n'y a rien de pire que de se croire résilient à une panne régionale, pour ensuite constater que ce n'est pas le cas en situation réelle.
Approche de résilience et de disponibilité deGoogle Cloud
Google Cloud surpasse régulièrement ses objectifs de conception de disponibilité, mais ne partez pas du principe que ces solides performances passées représentent la disponibilité minimale que vous pouvez concevoir. Sélectionnez plutôt les dépendances Google Cloud dont les objectifs de conception surpassent la fiabilité souhaitée pour votre application, de sorte que le temps d'arrêt de votre application et le temps d'arrêt de Google Cloud fournissent le résultat escompté.
Un système bien conçu peut répondre à la question suivante : "Que se passe-t-il lorsqu'une zone ou une région subit une panne de 1, 5, 10 ou 30 minutes ?" Cette question, ainsi que les questions suivantes, doivent être prises en compte au niveau de nombreuses couches :
- Quel est l'impact d'une panne pour mes clients ?
- Comment détecter une panne ?
- Qu'advient-il de mon application en cas de panne ?
- Qu'advient-il de mes données en cas de panne ?
- Qu'advient-il de mes autres applications lors d'une panne (en raison des dépendances croisées) ?
- Comment effectuer une reprise une fois la panne résolue ? Qui se charge de ce processus ?
- Qui informer d'une panne et dans quel délai ?
Guide par étapes sur la conception de la reprise après sinistre pour les applications dans Google Cloud
Dans les sections précédentes, vous avez découvert la façon dont Google conçoit une infrastructure cloud ainsi que quelques approches employées pour gérer les pannes zonales et régionales.
Cette section vous aide à développer un framework permettant d'appliquer le principe de composition à vos applications en fonction des résultats de fiabilité souhaités.
Les applications clientes dans Google Cloud qui ciblent des objectifs de reprise après sinistre tels que le RTO et le RPO doivent être conçues de manière à ce que les opérations critiques pour l'entreprise, soumises au RTO/RPO, ne dépendent que des composants du plan de données responsables du traitement continu des opérations pour le service. En d'autres termes, ces opérations critiques pour les entreprises clientes ne doivent pas dépendre des opérations du plan de gestion, qui gèrent l'état de la configuration et transfèrent la configuration au plan de contrôle et au plan de données.
Par exemple,les clients Google Cloud qui souhaitent atteindre un objectif RTO pour les opérations critiques ne doivent pas dépendre d'une API de création de VM ni de la mise à jour d'une autorisation IAM.
Étape 1 : Rassembler les exigences existantes
La première étape consiste à définir les exigences de disponibilité de vos applications. La plupart des entreprises reçoivent déjà dans une certaine mesure des conseils de conception dans cet espace, qui peuvent être développés ou dérivés en interne à partir de réglementations ou d'autres obligations légales. Ces conseils de conception sont généralement codifiés par deux métriques clés : l'objectif de temps de récupération (RTO) et l'objectif de point de récupération (RPO). Dans le langage d'affaires, la métrique RTO se traduit par "Combien de temps me faut-il pour redevenir opérationnel après un sinistre ?". La métrique RPO, quant à elle, se traduit par "Quelle quantité de données puis-je me permettre de perdre en cas de sinistre ?".

Par le passé, les entreprises ont défini des exigences en matière de RTO et de RPO pour un grand nombre de sinistres allant des défaillances de composants jusqu'aux séismes. Cette démarche était logique dans un monde sur site où les planificateurs devaient mapper les exigences en matière de RTO/RPO via l'ensemble de la pile logicielle et matérielle. Dans le cloud, vous n'avez plus besoin de définir vos exigences de manière aussi détaillée, car le fournisseur s'en charge. À la place, vous pouvez définir vos exigences en matière de RTO et de RPO en fonction de l'étendue de la perte (zones ou régions entières), sans spécifier de raisons sous-jacentes. Pour Google Cloud , cela réduit votre rassemblement des exigences à trois scénarios : panne zonale, panne régionale, ou panne extrêmement improbable de plusieurs régions.
Sachant que toutes les applications n'ont pas la même importance, la plupart des clients catégorisent leurs applications en niveaux de criticité auxquels appliquer une exigence RTO/RPO spécifique. Lorsqu'elles sont combinées, les métriques RTO/RPO et la criticité d'application simplifient le processus de conception d'une application donnée en répondant aux questions suivantes :
- L'application doit-elle s'exécuter dans plusieurs zones de la même région ou dans plusieurs zones de plusieurs régions ?
- Sur quels produits Google Cloud l'application peut-elle s'appuyer ?
Voici un exemple de résultat de l'exercice de rassemblement des exigences :
RTO et RPO par criticité d'application pour l'exemple d'organisation Co :
| Criticité d'application | Pourcentage d'applications | Exemples d'applications | Panne zonale | Panne régionale |
|---|---|---|---|---|
| Niveau 1
(le plus important) |
5 % | Applications externes ou mondiales destinées aux clients, telles que les applications de paiement en temps réel et les vitrines d'e-commerce. | RTO : zéro RPO : zéro |
RTO : zéro RPO : zéro |
| Niveau 2 | 35 % | Applications régionales ou applications internes importantes, telles que les solutions CRM ou ERP. | RTO : 15 minutes
RPO : 15 minutes |
RTO : 1 heure
RPO : 1 heure |
| Niveau 3
(le moins important) |
60 % | Applications destinées aux équipes ou aux services, telles que les applications pour le back-office, la gestion des congés, les déplacements internes, la comptabilité et les RH. | RTO : 1 heure
RPO : 1 heure |
RTO : 12 heures RPO : 12 heures |
Étape 2 : Mapper les fonctionnalités aux produits disponibles
La deuxième étape consiste à comprendre les fonctionnalités de résilience des produits Google Cloudque vos applications utiliseront. La plupart des entreprises examinent les informations pertinentes sur les produits, puis ajoutent des instructions décrivant comment modifier leurs architectures pour combler les écarts entre les fonctionnalités produit et leurs exigences de résilience. Cette section présente plusieurs recommandations et domaines courants concernant les limites des données et des applications dans cet espace.
Comme indiqué précédemment, les produits Google compatibles avec la reprise après sinistre répondent largement aux besoins de deux types d'étendue de panne : régionale et zonale. Les pannes partielles doivent être planifiées de la même manière que les pannes complètes en ce qui concerne la reprise après sinistre. Voici une matrice initiale d'ensemble décrivant les produits adaptés à chaque scénario par défaut :
Google Cloud Fonctionnalités générales des produits
(consultez l'annexe pour obtenir la liste des fonctionnalités de produits spécifiques)
| Tous les produits Google Cloud | Produits régionaux Google Cloud avec réplication automatique entre les zones | Produits multirégionaux ou mondiaux Google Cloud avec réplication automatique entre les régions | |
|---|---|---|---|
| Défaillance d'un composant d'une zone | Couvert* | Couvert | Couvert |
| Panne zonale | Non couvert | Couvert | Couvert |
| Panne régionale | Non couvert | Non couvert | Couvert |
* Tous les produits Google Cloud sont résilients aux défaillances des composants, sauf dans les cas spécifiques mentionnés dans la documentation du produit. Il s'agit habituellement de scénarios dans lesquels le produit fournit un accès direct ou un mappage statique à un élément matériel spécialisé, tel que la mémoire ou un disque SSD.
Comment le RPO limite le choix de produits
Dans la plupart des déploiements cloud, l'intégrité des données constitue l'aspect le plus important de l'architecture à prendre en compte pour un service. Au moins une partie des applications ont une exigence RPO de zéro, ce qui signifie qu'il n'y a aucune perte de données en cas de panne. Cette mise en œuvre nécessite généralement une réplication synchrone des données dans une autre zone ou région. La réplication synchrone présente des compromis en termes de coûts et de latence. Ainsi, même si de nombreux produits Google Cloud fournissent une réplication synchrone entre les zones, peu d'entre eux fournissent une réplication entre les régions. Ce compromis au niveau des coûts et de la complexité signifie qu'il n'est pas rare que différents types de données au sein d'une application aient des valeurs RPO différentes.
Pour les données avec un RPO supérieur à zéro, les applications peuvent tirer parti de la réplication asynchrone. La réplication asynchrone est acceptable lorsque les données perdues peuvent être facilement recréées, ou récupérées à partir d'une source de données fiable, si nécessaire. Il peut également s'agir d'un choix raisonnable lorsque la perte d'une faible quantité de données constitue un compromis acceptable pour les pannes zonales et régionales dont la durée est prévisible. Il est également important de noter qu'en cas de panne temporaire, les données écrites dans l'emplacement affecté qui n'ont pas encore été répliquées dans un autre emplacement deviennent généralement disponibles une fois la panne résolue. Cela signifie que le risque de perte de données permanente est inférieur au risque de perte d'accès aux données lors d'une panne.
Actions clés : déterminez si vous avez absolument besoin d'un RPO de zéro et, le cas échéant, si vous pouvez mettre en œuvre cette solution pour un sous-ensemble de vos données. Cela vous permet d'augmenter considérablement le nombre de services compatibles avec la reprise après sinistre dont vous pouvez disposer. Dans Google Cloud, l'obtention d'un RPO de zéro implique l'utilisation de produits principalement régionaux pour votre application, qui sont par défaut résilients aux pannes zonales, mais pas aux pannes régionales.
Comment le RPO limite le choix de produits
L'un des principaux avantages du cloud computing est la possibilité de déployer une infrastructure à la demande. Ce déploiement est toutefois différent d'un déploiement instantané. La valeur RTO de votre application doit inclure le RTO combiné des produits Google Cloud utilisés par votre application, ainsi que toutes les actions que vos ingénieurs ou ingénieurs SRE doivent entreprendre pour redémarrer vos VM ou les composants d'application. Un RTO mesuré en minutes implique de concevoir une application qui reprend automatiquement à la suite d'un sinistre sans intervention humaine, ou avec des étapes minimales (comme appuyer sur un bouton pour effectuer un basculement). Les coûts et la complexité de ce type de système ont toujours été très élevés, mais les produits Google Cloud tels que les équilibreurs de charge et les groupes d'instances rendent cette conception bien plus simple et abordable. Par conséquent, nous vous recommandons de mettre en place un basculement et une reprise automatiques pour la plupart des applications. Sachez que la conception d'un système pour ce type de basculement à chaud entre les régions est à la fois complexe et coûteuse. Seule une infime partie des services critiques justifient cette mise en œuvre.
La plupart des applications possèdent un RTO compris entre une heure et une journée. Cela permet un basculement tiède dans une situation de sinistre, où certains composants de l'application s'exécutent en permanence en mode de secours (tels que les bases de données), tandis que d'autres composants font l'objet d'un scaling horizontal en cas de sinistre (tels que les serveurs Web). Pour ces applications, nous vous conseillons vivement d'automatiser les événements à évolutivité horizontale. Les services avec un RTO de plus d'une journée sont les moins critiques et peuvent souvent être récupérés à partir d'une sauvegarde ou recréés entièrement.
Actions clés : déterminez si vous avez absolument besoin d'un RTO (proche) de zéro pour le basculement régional et, le cas échéant, si vous pouvez mettre en œuvre cette solution pour un sous-ensemble de vos services. Cela modifie le coût d'exécution et de maintenance de votre service.
Étape 3 : Développer vos propres architectures et guides de référence
La dernière étape recommandée consiste à créer vos propres modèles d'architecture spécifiques à l'entreprise pour aider vos équipes à standardiser leur approche de la reprise après sinistre. La plupart des clients Google Cloud fournissent à leurs équipes de développement un guide faisant correspondre leurs attentes métier individuelles en termes de résilience aux deux principales catégories de scénarios de panne sur Google Cloud. Ainsi, les équipes peuvent facilement catégoriser les produits compatibles avec la reprise après sinistre adaptés à chaque niveau de criticité.
Créer des directives produit
Reprenons l'exemple de tableau RTO/RPO ci-dessus. Vous disposez ici d'un guide hypothétique répertoriant les produits qui seront autorisés par défaut pour chaque niveau de criticité. Notez que même si certains produits ont été identifiés comme non adaptés par défaut, vous pouvez toujours ajouter vos propres mécanismes de réplication et de basculement pour obtenir une synchronisation interzone ou interrégionale, mais cet exercice dépasse le cadre de cet article. Les tableaux renvoient également vers des informations supplémentaires sur chaque produit pour vous aider à comprendre leurs fonctionnalités en ce qui concerne la gestion des pannes zonales ou régionales.
Exemples de modèles d'architecture pour l'exemple d'organisation Co - résilience aux pannes zonales
| Google Cloud Produit | Le produit répond-il aux exigences de panne zonale pour l'exemple d'organisation (avec une configuration de produit appropriée) ? | ||
|---|---|---|---|
| Niveau 1 | Niveau 2 | Niveau 3 | |
| Compute Engine | Non | Non | Non |
| Dataflow | Non | Non | Non |
| BigQuery | Non | Non | Yes |
| GKE | Yes | Oui | Oui |
| Cloud Storage | Oui | Oui | Oui |
| Cloud SQL | Non | Oui | Oui |
| Spanner | Oui | Oui | Oui |
| Cloud Load Balancing | Oui | Oui | Oui |
Le tableau ci-dessous n'est fourni qu'à titre d'exemple et est basé sur les niveaux hypothétiques présentés ci-dessus.
Exemples de modèles d'architecture pour l'exemple d'organisation Co - résilience aux pannes régionales
| Google Cloud Produit | Le produit répond-il aux exigences de panne régionale pour l'exemple d'organisation (avec une configuration de produit appropriée) ? | ||
|---|---|---|---|
| Niveau 1 | Niveau 2 | Niveau 3 | |
| Compute Engine | Oui | Oui | Oui |
| Dataflow | Non | Non | Non |
| BigQuery | Non | Non | Yes |
| GKE | Yes | Oui | Oui |
| Cloud Storage | Non | Non | Non |
| Cloud SQL | Non | Oui | Oui |
| Spanner | Oui | Oui | Oui |
| Cloud Load Balancing | Oui | Oui | Oui |
Le tableau ci-dessous n'est fourni qu'à titre d'exemple et est basé sur les niveaux hypothétiques présentés ci-dessus.
Pour vous montrer comment ces produits sont utilisés, les sections suivantes présentent quelques architectures de référence pour chaque niveau de criticité d'application. Il s'agit de descriptions volontairement générales qui illustrent les principales décisions en termes d'architecture. Elles ne représentent pas une conception de solution complète.
Exemple d'architecture de niveau 3
| Criticité d'application | Panne zonale | Panne régionale |
|---|---|---|
| Niveau 3 (le moins important) |
RTO : 12 heures RPO : 24 heures |
RTO : 28 jours RPO : 24 heures |
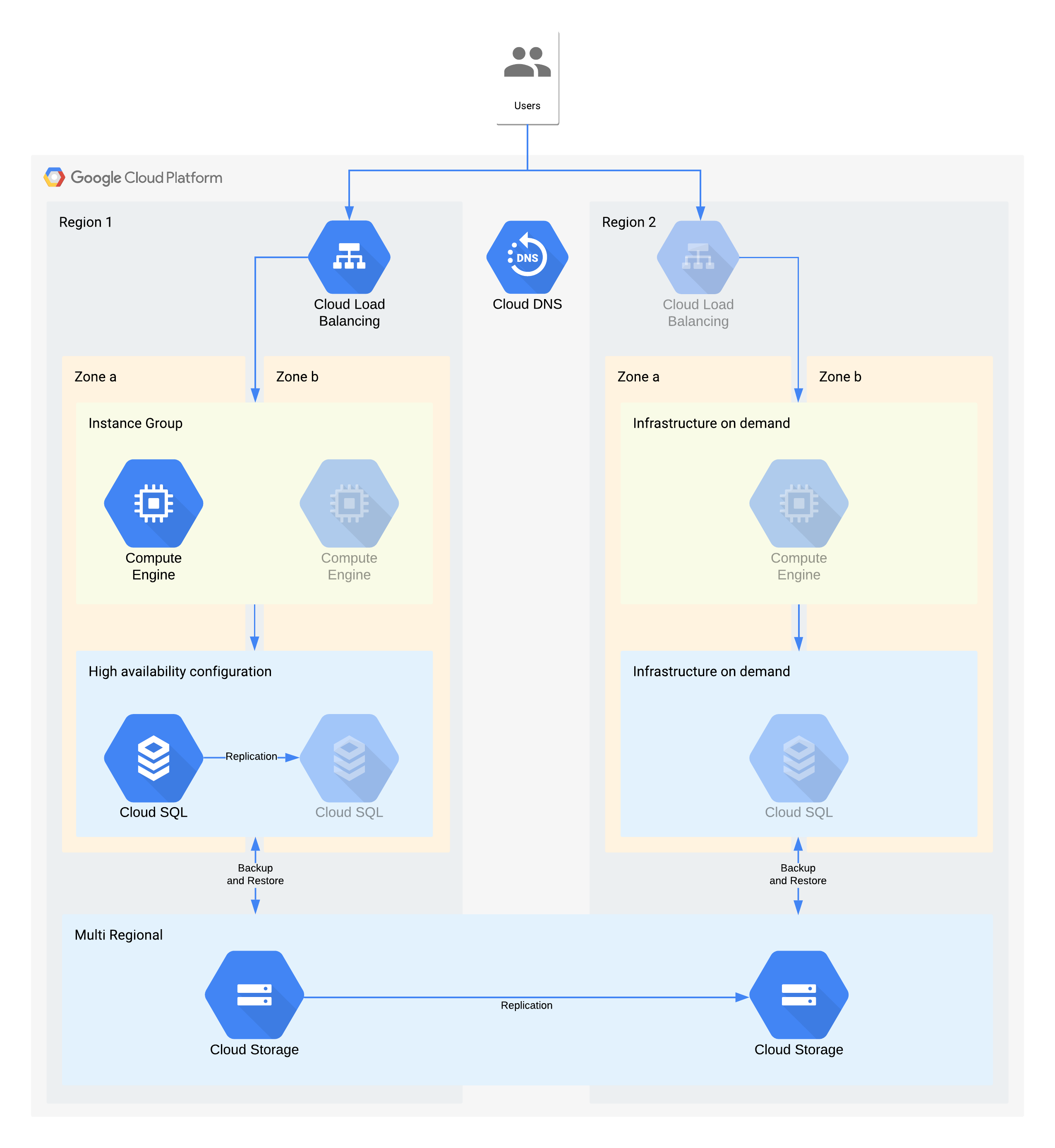
(Les icônes grisées indiquent l'infrastructure à activer pour la reprise.)
Cette architecture décrit une application cliente/serveur classique : les utilisateurs internes se connectent à une application qui s'exécute sur une instance de calcul soutenue par une base de données pour le stockage persistant.
Il est important de noter que cette architecture accepte des valeurs RTO et RPO supérieures à celles requises. Toutefois, vous devez également envisager de supprimer les étapes manuelles supplémentaires lorsqu'elles peuvent s'avérer coûteuses ou peu fiables. Par exemple, la récupération d'une base de données à partir d'une sauvegarde nocturne peut convenir au RPO de 24 heures, mais nécessite généralement la présence d'une personne qualifiée (telle qu'un administrateur de base de données) qui peut être indisponible, en particulier si plusieurs services ont été affectés en parallèle. Grâce à l'infrastructure à la demande de Google Cloud, vous pouvez bénéficier de cette fonctionnalité sans avoir à faire de compromis majeur en matière de coûts. Cette architecture exploite la haute disponibilité de Cloud SQL plutôt qu'une sauvegarde/restauration manuelle pour les pannes zonales.
Principales décisions en termes d'architecture pour les pannes zonales - RTO de 12 heures et RPO de 24 heures :
- Un équilibreur de charge interne est utilisé pour fournir un point d'accès évolutif aux utilisateurs, ce qui permet le basculement automatique vers une autre zone. Même si le RTO est de 12 heures, les modifications manuelles des adresses IP ou même les mises à jour DNS peuvent prendre plus de temps que prévu.
- Un groupe d'instances géré régional est configuré avec plusieurs zones, mais avec des ressources minimales. Ainsi, les coûts sont optimisés et les machines virtuelles peuvent toujours faire l'objet d'un scaling horizontal rapide dans la zone de sauvegarde.
- Une configuration Cloud SQL haute disponibilité fournit un basculement automatique vers une autre zone. Les bases de données sont considérablement plus difficiles à recréer et à restaurer que les machines virtuelles Compute Engine.
Principales décisions en termes d'architecture pour les pannes régionales - RTO de 28 jours et RPO de 24 heures :
- Un équilibreur de charge n'est créé dans la région 2 qu'en cas de panne régionale. Cloud DNS est employé pour fournir un basculement régional orchestré, mais manuel, dans la mesure où l'infrastructure de la région 2 n'est rendue disponible qu'en cas de panne régionale.
- Un nouveau groupe d'instances géré n'est créé qu'en cas de panne régionale. Cela permet d'optimiser les coûts, et ce scénario est peu susceptible de se produire en raison de la courte durée de la plupart des pannes régionales. Pour des raisons de simplicité, le schéma ne montre pas les outils associés nécessaires au redéploiement ni la copie des images Compute Engine requises.
- Une instance Cloud SQL est recréée et les données sont restaurées à partir d'une sauvegarde. Ici aussi, le risque d'une panne régionale prolongée est extrêmement faible. Il s'agit donc d'un autre compromis en matière d'optimisation des coûts.
- Le service Cloud Storage multirégional est utilisé pour stocker ces sauvegardes. Cela permet de fournir une zone automatique et une résilience régionale au sein du RTO et du RPO.
Exemple d'architecture de niveau 2
| Criticité d'application | Panne zonale | Panne régionale |
|---|---|---|
| Niveau 2 | RTO : 4 heures RPO : zéro |
RTO : 24 heures RPO : 4 heures |
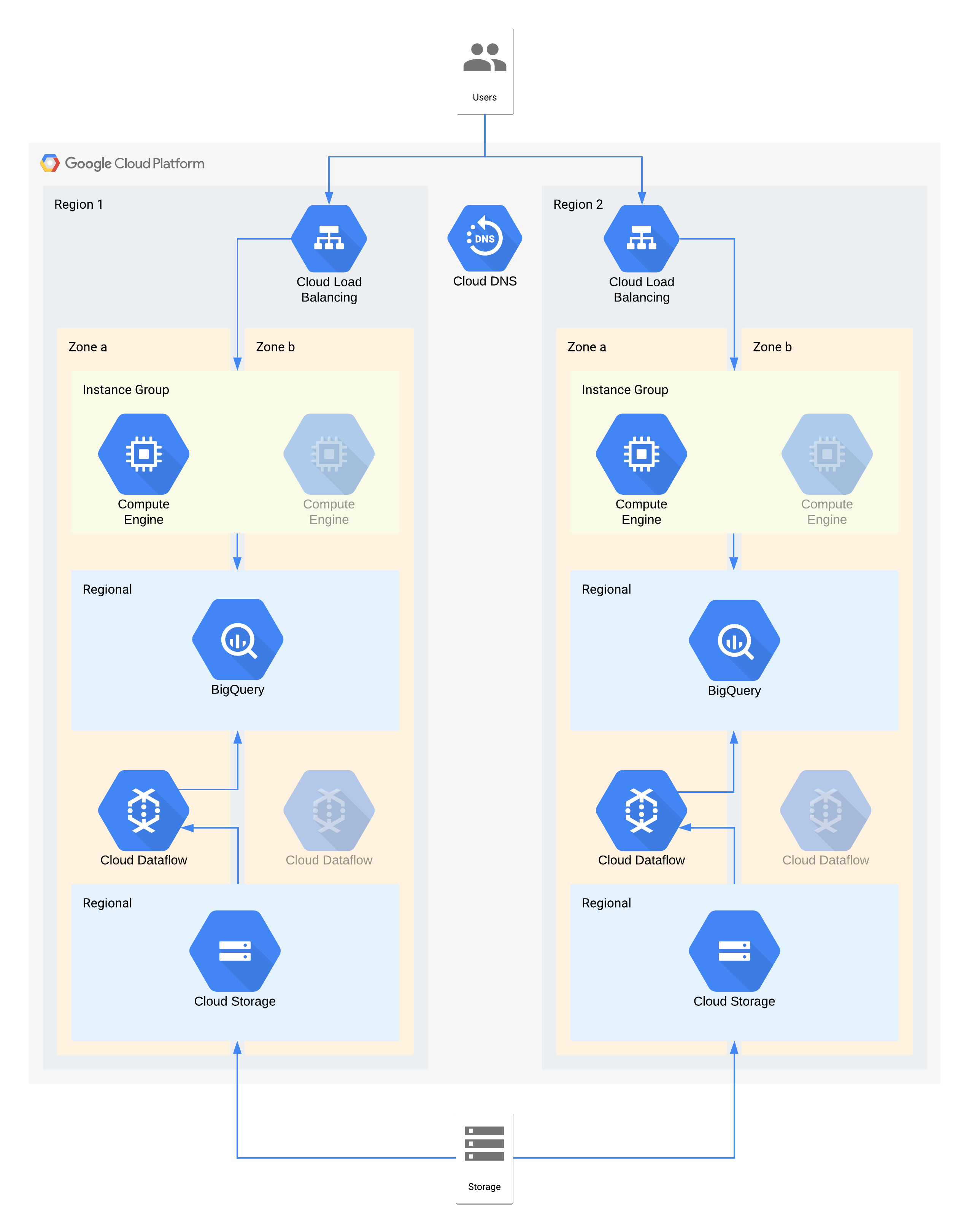
Cette architecture décrit un entrepôt de données avec des utilisateurs internes qui se connectent à une couche de visualisation d'instances de calcul, ainsi qu'une couche d'ingestion et de transformation de données qui remplit l'entrepôt de données backend.
Certains composants individuels de cette architecture n'acceptent pas directement le RPO requis pour leur niveau. Toutefois, grâce à la façon dont ces composants sont associés, le service global répond aux exigences en matière de RPO. Ici, comme Dataflow est un produit zonal, suivez les recommandations de la conception à haute disponibilité pour éviter toute perte de données lors d'une panne. Cependant, la couche Cloud Storage est la source fiable de ces données et accepte un RPO de zéro. Par conséquent, vous pouvez réingérer toutes les données perdues dans BigQuery en utilisant la zone b en cas de panne dans la zone a.
Principales décisions en termes d'architecture pour les pannes zonales - RTO de 4 heures et RPO de zéro :
- Un équilibreur de charge est utilisé pour fournir un point d'accès évolutif aux utilisateurs, ce qui permet le basculement automatique vers une autre zone. Même si le RTO est de 4 heures, les modifications manuelles des adresses IP ou même les mises à jour DNS peuvent prendre plus de temps que prévu.
- Un groupe d'instances géré régional pour la couche de calcul de visualisation des données est configuré avec plusieurs zones, mais avec des ressources minimales. Ainsi, les coûts sont optimisés et les machines virtuelles peuvent toujours faire l'objet d'un scaling horizontal rapide.
- Le service Cloud Storage régional est utilisé en tant que couche de préproduction pour l'ingestion initiale des données, ce qui permet de fournir une résilience de zone automatique.
- Dataflow est employé pour extraire des données de Cloud Storage et les transformer avant de les charger dans BigQuery. En cas de panne zonale, il s'agit d'un processus sans état qui peut être redémarré dans une autre zone.
- BigQuery fournit le backend de l'entrepôt de données pour l'interface de visualisation des données. En cas de panne zonale, toutes les données perdues sont réingérées à partir de Cloud Storage.
Principales décisions en termes d'architecture pour les pannes régionales - RTO de 24 heures et RPO de 4 heures :
- Un équilibreur de charge dans chaque région est utilisé pour fournir un point d'accès évolutif aux utilisateurs. Cloud DNS est employé pour fournir un basculement régional orchestré, mais manuel, dans la mesure où l'infrastructure de la région 2 n'est rendue disponible qu'en cas de panne régionale.
- Un groupe d'instances géré régional pour la couche de calcul de visualisation des données est configuré avec plusieurs zones, mais avec des ressources minimales. Cette opération n'est pas possible avant la reconfiguration de l'équilibreur de charge, mais elle ne nécessite aucune intervention manuelle.
- Le service Cloud Storage régional est utilisé en tant que couche de préproduction pour l'ingestion initiale des données. Le chargement est effectué simultanément dans les deux régions afin de répondre aux exigences en matière de RPO.
- Dataflow est employé pour extraire des données de Cloud Storage et les transformer avant de les charger dans BigQuery. En cas de panne régionale, les données les plus récentes de Cloud Storage sont ainsi insérées dans BigQuery.
- BigQuery fournit le backend de l'entrepôt de données. En situation normale, les données de l'entrepôt sont actualisées de façon intermittente. En cas de panne régionale, les données les plus récentes sont réingérées à partir de Cloud Storage via Dataflow.
Exemple d'architecture de niveau 1
| Criticité d'application | Panne zonale | Panne régionale |
|---|---|---|
| Niveau 1 (le plus important) |
RTO : zéro RPO : zéro |
RTO : 4 heures RPO : 1 heure |
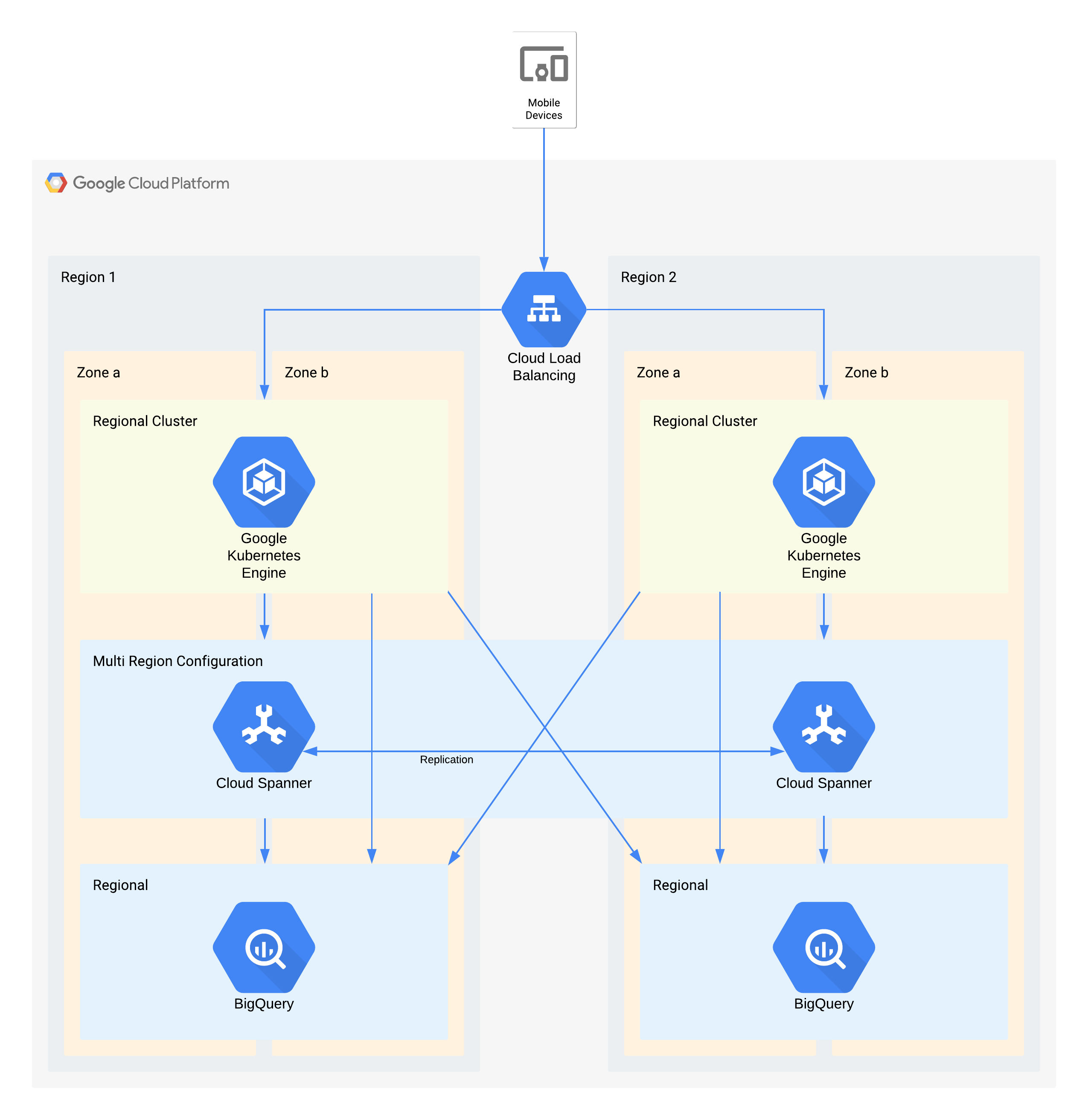
Cette architecture décrit une infrastructure backend d'application mobile avec des utilisateurs externes qui se connectent à un ensemble de microservices exécutés dans GKE. Spanner fournit la couche de stockage de données backend pour les données en temps réel, et les données de l'historique sont transmises à un lac de données BigQuery dans chaque région.
Ici aussi, certains composants individuels de cette architecture n'acceptent pas directement le RPO requis pour leur niveau. Mais grâce à la façon dont les composants sont associés, le service global accepte ce RPO. Dans ce cas, BigQuery est utilisé pour les requêtes analytiques. Chaque région reçoit simultanément des données de Spanner.
Principales décisions en termes d'architecture pour les pannes zonales - RTO de zéro et RPO de zéro :
- Un équilibreur de charge est utilisé pour fournir un point d'accès évolutif aux utilisateurs, ce qui permet le basculement automatique vers une autre zone.
- Un cluster GKE régional est utilisé pour la couche d'application qui est configurée avec plusieurs zones. Cela permet d'atteindre le RTO de zéro dans chaque région.
- Le service Spanner multirégional est utilisé en tant que couche de persistance des données, fournissant ainsi une résilience automatique des données de zone et une cohérence des transactions.
- BigQuery fournit la fonctionnalité d'analyse de l'application. Chaque région reçoit indépendamment des données de Spanner et est accessible indépendamment par l'application.
Principales décisions en termes d'architecture pour les pannes régionales - RTO de 4 heures et RPO de 1 heure :
- Un équilibreur de charge est utilisé pour fournir un point d'accès évolutif aux utilisateurs, ce qui permet le basculement automatique vers une autre région.
- Un cluster GKE régional est utilisé pour la couche d'application qui est configurée avec plusieurs zones. En cas de panne régionale, le cluster situé dans la région alternative fait l'objet d'un scaling automatique pour supporter la charge de traitement supplémentaire.
- Le service Spanner multirégional est utilisé en tant que couche de persistance des données, fournissant ainsi une résilience automatique des données régionales et une cohérence des transactions. Il s'agit du composant clé qui permet d'atteindre le RPO interrégional de 1 heure.
- BigQuery fournit la fonctionnalité d'analyse de l'application. Chaque région reçoit indépendamment des données de Spanner et est accessible indépendamment par l'application. Cette architecture compense le composant BigQuery en lui permettant de satisfaire aux exigences globales de l'application.
Annexe : documentation de référence produit
Cette section décrit l'architecture et les fonctionnalités de reprise après sinistre des produits Google Cloudles plus couramment utilisés dans les applications clientes et pouvant facilement répondre à vos exigences en matière de reprise après sinistre.
Thèmes communs
De nombreux produits Google Cloud proposent des configurations régionales ou multirégionales. Les produits régionaux sont résilients aux pannes zonales, tandis que les produits multirégionaux et mondiaux sont résilients aux pannes régionales. En général, cela signifie que lors d'une panne, votre application subit une perturbation minimale. Afin de parvenir à ce résultat, Google suit plusieurs approches architecturales courantes qui reflètent les conseils d'architecture ci-dessus.
Déploiement redondant : les backends d'applications et la solution de stockage des données sont déployés dans plusieurs zones d'une même région et dans plusieurs régions d'un même emplacement multirégional. Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
Réplication des données : les produits utilisent la réplication synchrone ou asynchrone sur les emplacements redondants.
La réplication synchrone signifie que lorsque votre application effectue un appel d'API pour créer ou modifier des données stockées par le produit, une réponse positive n'est obtenue qu'une fois que le produit a écrit les données dans plusieurs emplacements. La réplication synchrone garantit que vous ne perdrez pas l'accès à vos données lors d'une panne d'infrastructure Google Cloud , car toutes vos données sont disponibles dans l'un des emplacements de backend disponibles.
Bien que cette technique fournisse une protection maximale des données, elle peut présenter des compromis en termes de latence et de performances. Les produits multirégionaux qui utilisent la réplication synchrone font face à ce compromis de manière significative, et subissent généralement une latence supplémentaire de plusieurs dizaines ou centaines de millisecondes.
La réplication asynchrone signifie que lorsque votre application effectue un appel d'API pour créer ou modifier des données stockées par le produit, une réponse positive n'est obtenue qu'une fois que le produit a écrit les données dans un emplacement. Après votre requête d'écriture, le produit réplique vos données dans des emplacements supplémentaires.
Cette technique fournit une latence plus faible et un débit supérieur au niveau de l'API par rapport à la réplication synchrone, mais au détriment de la protection des données. Si l'emplacement dans lequel vous avez écrit des données subit une panne avant la fin de la réplication, vous perdez l'accès à ces données jusqu'à ce que la panne d'emplacement soit résolue.
Gestion des pannes grâce à l'équilibrage de charge : Google Cloud utilise l'équilibrage de charge logicielle pour acheminer les requêtes vers les backends d'applications appropriés. Comparée à d'autres approches telles que l'équilibrage de charge DNS, celle-ci réduit le temps mis par le système pour répondre à une panne. Lorsqu'une Google Cloud panne d'emplacement se produit, l'équilibreur de charge détecte rapidement que le backend déployé à cet emplacement n'est plus opérationnel et dirige toutes les requêtes vers un backend situé dans un autre emplacement. Ainsi, le produit peut continuer de diffuser les requêtes de votre application pendant une panne d'emplacement. Une fois la panne d'emplacement résolue, l'équilibreur de charge détecte que les backends de produit sont disponibles à cet emplacement et reprend la transmission du trafic.
Access Context Manager
Access Context Manager permet aux entreprises de configurer des niveaux d'accès en fonction d'une stratégie définie à partir des attributs d'une requête. Les stratégies sont mises en miroir au niveau régional.
En cas de panne zonale, les requêtes envoyées aux zones indisponibles sont diffusées automatiquement et de manière transparente depuis d'autres zones disponibles de la région.
En cas de panne régionale, les calculs de stratégie de la région concernée ne sont plus disponibles jusqu'à ce que la région redevienne disponible.
Access Transparency
Access Transparency permet aux administrateurs d'organisation Google Cloud de définir un contrôle d'accès précis et basé sur des attributs pour les projets et les ressources dans Google Cloud. Google doit parfois accéder aux données client à des fins administratives. Lorsque nous accédons aux données client, Access Transparency fournit des journaux d'accès aux clients Google Cloudconcernés. Ces journaux Access Transparency permettent de garantir l'engagement de Google en termes de sécurité des données et de transparence en matière de traitement des données.
Access Transparency est résilient aux pannes zonales et régionales. En cas de panne zonale ou régionale, Access Transparency continue de traiter les journaux d'accès administratifs dans une autre zone ou région.
AlloyDB pour PostgreSQL
AlloyDB pour PostgreSQL est un service de base de données entièrement géré compatible avec PostgreSQL. AlloyDB pour PostgreSQL offre une haute disponibilité dans une région via les nœuds redondants de son instance principale, qui sont situés dans deux zones différentes de la région. L'instance principale conserve la disponibilité régionale en déclenchant un basculement automatique vers la zone de secours si la zone active rencontre un problème. Le stockage régional garantit la durabilité des données en cas de perte d'une zone.
Comme autre méthode de reprise après sinistre, AlloyDB pour PostgreSQL utilise la réplication interrégionale pour fournir des fonctionnalités de reprise après sinistre en répliquant de manière asynchrone les données de votre cluster principal dans des clusters secondaires situés dans des régions Google Cloud distinctes.
Indisponibilité d'une zone : en fonctionnement normal, seul l'un des deux nœuds d'une instance principale à haute disponibilité est actif et diffuse toutes les écritures de données. Ce nœud actif stocke les données dans une couche de stockage régionale distincte du cluster.
AlloyDB pour PostgreSQL détecte automatiquement les défaillances au niveau d'une zone et déclenche un basculement pour restaurer la disponibilité de la base de données. Lors du basculement, AlloyDB pour PostgreSQL démarre la base de données sur le nœud de secours, qui est déjà provisionné dans une zone différente. Les nouvelles connexions à la base de données sont automatiquement acheminées vers cette zone.
Du point de vue d'une application cliente, l'indisponibilité d'une zone ressemble à une interruption temporaire de la connectivité réseau. Une fois le basculement terminé, un client peut se reconnecter à l'instance à la même adresse, en utilisant les mêmes identifiants, sans perdre de données.
Indisponibilité régionale : la réplication interrégionale utilise la réplication asynchrone, qui permet à l'instance principale d'effectuer un commit des transactions avant qu'elles ne soient validées sur les instances répliquées. Le délai entre le commit d'une transaction sur l'instance principale et le commit d'une transaction sur l'instance répliquée est appelé délai de réplication. Le délai entre le moment où l'instance principale génère le journal WAL et le moment où le journal WAL atteint l'instance répliquée est appelé délai de vidage. Le délai de réplication et le délai de vidage dépendent de la configuration de l'instance de base de données et de la charge de travail générée par l'utilisateur.
En cas d'indisponibilité régionale, vous pouvez promouvoir les clusters secondaires d'une autre région en cluster principal autonome accessible en écriture. Ce cluster promu ne réplique plus les données du cluster principal d'origine auquel il était auparavant associé. En raison du délai de vidage, les données peuvent être perdues, car certaines transactions du cluster principal d'origine peuvent ne pas être transmises au cluster secondaire.
Le RPO de réplication interrégionale est affecté par l'utilisation du processeur du cluster principal et la distance physique entre la région du cluster principal et la région du cluster secondaire. Pour optimiser le RPO, nous vous recommandons de tester votre charge de travail avec une configuration comprenant une instance répliquée pour établir une limite sûre de transactions par seconde (TPS), qui correspond au nombre de TPS le plus élevé n'augmentant pas le délai de vidage. Si votre charge de travail dépasse la limite sûre de TPS, le délai de vidage augmente et peut affecter le RPO. Pour limiter la latence du réseau, choisissez des paires de régions sur le même continent.
Pour en savoir plus sur la surveillance de la latence du réseau et d'autres métriques AlloyDB pour PostgreSQL, consultez Surveiller des instances.
Anti Money Laundering AI
Anti Money Laundering AI (AML AI) fournit une API pour aider les institutions financières internationales à détecter plus efficacement le blanchiment d'argent. Anti Money Laundering AI est une offre régionale, ce qui signifie que les clients peuvent choisir la région, mais pas les zones dont elle est composée. Les données et le trafic sont automatiquement équilibrés en charge entre les zones d'une même région. Les opérations (par exemple, la création d'un pipeline ou l'exécution d'une prédiction) font l'objet d'un scaling automatique en arrière-plan et sont équilibrées en charge entre les zones si nécessaire.
Indisponibilité d'une zone : AML AI stocke les données de ses ressources au niveau régional, répliquées de manière synchrone. Lorsqu'une opération de longue durée aboutit, les ressources peuvent être utilisées indépendamment des défaillances de zone. Le traitement est également répliqué sur plusieurs zones, mais cette réplication cible l'équilibrage de charge et non la haute disponibilité. L'indisponibilité d'une zone lors d'une opération peut donc entraîner l'échec de l'opération. Dans ce cas, relancez l'opération pour résoudre le problème. Lorsqu'une zone est indisponible, les temps de traitement peuvent être affectés.
Indisponibilité régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent créer leurs ressources AML AI. Les données ne sont jamais répliquées entre les régions. Le trafic client n'est jamais acheminé vers une autre région par AML AI. En cas de défaillance d'une région, AML AI redevient disponible dès que la défaillance est résolue.
Clés API
Les clés API fournissent une gestion des ressources de clé API évolutive pour un projet. Les clés API sont un service global, ce qui signifie qu'elles sont visibles et accessibles depuis n'importe quel emplacement Google Cloud . Ses données et métadonnées sont stockées de manière redondante dans plusieurs zones et régions.
Les clés API sont résilientes aux pannes zonales et régionales. En cas de panne zonale ou régionale, les clés API continuent de diffuser les requêtes depuis une autre zone de la même région ou d'une région différente.
Pour plus d'informations sur les clés API, consultez la page Présentation de l'API des clés API.
Apigee
Apigee fournit une plate-forme sécurisée, évolutive et fiable pour développer et gérer des API. Apigee propose des déploiements régionaux et multirégionaux.
Panne zonale : es données d'exécution client sont répliquées dans plusieurs zones de disponibilité. Par conséquent, une panne dans une seule zone n'a aucun impact sur Apigee.
Panne régionale : pour les instances Apigee à région unique, si une région tombe en panne, les instances Apigee ne sont pas disponibles dans cette région et ne peuvent pas être restaurées dans différentes régions. Pour les instances Apigee multirégionales, les données sont répliquées de manière asynchrone dans toutes les régions. Par conséquent, la défaillance d'une région ne réduit pas entièrement le trafic. Toutefois, il est possible que vous ne puissiez pas accéder aux données non validées dans la région concernée. Vous pouvez détourner le trafic des régions non opérationnelles. Pour obtenir un basculement automatique du trafic, vous pouvez configurer le routage réseau à l'aide de groupes d'instances gérés (MIG).
AutoML Translation
AutoML Translation est un service de traduction automatique qui vous permet d'importer vos propres données (paires de phrases) pour entraîner des modèles personnalisés en fonction des besoins spécifiques à votre domaine.
Panne zonale : AutoML Translation dispose de serveurs de calcul actifs dans plusieurs zones et régions. Il est également compatible avec la réplication synchrone des données entre les zones des régions. Ces fonctionnalités aident AutoML Translation à effectuer un basculement instantané sans perte de données pour les défaillances de zones, et sans nécessiter d'entrée ni d'ajustements de la part des clients.
Panne régionale : en cas de défaillance régionale, AutoML Translation n'est pas disponible.
AutoML Vision
AutoML Vision fait partie de Vertex AI. Il offre un framework unifié pour créer des ensembles de données, importer des données, entraîner des modèles et les diffuser pour la prédiction en ligne et la prédiction par lot.
AutoML Vision est une offre régionale. Les clients peuvent choisir la région à partir de laquelle ils souhaitent lancer un job, mais pas les zones spécifiques de cette région. Le service équilibre automatiquement la charge de travail sur différentes zones de la région.
Panne zonale : AutoML Vision stocke les métadonnées des jobs au niveau régional et les écrit de manière synchrone dans les zones de la région. Les jobs sont lancés dans une zone spécifique, sélectionnée par Cloud Load Balancing.
Tâches d'entraînement AutoML Vision : une panne zonale entraîne l'échec de toutes les tâches en cours d'exécution, et l'état de la tâche est mis à jour. Si une tâche échoue, réessayez immédiatement. La nouvelle tâche est acheminée vers une zone disponible.
Jobs de prédiction par lots AutoML Vision : la prédiction par lots est basée sur Vertex AI Batch Prediction. En cas de panne zonale, le service relance automatiquement le job en le redirigeant vers les zones disponibles. Si plusieurs tentatives échouent, l'état du job passe à "Échec". Les requêtes utilisateur suivantes pour exécuter la tâche sont redirigées vers une zone disponible.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent exécuter leurs jobs. Les données ne sont jamais répliquées entre les régions. En cas de panne régionale, le service AutoML Vision n'est pas disponible dans cette région. Elle redevient disponible une fois la panne résolue. Nous recommandons aux clients d'utiliser plusieurs régions afin qu'ils puissent exécuter leurs tâches. En cas de panne régionale, redirigez les jobs vers une autre région disponible.
Lot
Batch est un service entièrement géré permettant de mettre en file d'attente, planifier et exécuter des tâches par lot sur Google Cloud. Les paramètres de traitement par lots sont définis au niveau de la région. Les clients doivent choisir une région pour envoyer leurs tâches par lot, et non une zone dans une région. Lorsqu'une tâche est envoyée, Batch écrit de manière synchrone les données client dans plusieurs zones. Toutefois, les clients peuvent spécifier les zones dans lesquelles les VM par lot exécutent des tâches.
Défaillance zonale : en cas de défaillance d'une seule zone, les tâches exécutées dans cette zone échouent également. Si les tâches ont des paramètres de nouvelle tentative, Batch bascule automatiquement ces tâches vers d'autres zones actives de la même région. Le basculement automatique est soumis à la disponibilité des ressources dans les zones actives de la même région. Les tâches nécessitant des ressources zonales (telles que des VM, des GPU ou des disques persistants zonaux) qui ne sont disponibles que dans la zone défaillante sont mises en file d'attente jusqu'à la récupération de la zone défaillante ou jusqu'à ce que les délais avant expiration des tâches soient atteints. Dans la mesure du possible, nous recommandons aux clients de laisser Batch choisir des ressources zonales pour exécuter leurs tâches. Cela permet de garantir que les tâches sont résilientes aux pannes zonales.
Défaillance régionale : en cas de défaillance régionale, le plan de contrôle du service n'est pas disponible dans la région. Le service ne réplique pas les données ni les requêtes de redirection entre les régions. Nous recommandons aux clients d'utiliser plusieurs régions pour exécuter leurs tâches et rediriger les tâches vers une autre région en cas de défaillance d'une région.
Prévention des menaces et protection des données de Chrome Enterprise Premium
La prévention des menaces et la protection des données de Chrome Enterprise Premium fait partie de la solution Chrome Enterprise Premium. Elle étend Chrome avec diverses fonctionnalités de sécurité, telles que la protection contre les logiciels malveillants et l'hameçonnage, la Protection contre la perte de données, les règles de filtrage des URL et les rapports de sécurité.
Les administrateurs Chrome Enterprise Premium peuvent choisir de stocker les contenus principaux du client qui ne respectent pas les règlements sur les logiciels malveillants ou sur la Protection contre la perte de données dans les événements de journaux des règles Google Workspace et/ou dans Cloud Storage en vue d'une investigation ultérieure. Les événements de journaux des règles Google Workspace sont alimentés par une base de données Spanner multirégionale. La détection des cas de non-respect des règles par Chrome Enterprise Premium peut prendre plusieurs heures. Pendant cette période, toutes les données non traitées sont sujettes à une perte de données due à une indisponibilité zonale ou régionale. Une fois une infraction détectée, le contenu qui ne respecte pas vos règles est consigné dans les événements du journal des règles Google Workspace et/ou dans Cloud Storage.
Panne zonale et régionale : Étant donné que la prévention des menaces et la protection des données de Chrome Enterprise Premium sont multizonales et multirégionales, elles peuvent survivre à une perte complète et non planifiée d'une zone ou d'une région, sans perte de disponibilité. Il offre ce niveau de fiabilité en redirigeant le trafic vers son service dans d'autres zones ou régions actives. Toutefois, comme la prévention des menaces et la protection des données de Chrome Enterprise Premium peut mettre plusieurs heures à détecter les cas de non respect des règlements sur les logiciels malveillants ou sur la Protection contre la perte de données, toutes les données non traitées dans une zone ou une région spécifique sont susceptibles d'être perdues en raison d'une indisponibilité zonale ou régionale.
BigQuery
BigQuery est un entrepôt de données cloud sans serveur, hautement évolutif et économique, conçu pour optimiser l'agilité des entreprises. BigQuery accepte les types d'emplacement suivants pour les ensembles de données utilisateur :
- Une région : emplacement géographique spécifique, par exemple l'Iowa (
us-central1) ou Montréal (northamerica-northeast1). - Un emplacement multirégional : secteur géographique de grande étendue contenant au moins deux lieux géographiques, tel que les États-Unis (
US) ou l'Europe (EU).
Dans les deux cas, les données sont stockées de manière redondante dans deux zones d'une même région de l'emplacement sélectionné. Les données écrites dans BigQuery sont écrites de manière synchrone dans les zones principale et secondaire. Cette mise en œuvre vous fournit une protection contre l'indisponibilité d'une zone de la région, mais pas contre une panne régionale.
Binary Authorization
L'autorisation binaire est un produit de sécurité de la chaîne d'approvisionnement logicielle pour GKE et Cloud Run.
Toutes les stratégies d'autorisation binaire sont répliquées dans plusieurs zones de chaque région. La réplication permet aux opérations de lecture de stratégies d'autorisation binaire de se rétablir en cas de défaillances d'autres régions. La réplication rend également les opérations de lecture tolérantes aux défaillances de zone dans chaque région.
Les opérations d'application de l'autorisation binaire sont résilientes face aux pannes zonales, mais elles ne sont pas résilientes face aux pannes régionales. Les opérations d'application s'exécutent dans la même région que le cluster GKE ou le job Cloud Run à l'origine de la requête. Par conséquent, en cas de panne régionale, il n'y a aucune exécution en cours pour envoyer des requêtes d'application de l'autorisation binaire.
Gestionnaire de certificats
Le gestionnaire de certificats vous permet d'acquérir et de gérer des certificats Transport Layer Security (TLS) à utiliser avec différents types d'équilibrage de charge Cloud Load Balancing.
En cas de panne zonale, les gestionnaires de certificats régional et global sont résilients aux pannes zonales, car les jobs et les bases de données sont redondants dans plusieurs zones d'une même région. En cas de panne régionale, le gestionnaire de certificats global est résilient aux pannes régionales, car les jobs et les bases de données sont redondants dans plusieurs régions. Le gestionnaire de certificats régional est un produit régional. Il ne peut donc pas résister à une défaillance régionale.
Cloud Intrusion Detection System
Cloud IDS (Cloud Intrusion Detection System) est un service zonal qui fournit des points de terminaison IDS à portée zonale. Ces points de terminaison traitent le trafic des VM d'une zone spécifique et ne sont donc pas tolérants aux pannes zonales ou régionales.
Panne zonale : Cloud IDS est lié aux instances de VM. Si un client prévoit d'atténuer les pannes zonales en déployant des VM dans plusieurs zones (manuellement ou via des groupes d'instances gérés régionaux), il devra également déployer des points de terminaison Cloud IDS dans ces zones.
Panne régionale : Cloud IDS est un produit régional. Il ne fournit aucune fonctionnalité interrégionale. Une défaillance régionale entraînera l'arrêt de toutes les fonctionnalités Cloud IDS dans toutes les zones de cette région.
Solution SIEM pour les opérations de sécurité Google
Google Security Operations SIEM (qui fait partie de Google Security Operations) est un service entièrement géré qui aide les équipes de sécurité à détecter, examiner et contrer les menaces.
Google Security Operations SIEM propose des offres régionales et multirégionales.
Dans les offres régionales, les données et le trafic sont automatiquement équilibrés en charge entre les zones de la région choisie, et les données sont stockées de manière redondante entre les zones de disponibilité de la région.
Les emplacements multirégionaux sont géoredondants. Cette redondance offre un ensemble de protections plus étendu que le stockage régional. Cela permet également de s'assurer que le service continue de fonctionner même en cas de perte d'une région entière.
La majorité des chemins d'ingestion de données répliquent les données client de manière synchrone dans plusieurs emplacements. Lorsque les données sont répliquées de manière asynchrone, il existe une période (objectif de point de récupération ou RPO) pendant laquelle les données ne sont pas encore répliquées dans plusieurs emplacements. C'est le cas lors de l'ingestion avec des flux dans les déploiements multirégionaux. Après le RPO, les données sont disponibles dans plusieurs emplacements.
Panne zonale :
Déploiements régionaux : les requêtes sont traitées à partir de n'importe quelle zone de la région. Les données sont répliquées de manière synchrone dans plusieurs zones. En cas de panne zonale, les zones restantes continuent de diffuser le trafic et de traiter les données. Le provisionnement redondant et le scaling automatisé de Google Security Operations SIEM permettent de garantir que le service reste opérationnel dans les zones restantes lors des changements de charge.
Déploiements multirégionaux : les pannes zonales équivalent aux pannes régionales.
Panne régionale :
Déploiements régionaux : Google Security Operations SIEM stocke toutes les données client dans une seule région et le trafic n'est jamais acheminé entre les régions. En cas de panne régionale, la solution SIEM des opérations de sécurité Google n'est pas disponible dans la région tant que la panne n'est pas résolue.
Déploiements multirégionaux (sans flux) : les requêtes sont traitées à partir de n'importe quelle région du déploiement multirégional. Les données sont répliquées de manière synchrone dans plusieurs régions. En cas de panne régionale, les régions restantes continuent de diffuser le trafic et de traiter les données. Le provisionnement redondant et le scaling automatisé de Google Security Operations SIEM permettent de s'assurer que le service reste opérationnel dans les régions restantes lors de ces changements de charge.
Déploiements multirégionaux (avec des flux) : les requêtes sont traitées à partir de n'importe quelle région du déploiement multirégional. Les données sont répliquées de manière asynchrone dans plusieurs régions avec le RPO fourni. En cas de panne dans une région entière, seules les données stockées après le RPO sont disponibles dans les régions restantes. Les données incluses dans la période RPO peuvent ne pas être répliquées.
Inventaire des éléments cloud
L'inventaire des éléments cloud est un service global résilient et hautes performances qui gère un dépôt de métadonnées de ressources et de règles Google Cloud . L'inventaire des éléments cloud fournit des outils de recherche et d'analyse qui vous aident à suivre les éléments déployés dans plusieurs organisations, dossiers et projets.
En cas de panne zonale, l'inventaire des éléments cloud continue de diffuser les requêtes provenant d'une autre zone de la même région ou d'une région différente.
En cas de panne régionale, l'inventaire des éléments cloud continue de diffuser les requêtes provenant d'autres régions.
Bigtable
Bigtable est un service de base de données NoSQL entièrement géré et hautes performances pour les charges de travail analytiques et opérationnelles volumineuses.
Présentation de la réplication Bigtable
Bigtable offre une fonctionnalité de réplication flexible et entièrement configurable, que vous pouvez utiliser pour augmenter la disponibilité et la durabilité de vos données en les copiant sur des clusters situés dans plusieurs régions, ou dans plusieurs zones d'une même région. Bigtable peut également assurer le basculement automatique de vos requêtes lorsque vous utilisez la réplication.
Lorsque vous utilisez des configurations multizones ou multirégionales avec routage multicluster en cas de panne zonale ou régionale, Bigtable redirige automatiquement le trafic et envoie les requêtes à partir du cluster disponible le plus proche. Étant donné que la réplication Bigtable est asynchrone et cohérente à terme, des modifications très récentes des données concernant l'emplacement de la panne peuvent être indisponibles si elles n'ont pas encore été répliquées dans d'autres emplacements.
Considérations sur les performances
Lorsque les besoins en ressources de processeur dépassent la capacité disponible pour le nœud, Bigtable donne toujours la priorité aux requêtes entrantes, par rapport au trafic de réplication.
Pour en savoir plus sur l'utilisation de la réplication Bigtable avec votre charge de travail, consultez la page Présentation de la réplication Cloud Bigtable et des exemples de paramètres de réplication.
Les nœuds Bigtable sont utilisés à la fois pour diffuser les requêtes entrantes et pour répliquer les données d'autres clusters. En plus de conserver suffisamment de nœuds par cluster, vous devez également vous assurer que vos applications utilisent une conception de schéma appropriée pour éviter les hotspots, qui peuvent entraîner une utilisation excessive ou déséquilibrée du processeur et accroître la latence de réplication.
Pour en savoir plus sur la conception de votre schéma d'application afin d'optimiser les performances et l'efficacité de Bigtable, consultez la page Bonnes pratiques liées à la conception de schémas.
Surveillance
Bigtable propose plusieurs moyens de surveiller visuellement la latence de réplication de vos instances et clusters, à l'aide des graphiques pour la réplication disponibles dans la Google Cloud console.
Vous pouvez également surveiller de manière automatisée les métriques de réplication Bigtable à l'aide de l'API Cloud Monitoring.
Certificate Authority Service
Certificate Authority Service (CA Service) permet aux clients de simplifier, d'automatiser et de personnaliser le déploiement, la gestion et la sécurité d'autorités de certification (CA) privées et d'émettre de manière résiliente des certificats à grande échelle.
Panne zonale : CA Service est résilient aux pannes zonales, car son plan de contrôle est redondant dans plusieurs zones d'une région. En cas de panne zonale, CA Service continue de diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région. Les données étant répliquées de manière synchrone, il n'y a aucune perte ni corruption de données.
Panne régionale : CA Service est un produit régional et ne peut donc pas résister à une défaillance régionale. Si vous avez besoin de résilience en cas de défaillance régionale, créez des autorités de certification émettrices dans deux régions différentes. Créez l'autorité de certification émettrice principale dans la région où vous avez besoin de certificats. Créez une autorité de certification de remplacement dans une autre région. Utilisez le remplacement en cas de panne de la région de l'autorité de certification subordonnée principale. Si nécessaire, les deux autorités de certification peuvent être associées à la même autorité de certification racine.
Cloud Billing
L'API Cloud Billing permet aux développeurs de gérer la facturation de leurs projetsGoogle Cloud de façon automatisée. L'API Cloud Billing est conçue comme un système mondial dans lequel les mises à jour sont écrites de manière synchrone dans plusieurs zones et régions.
Défaillance zonale ou régionale : l'API Cloud Billing bascule automatiquement vers une autre zone ou région. Les requêtes individuelles peuvent échouer, mais une stratégie de nouvelle tentative doit autoriser les tentatives ultérieures à réussir.
Cloud Build
Cloud Build est un service qui exécute vos compilations sur Google Cloud.
Cloud Build est composé d'instances isolées régionalement qui répliquent les données de manière synchrone entre les zones de la région. Nous vous recommandons d'utiliser des régions Google Cloud spécifiques plutôt que la région globale, et de vous assurer que les ressources que votre compilation utilise (y compris les buckets de journaux, les dépôts Artifact Registry, etc.) sont alignées sur la région dans laquelle votre compilation s'exécute.
En cas de panne zonale, les opérations du plan de contrôle ne sont pas affectées. Toutefois, les compilations en cours d'exécution dans la zone défaillante seront retardées ou définitivement perdues. Les compilations nouvellement déclenchées seront automatiquement distribuées aux zones opérationnelles restantes.
En cas de défaillance régionale, le plan de contrôle est hors connexion et les compilations en cours d'exécution sont retardées ou définitivement perdues. Les déclencheurs, les pools de nœuds de calcul et les données de compilation ne sont jamais répliqués entre les régions. Nous vous recommandons de préparer des déclencheurs et des pools de nœuds de calcul dans plusieurs régions pour faciliter la résolution des pannes.
Cloud CDN
Cloud CDN assure la distribution et la mise en cache de contenu pour de nombreux emplacements du réseau de Google, afin de réduire la latence de diffusion pour les clients. Le contenu mis en cache est diffusé de la manière la plus optimale possible : lorsqu'une requête ne peut pas être diffusée par le cache Cloud CDN, elle est transmise aux serveurs d'origine, tels que les VM de backend ou les buckets Cloud Storage, où est stocké le contenu d'origine.
En cas de défaillance d'une zone ou d'une région, les caches des emplacements concernés sont indisponibles. Les requêtes entrantes sont acheminées vers des emplacements et des caches Google disponibles en périphérie. Si ces autres caches ne peuvent pas diffuser la requête, ils transfèrent la requête vers un serveur d'origine disponible. Si le serveur peut traiter la requête avec des données à jour, le contenu ne sera pas perdu. Un taux de défaut de cache plus élevé entraîne une augmentation des volumes de trafic au-delà de la normale sur les serveurs d'origine, lors du remplissage des caches. Les requêtes ultérieures sont diffusées à partir des caches non affectés par la panne zonale ou régionale.
Pour plus d'informations sur le comportement de Cloud CDN et de la mise en cache, consultez la documentation de Cloud CDN.
Cloud Composer
Cloud Composer est un service d'orchestration de workflows géré qui vous permet de créer, planifier, surveiller et gérer des workflows couvrant des clouds et des centres de données sur site. Les environnements Cloud Composer sont basés sur le projet Open Source Apache Airflow.
La disponibilité de l'API Cloud Composer n'est pas affectée par l'indisponibilité zonale. Lors d'une panne zonale, vous conservez l'accès à l'API Cloud Composer, y compris la possibilité de créer des environnements Cloud Composer.
Un environnement Cloud Composer possède un cluster GKE dans son architecture. Lors d'une panne zonale, les workflows du cluster peuvent être interrompus :
- Dans Cloud Composer 1, le cluster de l'environnement est une ressource zonale. Par conséquent, une panne zonale peut rendre le cluster indisponible. Les workflows exécutés au moment de la panne peuvent être arrêtés avant leur terme.
- Dans Cloud Composer 2, le cluster de l'environnement est une ressource régionale. Toutefois, les workflows exécutés sur des nœuds dans les zones affectées par une panne de zone peuvent être arrêtés avant la fin.
Dans les deux versions de Cloud Composer, une panne zonale peut entraîner l'arrêt des workflows partiellement exécutés, y compris les actions externes que vous avez configurées. Selon le workflow, cette situation peut entraîner des incohérences en externe, par exemple, si le workflow s'arrête au milieu d'une exécution en plusieurs étapes visant à modifier des datastores externes. Par conséquent, vous devez tenir compte du processus de reprise lorsque vous concevez votre workflow Airflow, et envisager comment détecter l'état des workflows partiellement non exécutés et réparer les modifications de données partielles.
Dans Cloud Composer 1, vous pouvez choisir de démarrer un nouvel environnement Cloud Composer dans une autre zone lors d'une panne zonale. Airflow conserve l'état de vos workflows dans sa base de données de métadonnées. Par conséquent, le transfert de ces informations vers un nouvel environnement Cloud Composer peut nécessiter des étapes supplémentaires et de la préparation.
Dans Cloud Composer 2, vous pouvez gérer les pannes zonales en configurant au préalable la reprise après sinistre avec des instantanés d'environnement. Lors d'une panne zonale, vous pouvez basculer vers un autre environnement en transférant l'état de vos workflows avec un instantané d'environnement. Seul Cloud Composer 2 est compatible avec la reprise après sinistre avec des instantanés d'environnement.
Cloud Data Fusion
Cloud Data Fusion est un service cloud natif entièrement géré d'intégration de données d'entreprise qui permet de créer et de gérer rapidement des pipelines de données. Il fournit trois éditions.
Les pannes zonales affectent les instances de l'édition Developer.
Les pannes régionales ont une incidence sur les instances de l'édition Basic et Enterprise.
Pour contrôler l'accès aux ressources, vous pouvez concevoir et exécuter des pipelines dans des environnements distincts. Cette séparation vous permet de concevoir un pipeline une fois, puis de l'exécuter dans plusieurs environnements. Vous pouvez récupérer les pipelines dans les deux environnements. Pour en savoir plus, consultez la page Sauvegarder et restaurer des données d'instance.
Les conseils suivants s'appliquent aux pannes régionales et zonales.
Pannes dans l'environnement de conception du pipeline
Dans l'environnement de conception, enregistrez les brouillons du pipeline en cas de panne. En fonction d'exigences RTO et RPO spécifiques, vous pouvez utiliser les brouillons enregistrés pour restaurer le pipeline dans une autre instance Cloud Data Fusion lors d'une panne.
Pannes dans l'environnement d'exécution du pipeline
Dans l'environnement d'exécution, vous démarrez le pipeline en interne avec des déclencheurs ou des planifications Cloud Data Fusion, ou en externe avec des outils d'orchestration tels que Cloud Composer. Pour pouvoir récupérer les configurations d'exécution des pipelines, sauvegardez les pipelines et les configurations, tels que les plug-ins et les programmations. En cas de panne, vous pouvez utiliser la sauvegarde pour répliquer une instance dans une région ou une zone non affectée.
Une autre façon de vous préparer aux pannes consiste à disposer de plusieurs instances dans les différentes régions avec la même configuration et le même pipeline défini. Si vous utilisez une orchestration externe, la charge des pipelines en cours d'exécution est automatiquement équilibrée entre les instances. Soyez particulièrement attentif à ce qu'aucune ressource (sources de données ou outils d'orchestration) ne soit liée à une région unique et utilisée par toutes les instances, car cela pourrait devenir un point de défaillance central en cas de panne. Par exemple, vous pouvez avoir plusieurs instances dans différentes régions et utiliser Cloud Load Balancing et Cloud DNS pour diriger les requêtes d'exécution du pipeline vers une instance non affectée par une panne (voir l'exemple d'architectures de niveau 1 et de niveau 3).
Pannes liées à d'autres services de données Google Cloud dans le pipeline
Votre instance peut utiliser d'autres services Google Cloud en tant que sources de données ou environnements d'exécution de pipeline, tels que Dataproc, Cloud Storage ou BigQuery. Ces services peuvent se trouver dans différentes régions. Lorsque l'exécution interrégionale est requise, l'échec de l'une ou l'autre région entraîne une interruption. Dans ce scénario, vous suivez la procédure standard de reprise après sinistre, en gardant à l'esprit que la configuration interrégionale avec des services critiques dans différentes régions est moins résiliente.
Cloud Deploy
Cloud Deploy fournit une livraison continue des charges de travail dans des services d'exécution tels que GKE et Cloud Run. Le service est composé d'instances régionales qui répliquent de manière synchrone les données entre les zones de la région.
Panne zonale : les opérations du plan de contrôle ne sont pas affectées. Cependant, les compilations Cloud Build (par exemple, les opérations de rendu ou de déploiement) qui s'exécutent lorsqu'une zone échoue sont retardées ou définitivement perdues. Lors d'une panne, la ressource Cloud Deploy qui a déclenché la compilation (une version ou un déploiement) affiche un état d'échec qui indique que l'opération sous-jacente a échoué. Vous pouvez recréer la ressource pour démarrer une nouvelle compilation dans les zones de fonctionnement restantes. Par exemple, créez un déploiement en redéployant la version sur une cible.
Panne régionale : les opérations du plan de contrôle, ainsi que les données de Cloud Deploy, ne sont pas disponibles jusqu'à la restauration de la région. Pour faciliter la restauration du service en cas de panne régionale, nous vous recommandons de stocker votre pipeline de diffusion et vos définitions de cibles dans le contrôle des sources. Vous pouvez utiliser ces fichiers de configuration pour recréer vos pipelines Cloud Deploy dans une région fonctionnelle. Lors d'une panne, les données sur les versions existantes sont perdues. Créez une version pour continuer à déployer le logiciel sur vos cibles.
Cloud DNS
Cloud DNS est un système de noms de domaine (DNS) global, résilient et offrant de hautes performances. C'est un moyen économique de publier vos noms de domaine dans le DNS mondial.
En cas de panne zonale, Cloud DNS continue à diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région, ou d'une région différente. Les mises à jour des enregistrements Cloud DNS sont répliquées de manière synchrone dans les zones de la région où elles sont reçues. Il n'y a par conséquent aucune perte de données.
En cas de panne régionale, Cloud DNS continue à diffuser les requêtes provenant d'autres régions. Il est possible que les mises à jour très récentes des enregistrements Cloud DNS soient indisponibles, car les mises à jour sont d'abord traitées dans une seule région avant d'être répliquées de manière asynchrone dans d'autres régions.
API Cloud Healthcare
L'API Cloud Healthcare, un service de stockage et de gestion des données de santé, est conçue pour fournir une haute disponibilité et une protection contre les défaillances zonales et régionales (en fonction de la configuration choisie).
Configuration régionale : dans sa configuration par défaut, l'API Cloud Healthcare offre une protection contre les défaillances zonales. Le service est déployé dans trois zones d'une même région, et les données sont également dupliquées sur différentes zones de la région. En cas de défaillance zonale affectant la couche de service ou la couche de données, les zones restantes prennent le relais sans interruption. Avec la configuration régionale, si l'intégralité de la région où réside le service subit une panne, le service sera indisponible jusqu'à ce que la région soit de nouveau en ligne. Dans le cas imprévu d'une destruction physique d'une région entière, les données stockées dans cette région seront perdues.
Configuration multirégionale : dans sa configuration multirégionale, l'API Cloud Healthcare est déployée dans trois zones appartenant à trois régions différentes. Les données sont également répliquées sur trois régions. Cela évite la perte de service en cas de panne d'une région entière, car les régions restantes prennent automatiquement le relais. Les données structurées, telles que FHIR, sont répliquées de manière synchrone dans plusieurs régions, ce qui les protège contre la perte de données en cas d'indisponibilité régionale. Les données stockées dans des buckets Cloud Storage, telles que DICOM et Dictation, ou des objets HL7v2/FHIR volumineux, sont répliquées de manière asynchrone dans plusieurs régions.
Cloud Identity
Les services Cloud Identity sont répartis sur plusieurs régions et utilisent l'équilibrage de charge dynamique. Cloud Identity ne permet pas aux utilisateurs de sélectionner un champ d'application pour les ressources. Si une zone ou une région spécifique subit une panne, le trafic est automatiquement distribué vers d'autres zones ou régions.
Dans la plupart des cas, les données persistantes sont mises en miroir dans plusieurs régions grâce à la réplication synchrone. Pour des raisons de performances, certains systèmes (tels que les caches ou les modifications affectant un grand nombre d'entités) sont répliqués de manière asynchrone entre les régions. Si la région principale qui contient les données les plus récentes subit une panne, Cloud Identity diffuse des données obsolètes depuis un autre emplacement jusqu'à ce que la région principale redevienne disponible.
Cloud Interconnect
Cloud Interconnect offre aux clients un accès RFC 1918 aux réseaux Google Cloud depuis leurs centres de données sur site, via des câbles physiques connectés à des points d'appairage périphériques de Google.
Cloud Interconnect fournit aux clients un contrat de niveau de service garantissant une disponibilité de 99,9 % s'ils provisionnent des connexions à deux EAD (domaines de disponibilité de périphérie) dans une zone métropolitaine. Un contrat de niveau de service garantissant une disponibilité de 99,99 % est disponible si le client provisionne des connexions à deux EAD dans deux zones métropolitaines vers deux régions avec un routage global. Pour en savoir plus, consultez les pages Présentation de la topologie pour les applications non critiques et Présentation de la topologie pour les applications en production.
Cloud Interconnect est indépendant de la zone de calcul et fournit une haute disponibilité sous forme de domaines de disponibilité de périphérie. En cas de défaillance d'un domaine de disponibilité de périphérie, sa session BGP s'interrompt et le trafic bascule vers l'autre domaine de disponibilité de périphérie.
En cas de défaillance régionale, les sessions BGP vers cette région cessent de fonctionner et le trafic bascule vers les ressources de la région de travail. Cela s'applique lorsque le routage global est activé.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) fournit une gestion des ressources de clé cryptographique à la fois évolutive et hautement durable. Le service stocke toutes ses données et métadonnées dans des bases de données Spanner, qui offrent une durabilité et une disponibilité des données élevées avec une réplication synchrone.
Les ressources Cloud KMS peuvent être créées dans une seule région, dans plusieurs régions ou à l'échelle mondiale.
En cas de panne zonale, Cloud KMS continue de diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région ou d'une région différente. Les données étant répliquées de manière synchrone, il n'y a aucune perte ni corruption de données. Une fois la panne zonale résolue, la redondance complète est restaurée.
En cas de panne régionale, les ressources régionales de la région affectée sont hors ligne jusqu'à ce que la région redevienne disponible. Notez que même au sein d'une région, au moins trois instances dupliquées sont gérées dans des zones distinctes. Si une disponibilité plus élevée est requise, nous vous conseillons de stocker les ressources dans une configuration multirégionale ou mondiale. Les configurations multirégionales et mondiales sont conçues pour rester disponibles durant une panne régionale, grâce à un stockage géoredondant et à une diffusion des données dans plusieurs régions.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager est intégré à Cloud Key Management Service pour vous permettre de contrôler les clés externes et d'y accéder via des partenaires tiers compatibles. Vous pouvez utiliser ces clés externes pour chiffrer les données au repos afin de les utiliser avec d'autres services Google Cloud compatibles avec l'intégration de clés de chiffrement gérées par le client (CMEK).
Panne zonale : Cloud External Key Manager est résilient aux pannes zonales en raison de la redondance fournie par plusieurs zones d'une région. En cas de panne zonale, le trafic est redirigé vers d'autres zones de la région. Lors de la redirection du trafic, vous constaterez peut-être une augmentation du nombre d'erreurs, mais le service sera toujours disponible.
Panne régionale : Cloud External Key Manager n'est pas disponible en cas de panne régionale dans la région affectée. Il n'existe aucun mécanisme de basculement qui redirige les requêtes entre les régions. Nous recommandons aux clients d'utiliser plusieurs régions pour exécuter leurs jobs.
Cloud External Key Manager ne stocke aucune donnée client de manière persistante. Ainsi, il n'y a aucune perte de données lors d'une panne régionale dans le système Cloud External Key Manager. Cependant, Cloud External Key Manager dépend de la disponibilité d'autres services, tels que Cloud Key Management Service et des fournisseurs tiers externes. Si ces systèmes échouent lors d'une panne régionale, vous risquez de perdre des données. Les valeurs RPO/RTO de ces systèmes n'entrent pas dans le cadre des engagements Cloud External Key Manager.
Cloud Load Balancing
Cloud Load Balancing est un service géré, défini par logiciel et entièrement distribué. Avec Cloud Load Balancing, une seule adresse IP anycast peut servir d'interface pour les backends du monde entier. Comme il n'est pas basé sur le matériel, vous n'avez pas besoin de gérer une infrastructure physique d'équilibrage de charge. Les équilibreurs de charge constituent un composant essentiel de la plupart des applications à disponibilité élevée.
Cloud Load Balancing propose des équilibreurs de charge régionaux et mondiaux. Vous bénéficiez aussi d'un équilibrage de charge interrégional avec un basculement automatique multirégional qui transfère le trafic vers les backends de basculement si vos backends principaux ne sont plus opérationnels.
Les équilibreurs de charge mondiaux sont résilients aux pannes zonales et régionales. Les équilibreurs de charge régionaux sont résilients aux pannes zonales, mais sont affectés par les pannes dans leur région. Toutefois, dans les deux cas, il est important de comprendre que la résilience de votre application dans son ensemble dépend non seulement du type d'équilibreur de charge que vous déployez, mais également de la redondance de vos backends.
Pour en savoir plus sur Cloud Load Balancing et ses fonctionnalités, consultez la présentation de Cloud Load Balancing.
Cloud Logging
Cloud Logging se compose de deux éléments principaux : le routeur de journaux et l'espace de stockage Cloud Logging.
Le routeur de journaux gère les événements de journaux de streaming et dirige les journaux vers Cloud Storage, Pub/Sub, BigQuery ou l'espace de stockage Cloud Logging.
Le stockage Cloud Logging est un service permettant de stocker et d'interroger des journaux, ainsi que d'en gérer la conformité. Ce service est compatible avec de nombreux utilisateurs et workflows, y compris pour le développement, la conformité, le dépannage et les alertes proactives.
Routeur de journaux et journaux entrants : lors d'une panne zonale, l'API Cloud Logging achemine les journaux vers d'autres zones de la région. Normalement, les journaux acheminés par le routeur de journaux vers Cloud Logging, BigQuery ou Pub/Sub sont écrits le plus rapidement possible dans leur destination finale, tandis que les journaux envoyés à Cloud Storage sont mis en mémoire tampon et écrits chaque heure sous forme de lots.
Entrées de journal : en cas de panne zonale ou régionale, les entrées de journal qui ont été mises en mémoire tampon dans la zone ou dans la région affectée et qui n'ont pas été écrites dans la destination d'exportation deviennent inaccessibles. Les métriques basées sur les journaux sont également calculées dans le routeur de journaux et soumises aux mêmes contraintes. Une fois envoyés à l'emplacement d'exportation des journaux sélectionné, les journaux sont répliqués conformément au service de destination. Les journaux exportés vers l'espace de stockage Cloud Logging sont répliqués de manière synchrone sur deux zones d'une région. Pour en savoir plus sur le comportement de réplication d'autres types de destination, consultez la section correspondante de cet article. Notez que les journaux exportés vers Cloud Storage sont regroupés et écrits toutes les heures. Par conséquent, nous vous recommandons d'utiliser le stockage Cloud Logging, BigQuery ou Pub/Sub pour minimiser la quantité de données affectées par une panne.
Métadonnées de journal : les métadonnées telles que la configuration du récepteur et la configuration des exclusions sont stockées mondialement, mais mises en cache localement. Par conséquent, en cas de panne, les instances régionales du routeur de journaux continuent de fonctionner. Les pannes limitées à une seule région n'ont aucun impact en dehors de la région.
Cloud Monitoring
Cloud Monitoring comprend diverses fonctionnalités interconnectées, telles que des tableaux de bord (intégrés et définis par l'utilisateur), des alertes et une surveillance du temps d'activité.
Toutes les configurations de Cloud Monitoring, y compris les tableaux de bord, les tests de disponibilité et les règles d'alerte, sont définies globalement. Toutes les modifications apportées sont répliquées de manière synchrone dans plusieurs régions. Par conséquent, lors des pannes zonales et régionales, les modifications apportées à la configuration sont durables. De plus, bien que des défaillances temporaires de lecture et d'écriture puissent survenir en cas de défaillance initiale d'une zone ou d'une région, Cloud Monitoring redirige les requêtes vers les zones et les régions disponibles. Dans ce cas, vous pouvez relancer les modifications de configuration avec un intervalle exponentiel entre les tentatives.
Lors de l'écriture de métriques pour une ressource spécifique, Cloud Monitoring identifie d'abord la région dans laquelle se trouve la ressource. Il écrit ensuite trois répliques indépendantes des données de métriques dans la région. L'écriture globale de métriques régionales est renvoyée dès que l'une des trois écritures zonales aboutit. Il n'est pas garanti que les trois répliques se trouvent dans des zones différentes de la région.
Zonal : lors d'une panne zonale, les écritures et les lectures de métriques sont complètement indisponibles pour les ressources dans la zone affectée. En effet, Cloud Monitoring agit comme si la zone concernée n'existait pas.
Régionale : lors d'une panne régionale, les écritures et les lectures de métriques sont complètement indisponibles pour les ressources de la région concernée. En effet, Cloud Monitoring agit comme si la région concernée n'existait pas.
Cloud NAT
Cloud NAT (NAT signifiant traduction d'adresses réseau) est un service géré distribué et défini par logiciel, qui permet à certaines ressources sans adresse IP externe de créer des connexions sortantes à Internet. Il n'est pas basé sur les VM ou les appareils de proxy. Cloud NAT configure le logiciel Andromeda qui alimente votre réseau de cloud privé virtuel (VPC), afin qu'il effectue la traduction des adresses réseau sources (NAT source ou SNAT) pour les VM sans adresse IP externe. Cloud NAT fournit également une traduction des adresses réseau de destination (NAT de destination ou DNAT) pour les paquets de réponses entrants établis.
Pour en savoir plus sur les fonctionnalités de Cloud NAT, consultez la documentation.
Panne zonale : Cloud NAT est résilient aux pannes zonales, car le plan de contrôle et le plan de données réseau sont redondants dans plusieurs zones d'une même région.
Panne régionale : Cloud NAT est un produit régional. Il ne peut donc pas résister à une défaillance régionale.
Cloud Router
Cloud Router est un service Google Cloud entièrement distribué et géré qui utilise le protocole BGP (Border Gateway Protocol) pour annoncer des plages d'adresses IP. Il programme des routes dynamiques personnalisées en fonction des annonces BGP reçues d'un pair. Au lieu d'un appareil physique ou d'un dispositif matériel, chaque routeur Cloud Router est constitué de tâches logicielles qui agissent en tant que speakers et répondeurs BGP.
En cas de panne zonale, Cloud Router doté d'une configuration à haute disponibilité est résilient aux pannes zonales. Dans ce cas, une interface peut perdre la connectivité, mais le trafic est redirigé vers l'autre interface via le routage dynamique via BGP.
En cas de panne régionale, Cloud Router est un produit régional. Il ne peut donc pas résister à une défaillance régionale. Si les clients ont activé le mode de routage global, le routage entre la région défaillante et d'autres régions peut être affecté.
Cloud Run
Cloud Run est un environnement informatique sans état dans lequel les clients peuvent exécuter leur code conteneurisé sur l'infrastructure de Google. Cloud Run est une offre régionale, ce qui signifie que les clients peuvent choisir la région, mais pas les zones dont elle est composée. Les données et le trafic sont automatiquement équilibrés entre les zones d'une même région. Les instances de conteneur sont automatiquement adaptées au trafic entrant et équilibrées entre les zones si nécessaire. Chaque zone gère un programmeur qui fournit cet autoscaling par zone. Il est également informé de la charge reçue par d'autres zones et provisionne une capacité supplémentaire dans la zone pour parer à toute défaillance de zone.
Si vous utilisez des GPU Cloud Run, vous pouvez désactiver la redondance zonale pour le service et utiliser à la place une fiabilité de type "best effort" en cas d'indisponibilité zonale, à un coût inférieur. Pour en savoir plus, consultez Options de redondance zonale des GPU.
Panne zonale : Cloud Run stocke les métadonnées ainsi que le conteneur déployé. Ces données sont stockées au niveau régional et écrites de manière synchrone. L'API Admin de Cloud Run ne renvoie l'appel d'API qu'une fois les données validées dans un quorum au sein d'une région. Les données étant stockées au niveau régional, les opérations du plan de données ne sont pas affectées non plus par les défaillances zonales. Le trafic sera acheminé vers d'autres zones en cas de défaillance d'une zone.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent créer leur service Cloud Run. Les données ne sont jamais répliquées entre les régions. Le trafic client ne sera jamais acheminé vers une autre région par Cloud Run. En cas de défaillance d'une région, Cloud Run redevient disponible dès que la défaillance est résolue. Les clients sont invités à déployer sur plusieurs régions et à utiliser Cloud Load Balancing pour obtenir une disponibilité plus élevée si nécessaire.
Cloud Shell
Cloud Shell fournit aux utilisateurs Google Cloud un accès à des instances Compute Engine mono-utilisateur préconfigurées pour les tâches d'intégration, d'enseignement, de développement et d'opérateur.
Cloud Shell ne convient pas à l'exécution de charges de travail d'applications. Il est plutôt destiné à des cas d'utilisation de développement et d'enseignement interactifs. Il dispose de limites de quota d'exécution par utilisateur, est arrêté automatiquement après une courte période d'inactivité, et l'instance n'est accessible qu'à l'utilisateur assigné.
Les instances Compute Engine qui sauvegardent le service sont des ressources zonales. Par conséquent, en cas de panne zonale, le Cloud Shell d'un utilisateur n'est pas disponible.
Cloud Source Repositories
Cloud Source Repositories permet aux utilisateurs de créer et de gérer des dépôts de code source privés. Ce produit est conçu avec un modèle global. Vous n'avez donc pas besoin de le configurer pour la résilience régionale ou zonale.
Au lieu de cela, les opérations git push sur Cloud Source Repositories répliquent de manière synchrone les mises à jour du dépôt source sur plusieurs zones de plusieurs régions. Cela signifie que le service est résilient aux pannes d'une région.
Si une zone ou une région spécifique subit une panne, le trafic est automatiquement distribué vers d'autres zones ou régions.
La fonctionnalité de mise en miroir automatique des dépôts depuis GitHub ou Bitbucket peut être affectée par des problèmes dans ces produits. Par exemple, la mise en miroir est affectée si GitHub ou Bitbucket ne peuvent pas alerter Cloud Source Repositories en cas de nouveaux commits, ou si Cloud Source Repositories ne peut pas récupérer le contenu du dépôt mis à jour.
Spanner
Spanner est une base de données évolutive, hautement disponible, à versions multiples, répliquée de manière synchrone et à cohérence forte avec la sémantique relationnelle.
Les instances Spanner régionales répliquent les données de manière synchrone sur trois zones d'une même région. Une écriture sur une instance Spanner régionale est envoyée de manière synchrone aux trois instances dupliquées et confirmée au client après qu'au moins deux instances dupliquées (le quorum majoritaire sur 2 des 3 instances) aient validé l'écriture. Cela rend Spanner résilient aux défaillances de zones en lui permettant d'accéder à toutes les données, car les dernières écritures ont été conservées et un quorum majoritaire des écritures peut être obtenu avec deux instances dupliquées.
Les instances multirégionales Spanner incluent un service d'écriture répliquée qui réplique les données de manière synchrone dans cinq zones situées dans trois régions (deux instances dupliquées en lecture/écriture dans la région principale par défaut et une autre région, et une instance dupliquée dans la région témoin). Une écriture sur une instance Spanner multirégionale est confirmée après qu'au moins trois instances dupliquées (quorum majoritaire de trois sur cinq) ont validé l'écriture. En cas de défaillance d'une zone ou d'une région, Spanner a accès à toutes les données (y compris les dernières écritures) et diffuse des requêtes de lecture/écriture, car les données sont conservées dans au moins trois zones dans deux régions au moment où l'écriture est confirmée pour le client.
Pour en savoir plus sur ces configurations, consultez la documentation sur les instances de Spanner. Vous pouvez aussi consulter la documentation sur la réplication pour en savoir plus sur le fonctionnement de la réplication Spanner.
Cloud SQL
Cloud SQL est un service de base de données relationnelle entièrement géré pour MySQL, PostgreSQL et SQL Server. Le service exploite des machines virtuelles Compute Engine gérées pour exécuter le logiciel de base de données. Il offre aussi une configuration haute disponibilité pour la redondance régionale, protégeant ainsi la base de données contre les pannes zonales. Les instances dupliquées interrégionales peuvent être provisionnées pour protéger la base de données contre les pannes régionales. Étant donné que le produit propose également une option zonale, qui n'est pas résiliente aux pannes zonales ni régionales, veillez à bien sélectionner la configuration haute disponibilité, la configuration avec instances dupliquées interrégionales ou les deux.
Panne zonale : l'option Haute disponibilité crée une instance de VM principale et une instance de secours dans deux zones distinctes d'une même région. En situation normale, l'instance de VM principale diffuse toutes les requêtes en écrivant les fichiers de base de données sur un disque persistant régional, qui est répliqué de manière synchrone sur les zones principale et de secours. Si une panne zonale affecte l'instance principale, Cloud SQL lance un basculement pendant lequel le disque persistant est associé à la VM de secours et le trafic est réacheminé.
Au cours de ce processus, la base de données doit être initialisée, ce qui inclut le traitement de toutes les transactions qui ont été écrites dans le journal des transactions, mais qui n'ont pas été appliquées à la base de données. Le nombre et le type de transactions non traitées peuvent augmenter le temps RTO. Un grand nombre d'écritures récentes peut causer une accumulation de transactions non traitées en attente. Le temps RTO est fortement affecté par (a) l'activité liée à un grand nombre d'écritures récentes et (b) les modifications récentes apportées aux schémas de base de données.
Enfin, une fois la panne zonale résolue, vous pouvez déclencher manuellement une opération de basculement afin de reprendre la diffusion dans la zone principale.
Pour en savoir plus sur l'option de haute disponibilité, consultez la documentation sur la haute disponibilité de Cloud SQL.
Panne régionale : l'option Instance dupliquée interrégionale protège votre base de données contre les pannes régionales en créant des instances dupliquées avec accès en lecture de votre instance principale dans d'autres régions. La réplication interrégionale utilise la réplication asynchrone, qui permet à l'instance principale d'effectuer un commit des transactions avant qu'elles ne soient validées sur les instances dupliquées. Le délai entre le commit d'une transaction sur l'instance principale et le commit d'une transaction sur l'instance dupliquée est appelé "délai de réplication" (et peut être surveillé). Cette métrique reflète à la fois les transactions qui n'ont pas été envoyées de l'instance principale aux instances dupliquées et les transactions qui ont été reçues, mais qui n'ont pas été traitées par l'instance dupliquée. Les transactions qui n'ont pas été envoyées à l'instance dupliquée deviennent indisponibles en cas de panne régionale. Les transactions qui ont été reçues, mais qui n'ont pas été traitées par l'instance dupliquée, affectent le temps de récupération comme décrit ci-dessous.
Cloud SQL vous recommande de tester votre charge de travail avec une configuration comprenant une instance dupliquée pour établir une limite sûre de transactions par seconde (TPS), qui correspond au nombre de TPS le plus élevé n'augmentant pas le délai de réplication. Si votre charge de travail dépasse la limite sûre de TPS, le délai de réplication augmente, affectant ainsi négativement les valeurs RPO et RTO. En règle générale, nous vous conseillons d'éviter d'utiliser des configurations incluant de petites instances (moins de deux cœurs de processeur virtuel, disques de moins de 100 Go ou disques persistants HDD), qui sont sensibles au délai de réplication.
En cas de panne régionale, vous devez décider de promouvoir manuellement ou non une instance dupliquée avec accès en lecture. Cette opération est manuelle, car la promotion peut causer une situation de split-brain, où l'instance dupliquée promue accepte de nouvelles transactions malgré le retard pris sur l'instance principale au moment de la promotion. Cette situation peut poser problème une fois la panne régionale résolue, et vous devrez rapprocher les transactions qui n'ont pas été propagées de l'instance principale à l'instance dupliquée. Si ce scénario nuit à vos besoins, vous pouvez envisager d'utiliser un produit de base de données à réplication synchrone interrégionale, tel que Spanner.
Une fois déclenché par l'utilisateur, le processus de promotion suit des étapes semblables à celles de l'activation d'une instance de secours dans la configuration haute disponibilité. Dans ce processus, l'instance répliquée avec accès en lecture doit traiter le journal des transactions, ce qui augmente le temps de récupération total. Étant donné qu'aucun équilibreur de charge intégré n'est impliqué dans la promotion du réplica, redirigez manuellement les applications vers le nouveau primaire.
Pour en savoir plus sur l'option "Instance dupliquée interrégionale", consultez la documentation sur les instances dupliquées interrégionales Cloud SQL.
Pour en savoir plus sur la reprise après sinistre Cloud SQL, consultez les ressources suivantes :
- Reprise après sinistre pour une base de données Cloud SQL pour MySQL
- Reprise après sinistre pour une base de données Cloud SQL pour PostgreSQL
- Reprise après sinistre pour une base de données Cloud SQL pour SQL Server
Cloud Storage
Cloud Storage fournit une solution de stockage d'objets unifiée, évolutive et hautement durable à l'échelle mondiale. Les buckets Cloud Storage peuvent être créés dans l'un des trois types d'emplacements suivants : dans une seule région, dans deux régions ou dans plusieurs régions d'un même continent. Avec les buckets régionaux, les objets sont stockés de manière redondante entre les zones de disponibilité d'une même région. Les buckets birégionaux et multirégionaux, en revanche, sont géoredondants. Cela signifie qu'une fois que les données nouvellement écrites sont répliquées dans au moins une région distante, les objets sont stockés de manière redondante entre les régions. Avec cette approche, les données des buckets birégionaux et multirégionaux bénéficient d'un ensemble de protections plus étendu qu'avec le stockage régional.
Les buckets régionaux sont conçus pour être résilients en cas de panne dans une zone de disponibilité unique. Si une zone subit une panne, les objets de la zone indisponible sont diffusés automatiquement et de manière transparente depuis un autre emplacement de la région. Les données et les métadonnées sont stockées de manière redondante entre les zones, et ce, dès l'écriture initiale. Aucune écriture n'est perdue si une zone devient indisponible. En cas de panne régionale, les buckets régionaux de la région affectée sont hors ligne jusqu'à ce que la région redevienne disponible.
Si vous avez besoin d'une disponibilité plus élevée, vous pouvez stocker les données dans une configuration birégionale ou multirégionale. Les buckets birégionaux et multirégionaux sont des buckets uniques (sans emplacements principaux et secondaires distincts), mais ils stockent les données et les métadonnées de manière redondante entre les régions. En cas de panne régionale, le service n'est pas interrompu. Les buckets birégionaux et multirégionaux sont considérés comme étant de type "actif-actif", en ce sens que vous pouvez lire et écrire des charges de travail dans plusieurs régions simultanément tout en conservant un bucket fortement cohérent. Cela peut être particulièrement intéressant pour les clients qui souhaitent répartir leur charge de travail entre les deux régions dans le cadre d'une architecture de reprise après sinistre.
Les emplacements birégionaux et multirégionaux sont fortement cohérents car les métadonnées sont toujours écrites de manière synchrone entre les régions. Cette approche permet au service de toujours déterminer quelle est la dernière version d'un objet et d'où elle peut être diffusée, y compris à partir de régions distantes.
Les données sont répliquées de manière asynchrone. Cela signifie que le RPO définit un laps de temps durant lequel les objets nouvellement écrits sont protégés en tant qu'objets régionaux, avec une redondance entre les zones de disponibilité d'une même région. Le service réplique ensuite les objets de ce délai RPO dans une ou plusieurs régions distantes pour les rendre géoredondants. Une fois la réplication terminée, les données peuvent être diffusées automatiquement et de manière transparente depuis une autre région en cas de panne régionale. La réplication turbo est une fonctionnalité premium disponible sur un bucket birégional afin d'obtenir un délai RPO plus court, qui vise à ce que 100 % des objets nouvellement écrits soient répliqués et rendus géoredondants sur 15 minutes.
Le RPO est un élément important à prendre en compte, car lors d'une panne régionale, les données récemment écrites dans la région affectée dans le délai RPO peuvent ne pas avoir encore été répliquées dans d'autres régions. Par conséquent, ces données peuvent ne pas être accessibles pendant la panne et risquent d'être perdues en cas de destruction physique des données dans la région affectée.
Cloud Translation
Cloud Translation dispose de serveurs de calcul actifs dans plusieurs zones et régions. Il est également compatible avec la réplication synchrone des données entre les zones des régions. Ces fonctionnalités aident Translation à effectuer un basculement instantané sans perte de données pour les défaillances de zones, et sans nécessiter d'entrée ni d'ajustements de la part des clients. En cas de défaillance régionale, Cloud Translation n'est pas disponible.
Compute Engine
Compute Engine est l'une des options Infrastructure as a Service de Google Cloud. Cette solution s'appuie sur l'infrastructure mondiale de Google pour fournir des machines virtuelles (et des services associés) aux clients.
Les instances Compute Engine sont des ressources zonales. Par conséquent, elles sont indisponibles par défaut en cas de panne zonale. Compute Engine propose des groupes d'instances gérés (MIG) qui peuvent ajouter automatiquement des VM supplémentaires à partir de modèles d'instances préconfigurés, dans une seule ou dans plusieurs zones d'une région. Les MIG conviennent parfaitement aux applications sans état qui nécessitent une résilience aux pertes de zone, mais ils exigent également une configuration et une planification des ressources. Vous pouvez exploiter plusieurs MIG régionaux afin de bénéficier d'une résilience aux pannes régionales pour les applications sans état.
Les applications comportant des charges de travail avec état peuvent également utiliser des MIG avec état, mais des précautions supplémentaires doivent être prises lors de la planification de la capacité, car ils ne donnent pas lieu à un scaling horizontal. Quel que soit le scénario, il est important de configurer correctement et de tester les modèles d'instances Compute Engine et les MIG à l'avance, afin de garantir le bon fonctionnement du basculement vers d'autres zones. Pour en savoir plus, consultez la section Développer vos propres architectures et guides de référence ci-dessus.
Location unique
La location unique vous permet d'avoir un accès exclusif à un nœud à locataire unique, qui est un serveur physique Compute Engine entièrement dédié à l'hébergement des VM de votre projet.
Les nœuds à locataire unique, tels que les instances Compute Engine, sont des ressources zonales. Dans le cas peu probable d'une panne de zone, ils sont indisponibles. Pour limiter les défaillances zonales, vous pouvez créer un nœud à locataire unique dans une autre zone. Étant donné que certaines charges de travail peuvent bénéficier de nœuds à locataire unique à des fins de licence ou de comptabilité CAPEX, vous devez planifier une stratégie de basculement à l'avance.
La recréation de ces ressources dans un autre emplacement peut entraîner des coûts de licence supplémentaires ou enfreindre les exigences de comptabilité CAPEX. Pour obtenir des conseils généraux, consultez la page Développer vos propres architectures et guides de référence.
Les nœuds à locataire unique sont des ressources zonales et ne peuvent pas résister aux défaillances régionales. Pour effectuer un scaling sur plusieurs zones, utilisez des MIG régionaux.
Mise en réseau pour Compute Engine
Pour en savoir plus sur les configurations de haute disponibilité pour les connexions par interconnexion, consultez les documents suivants :
- Disponibilité de 99,99 % pour l'interconnexion dédiée
- Disponibilité de 99,99 % pour l'interconnexion partenaire
Vous pouvez provisionner des adresses IP externes en mode global ou régional, ce qui affecte leur disponibilité en cas de défaillance régionale.
Résilience de Cloud Load Balancing
Les équilibreurs de charge constituent un composant essentiel de la plupart des applications à disponibilité élevée. Il est important de comprendre que la résilience de votre application dans son ensemble dépend non seulement du champ d'application de l'équilibreur de charge que vous choisissez (global ou régional), mais également de la redondance de vos services de backend.
Le tableau suivant récapitule la résilience des équilibreurs de charge en fonction de leur distribution ou de leur champ d'application.
| Champ d'application de l'équilibreur de charge | Architecture | Résilient aux pannes zonales | Résilient aux pannes régionales |
|---|---|---|---|
| Mondial | Chaque équilibreur de charge est réparti entre toutes les régions | ||
| Interrégional | Chaque équilibreur de charge est réparti entre toutes les régions | ||
| Régional | Chaque équilibreur de charge est réparti sur plusieurs zones de la région | Une panne dans une région donnée affecte les équilibreurs de charge régionaux dans cette région. |
Pour en savoir plus sur le choix d'un équilibreur de charge, consultez la documentation Cloud Load Balancing.
Tests de connectivité
Les tests de connectivité se présentent comme un outil de diagnostic qui vous permet de vérifier la connectivité entre les points de terminaison du réseau. Il analyse votre configuration et, dans certains cas, effectue une analyse du plan de données en direct entre les points de terminaison. Un point de terminaison est une source ou une destination de trafic réseau, telle qu'une VM, un cluster Google Kubernetes Engine (GKE), une règle de transfert de l'équilibreur de charge ou une adresse IP. Le module Tests de connectivité est un outil de diagnostic sans composants de plan de données. Il ne traite ni ne génère de trafic utilisateur.
Panne zonale : les ressources du module Tests de connectivité sont globales. Vous pouvez les gérer et les consulter en cas de panne de zone. Les ressources Tests de connectivité correspondent aux résultats de vos tests de configuration. Ces résultats peuvent inclure les données de configuration des ressources zonales (par exemple, les instances de VM) dans une zone affectée. En cas de panne, les résultats de l'analyse ne sont pas précis, car ils sont basés sur des données obsolètes datant d'avant la panne. N'y comptez pas.
Panne régionale : dans une panne régionale, vous pouvez toujours gérer et afficher les ressources Tests de connectivité. Les ressources Tests de connectivité peuvent inclure les données de configuration des ressources régionales, telles que des sous-réseaux, dans une région affectée. En cas de panne, les résultats de l'analyse ne sont pas précis, car ils sont basés sur des données obsolètes datant d'avant la panne. N'y comptez pas.
Container Registry
Container Registry propose une mise en œuvre hébergée et évolutive de Docker Registry qui stocke de manière sécurisée et privée les images de conteneur Docker. La solution met en œuvre l'API HTTP Docker Registry.
Container Registry est un service mondial qui stocke les métadonnées d'images de manière synchrone dans plusieurs zones et régions par défaut. Les images de conteneurs sont stockées dans des buckets multirégionaux Cloud Storage. Cette stratégie de stockage permet à Container Registry de fournir une résilience aux pannes zonales quel que soit le scénario, ainsi qu'une résilience aux pannes régionales pour toutes les données qui ont été répliquées de manière asynchrone dans plusieurs régions par Cloud Storage.
Database Migration Service
Database Migration Service est un service Google Cloud entièrement géré permettant de migrer des bases de données d'autres fournisseurs cloud ou de centres de données sur site vers Google Cloud.
Database Migration Service est conçu comme un plan de contrôle régional. Le plan de contrôle ne dépend pas d'une zone individuelle d'une région donnée. Lors d'une panne zonale, vous conservez l'accès aux API Database Migration Service, y compris la possibilité de créer et de gérer des jobs de migration. Lors d'une panne régionale, vous perdez l'accès aux ressources de Database Migration Service appartenant à cette région jusqu'à ce que la panne soit résolue.
Database Migration Service dépend de la disponibilité des bases de données source et de destination qui sont utilisées pour le processus de migration. Si une base de données source ou de destination de Database Migration Service n'est pas disponible, les migrations cessent de progresser, mais aucune donnée principale de job ou de client n'est perdue. Les jobs de migration reprennent lorsque les bases de données source et de destination sont à nouveau disponibles.
Par exemple, vous pouvez configurer une base de données Cloud SQL de destination avec la haute disponibilité activée pour obtenir une base de données de destination qui est résiliente en cas de pannes zonales.
Les migrations de Database Migration Service passent par deux phases :
- Vidage complet : effectue une copie complète des données de la source vers la destination conformément à la spécification du job de migration.
- Capture de données modifiées (CDC, Change Data Capture) : réplique les modifications incrémentielles de la source vers la destination.
Panne zonale : si une panne zonale se produit pendant l'une de ces phases, vous pouvez toujours accéder aux ressources et les gérer dans Database Migration Service. La migration des données est affectée comme suit :
- Vidage complet : échec de la migration des données. Vous devez redémarrer le job de migration une fois que la base de données de destination termine l'opération de basculement.
- CDC : la migration des données est suspendue. Le job de migration reprend automatiquement une fois que la base de données de destination termine l'opération de basculement.
Panne régionale : Database Migration Service n'est pas compatible avec les ressources interrégionales. Il n'est donc pas résilient en cas de panne régionale.
Dataflow
Dataflow est le service de traitement de données sans serveur entièrement géré de Google Cloudpour les pipelines de traitement par flux et par lot. Par défaut, un point de terminaison régional configure le pool de nœuds de calcul Dataflow pour utiliser toutes les zones disponibles de la région. La sélection de la zone est calculée pour chaque nœud de calcul au moment de sa création, en optimisant l'acquisition de ressources et l'utilisation des réservations inutilisées. Dans la configuration par défaut des jobs Dataflow, les données intermédiaires sont stockées par le service Dataflow, et l'état du job est stocké dans le backend. Si une zone échoue, les jobs Dataflow peuvent continuer à s'exécuter, car les nœuds de calcul sont recréés dans d'autres zones.
Les limites suivantes s'appliquent :
- L'emplacement régional n'est compatible qu'avec les jobs utilisant Streaming Engine ou Dataflow Shuffle. Les jobs ayant désactivé Streaming Engine ou Dataflow Shuffle ne peuvent pas utiliser l'emplacement régional.
- L'emplacement régional s'applique uniquement aux VM et non aux ressources associées à Streaming Engine et à Dataflow Shuffle.
- Les VM ne sont pas répliquées dans plusieurs zones. Si une VM devient indisponible, ses éléments de travail sont considérés comme perdus et sont traités à nouveau par une autre VM.
- En cas d'indisponibilité à l'échelle de la région, le service Dataflow ne peut plus créer de VM.
Concevoir l'architecture de pipelines Dataflow pour la haute disponibilité
Vous pouvez exécuter plusieurs pipelines de streaming en parallèle pour traiter des données à haute disponibilité. Par exemple, vous pouvez exécuter deux tâches de streaming en parallèle dans différentes régions. L'exécution de pipelines parallèles offre une redondance géographique et une tolérance aux pannes pour le traitement des données. En tenant compte de la disponibilité géographique des sources et des récepteurs de données, vous pouvez exploiter des pipelines de bout en bout dans une configuration multirégionale hautement disponible. Pour en savoir plus, consultez Haute disponibilité et redondance géographique dans "Concevoir des workflows de pipeline Dataflow".
En cas de panne zonale ou régionale, vous pouvez réutiliser le même abonnement au sujet Pub/Sub pour éviter de perdre des données. Pour garantir que les enregistrements ne sont pas perdus lors du brassage, Dataflow utilise la sauvegarde en amont, ce qui signifie que le nœud de calcul qui envoie les enregistrements relance les RPC jusqu'à ce qu'il reçoive un accusé de réception positif et que le traitement de l'enregistrement soit effectué dans l'espace de stockage persistant en aval. Dataflow continue également à effectuer des tentatives de RPC si le nœud de calcul qui envoie les enregistrements devient indisponible. Les tentatives de RPC garantissent que chaque enregistrement est distribué exactement une fois. Pour en savoir plus sur la garantie de type "exactement une fois" de Dataflow, consultez la section Exactement une fois dans Dataflow.
Si le pipeline utilise le regroupement ou le fenêtrage, vous pouvez recourir à la fonctionnalité de recherche de Pub/Sub ou à la fonctionnalité de réouverture de Kafka après une panne zonale ou régionale pour retraiter les éléments de données et obtenir les mêmes résultats de calcul. Si la logique métier utilisée par le pipeline ne s'appuie pas sur les données avant la panne, la perte de données des résultats du pipeline peut être réduite à zéro élément. Si la logique métier du pipeline s'appuie sur les données traitées avant la panne (par exemple, si des fenêtres glissantes de longue durée sont utilisées ou si une fenêtre globale stocke des compteurs toujours croissants), utilisez les Instantanés Dataflow pour enregistrer l'état du pipeline de traitement en flux continu et démarrer une nouvelle version de votre tâche sans perdre l'état.
Dataproc
Dataproc propose des fonctionnalités de traitement des données par flux et par lot. Le service est conçu en tant que plan de contrôle régional permettant aux utilisateurs de gérer les clusters Dataproc. Le plan de contrôle ne dépend pas d'une zone individuelle d'une région donnée. Par conséquent, vous conservez l'accès aux API Dataproc lors d'une panne zonale, y compris la possibilité de créer des clusters.
Vous pouvez créer des clusters Dataproc sur :
Clusters Dataproc sur Compute Engine
Étant donné qu'un cluster Dataproc sur Compute Engine est une ressource zonale, il devient indisponible ou est détruit en cas de panne zonale. Dataproc ne prend pas automatiquement d'instantanés de l'état des clusters. Une panne zonale peut donc causer la perte des données en cours de traitement. Dataproc ne conserve pas les données utilisateur au sein du service. Les utilisateurs peuvent configurer leurs pipelines de façon à écrire les résultats dans plusieurs datastores. Vous devez songer à l'architecture du datastore et choisir un produit proposant la résilience aux sinistres requise.
Si une zone subit une panne, vous pouvez recréer une instance du cluster dans une autre zone de deux manières : en spécifiant une zone différente ou en utilisant la fonctionnalité de sélection de zone automatique dans Dataproc, qui choisira automatiquement une zone disponible. Une fois le cluster disponible, le traitement des données peut reprendre. Vous pouvez également exécuter un cluster sur lequel le mode haute disponibilité est activé, ce qui réduit la probabilité qu'une panne zonale partielle survienne sur un nœud maître et, par conséquent, sur le cluster tout entier.
Clusters Dataproc sur GKE
Les clusters Dataproc sur GKE peuvent être zonaux ou régionaux.
Pour en savoir plus sur l'architecture et les fonctionnalités de reprise après sinistre des clusters GKE zonaux et régionaux, consultez la section Google Kubernetes Engine plus loin dans ce document.
Datastream
Datastream est un service de réplication et de capture des données modifiées (CDC, Change Data Capture) sans serveur. Il vous permet de synchroniser les données de manière fiable et avec une latence minimale. Datastream permet de répliquer les données de bases de données opérationnelles dans BigQuery et Cloud Storage. De plus, il offre une intégration simplifiée avec les modèles Dataflow, ce qui permet de créer des workflows personnalisés pour charger des données dans un large éventail de destinations, telles que Cloud SQL et Spanner.
Panne zonale : Datastream est un service multizonal. Elle peut résister à une panne zonale complète et non planifiée sans perte de données ni de disponibilité. En cas de défaillance d'une zone, vous pouvez toujours accéder à vos ressources et les gérer dans Datastream.
Panne régionale : en cas de panne régionale, Datastream redevient disponible dès que la panne est résolue.
Document AI
Document AI est une plate-forme de reconnaissance de documents qui convertit les données non structurées des documents en données structurées afin d'en faciliter la compréhension, l'analyse et l'utilisation. Document AI est une offre régionale. Les clients peuvent choisir la région, mais pas les zones de cette région. Les données et le trafic sont automatiquement équilibrés entre les zones d'une même région. Les serveurs sont automatiquement adaptés au trafic entrant et équilibrés entre les zones si nécessaire. Chaque zone gère un programmeur qui fournit cet autoscaling par zone. Le programmeur connaît également la charge reçue par d'autres zones et provisionne une capacité supplémentaire dans la zone pour parer à toute défaillance de zone.
Panne zonale : Document AI stocke les documents utilisateur et les données de version du processeur. Ces données sont stockées au niveau régional et écrites de manière synchrone. Les données étant stockées au niveau régional, les opérations du plan de données ne sont pas affectées par les défaillances zonales. Le trafic est automatiquement acheminé vers d'autres zones en cas de défaillance d'une zone, avec un délai basé sur la durée de récupération des services dépendants, tels que Vertex AI.
Panne régionale : les données ne sont jamais répliquées entre les régions. En cas d'indisponibilité régionale, Document AI ne basculera pas. Les clients choisissent la région Google Cloud dans laquelle ils souhaitent utiliser Document AI. Toutefois, ce trafic client n'est jamais acheminé vers une autre région.
Validation des points de terminaison
La validation des points de terminaison permet aux administrateurs et aux professionnels des opérations de sécurité de créer un inventaire des appareils accédant aux données d'une organisation. Dans le cadre de la solution Chrome Enterprise Premium, la validation des points de terminaison offre également un niveau d'approbation critique pour les appareils et un contrôle des accès basé sur la sécurité.
Utilisez la validation des points de terminaison lorsque vous souhaitez avoir un aperçu de la stratégie de sécurité des ordinateurs et des appareils de votre organisation. Lorsqu'elle est associée aux offres Chrome Enterprise Premium, la validation des points de terminaison vous aide à appliquer un contrôle des accès précis à vos ressources Google Cloud .
La validation des points de terminaison est disponible pour Google Cloud, Cloud Identity, Google Workspace Business et Google Workspace Enterprise.
Eventarc
Eventarc fournit des événements diffusés de manière asynchrone à partir de fournisseurs Google (propriétaires), d'applications utilisateur (tierces) et de logiciels en tant que service (tiers) à l'aide de services faiblement couplés qui réagissent aux changements d'état. Il permet aux clients de configurer leurs destinations (par exemple, une instance Cloud Run ou une fonction Cloud Run de deuxième génération) pour qu'elles soient déclenchées lorsqu'un événement se produit dans un service de fournisseur d'événements ou dans le code du client.
Panne zonale : Eventarc stocke les métadonnées liées aux déclencheurs. Ces données sont stockées au niveau régional et écrites de manière synchrone. L'API Eventarc qui crée et gère les déclencheurs et les canaux ne renvoie l'appel d'API que lorsque les données ont été validées dans un quorum au sein d'une région. Les données étant stockées au niveau régional, les opérations du plan de données ne sont pas affectées par les défaillances zonales. En cas de défaillance d'une zone, le trafic est automatiquement acheminé vers d'autres zones. Les services Eventarc permettant de recevoir et de distribuer des événements de seconde et de tierce partie sont répliqués dans plusieurs zones. Ces services sont distribués au niveau régional. Les requêtes envoyées aux zones indisponibles sont automatiquement diffusées depuis les zones disponibles de la région.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent créer leurs déclencheurs Eventarc. Les données ne sont jamais répliquées entre les régions. Eventarc n'achemine jamais le trafic client vers une autre région. En cas de défaillance d'une région, Eventarc redevient disponible dès que la défaillance est résolue. Pour obtenir une disponibilité plus élevée, les clients sont invités à déployer des déclencheurs dans plusieurs régions si nécessaire.
Veuillez noter les points suivants :
- Les services Eventarc permettant de recevoir et de distribuer des événements propriétaires sont fournis dans la mesure du possible et ne sont pas couverts par le RTO/RPO.
- La diffusion d'événements Eventarc pour les services Google Kubernetes Engine est fournie dans la mesure du possible et n'est pas couverte par les objectifs de temps de récupération (RTO) ni les objectifs de point de récupération (RPO).
Filestore
Les niveaux "De base" et "Zonal" sont des ressources zonales. Ils ne tolèrent pas les défaillances de la zone ou de la région déployée.
Les instances Filestore de niveau régional sont des ressources régionales. Filestore adopte la règle de cohérence stricte requise par NFS. Lorsqu'un client écrit des données, Filestore ne renvoie pas de confirmation tant que la modification n'est pas rendue persistante et répliquée dans deux zones afin que les lectures suivantes renvoient les données correctes.
En cas de défaillance d'une zone, une instance de niveau régional continue de diffuser des données à partir d'autres zones et accepte de nouvelles écritures en attendant. Les performances des opérations de lecture et d'écriture peuvent être dégradées ; il est possible que l'opération d'écriture ne soit pas répliquée. Le chiffrement n'est pas compromis, car la clé sera fournie à partir d'autres zones.
Nous recommandons aux clients de créer des sauvegardes externes en cas de nouvelles pannes dans d'autres zones de la même région. La sauvegarde peut être utilisée pour restaurer l'instance dans d'autres régions.
Firestore
Créé par Firebase et Google Cloud, Firestore est une base de données flexible et évolutive pour le développement mobile, Web et serveur. Firestore offre une réplication automatique et multirégionale des données, des garanties de cohérence forte, des opérations atomiques par lot et des transactions ACID.
Firestore propose aux clients des emplacements régionaux et multirégionaux. Le trafic est automatiquement équilibré en charge entre les zones d'une région.
Les instances Firestore régionales répliquent les données de manière synchrone sur au moins trois zones. En cas de défaillance d'une zone, un commit des écritures peut toujours être effectué par les deux (ou plus) autres instances dupliquées, et les données qui ont subi un commit sont conservées. Le trafic est automatiquement acheminé vers d'autres zones. Un emplacement régional offre des coûts réduits, une latence d'écriture inférieure et une colocation avec d'autres ressources Google Cloud.
Les instances multirégionales Firestore répliquent de manière synchrone les données sur cinq zones de trois régions (deux régions de diffusion et une région témoin), et résistent aux défaillances zonales et régionales. En cas de défaillance d'une zone ou d'une région, les données ayant subi un commit sont conservées. Le trafic est automatiquement acheminé vers des zones/régions de diffusion, et les commits sont toujours diffusés par au moins trois zones dans les deux régions restantes. Les emplacements multirégionaux optimisent la disponibilité et la durabilité des bases de données.
Firewall Insights
Firewall Insights vous aide à comprendre et à optimiser vos règles de pare-feu. Il fournit des insights, des recommandations et des métriques sur l'utilisation de vos règles de pare-feu. Firewall Insights utilise également le machine learning pour prédire l'utilisation future des règles de pare-feu. Firewall Insights vous permet de prendre de meilleures décisions lors de l'optimisation des règles de pare-feu. Par exemple, Firewall Insights identifie les règles qu'il classe comme trop permissives. Vous pouvez utiliser ces informations pour renforcer la configuration de votre pare-feu.
Panne zonale : les données Firewall Insights étant répliquées entre les zones, elles ne sont pas affectées par une indisponibilité zonale et le trafic client est automatiquement acheminé vers d'autres zones.
Panne régionale : les données Firewall Insights étant répliquées entre les régions, elles ne sont pas affectées par une indisponibilité régionale, et le trafic client est automatiquement acheminé vers d'autres régions.
Parc
Les parcs permettent aux clients de gérer plusieurs clusters Kubernetes en tant que groupe, et permettent aux administrateurs de plate-forme d'utiliser des services multiclusters. Par exemple, les parcs permettent aux administrateurs d'appliquer des règles uniformes à tous les clusters ou de configurer Multi Cluster Ingress.
Lorsque vous enregistrez un cluster GKE dans un parc, il dispose par défaut d'une appartenance régionale dans la même région. Lorsque vous enregistrez un cluster autre queGoogle Cloud dans un parc, vous pouvez choisir n'importe quelle région ou n'importe quel emplacement global. Il est recommandé de choisir une région proche de l'emplacement physique du cluster. Cela permet une latence optimale lorsque vous utilisez la passerelle Connect pour accéder au cluster.
En cas de panne zonale, les fonctionnalités de parc ne sont pas affectées, sauf si le cluster sous-jacent est zonal et devient indisponible.
En cas de panne régionale, les fonctionnalités de parc échouent de manière statique pour les clusters d'appartenance régionaux. L'atténuation d'une panne régionale nécessite un déploiement dans plusieurs régions, comme suggéré par la page Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud.
Google Cloud Armor
Cloud Armor vous aide à protéger vos déploiements et vos applications contre différents types de menaces, y compris les attaques DDoS volumétriques et les attaques d'applications, telles que les scripts intersites et l'injection SQL. Cloud Armor filtre le trafic indésirable au niveau des équilibreurs de charge Google Cloud et empêche ce trafic d'entrer dans votre VPC et de consommer des ressources. Certaines de ces protections sont automatiques. Certaines nécessitent la configuration de règles de sécurité et leur association à des services de backend ou à des régions. Les règles de sécurité Cloud Armor à portée globale sont appliquées aux équilibreurs de charge globaux. Les règles de sécurité à l'échelle de la région sont appliquées aux équilibreurs de charge régionaux.
Indisponibilité zonale : en cas de panne zonale, les équilibreurs de charge Google Cloud redirigent votre trafic vers d'autres zones où des instances backend opérationnelles sont disponibles. La protection Cloud Armor est disponible immédiatement après le basculement du trafic, car vos règles de sécurité Cloud Armor sont répliquées de manière synchrone sur toutes les zones d'une région.
Indisponibilité régionale : en cas d'indisponibilité régionale, les équilibreurs de charge mondiaux Google Cloud redirigent votre trafic vers d'autres régions où des instances backend opérationnelles sont disponibles. La protection Cloud Armor est disponible immédiatement après le basculement du trafic, car vos règles de sécurité Cloud Armor globales sont répliquées de manière synchrone dans toutes les régions. Pour plus de résilience contre les défaillances régionales, vous devez configurer des règles de sécurité régionales Cloud Armor pour toutes vos régions.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) propose un service Kubernetes géré en simplifiant le déploiement d'applications conteneurisées sur Google Cloud. Vous pouvez choisir entre les topologies de cluster régionale et zonale.
- Lors de la création d'un cluster zonal, GKE provisionne une machine de plan de contrôle dans la zone choisie, ainsi que des machines de calcul (nœuds) au sein de cette même zone.
- Pour les clusters régionaux, GKE provisionne trois machines de plan de contrôle dans trois zones différentes de la région choisie. Par défaut, les nœuds sont également répartis sur trois zones, bien que vous puissiez choisir de créer un cluster régional avec des nœuds provisionnés dans une seule zone.
- Les clusters multizones sont semblables aux clusters zonaux, car ils incluent une machine maître, mais ils permettent aussi de répartir les nœuds sur plusieurs zones.
Panne zonale : pour éviter les pannes zonales, utilisez des clusters régionaux. Le plan de contrôle et les nœuds sont répartis sur trois zones différentes d'une même région. Les pannes zonales n'affectent pas le plan de contrôle ni les nœuds de calcul déployés dans les deux autres zones.
Panne régionale : l'atténuation d'une panne régionale nécessite un déploiement dans plusieurs régions. Bien que la topologie multirégionale ne soit actuellement pas fournie de manière intégrée avec les produits, cette approche a été adoptée par plusieurs clients GKE et peut être mise en œuvre manuellement. Vous pouvez créer plusieurs clusters régionaux pour répliquer vos charges de travail sur plusieurs régions, et contrôler le trafic vers ces clusters à l'aide d'une entrée multicluster.
VPN haute disponibilité
Un VPN haute disponibilité est une solution Cloud VPN résiliente qui chiffre de manière sécurisée votre trafic depuis votre cloud privé sur site, un autre cloud privé virtuel ou tout autre réseau de fournisseurs de services cloud vers votre cloud privé virtuel (VPC) Google Cloud.
Les passerelles VPN haute disponibilité possèdent deux interfaces, chacune avec une adresse IP provenant de pools d'adresses IP distincts, réparties de manière logique et physique entre différents POP et clusters, pour assurer une redondance optimale.
Panne zonale : en cas de panne zonale, une interface peut perdre la connectivité, mais le trafic est redirigé vers l'autre interface via le routage dynamique à l'aide du protocole BGP (Border Gateway Protocol).
Panne régionale : en cas de panne régionale, les deux interfaces peuvent perdre la connectivité pendant une courte période.
Identity and Access Management
Identity and Access Management (IAM) est responsable de toutes les décisions d'autorisation concernant les actions sur les ressources cloud. IAM confirme qu'une stratégie accorde des autorisations pour chaque action (dans le plan de données) et traite les mises à jour de ces stratégies via un appel SetPolicy (dans le plan de contrôle).
Toutes les stratégies IAM sont répliquées dans plusieurs zones de chaque région, ce qui permet aux opérations de plan de données IAM de se rétablir en cas de défaillances d'autres régions et de tolérer les défaillances de zones dans chaque région. La résilience du plan de données IAM aux défaillances de zones et de régions permet d'utiliser des architectures multirégionales et multizones pour assurer une haute disponibilité.
Les opérations du plan de contrôle IAM peuvent dépendre d'une réplication interrégionale. Lorsque les appels SetPolicy aboutissent, les données sont écrites dans plusieurs régions, mais la propagation dans d'autres régions est cohérente à terme.
Le plan de contrôle IAM est résilient aux défaillances d'une seule région.
Identity-Aware Proxy
Identity-Aware Proxy (IAP) permet d'accéder aux applications hébergées sur Google Cloud, sur d'autres clouds et sur site. IAP est distribué au niveau régional, et les requêtes vers les zones indisponibles sont automatiquement diffusées depuis d'autres zones disponibles de la région.
Les pannes régionales dans IAP affectent l'accès aux applications hébergées dans la région affectée. Nous vous recommandons un déploiement dans plusieurs régions et d'utiliser Cloud Load Balancing pour améliorer la disponibilité et la résilience face aux pannes régionales.
Identity Platform
Identity Platform permet aux clients d'ajouter à leurs applications une fonctionnalité de gestion de l'authentification et des accès personnalisable propres à Google. Identity Platform est une offre mondiale. Les clients ne peuvent pas choisir les régions ni les zones dans lesquelles leurs données sont stockées.
Panne zonale : lors d'une panne zonale, Identity Platform bascule les requêtes vers la cellule la plus proche. Toutes les données sont enregistrées à l'échelle mondiale. Vous ne perdrez donc aucune donnée.
Panne régionale : lors d'une panne régionale, les requêtes Identity Platform adressées à la région indisponible échouent temporairement pendant qu'Identity Platform supprime le trafic de la région affectée. Une fois qu'il n'y a plus de trafic vers la région concernée, un service d'équilibrage de charge de serveur global achemine les requêtes vers la région opérationnelle disponible la plus proche. Toutes les données sont enregistrées à l'échelle mondiale. Vous ne perdrez donc aucune donnée.
Knative serving
Knative serving est un service mondial qui permet aux clients d'exécuter des charges de travail sans serveur sur des clusters clients. Son objectif est de s'assurer que les charges de travail Knative serving sont correctement déployées sur les clusters de clients et que l'état d'installation de Knative serving est reflété dans la ressource de fonctionnalité de l'API GKE Fleet. Ce service ne fonctionne que lors de l'installation ou de la mise à niveau des ressources Knative serving sur les clusters clients. Il n'est pas impliqué dans l'exécution des charges de travail des clusters. Les clusters de client appartenant à des projets pour lesquels Knative serving est activé sont répartis entre les instances répliquées dans plusieurs régions et zones. Chaque cluster est surveillé par une instance répliquée.
Panne zonale et régionale : les clusters surveillés par des instances répliquées hébergées dans un emplacement en panne sont automatiquement redistribués entre les instances répliquées opérationnelles dans d'autres zones et régions. Pendant cette réattribution, il est possible que certains clusters ne soient pas surveillés par le service Knative Serving pendant une courte période. Si, pendant cette période, l'utilisateur décide d'activer les fonctionnalités Knative serving sur le cluster, l'installation des ressources Knative serving sur le cluster commence une fois que celui-ci se reconnecte à une instance répliquée de service Knative serving opérationnelle.
Looker (Google Cloud Core)
Looker (Google Cloud Core) est une plate-forme d'informatique décisionnelle qui simplifie et optimise le provisionnement, la configuration et la gestion d'une instance Looker à partir de la console Google Cloud . Looker (Google Cloud Core) permet aux utilisateurs d'explorer des données, de créer des tableaux de bord, de configurer des alertes et de partager des rapports. De plus, Looker (Google Cloud Core) propose un IDE pour les modélisateurs de données, ainsi que des fonctionnalités d'intégration et d'API riches pour les développeurs.
Looker (Google Cloud core) est composé d'instances isolées régionales qui répliquent les données de manière synchrone dans les zones de la région. Assurez-vous que les ressources utilisées par votre instance, telles que les sources de données auxquelles Looker (Google Cloud Core) se connecte, se trouvent dans la même région que celle dans laquelle votre instance s'exécute.
Panne zonale : les instances Looker (Google Cloud Core) stockent les métadonnées et leurs propres conteneurs déployés. Les données sont écrites de manière synchrone sur les instances répliquées. En cas de panne zonale, les instances Looker (Google Cloud Core) continuent de diffuser les données à partir d'autres zones disponibles de la même région. Toutes les transactions ou tous les appels d'API sont renvoyés une fois les données validées dans un quorum au sein d'une région. Si la réplication échoue, la transaction n'est pas validée et l'utilisateur est informé de l'échec. Si plusieurs zones échouent, les transactions échouent également et l'utilisateur en est averti. Looker (Google Cloud Core) arrête les plannings ou les requêtes en cours d'exécution. Vous devez les reprogrammer ou les remettre en file d'attente après la résolution de l'échec.
Panne régionale : les instances Looker (Google Cloud Core) de la région concernée ne sont pas disponibles. Looker (Google Cloud Core) arrête les plannings ou les requêtes en cours d'exécution. Vous devez reprogrammer ou remettre en file d'attente les requêtes après la résolution de l'échec. Vous pouvez créer manuellement des instances dans une autre région. Vous pouvez également récupérer vos instances à l'aide de la procédure définie dans Importer ou exporter des données dans/depuis une instance Looker (Google Cloud Core). Nous vous recommandons de configurer un processus d'exportation de données périodique pour copier les composants à l'avance, en cas de panne régionale (peu probable).
Looker Studio
Looker Studio est un produit de visualisation des données et d'informatique décisionnelle. Il permet aux clients de se connecter à leurs données stockées dans d'autres systèmes, de créer des rapports et des tableaux de bord à l'aide de ces données, et de partager les rapports et les tableaux de bord au sein de leur organisation. Looker Studio est un service global qui ne permet pas aux utilisateurs de sélectionner un champ d'application pour les ressources.
En cas de panne zonale, Looker Studio continue de diffuser les requêtes depuis une autre zone de la même région ou d'une région différente, sans interruption. Les éléments concernant les utilisateurs sont répliqués de manière synchrone entre les régions. Il n'y a par conséquent aucune perte de données.
En cas de panne régionale, Looker Studio continue de diffuser les requêtes depuis une autre région sans interruption. Les éléments concernant les utilisateurs sont répliqués de manière synchrone entre les régions. Il n'y a par conséquent aucune perte de données.
Memorystore pour Memcached
Memorystore pour Memcached est l'offre Memcached gérée de Google Cloud. Memorystore pour Memcached permet aux clients de créer des clusters Memcached qui peuvent être utilisés comme bases de données clé-valeur à haut débit pour les applications.
Les clusters Memcached sont régionaux, avec des nœuds répartis entre toutes les zones spécifiées par le client. Cependant, Memcached ne réplique aucune donnée entre les nœuds. Par conséquent, une défaillance zonale peut entraîner une perte de données, également appelée vidage partiel du cache. Les instances Memcached continueront de fonctionner, mais elles auront moins de nœuds. Le service ne démarrera aucun nouveau nœud en cas de défaillance d'une zone. Les nœuds Memcached des zones non affectées continueront de diffuser le trafic, mais la défaillance zonale entraînera un taux de succès de cache plus faible jusqu'à ce que la zone soit récupérée.
En cas de défaillance régionale, les nœuds Memcached ne diffusent pas le trafic. Dans ce cas, les données sont perdues, ce qui entraîne un vidage complet du cache. Pour limiter les pannes régionales, vous pouvez mettre en œuvre une architecture qui déploie l'application et Memorystore pour Memcached dans plusieurs régions.
Memorystore pour Redis
Memorystore pour Redis est un service Redis entièrement géré pour Google Cloud, qui peut réduire la charge liée à la gestion des déploiements Redis complexes. Il propose actuellement deux niveaux : le niveau de base et le niveau standard. Au niveau de base, une panne zonale ou régionale entraîne une perte de données, également appelée vidage complet du cache. Au niveau standard, une panne régionale entraîne une perte de données. Une panne zonale peut entraîner une perte de données partielle sur l'instance de niveau standard en raison de sa réplication asynchrone.
Panne zonale : les instances de niveau standard répliquent de manière asynchrone les opérations de l'ensemble de données du nœud principal sur le nœud d'instance dupliquée. Lorsque la panne se produit dans la zone du nœud principal, le nœud d'instance dupliquée devient le nœud principal. Pendant la promotion, un basculement se produit et le client Redis doit se reconnecter à l'instance. Une fois la reconnexion effectuée, les opérations reprennent. Pour en savoir plus sur la haute disponibilité des instances Memorystore pour Redis au niveau standard, consultez la page Memorystore pour Redis haute disponibilité.
Si vous activez des instances dupliquées avec accès en lecture dans votre instance de niveau standard et que vous n'avez qu'une seule instance dupliquée, le point de terminaison de lecture n'est pas disponible pendant la durée d'une panne zonale. Pour en savoir plus sur la reprise après sinistre des instances dupliquées avec accès en lecture, consultez la section Modes de défaillance pour les instances dupliquées avec accès en lecture.
Panne régionale : Memorystore pour Redis est un produit régional. Une instance ne peut donc pas résister à une défaillance régionale. Vous pouvez planifier des tâches périodiques pour exporter une instance Redis vers un bucket Cloud Storage dans une autre région. En cas de panne régionale, vous pouvez restaurer l'instance Redis dans une région différente de celle de l'ensemble de données que vous avez exporté.
Détection de services multiclusters et Multi Cluster Ingress
Les services multiclusters GKE (MCS) sont constitués de plusieurs composants. Les composants incluent le hub Google Kubernetes Engine (qui orchestre plusieurs clusters Google Kubernetes Engine à l'aide d'abonnements), les clusters eux-mêmes et les contrôleurs de hub GKE (entrée multicluster, détection de services multiclusters). Les contrôleurs de hub orchestrent la configuration de l'équilibreur de charge Compute Engine en utilisant des backends sur plusieurs clusters.
En cas de panne zonale, la détection de services multiclusters continue de diffuser les requêtes depuis une autre zone ou région. En cas de panne régionale, la détection de services multiclusters ne bascule pas.
En cas de panne zonale pour une entrée multicluster, si le cluster de configuration est zonal et dans le champ de défaillance, l'utilisateur doit basculer manuellement. Le plan de données est statique en cas d'échec et continuera de diffuser du trafic jusqu'à ce que l'utilisateur ait basculé. Pour éviter d'avoir à basculer manuellement, utilisez un cluster régional pour le cluster de configuration.
En cas de panne régionale, Multi Cluster Ingress ne peut pas basculer. Les utilisateurs doivent disposer d'un plan de reprise après sinistre pour basculer manuellement le cluster de configuration. Pour en savoir plus, consultez les pages Configurer Multi Cluster Ingress et Configurer des services multiclusters.
Pour en savoir plus sur GKE, consultez la section "Google Kubernetes Engine" de la page Concevoir une solution de reprise après sinistre pour les pannes d'infrastructures cloud.
Network Analyzer
Network Analyzer surveille automatiquement vos configurations de réseau VPC et détecte les erreurs de configuration et les configurations non optimales. Il fournit des informations sur la topologie du réseau, les règles de pare-feu, les routes, les dépendances de configuration, ainsi que la connectivité aux services et aux applications. Il identifie les défaillances du réseau, fournit des informations sur l'origine des problèmes et suggère des solutions possibles.
L'analyseur de réseau s'exécute en continu et déclenche des analyses pertinentes basées sur des mises à jour de configuration en quasi-temps réel sur votre réseau. Si Network Analyzer détecte une défaillance du réseau, il tente de la mettre en corrélation avec les modifications de configuration récentes pour identifier les causes fondamentales. Dans la mesure du possible, il fournit des recommandations suggérant des solutions pour résoudre les problèmes.
Network Analyzer est un outil de diagnostic sans composants de plan de données. Il ne traite ni ne génère de trafic utilisateur.
Panne zonale : le service Network Analyzer est répliqué à l'échelle mondiale et sa disponibilité n'est pas affectée par une panne de zone.
Si les insights de Network Analyzer contiennent des configurations provenant d'une zone en panne, la qualité des données est affectée. Les insights réseau qui font référence aux configurations de cette zone deviennent obsolètes. Ne vous fiez pas aux insights fournis par Network Analyzer en cas de panne.
Panne régionale : le service Network Analyzer est répliqué à l'échelle mondiale, et sa disponibilité n'est pas affectée par une panne régionale.
Si les insights de Network Analyzer contiennent des configurations provenant d'une région touchée par une panne, la qualité des données est affectée. Les insights réseau qui font référence aux configurations de cette région deviennent obsolètes. Ne vous fiez pas aux insights fournis par Network Analyzer en cas de panne.
Network Topology
Network Topology est un outil de visualisation qui montre la topologie de votre infrastructure réseau. La vue "Infrastructure" affiche les réseaux de cloud privé virtuel (VPC), la connectivité hybride vers et depuis vos réseaux sur site, la connectivité aux services gérés par Google, et les métriques associées.
Panne zonale : en cas de panne zonale, les données de cette zone n'apparaîtront pas dans Network Topology. Les données des autres zones ne sont pas affectées.
Panne régionale : en cas de panne régionale, les données de cette région n'apparaîtront pas dans Network Topology. Les données des autres régions ne sont pas affectées.
Performance Dashboard
Performance Dashboard vous offre une visibilité sur les performances de l'ensemble du réseau Google Cloud , ainsi que sur les performances des ressources de votre projet.
Ces fonctionnalités de surveillance des performances vous permettent de faire la distinction entre un problème dans votre application et un problème du réseau Google Cloud sous-jacent. Vous pouvez également examiner l'historique des problèmes de performances du réseau. Performance Dashboard exporte également les données vers Cloud Monitoring. Vous pouvez utiliser Monitoring pour interroger les données et accéder à des informations supplémentaires.
Panne zonale :
En cas de panne zonale, les données de latence et de perte de paquets pour le trafic de la zone affectée n'apparaîtront pas dans Performance Dashboard. Les données de latence et de perte de paquets pour le trafic provenant d'autres zones ne sont pas affectées. À la fin de la panne, les données de latence et de perte de paquets reprennent.
Panne régionale :
En cas de panne régionale, les données de latence et de perte de paquets pour le trafic de la région affectée n'apparaîtront pas dans Performance Dashboard. Les données de latence et de perte de paquets pour le trafic provenant d'autres régions ne sont pas affectées. À la fin de la panne, les données de latence et de perte de paquets reprennent.
Network Connectivity Center
Network Connectivity Center est un produit de gestion de la connectivité réseau qui utilise une architecture en étoile, ou "hub-and-spoke". Avec cette architecture, une ressource de gestion centrale sert de hub et chaque ressource de connectivité sert de spoke. Les spokes hybrides sont actuellement compatibles avec les VPN haute disponibilité, les interconnexions dédiées et partenaires, ainsi que les appareils de routeur SD-WAN des principaux fournisseurs tiers. Avec les spokes hybrides de Network Connectivity Center, les entreprises peuvent connecter des charges de travail et des services Google Cloud à des centres de données sur site, d'autres clouds et leurs filiales, grâce à la portée mondiale du réseau Google Cloud .
Panne zonale : un spoke hybride Network Connectivity Center avec configuration haute disponibilité est résilient en cas de panne zonale, car le plan de contrôle et le plan de données réseau sont redondants dans plusieurs zones d'une région.
Panne régionale : un spoke hybride Network Connectivity Center est une ressource régionale. Il ne peut donc pas résister à une panne régionale.
Niveaux de service réseau
Les niveaux de service réseau vous permettent d'optimiser la connectivité entre les systèmes sur Internet et vos instances Google Cloud . Il propose deux niveaux de service distincts : le niveau Premium et le niveau Standard. Avec le niveau Premium, une adresse IP anycast Premium annoncée à l'échelle mondiale peut servir d'interface pour les backends régionaux ou globaux. Au niveau Standard, une adresse IP de niveau Standard annoncée au niveau régional peut servir d'interface pour les backends régionaux. La résilience globale d'une application est influencée à la fois par le niveau de service réseau et par la redondance des backends auxquels elle est associée.
Panne zonale : les niveaux Premium et Standard offrent tous deux une résilience face aux pannes zonales lorsqu'ils sont associés à des backends redondants au niveau régional. En cas de panne zonale, le comportement de basculement pour les cas utilisant des backends redondants au niveau régional est déterminé par les backends associés eux-mêmes. Lorsqu'il est associé à des backends zonaux, le service redevient disponible dès que la panne est résolue.
Panne régionale : le niveau Premium offre une résilience aux pannes régionales lorsqu'il est associé à des backends redondants à l'échelle mondiale. Dans le niveau Standard, tout le trafic vers la région concernée échouera. Le trafic vers toutes les autres régions n'est pas affecté. En cas de panne régionale, le comportement de basculement pour les cas utilisant le niveau Premium avec des backends redondants à l'échelle mondiale est déterminé par les backends associés eux-mêmes. Lorsque vous utilisez le niveau Premium avec des backends régionaux, ou le niveau Standard, le service redevient disponible dès que la panne est résolue.
Service de règles d'administration
Le service de règles d'administration offre un contrôle centralisé et automatisé sur les ressources Google Cloud de votre organisation. En tant qu'administrateur des règles d'administration, vous pouvez configurer des contraintes sur l'ensemble de votre hiérarchie des ressources.
Panne zonale : toutes les règles d'administration créées par le service de règles d'administration sont répliquées de manière asynchrone dans plusieurs zones de chaque région. Les données et les opérations du plan de contrôle des règles d'administration sont tolérantes aux défaillances de zone dans chaque région.
Panne régionale : toutes les règles d'administration créées par le service de règles d'administration sont répliquées de manière asynchrone dans plusieurs régions. Les opérations du plan de contrôle des règles d'administration sont écrites dans plusieurs régions, et la propagation aux autres régions est cohérente en quelques minutes. Le plan de contrôle des règles d'administration est résilient aux défaillances d'une seule région. Les opérations du plan de données des règles d'administration peuvent se rétablir en cas de défaillances dans d'autres régions. La résilience du plan de données des règles d'administration aux défaillances de zones et de régions permet d'utiliser des architectures multirégionales et multizones pour assurer une haute disponibilité.
Mise en miroir de paquets
La mise en miroir de paquets clone le trafic de certaines instances spécifiées de votre réseau VPC (Virtual Private Cloud, VPC) et transfère les données clonées aux instances situées derrière un équilibreur de charge interne régional pour examen. La mise en miroir de paquets permet de capturer toutes les données sur le trafic et les paquets, y compris les charges utiles et les en-têtes.
Pour plus d'informations sur les fonctionnalités de mise en miroir de paquets, consultez la page de présentation de la mise en miroir de paquets.
Panne zonale : configurez l'équilibreur de charge interne pour qu'il existe des instances dans plusieurs zones. En cas de panne zonale, la mise en miroir de paquets redirige les paquets clonés vers une zone opérationnelle.
Panne régionale : la mise en miroir de paquets est un produit régional. En cas de panne régionale, les paquets de la région concernée ne sont pas clonés.
Persistent Disk
Les disques persistants sont disponibles dans les configurations zonales et régionales.
Les disques persistants zonaux sont hébergés dans une seule zone. Si la zone du disque est indisponible, le disque persistant l'est aussi jusqu'à ce que la panne zonale soit résolue.
Les disques persistants régionaux permettent une réplication synchrone des données entre deux zones d'une même région. En cas de panne dans la zone de votre machine virtuelle, vous pouvez forcer l'association d'un disque persistant régional à une instance de VM dans la zone secondaire du disque. Pour cela, vous devez soit démarrer une autre instance de VM dans cette zone, soit y conserver une instance de VM de secours à chaud (hot standby).
Pour répliquer de manière asynchrone des données dans un disque persistant entre les régions, vous pouvez utiliser la réplication asynchrone des disques persistants, qui fournit une réplication de stockage de blocs à faibles RTO et RPO pour la reprise après sinistre active/passive interrégionale. Dans le cas peu probable d'une panne régionale, la réplication asynchrone des disques persistants vous permet de basculer vos données vers une région secondaire et de redémarrer votre charge de travail dans cette région.
Personalized Service Health
Personalized Service Health communique les interruptions de service pertinentes pour vos projets Google Cloud . Cette solution fournit plusieurs canaux et processus permettant d'afficher ou d'intégrer des événements perturbateurs (incidents, maintenance planifiée) dans votre processus de gestion des incidents, y compris les suivants :
- Tableau de bord dans la console Google Cloud
- API de service
- Alertes configurables
- Journaux générés et envoyés à Cloud Logging
Indisponibilité zonale : les données sont diffusées à partir d'une base de données mondiale sans dépendance vis-à-vis d'emplacements spécifiques. En cas d'indisponibilité zonale, Service Health peut diffuser les requêtes et rediriger automatiquement le trafic vers les zones de la même région qui fonctionnent toujours. L'Service Health peut renvoyer des appels d'API avec succès s'il est en mesure de récupérer les données d'événement à partir de la base de données de Service Health.
Indisponibilité régionale : les données sont diffusées à partir d'une base de données mondiale sans dépendance vis-à-vis d'emplacements spécifiques. En cas d'indisponibilité régionale, Service Health peut toujours diffuser les requêtes, mais peut fonctionner avec une capacité réduite. Des défaillances régionales dans les emplacements de journalisation peuvent affecter les utilisateurs de Service Health qui consomment des journaux ou des notifications d'alerte cloud.
Private Service Connect
Private Service Connect est une fonctionnalité de mise en réseau de Google Cloudqui permet aux clients d'accéder à des services gérés en mode privé depuis leur réseau VPC. De même, il permet aux producteurs de services gérés d'héberger ces services dans leurs propres réseaux VPC séparés et de proposer une connexion privée à leurs clients.
Points de terminaison Private Service Connect pour les services publiés
Un point de terminaison Private Service Connect se connecte aux services d'un réseau VPC de producteur de services à l'aide d'une règle de transfert Private Service Connect. Le producteur de services fournit un service à un client de service à l'aide d'une connectivité privée, en exposant un seul rattachement de service. Le client du service peut alors attribuer une adresse IP virtuelle à partir de son VPC pour ce service.
Panne zonale : le trafic Private Service Connect provenant du trafic de VM généré par les points de terminaison du client VPC consommateur peut toujours accéder aux services gérés exposés sur le réseau VPC interne du producteur de services. Cela est possible, car le trafic Private Service Connect bascule vers des backends de service plus sains dans une autre zone.
Panne régionale : Private Service Connect est un produit régional. Il n'est pas résilient aux pannes régionales. Les services gérés multirégionaux peuvent atteindre une haute disponibilité en cas de panne régionale en configurant des points de terminaison Private Service Connect dans plusieurs régions.
Points de terminaison Private Service Connect pour les API Google
Un point de terminaison Private Service Connect se connecte aux API Google à l'aide d'une règle de transfert Private Service Connect. Cette règle de transfert permet aux clients d'utiliser des noms de points de terminaison personnalisés avec leurs adresses IP internes.
Panne zonale : le trafic Private Service Connect provenant des points de terminaison du client VPC consommateur peut toujours accéder aux API Google, car la connectivité entre la VM et le point de terminaison bascule automatiquement vers une autre zone fonctionnelle dans la même région. Les requêtes en cours de transfert au début d'une panne dépendent du délai avant expiration et du comportement de nouvelle tentative du client pour la récupération.
Pour en savoir plus, consultez la page Récupération sur Compute Engine.
Panne régionale : Private Service Connect est un produit régional. Il n'est pas résilient aux pannes régionales. Les services gérés multirégionaux peuvent atteindre une haute disponibilité en cas de panne régionale en configurant des points de terminaison Private Service Connect dans plusieurs régions.
Pour plus d'informations sur Private Service Connect, consultez la section "Points de terminaison" dans Types Private Service Connect.
Pub/Sub
Pub/Sub est un service de messagerie pour l'intégration d'applications et l'analyse de flux. Les sujets Pub/Sub sont mondiaux, ce qui veut dire qu'ils sont visibles et accessibles depuis n'importe quel emplacement Google Cloud . Chaque message n'est toutefois stocké que dans une seule région Google Cloud : la plus proche de l'éditeur et celle autorisée par la règle d'emplacement des ressources. Ainsi, un sujet peut contenir des messages stockés dans différentes régions Google Cloud. La règle de stockage des messages Pub/Sub peut restreindre les régions où les messages sont stockés.
Panne zonale : lorsqu'un message Pub/Sub est publié, il est écrit de manière synchrone dans l'espace de stockage d'au moins deux zones de la région. Par conséquent, si une zone devient indisponible, il n'y a aucun impact pour le client.
Panne régionale : lors d'une panne régionale, les messages stockés dans la région sont inaccessibles. Les éditeurs et les abonnés qui se connectent à la région concernée, que ce soit via un point de terminaison régional ou le point de terminaison mondial, ne peuvent pas se connecter. Les éditeurs et les abonnés qui se connectent à d'autres régions peuvent toujours se connecter, et les messages disponibles dans d'autres régions sont distribués aux abonnés les plus proches du réseau disposant de capacité.
Si votre application repose sur le tri des messages, consultez les recommandations détaillées de l'équipe Pub/Sub. Les garanties de tri des messages sont fournies par région, et peuvent subir des interruptions si vous utilisez un point de terminaison global.
reCAPTCHA
reCAPTCHA est un service mondial qui détecte les activités frauduleuses, le spam et les utilisations abusives. Il ne nécessite pas et ne permet pas de configuration pour la résilience régionale ou zonale. Les mises à jour des métadonnées de configuration sont répliquées de manière asynchrone dans chaque région où reCAPTCHA est exécuté.
En cas de panne zonale, reCAPTCHA continue à diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région, ou d'une région différente.
En cas de panne régionale, reCAPTCHA continue à diffuser de façon ininterrompue les requêtes qui proviennent d'une autre région.
Secret Manager
Secret Manager est un produit de gestion des secrets et des identifiants pourGoogle Cloud. Avec Secret Manager, vous pouvez facilement auditer et restreindre l'accès aux secrets, chiffrer les secrets au repos et vous assurer que les informations sensibles sont sécurisées dans Google Cloud.
Les ressources Secret Manager sont normalement créées avec la règle de réplication automatique (recommandée), ce qui entraîne leur réplication globale. Si votre organisation doit suivre des règles qui n'autorisent pas la réplication globale des données des secrets, vous pouvez créer des ressources Secret Manager avec des règles de réplication gérées par l'utilisateur, dans lesquelles une ou plusieurs régions sont choisies pour répliquer les secrets.
Panne zonale : en cas de panne dans une zone, Secret Manager continue de diffuser de façon ininterrompue les requêtes provenant d'une autre zone de la même région ou d'une région différente. Dans chaque région, Secret Manager conserve toujours au moins deux instances dupliquées dans des zones distinctes (dans la plupart des régions, trois instances dupliquées). Une fois la panne zonale résolue, la redondance complète est restaurée.
Panne régionale : en cas de panne régionale, Secret Manager continue de diffuser les requêtes depuis une autre région sans interruption, en supposant que les données ont été répliquées dans plusieurs régions (via la réplication automatique ou via la réplication gérée par l'utilisateur dans plusieurs régions). Une fois la panne régionale résolue, la redondance complète est restaurée.
Security Command Center
Security Command Center est la plate-forme mondiale de gestion des risques en temps réel pour Google Cloud. Il présente deux composants principaux : les détecteurs et les résultats.
Les détecteurs sont affectés par les pannes régionales et zonales, mais de différentes manières. En cas de panne régionale, les détecteurs ne peuvent pas générer de nouveaux résultats pour les ressources régionales, car les ressources qu'ils sont censés analyser ne sont pas disponibles.
Lors d'une panne zonale, les détecteurs peuvent prendre quelques minutes à plusieurs heures pour reprendre un fonctionnement normal. Security Command Center ne perdra pas les résultats. Il ne générera pas non plus de nouveaux résultats pour les ressources indisponibles. Dans le pire des cas, les agents Container Threat Detection peuvent manquer d'espace tampon en se connectant à une cellule opérationnelle, ce qui peut entraîner une perte de détection.
Les résultats sont résilients aux pannes régionales et zonales, car ils sont répliqués de manière synchrone dans les régions.
Protection des données sensibles (y compris l'API DLP)
La protection des données sensibles fournit des services sensibles de classification, de profilage, d'anonymisation et de tokenisation, ainsi que d'analyse des risques liés à la confidentialité. Il fonctionne de manière synchrone sur les données envoyées dans le corps des requêtes, ou de manière asynchrone sur les données déjà présentes dans les systèmes de stockage dans le cloud. La protection des données sensibles peut être appelée via des points de terminaison mondiaux ou spécifiques à une région.
Point de terminaison mondial : le service est conçu pour résister aux défaillances régionales et zonales. Si le service est surchargé lorsqu'une défaillance se produit, les données envoyées à la méthode hybridInspect du service peuvent être perdues.
Pour créer une architecture anti-défaillance, incluez une logique permettant d'examiner le résultat de pré-échec le plus récent produit par la méthode hybridInspect. En cas de panne, les données envoyées à la méthode peuvent être perdues, mais pas plus de 10 minutes avant l'événement de défaillance. Si des résultats sont antérieures à 10 minutes avant le début de l'interruption, cela signifie que les données qui ont abouti à ce résultat n'ont pas été perdues. Dans ce cas, il n'est pas nécessaire de relire les données antérieures à l'horodatage du résultat, même si elles se trouvent dans l'intervalle de 10 minutes.
Point de terminaison régional : les points de terminaison régionaux ne sont pas résilients aux défaillances régionales. Si la résilience en cas de défaillance régionale est requise, envisagez de basculer vers d'autres régions. Les caractéristiques de défaillance zonale sont identiques à celles décrites ci-dessus.
Service Usage
L'API Service Usage est un service d'infrastructure de Google Cloud qui vous permet de répertorier et de gérer les API et les services dans vos projets Google Cloud . Vous pouvez recenser et gérer les API et les services fournis par Google, Google Cloudet des producteurs tiers. L'API Service Usage est un service mondial résilient aux pannes zonales et régionales. En cas de panne zonale ou régionale, l'API Service Usage continue de diffuser les requêtes depuis une autre zone de différentes régions.
Pour plus d'informations sur Service Usage, consultez la documentation de Service Usage.
Speech-to-Text
Speech-to-Text vous permet de convertir du contenu audio vocal en texte en utilisant des techniques de machine learning, telles que des modèles de réseau de neurones. Le contenu audio est envoyé en temps réel depuis le micro d'une application ou traité sous forme d'un lot de fichiers audio.
Panne zonale :
API Speech-to-Text v1 : lors d'une panne zonale, la version 1 de l'API Speech-to-Text continue de diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région. Cependant, tous les jobs en cours d'exécution dans la zone défaillante sont perdus. Les utilisateurs doivent relancer les jobs ayant échoué, qui seront automatiquement acheminés vers une zone disponible.
API Speech-to-Text v2 : lors d'une indisponibilité de zone, la version 2 de l'API Speech-to-Text continue de diffuser les requêtes qui proviennent d'une autre zone de la même région. Cependant, tous les jobs en cours d'exécution dans la zone défaillante sont perdus. Les utilisateurs doivent relancer les jobs ayant échoué, qui seront automatiquement acheminés vers une zone disponible. L'API Speech-to-Text ne renvoie l'appel d'API qu'une fois les données validées dans un quorum au sein d'une région. Dans certaines régions, les accélérateurs d'IA (TPU) ne sont disponibles que dans une seule zone. Dans ce cas, une panne dans cette zone entraîne l'échec de la reconnaissance vocale, mais aucune perte de données.
Panne régionale :
API Speech-to-Text v1 : l'API Speech-to-Text version 1 n'est pas affectée par les défaillances régionales, car il s'agit d'un service multirégional mondial. Le service continue de diffuser les requêtes depuis une autre région de façon ininterrompue. Toutefois, les jobs en cours d'exécution dans la région défaillante sont perdues. Les utilisateurs doivent relancer ces jobs ayant échoué, qui seront automatiquement acheminées vers une région disponible.
API Speech-to-Text v2 :
Version 2 de l'API Speech-to-Text multirégionale, le service continue de diffuser de façon ininterrompue les requêtes qui proviennent d'une autre zone de la même région.
API Speech-to-Text à région unique version 2 : le service limite l'exécution du job à la région demandée. La version 2 de l'API Speech-to-Text n'achemine pas le trafic vers une autre région, et les données ne sont pas répliquées vers une autre région. En cas de défaillance régionale, la version 2 de l'API Speech-to-Text n'est pas disponible dans cette région. Cependant, elle redevient disponible une fois la panne résolue.
Service de transfert de stockage
Le service de transfert de stockage gère les transferts de données depuis différentes sources cloud vers Cloud Storage, ainsi que vers, depuis et entre les systèmes de fichiers.
L'API du service de transfert de stockage est une ressource globale.
Le service de transfert de stockage dépend de la disponibilité de la source et de la destination d'un transfert. Si une source ou une destination de transfert n'est pas disponible, les transferts cessent de progresser. Cependant, aucune donnée de base ou de job client n'est perdue. Les transferts reprennent lorsque la source et la destination sont à nouveau disponibles.
Vous pouvez utiliser le service de transfert de stockage avec ou sans agent, comme suit :
Les transferts sans agent utilisent des nœuds de calcul régionaux pour orchestrer les tâches de transfert.
Les transferts basés sur des agents utilisent des agents logiciels installés sur votre infrastructure. Les transferts basés sur des agents dépendent de la disponibilité des agents de transfert et de la capacité des agents à se connecter au système de fichiers. Lorsque vous décidez où installer les agents de transfert, tenez compte de la disponibilité du système de fichiers. Par exemple, si vous exécutez des agents de transfert sur plusieurs VM Compute Engine pour transférer des données vers une instance Filestore de niveau Enterprise (une ressource régionale), envisagez de placer les VM dans différentes zones de la région de l'instance Filestore.
Si les agents deviennent indisponibles ou si leur connexion au système de fichiers est interrompue, les transferts cessent de progresser, mais aucune donnée n'est perdue. Si tous les processus d'agent sont arrêtés, le job de transfert est mis en pause jusqu'à ce que de nouveaux agents soient ajoutés au pool d'agents du transfert.
Lors d'une panne, le comportement du service de transfert de stockage est le suivant :
Panne zonale : lors d'une panne zonale, les API du service de transfert de stockage restent disponibles et vous pouvez continuer à créer des jobs de transfert. Les données continuent d'être transférées.
Panne régionale : lors d'une panne régionale, les API du service de transfert de stockage restent disponibles et vous pouvez continuer à créer des jobs de transfert. Si les nœuds de calcul de votre transfert sont situés dans la région affectée, le transfert de données s'arrête jusqu'à ce que la région redevienne disponible et le transfert reprend automatiquement.
Vertex ML Metadata
Vertex ML Metadata vous permet d'enregistrer les métadonnées et les artefacts générés par votre système de ML et de les interroger pour faciliter l'analyse, le débogage et l'audit des performances de votre système de ML ou des artefacts qu'il crée.
Indisponibilité zonale : dans la configuration par défaut, Vertex ML Metadata offre une protection contre les défaillances zonales. Le service est déployé dans plusieurs zones de chaque région, les données étant répliquées de manière synchrone dans chaque zone de la région. En cas de défaillance d'une zone, les zones restantes prennent le relais avec une interruption minimale.
Panne régionale : Vertex ML Metadata est un service régionalisé. En cas d'indisponibilité régionale, Vertex ML Metadata ne bascule pas vers une autre région.
Vertex AI Batch Prediction
La prédiction par lots permet aux utilisateurs d'exécuter des prédictions par lots sur des modèles d'IA/ML sur l'infrastructure de Google. La prédiction par lots est une offre régionale. Les clients peuvent choisir la région dans laquelle ils exécutent des jobs, mais pas les zones spécifiques de cette région. Le service de prédiction par lots équilibre automatiquement la charge du job sur différentes zones de la région choisie.
Panne zonale : la prédiction par lots stocke les métadonnées des jobs de prédiction par lots dans une région. Les données sont écrites de manière synchrone dans plusieurs zones de cette région. Lors d'une panne zonale, la prédiction par lots perd partiellement les nœuds de calcul effectuant des jobs, mais les rajoute automatiquement dans d'autres zones disponibles. Si plusieurs tentatives de prédiction par lots échouent, l'interface utilisateur indique l'état du job comme échec dans l'interface utilisateur et dans les requêtes d'appel d'API. Les requêtes utilisateur suivantes pour exécuter le job sont redirigées vers les zones disponibles.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent exécuter leurs jobs de prédiction par lots. Les données ne sont jamais répliquées entre les régions. La prédiction par lots couvre le champ d'application de l'exécution du job vers la région demandée et n'achemine jamais les requêtes de prédiction vers une autre région. Lorsqu'une défaillance régionale se produit, la prédiction par lots n'est pas disponible dans cette région. Elle redevient disponible une fois la panne résolue. Nous recommandons aux clients d'utiliser plusieurs régions pour exécuter leurs jobs. En cas de panne régionale, redirigez les jobs vers une autre région disponible.
Vertex AI Model Registry
Vertex AI Model Registry permet aux utilisateurs de simplifier la gestion, la gouvernance et le déploiement des modèles de ML dans un dépôt central. Vertex AI Model Registry est une offre régionale à haute disponibilité qui offre une protection contre les pannes zonales.
Panne zonale : Vertex AI Model Registry propose une protection contre les pannes zonales. Le service est déployé dans trois zones de chaque région, les données étant répliquées de manière synchrone dans différentes zones de la région. Si une zone échoue, les zones restantes prennent le relais sans perte de données ni interruption de service.
Panne régionale : Vertex AI Model Registry est un service régionalisé. Si une région échoue, Model Registry ne bascule pas.
Prédiction en ligne Vertex AI
La prédiction en ligne permet aux utilisateurs de déployer des modèles d'IA/ML sur Google Cloud. La prédiction en ligne est une offre régionale. Les clients peuvent choisir la région dans laquelle ils déploient leurs modèles, mais pas les zones spécifiques de cette région. Le service de prédiction équilibrera automatiquement la charge de travail sur différentes zones de la région sélectionnée.
Panne zonale : la prédiction en ligne ne stocke aucun contenu client. Une panne zonale entraîne l'échec de l'exécution de la requête de prédiction en cours. La prédiction en ligne peut ou non réessayer automatiquement la requête de prédiction en fonction du type de point de terminaison utilisé. Plus précisément, un point de terminaison public réessayer automatiquement, tandis qu'un point de terminaison privé ne le fera pas. Pour gérer les échecs et améliorer la résilience, intégrez une logique de nouvelle tentative avec un intervalle exponentiel entre les tentatives dans votre code.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent exécuter leurs modèles d'IA/ML et leurs services de prédiction en ligne. Les données ne sont jamais répliquées entre les régions. La prédiction en ligne couvre l'exécution du modèle d'IA/ML vers la région demandée et n'achemine jamais les requêtes de prédiction vers une autre région. Lorsqu'une défaillance régionale se produit, le service de prédiction en ligne n'est pas disponible dans cette région. Cependant, elle redevient disponible une fois la panne résolue. Nous recommandons aux clients d'utiliser plusieurs régions pour exécuter leurs modèles d'IA/ML. En cas de panne régionale, redirigez le trafic vers une autre région disponible.
Vertex AI Pipelines
Vertex AI Pipelines est un service Vertex AI qui vous permet d'automatiser, de surveiller et de gérer vos workflows de machine learning (ML) sans serveur. Vertex AI Pipelines est conçu pour offrir une haute disponibilité et une protection contre les défaillances de zone.
Indisponibilité zonale : dans la configuration par défaut, Vertex AI Pipelines offre une protection contre les défaillances zonales. Le service est déployé dans plusieurs zones de chaque région, les données étant répliquées de manière synchrone dans différentes zones de la région. En cas de défaillance d'une zone, les zones restantes prennent le relais avec une interruption minimale.
Indisponibilité régionale : Vertex AI Pipelines est un service régionalisé. En cas d'indisponibilité régionale, Vertex AI Pipelines ne bascule pas vers une autre région. En cas d'indisponibilité régionale, nous vous recommandons d'exécuter vos jobs de pipeline dans une région de sauvegarde.
Vertex AI Search
Vertex AI Search est une solution de recherche personnalisable qui propose des fonctionnalités d'IA générative et une conformité native aux entreprises. Vertex AI Search est automatiquement déployé et répliqué dans plusieurs régions de Google Cloud. Vous pouvez configurer l'emplacement de stockage des données en choisissant un emplacement multirégional compatible, par exemple : mondial, États-Unis ou UE.
Panne zonale et régionale : UserEvents importé dans Vertex AI Search peut ne pas être récupérable en raison du délai de duplication asynchrone. Les autres données et services fournis par Vertex AI Search restent disponibles en raison du basculement automatique et de la réplication synchrone des données.
Vertex AI Training
Vertex AI Training permet aux utilisateurs d'exécuter des jobs d'entraînement personnalisés sur l'infrastructure de Google. Vertex AI Training est une offre régionale, ce qui signifie que les clients peuvent choisir la région pour l'exécution de leurs jobs d'entraînement. Toutefois, les clients ne peuvent pas choisir des zones spécifiques dans cette région. Le service d'entraînement peut équilibrer automatiquement la charge d'exécution des jobs sur différentes zones de la région.
Panne zonale : Vertex AI Training stocke les métadonnées pour le job d'entraînement personnalisé. Ces données sont stockées au niveau régional et écrites de manière synchrone. L'appel d'API Vertex AI Training ne renvoie une réponse qu'une fois ces métadonnées validées dans un quorum au sein d'une région. Le job d'entraînement peut s'exécuter dans une zone spécifique. Une panne zonale entraîne l'échec de l'exécution du job en cours. Si tel est le cas, le service relance automatiquement le job en le redirigeant vers une autre zone. Si plusieurs tentatives échouent, le job passe à l'état d'échec. Les requêtes utilisateur suivantes pour exécuter la tâche sont redirigées vers une zone disponible.
Panne régionale : les clients choisissent la région Google Cloud dans laquelle ils souhaitent exécuter leurs jobs d'entraînement. Les données ne sont jamais répliquées entre les régions. Vertex AI Training limite le champ d'application de l'exécution de la tâche à la région demandée et ne redirige jamais les jobs d'entraînement vers une autre région. En cas de panne régionale, le service Vertex AI Training n'est pas disponible dans cette région et redevient disponible une fois la panne résolue. Nous recommandons aux clients d'utiliser plusieurs régions pour exécuter leurs jobs et, en cas de panne régionale, de rediriger les jobs vers une autre région disponible.
Virtual Private Cloud (VPC)
Le cloud privé virtuel est un service global qui fournit une connectivité réseau aux ressources (par exemple, des VM). Cependant, les défaillances sont zonales. En cas de défaillance d'une zone, les ressources associées ne sont pas disponibles. De même, en cas de défaillance d'une région, seul le trafic acheminé vers et depuis la région défaillante est affecté. La connectivité des régions opérationnelles n'est pas affectée.
Panne zonale : si un réseau VPC couvre plusieurs zones et qu'une zone échoue, il reste opérationnel pour les zones opérationnelles. Le trafic réseau entre les ressources des zones opérationnelles continuera de fonctionner normalement pendant la défaillance. Une défaillance de zone n'affecte que le trafic réseau vers et depuis les ressources de la zone défaillante. Pour atténuer l'impact des défaillances zonales, nous vous recommandons de ne pas créer toutes les ressources dans une seule zone. Au lieu de cela, lorsque vous créez des ressources, répartissez-les sur plusieurs zones.
Panne régionale : si un réseau VPC couvre plusieurs régions et qu'une région échoue, le réseau VPC restera opérationnel pour les régions opérationnelles. Le trafic réseau entre les ressources des régions opérationnelles continuera de fonctionner normalement pendant la défaillance. Une défaillance régionale n'affecte que le trafic réseau vers et depuis les ressources de la région défaillante. Pour atténuer l'impact des défaillances régionales, nous vous recommandons de répartir les ressources sur plusieurs régions.
VPC Service Controls
VPC Service Controls est un service régional. Grâce à VPC Service Controls, les équipes chargées de la sécurité de l'entreprise peuvent définir des contrôles de périmètre ultraprécis, et appliquer la stratégie de sécurité à de nombreux services et projets Google Cloud . Les règles client sont mises en miroir au niveau régional.
Panne zonale : VPC Service Controls continue de diffuser de façon ininterrompue les requêtes provenant d'une autre zone de la même région.
Panne régionale : les API configurées pour l'application de la règle VPC Service Controls sur la région affectée sont indisponibles jusqu'à ce que la région redevienne disponible. Les clients sont invités à déployer des services appliqués de VPC Service Controls dans plusieurs régions si une disponibilité plus élevée est souhaitée.
Workflows
Workflows est un produit d'orchestration qui permet aux clients Google Cloudd'effectuer les opérations suivantes :
- Déployer et exécuter des workflows qui connectent d'autres services existants à l'aide du protocole HTTP
- Automatiser les processus, y compris attendre des réponses HTTP avec des nouvelles tentatives automatiques pendant un an au maximum
- Implémenter un traitement en temps réel avec des exécutions à faible latence basées sur des événements
Un client Workflows peut déployer des workflows décrivant la logique métier qu'il souhaite mettre en œuvre, puis exécuter les workflows directement avec l'API ou avec des déclencheurs basés sur des événements (actuellement limités à Pub/Sub ou Eventarc). Le workflow en cours d'exécution peut manipuler des variables, effectuer des appels HTTP et stocker les résultats, ou définir des rappels et attendre d'être réactivé par un autre service.
Panne zonale : le code source des workflows n'est pas affecté par les pannes zonales. Workflows stocke le code source des workflows, ainsi que les valeurs de variables et les réponses HTTP reçues par les workflows en cours d'exécution. Le code source est stocké au niveau régional et écrit de manière synchrone : l'API du plan de contrôle ne s'affiche qu'une fois ces métadonnées validées dans un quorum au sein d'une région. Les variables et les résultats HTTP sont également stockés au niveau régional et écrits de manière synchrone, au moins toutes les cinq secondes.
Si une zone échoue, les workflows sont automatiquement repris en fonction des dernières données stockées. Toutefois, les requêtes HTTP qui n'ont pas encore reçu de réponse ne sont pas automatiquement réessayées. Utilisez des règles de réessai pour les requêtes pouvant être relancées en toute sécurité, comme décrit dans notre documentation.
Panne régionale : Workflows est un service régionalisé. En cas de panne régionale, les workflows ne basculent pas. Les clients sont invités à déployer Workflows dans plusieurs régions dans le cas où ils souhaiteraient atteindre une disponibilité plus élevée.
Cloud Service Mesh
Cloud Service Mesh vous permet de configurer un maillage de services géré couvrant plusieurs clusters GKE. Cette documentation ne concerne que Cloud Service Mesh géré. La variante dans le cluster est auto-hébergée et les consignes standards de la plate-forme doivent être suivies.
Panne zonale : la configuration du maillage, telle qu'elle est stockée dans le cluster GKE, est résiliente aux pannes zonales tant que le cluster est régional. Les données utilisées par le produit pour la comptabilité interne sont stockées à l'échelle régionale ou mondiale. Elles ne sont pas affectées si une zone est mise hors service. Le plan de contrôle est exécuté dans la même région que le cluster GKE qu'il prend en charge (pour les clusters zonaux, il s'agit de la région qui les contient). Il n'est pas affecté par les pannes d'une seule zone.
Panne régionale : Cloud Service Mesh fournit des services aux clusters GKE, régionaux ou zonaux. En cas de panne régionale, Cloud Service Mesh ne bascule pas. Il en va de même pour GKE. Les clients sont invités à déployer des maillages composés de clusters GKE couvrant différentes régions.
Annuaire des services
L'annuaire des services est une plate-forme permettant de découvrir, de publier et de connecter des services. Il fournit des informations en temps réel sur tous vos services, au même endroit. Quel que soit le nombre de points de terminaison de services dont vous disposez, l'Annuaire des services vous permet de gérer votre inventaire de services à grande échelle.
Les ressources de l'Annuaire des services sont créées au niveau régional et correspondent au paramètre d'emplacement spécifié par l'utilisateur.
Panne zonale : lors d'une panne zonale, l'Annuaire des services continue de diffuser sans interruption les requêtes provenant d'une autre zone de la même région ou d'une région différente. Dans chaque région, l'Annuaire des services gère toujours plusieurs instances dupliquées. Une fois la panne zonale résolue, la redondance complète est restaurée.
Panne régionale : l'annuaire des services n'est pas résilient aux pannes régionales.