Cet article constitue la deuxième partie d'une série qui traite de la reprise après sinistre (DR, Disaster Recovery) dans Google Cloud. Cette partie traite des services et des produits que vous pouvez utiliser comme structure pour votre plan de reprise après sinistre, qu'il s'agisse de produits Google Cloud ou de produits sur plusieurs plates-formes.
La série comprend les éléments suivants :
- Guide de planification de reprise après sinistre
- Structure de la reprise après sinistre (cet article)
- Scénarios de reprise après sinistre pour les données
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
Google Cloud propose un large éventail de produits que vous pouvez utiliser dans le cadre de votre architecture de reprise après sinistre. Dans cette section, nous traitons des fonctionnalités des produits de reprise après sinistre les plus couramment utilisées en tant que structure de reprise après sinistre Google Cloud .
Beaucoup de ces services disposent de fonctionnalités haute disponibilité. La haute disponibilité ne couvre pas entièrement la reprise après sinistre, mais bon nombre de ses objectifs s'appliquent également à la conception d'un plan de reprise après sinistre. Par exemple, en tirant parti des fonctionnalités de haute disponibilité, vous pouvez concevoir des architectures optimisant le temps d'activité et permettant d'atténuer les effets des défaillances à petite échelle, telles que sur une seule VM. Pour plus d'informations sur les relations entre reprise après sinistre et haute disponibilité, consultez le Guide de planification de reprise après sinistre.
Les sections suivantes décrivent ces structures de reprise après sinistre Google Cloud et l'aide qu'elles vous apportent pour mettre en œuvre vos objectifs dans ce domaine.
Calcul et stockage
Le tableau suivant récapitule les fonctionnalités des services de calcul et de stockage Google Cloud , qui constituent des fondements de la reprise après sinistre :
| Produit | Sélection |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Pour en savoir plus sur la façon dont les fonctionnalités et la conception de ces produitsGoogle Cloud et d'autres peuvent influencer votre stratégie de reprise après sinistre, consultez Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud : référence produit.
Compute Engine
Compute Engine fournit des instances de machine virtuelle (VM) qui constituent l'outil de travail de Google Cloud. Outre la configuration, le lancement et la surveillance des instances Compute Engine, vous recourez généralement à diverses fonctionnalités associées pour mettre en œuvre un plan de reprise après sinistre.
Pour les scénarios de reprise après sinistre, vous pouvez empêcher la suppression accidentelle de VM en définissant l'indicateur de protection contre la suppression. Ceci est particulièrement utile lorsque vous hébergez des services avec état, tels que des bases de données.
Pour savoir comment atteindre des valeurs RTO et RPO faibles, consultez Concevoir des systèmes résilients.
Modèles d'instances
Vous pouvez utiliser des modèles d'instance Compute Engine pour enregistrer les détails de configuration de la VM, puis créer des instances Compute Engine à partir de modèles d'instance existants. Lorsque vous devez mettre en place l'environnement cible de votre reprise après sinistre, vous pouvez utiliser le modèle pour lancer autant d'instances que vous le souhaitez, configurées exactement comme vous le souhaitez. Les modèles d'instance sont répliqués globalement, ce qui vous permet de recréer facilement l'instance n'importe où dans Google Cloud avec la même configuration.
Pour en savoir plus, consultez les ressources suivantes :
Pour en savoir plus sur l'utilisation des images Compute Engine, consultez la section Trouver un équilibre entre configuration de l'image et vitesse de déploiement, plus loin dans ce document.
Groupes d'instances gérés
Les groupes d'instances gérés fonctionnent avec Cloud Load Balancing (décrit plus loin dans ce document) pour répartir le trafic vers des groupes d'instances configurées de manière identique et copiées dans différentes zones. Les groupes d'instances gérés autorisent des fonctionnalités telles que l'autoscaling et l'autoréparation, dans lesquelles le groupe d'instances géré peut supprimer et recréer automatiquement des instances.
Réservations
Compute Engine permet de réserver des instances de VM dans une zone spécifique, à l'aide de types de machines personnalisés ou prédéfinis, avec ou sans GPU supplémentaires ou SSD locaux. Afin de garantir la capacité de vos charges de travail critiques pour la reprise après sinistre, vous devez créer des réservations dans vos zones cibles de reprise après sinistre. Sans réservation, il est possible que vous ne puissiez pas obtenir la capacité à la demande dont vous avez besoin pour atteindre votre objectif de temps de récupération. Les réservations peuvent être utiles dans les scénarios de reprise après sinistre à froid, tièdes ou à chaud. Elles vous permettent de conserver des ressources de récupération disponibles pour le basculement afin de répondre à des besoins en RTO plus faibles, sans avoir à les configurer et à les déployer à l'avance.
Disques persistants et instantanés
Les disques persistants sont des périphériques de stockage réseau durables auxquels vos instances peuvent accéder. Ils ne dépendent pas de vos instances. Vous pouvez donc détacher et déplacer des disques persistants pour conserver vos données même après la suppression de vos instances.
Vous pouvez effectuer des sauvegardes ou des instantanés incrémentiels de VM Compute Engine que vous pouvez copier dans différentes régions et utiliser pour recréer des disques persistants en cas de sinistre. Vous pouvez également créer des instantanés de disques persistants pour vous protéger contre les pertes de données dues aux erreurs des utilisateurs. Les instantanés sont incrémentiels et se créent en quelques minutes seulement, même si vos disques d'instantané sont associés à des instances en cours d'exécution.
Les disques persistants sont dotés d'une fonction de redondance intégrée qui protège les données contre les pannes de matériel et qui assure la disponibilité de ces données lors des événements de maintenance du centre de données. Les disques persistants sont soit zonaux, soit régionaux. Les disques persistants régionaux répliquent les écritures dans deux zones d'une région. En cas de panne de zone, une instance de VM de secours peut forcer l'association d'un disque persistant régional dans la zone secondaire. Pour en savoir plus, consultez la page Options de haute disponibilité avec des disques persistants régionaux.
Maintenance transparente
Google assure une maintenance régulière de son infrastructure en appliquant les logiciels correctifs les plus récents sur ses systèmes, en effectuant des tests de routine et de la maintenance préventive, et en s'assurant de façon générale que l'infrastructure Google est aussi rapide et efficace que possible.
Par défaut, toutes les instances Compute Engine sont configurées pour que ces événements de maintenance soient transparents pour vos applications et vos charges de travail. Pour en savoir plus, consultez Maintenance transparente.
Lorsqu'un événement de maintenance se produit, Compute Engine utilise la migration à chaud pour migrer automatiquement vos instances en cours d'exécution vers un autre hôte de la même zone. La migration à chaud permet à Google d'effectuer une maintenance essentielle à la protection et à la fiabilité de l'infrastructure sans interrompre vos VM.
Outil d'importation de disque virtuel
L'outil d'importation de disque virtuel vous permet d'importer des formats de fichier, tels que VMDK, VHD et RAW, pour créer de nouvelles machines virtuelles Compute Engine. À l'aide de cet outil, vous pouvez créer des machines virtuelles Compute Engine ayant la même configuration que vos machines virtuelles sur site. C'est une bonne approche lorsque vous ne pouvez pas configurer les images Compute Engine à partir des fichiers binaires sources du logiciel déjà installé sur vos images.
Sauvegardes automatiques
Vous pouvez automatiser les sauvegardes de vos instances Compute Engine à l'aide de tags. Par exemple, vous pouvez créer un modèle de plan de sauvegarde à l'aide du service Backup and DR, puis l'appliquer automatiquement à vos instances Compute Engine.
Pour en savoir plus, consultez Automatiser la protection des nouvelles instances Compute Engine.
Cloud Storage
Cloud Storage est un store d'objets idéal pour stocker des fichiers de sauvegarde. Il fournit différentes classes de stockage adaptées à des cas d'utilisation spécifiques, comme indiqué dans le diagramme suivant.

Dans les scénarios de reprise après sinistre, les stockages Nearline, Coldline et Archive présentent un intérêt particulier, dans la mesure où ils réduisent vos coûts de stockage par rapport à un stockage standard. Toutefois, la récupération de données ou de métadonnées stockées dans ces classes entraîne des coûts supplémentaires, ainsi que des durées de stockage minimales facturées. Nearline est conçu pour les scénarios de sauvegarde dont l'accès ne dépasse pas une fois par mois, ce qui est idéal pour vous permettre de réaliser des tests réguliers de contrainte de reprise après sinistre tout en maintenant des coûts bas.
Les solutions Nearline, Coldline et Archive sont optimisées pour un accès peu fréquent, et le modèle de tarification est conçu dans cet esprit. Par conséquent, vous êtes facturé à hauteur des durées de stockage minimales, et la récupération de données ou de métadonnées dans ces classes avant la fin de la durée de stockage minimale de la classe entraîne des coûts supplémentaires.
Pour protéger les données d'un bucket Cloud Storage contre toute suppression accidentelle ou malveillante, vous pouvez utiliser la fonctionnalité de suppression réversible, qui permet de conserver les objets supprimés et écrasés pendant une période spécifiée, et la fonctionnalité de conservation des objets, qui permet d'empêcher la suppression ou la mise à jour des objets.
Le service de transfert de stockage vous permet d'importer des données à partir de sources Amazon S3, Azure Blob Storage ou de sources de données sur site dans Cloud Storage. Dans les scénarios de reprise après sinistre, vous pouvez utiliser le service de transfert de stockage pour effectuer les opérations suivantes :
- sauvegarder les données d'autres fournisseurs de stockage sur un bucket Cloud Storage ;
- déplacer les données d'un bucket se trouvant dans un emplacement birégional ou multirégional vers un bucket situé dans un emplacement régional afin de réduire les coûts de stockage des sauvegardes.
Filestore
Les instances Filestore sont des serveurs de fichiers NFS entièrement gérés à utiliser avec des applications exécutées sur des instances Compute Engine ou des clusters GKE.
Les niveaux Filestore de base et zonal sont des ressources zonales et ne permettent pas la réplication entre zones, tandis que les instances Filestore de niveau Enterprise sont des ressources régionales. Pour vous aider à améliorer la résilience de votre environnement Filestore, nous vous recommandons d'utiliser des instances de niveau Enterprise.
Google Kubernetes Engine
GKE est un environnement géré, prêt pour la production, permettant de déployer des applications conteneurisées. GKE vous permet d'orchestrer des systèmes haute disponibilité et inclut les fonctionnalités suivantes :
- Réparation automatique des nœuds. Si un nœud échoue lors de vérifications consécutives de l'état sur une période prolongée (environ 10 minutes), GKE lance un processus de réparation pour ce nœud.
- Vérifications d'activité et d'aptitude : Vous pouvez spécifier une vérification d'activité qui informe périodiquement GKE que le pod est en cours d'exécution. Si le pod échoue, la sonde peut être redémarrée.
- Clusters multizones et régionaux. Vous pouvez répartir les ressources Kubernetes sur plusieurs zones d'une même région.
- La passerelle multicluster vous permet de configurer des ressources d'équilibrage de charge partagées entre plusieurs clusters GKE dans différentes régions.
- Le service Sauvegarde pour GKE vous permet de sauvegarder et de restaurer des charges de travail sur des clusters GKE.
Mise en réseau et transfert de données
Le tableau suivant récapitule les fonctionnalités des services de mise en réseau et de transfert de données Google Cloud , qui constituent des fondements de la reprise après sinistre :
| Produit | Sélection |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing fournit une haute disponibilité pour les produits de calcul Google Cloud en répartissant le trafic utilisateur entre plusieurs instances de vos applications. Vous pouvez configurer Cloud Load Balancing avec des vérifications de l'état qui déterminent si des instances sont disponibles pour que le trafic ne soit pas acheminé vers des instances en échec.
Cloud Load Balancing fournit une seule adresse IP anycast pour faire face à vos applications. Vos applications peuvent avoir des instances s'exécutant dans différentes régions (par exemple, en Europe et aux États-Unis) et vos utilisateurs finaux sont dirigés vers l'ensemble d'instances le plus proche. En plus de fournir un équilibrage de charge pour les services exposés à Internet, vous pouvez configurer un équilibrage de charge interne pour vos services derrière une adresse IP d'équilibrage de charge privée. Cette adresse IP est accessible uniquement aux instances de VM internes à votre cloud privé virtuel (VPC).
Pour en savoir plus, consultez la présentation de Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh est un maillage de services géré par Google et disponible sur Google Cloud. Cloud Service Mesh fournit une télémétrie détaillée pour vous aider à recueillir des insights précis sur vos applications. Il est compatible avec les services qui s'exécutent sur différentes infrastructures de calcul.
Cloud Service Mesh est également compatible avec les fonctionnalités avancées de gestion et de routage du trafic, telles que les disjoncteurs et l'injection de pannes. Avec la rupture de circuit, vous pouvez appliquer des limites aux requêtes adressées à un service particulier. Lorsque les limites de rupture de circuit sont atteintes, les requêtes ne peuvent pas atteindre le service, ce qui empêche qu'il se dégrade davantage. Avec l'injection de pannes, Cloud Service Mesh peut retarder ou interrompre une partie des requêtes vers un service. L'injection de pannes vous permet de tester la capacité de votre service à survivre aux requêtes retardées ou interrompues.
Pour en savoir plus, consultez la présentation de Cloud Service Mesh.
Cloud DNS
Cloud DNS fournit un moyen automatisé de gérer vos entrées DNS dans le cadre d'un processus de reprise automatique. Cloud DNS utilise le réseau mondial de Google de serveurs de noms Anycast pour desservir vos zones DNS à partir d'emplacements redondants dans le monde entier, ce qui offre une haute disponibilité et une latence réduite à vos utilisateurs.
Si vous avez choisi de gérer les entrées DNS sur site, vous pouvez activer les VM dansGoogle Cloud pour résoudre ces adresses via le transfert Cloud DNS.
Cloud DNS accepte la définition de règles, afin de configurer la manière dont il va répondre aux requêtes DNS. Par exemple, vous pouvez configurer des règles de routage DNS pour orienter le trafic en fonction de critères spécifiques, comme l'activation du basculement vers une configuration de sauvegarde pour assurer une haute disponibilité ou l'acheminement des requêtes DNS en fonction de leur emplacement géographique.
Cloud Interconnect
Cloud Interconnect permet de transférer vers Google Clouddes informations à partir d'autres sources. Nous en parlerons plus tard dans la section Transférer des données vers et à partir de Google Cloud.
Gestion et surveillance
Le tableau suivant récapitule les fonctionnalités des services de gestion et de surveillance de Google Cloud , qui constituent des fondements de la reprise après sinistre :
| Produit | Sélection |
|---|---|
| Tableau de bord d'état du cloud |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service pour Prometheus |
|
Tableau de bord d'état du cloud
Le tableau de bord d'état du cloud indique la disponibilité actuelle des services Google Cloud . Vous pouvez afficher l'état sur la page et vous pouvez vous abonner à un flux RSS mis à jour chaque fois qu'il y a des actualités concernant un service.
Cloud Monitoring
Cloud Monitoring collecte des métriques, des événements et des métadonnées provenant de Google Cloud, d'AWS, de vérifications du temps d'activité, de l'instrumentation d'applications et de divers composants d'application. Vous pouvez configurer les alertes pour envoyer des notifications à des outils tiers tels que Slack ou Pagerduty afin de fournir des informations rapides aux administrateurs.
Cloud Monitoring vous permet de créer des tests de disponibilité pour les points de terminaison accessibles au public et pour les points de terminaison de vos VPC. Par exemple, vous pouvez surveiller des URL, des instances Compute Engine, des révisions Cloud Run et des ressources tierces, telles que des instances Amazon Elastic Compute Cloud (EC2).
Google Cloud Managed Service pour Prometheus
Google Cloud Managed Service pour Prometheus est une solution multiprojet et multicloud gérée par Google pour les métriques Prometheus. Il vous permet de surveiller vos charges de travail et d'envoyer des alertes à l'échelle mondiale à l'aide de Prometheus, sans avoir à gérer et exploiter manuellement Prometheus à grande échelle.
Pour en savoir plus, consultez la page Google Cloud Managed Service pour Prometheus.
Structure de reprise après sinistre multiplate-forme
Lorsque vous exécutez des charges de travail sur plusieurs plates-formes, vous pouvez sélectionner un outil qui fonctionne avec toutes les plates-formes que vous utilisez pour réduire les coûts opérationnels. Cette section traite de certains outils et services qui ne dépendent pas de la plate-forme et qui prennent donc en charge les scénarios de reprise après sinistre multiplate-forme.
Infrastructure as Code
En définissant votre infrastructure à l'aide de code plutôt que d'interfaces graphiques ou de scripts, vous pouvez adopter des outils de modélisation déclaratifs et automatiser le provisionnement et la configuration de l'infrastructure sur plusieurs plates-formes. Par exemple, vous pouvez utiliser Terraform et Infrastructure Manager pour activer votre configuration d'infrastructure déclarative.
Outils de gestion de la configuration
Pour les infrastructures de reprise après sinistre complexes ou volumineuses, nous recommandons des outils de gestion logicielle indépendants de la plate-forme, tels que Chef et Ansible. Ces outils garantissent que des configurations reproductibles peuvent être appliquées, peu importe où se trouve votre charge de travail de calcul.
Outils d'orchestration
Les conteneurs peuvent également être considérés comme une structure de reprise après sinistre. Ils sont un moyen de regrouper les services et d'introduire une cohérence entre les plates-formes.
Si vous travaillez avec des conteneurs, vous utilisez généralement un système d'orchestration. Kubernetes ne fonctionne pas uniquement pour gérer les conteneurs dans Google Cloud (à l'aide de GKE), mais constitue un moyen d'orchestrer les charges de travail basées sur les conteneurs de plusieurs plates-formes. Google Cloud, AWS et Microsoft Azure fournissent tous des versions gérées de Kubernetes.
Pour répartir le trafic vers les clusters Kubernetes s'exécutant sur différentes plates-formes cloud, vous pouvez utiliser un service DNS prenant en charge les enregistrements pondérés et intégrant la vérification de l'état.
Vous devez également vous assurer que vous pouvez extraire l'image vers l'environnement cible. Cela signifie que vous devez pouvoir accéder à votre registre d'images en cas de sinistre. Nous vous conseillons pour ce faire d'utiliser Artefact Registry, qui présente en outre l'avantage de ne pas dépendre de la plate-forme.
Transfert de données
Le transfert de données est un élément essentiel des scénarios de reprise après sinistre multiplate-formes. Assurez-vous de concevoir, mettre en œuvre et tester vos scénarios de reprise après sinistre multiplate-formes en utilisant des maquettes réalistes de ce que le scénario de transfert de données de reprise après sinistre implique. Nous discutons des scénarios de transfert de données dans la section suivante.
Service Backup and DR
Le service Backup and DR est une solution de sauvegarde et de reprise après sinistre pour les charges de travail cloud. Il vous aide à récupérer des données et à reprendre vos opérations commerciales critiques. Il est compatible avec plusieursGoogle Cloud produits, bases de données tierces et systèmes de stockage de donnéesGoogle Cloud .
Pour en savoir plus, consultez la présentation du service Backup and DR.
Modèles de reprise après sinistre
Cette section présente quelques-uns des modèles les plus courants pour les architectures de reprise après sinistre, basés sur les structures décrites précédemment.
Transférer des données vers et depuis Google Cloud
Un aspect important de votre plan de reprise après sinistre est la rapidité avec laquelle les données peuvent être transférées vers et depuis Google Cloud. Cette exigence est essentielle lorsque votre plan de reprise après sinistre est basé sur le déplacement des données sur site vers Google Cloud ou depuis un autre fournisseur cloud vers Google Cloud. Dans cette section, nous abordons le sujet des services réseau etGoogle Cloud capables d'assurer un bon débit.
Lorsque vous utilisez Google Cloud en tant que site de récupération pour des charges de travail sur site ou dans un autre environnement cloud, vous devez prendre en compte les éléments clés suivants :
- Comment vous connectez-vous à Google Cloud ?
- Combien de bande passante y a-t-il entre vous et le fournisseur d'interconnexion ?
- Quelle est la bande passante fournie directement par le fournisseur à Google Cloud ?
- Quelles autres données seront transférées via ce lien ?
Pour en savoir plus sur le transfert de données vers Google Cloud, consultez Migrer vers Google Cloud : transférer vos ensembles de données volumineux.
Équilibrer la configuration de l'image et la vitesse de déploiement
Lorsque vous configurez une image système pour le déploiement de nouvelles instances, prenez en compte l'effet de votre configuration sur la vitesse de déploiement. Il existe un compromis entre la quantité de préconfiguration de l'image, les coûts de maintenance de l'image et la vitesse de déploiement. Par exemple, si une image système est configurée de manière minimale, les instances qui l'utilisent auront besoin de plus de temps pour se lancer, car elles doivent télécharger et installer des dépendances. En revanche, si votre image système est configurée de façon avancée, les instances qui l'utilisent se lancent plus rapidement, mais vous devez mettre à jour l'image plus souvent. Le temps pris pour lancer une instance entièrement opérationnelle aura une corrélation directe avec votre DMIA.
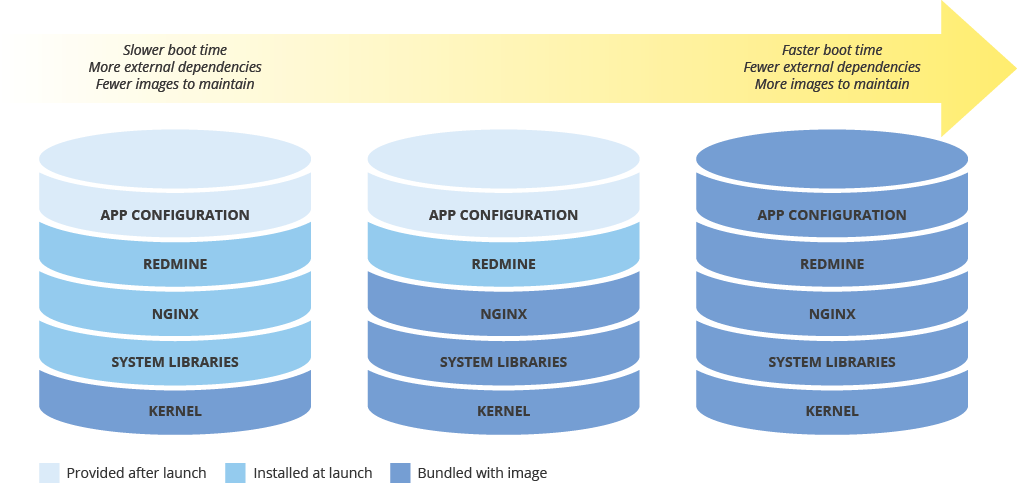
Maintenir la cohérence de l'image système dans des environnements hybrides
Si vous mettez en œuvre une solution hybride (sur site vers le cloud ou d'un cloud à un autre), vous devez trouver un moyen de maintenir la cohérence des images dans les environnements de production.
Si une image entièrement configurée est requise, envisagez d'utiliser Packer qui peut créer des images système identiques pour plusieurs plates-formes. Vous pouvez utiliser les mêmes scripts avec des fichiers de configuration spécifiques à la plate-forme. Dans le cas de Packer, vous pouvez placer le fichier de configuration dans le contrôle de version pour garder une trace de la version déployée en production.
Une autre option consiste à utiliser des outils de gestion de la configuration tels que Chef, Puppet, Ansible ou Saltstack pour configurer des instances de manière plus précise, en créant des images de base, des images à configuration minimale ou des images à configuration avancée, selon les besoins.
Vous pouvez également convertir et importer manuellement des images existantes telles que des AMI Amazon, des images Virtualbox et des images de disque RAW vers Compute Engine.
Mettre en œuvre un stockage à plusieurs niveaux
Le modèle de stockage à plusieurs niveaux est généralement utilisé pour les sauvegardes où la sauvegarde la plus récente se trouve sur un stockage plus rapide. Vous migrez ensuite lentement vos sauvegardes anciennes vers un stockage lent moins coûteux. En appliquant ce modèle, vous migrez les sauvegardes entre des buckets de différentes classes de stockage, généralement des classes de stockage standards vers des classes de stockage moins coûteuses, telles que Nearline et Coldline.
Pour implémenter ce modèle, vous pouvez utiliser la gestion du cycle de vie des objets. Par exemple, vous pouvez modifier automatiquement la classe de stockage des objets plus anciens qu'un certain délai pour les passer à Coldline.
Étapes suivantes
- En savoir plus sur les zones géographiques et régionsGoogle Cloud
Consultez d'autres articles de cette série sur la reprise après sinistre :
- Guide de planification de reprise après sinistre
- Scénarios de reprise après sinistre pour les données
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
Contributeurs
Auteurs :
- Grace Mollison | Responsable des solutions
- Marco Ferrari | Architecte de solutions cloud