Cette page présente la configuration de la haute disponibilité pour les instances Cloud SQL. Pour configurer la haute disponibilité pour une nouvelle instance ou pour l'activer sur une instance existante, consultez la page Activer et désactiver la haute disponibilité sur une instance.
Présentation de la configuration de la haute disponibilité
L'objectif d'une configuration de haute disponibilité est de réduire les temps d'arrêt lorsqu'une zone ou une instance devient indisponible. Cela peut se produire en cas de panne de zone ou en cas de problème matériel. Avec la haute disponibilité, vos données restent disponibles pour les applications clientes.
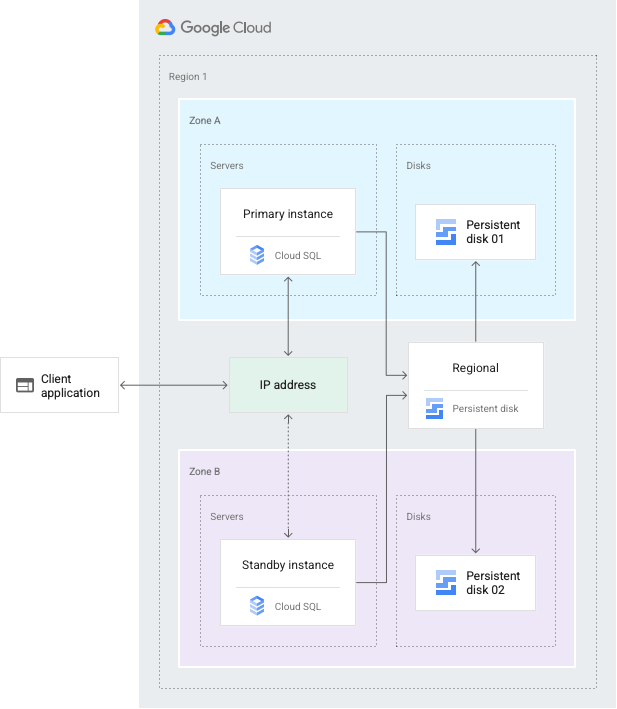
La configuration de la haute disponibilité permet la redondance des données. Une instance Cloud SQL configurée pour la haute disponibilité est également appelée une instance régionale. Elle comporte une zone principale et une zone secondaire dans la région configurée*. Au sein d'une instance régionale, la configuration se compose d'une instance principale et d'une instance de secours. Grâce à la réplication synchrone sur le disque persistant de chaque zone, toutes les écritures effectuées sur l'instance principale sont répliquées sur les disques des deux zones avant que la transaction ne soit signalée comme validée. En cas de défaillance d'une instance ou d'une zone, l'instance de secours devient la nouvelle instance principale. Les utilisateurs sont ensuite réacheminés vers la nouvelle instance principale. Ce processus est appelé basculement.
Après un basculement, l'instance qui a reçu le basculement continue d'être l'instance principale, même après la reconnexion de l'instance d'origine. Lorsque la zone ou l'instance ayant subi une panne redevient disponible, l'instance principale d'origine est détruite et recréée. Puis elle devient la nouvelle instance de secours. Si un basculement se produit dans le futur, la nouvelle instance principale basculera vers l'instance d'origine dans la zone d'origine.
Si vous devez disposer de l'instance principale dans la zone où la panne a eu lieu, vous pouvez effectuer une restauration. Une restauration effectue les mêmes étapes que le basculement, uniquement dans la direction opposée, pour rediriger le trafic vers l'instance d'origine. Pour effectuer une restauration, suivez la procédure décrite dans Lancer un basculement.
L'assistance concernant les disques persistants régionaux pour la configuration de la haute disponibilité de Cloud SQL comportant au moins un processeur dédié est couverte par le contrat de niveau de service complet. Une instance configurée pour la haute disponibilité coûte deux fois plus cher qu'une instance autonome. Le processeur, la mémoire RAM et le stockage sont inclus dans ce prix. Pour en savoir plus, consultez la page des tarifs.
* Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
Instances dupliquées avec accès en lecture
Si la disponibilité est un facteur à prendre en compte pour vos instances dupliquées avec accès en lecture, vous pouvez activer la haute disponibilité sur les instances dupliquées. Lorsque vous promouvez une instance dupliquée pour en faire une instance primaire, elle est déjà configurée en tant qu'instance hautement disponible.
Lors d'une indisponibilité de zone, le trafic s'arrête pour lire les instances répliquées dans cette zone. Lorsque la zone redevient disponible, toute instance répliquée avec accès en lecture de la zone reprend la réplication à partir de l'instance principale. Si les instances dupliquées avec accès en lecture ne se trouvent pas dans une zone qui subit une panne, elles se connectent à l'instance de secours lorsqu'elle devient l'instance principale.
Il est recommandé de placer certaines de vos instances dupliquées avec accès en lecture dans une zone différente de celle des instances principale et de secours. Par exemple, si vous disposez d'une instance principale dans la zone A et d'une instance de secours dans la zone B, placez une instance dupliquée avec accès en lecture dans la zone C pour améliorer la fiabilité. Cette pratique garantit que les instances dupliquées avec accès en lecture continuent de fonctionner même si la zone de l'instance principale subit une panne. Vous devez également ajouter une logique métier dans l'application cliente afin d'envoyer des lectures à l'instance principale lorsque les instances dupliquées avec accès en lecture ne sont pas disponibles.
Remarque : L'instance de secours ne peut pas être utilisée pour les requêtes de lecture. Cela diffère de l'ancienne configuration de la haute disponibilité de Cloud SQL pour MySQL.
Présentation du basculement
Si une instance configurée pour la haute disponibilité ne répond plus, Cloud SQL passe automatiquement à l'instance de secours pour la diffusion des données. Pour savoir si un basculement a eu lieu, vous pouvez consulter l'historique dans le journal des opérations.
Découvrez comment créer des requêtes dans l'explorateur de journaux. Si vous avez besoin d'informations plus détaillées au sujet d'une opération, par exemple l'utilisateur qui a effectué l'opération, vous devez activer la journalisation d'audit.
Cliquez sur les onglets pour découvrir les conséquences du basculement sur vos instances.
Normal

Basculement

Après le basculement

Restauration automatique
Processus
Le processus suivant se produit :
L'instance principale ou la zone échoue.
Le système de pulsation détecte chaque seconde si l'instance principale est opérationnelle. Si le système ne parvient pas à détecter plusieurs pulsations, le basculement est lancé.
Au moment de la reconnexion, c'est l'instance de secours qui diffuse des données.
Par le biais d'une adresse IP statique partagée avec l'instance principale, l'instance de secours diffuse désormais des données depuis la zone secondaire.
Exigences
Pour que Cloud SQL autorise un basculement, la configuration doit répondre aux critères suivants :
- L'instance principale doit se trouver dans un état de fonctionnement normal. Cela signifie qu'elle n'est pas arrêtée ni en cours de maintenance, et n'effectue pas d'opération de longue durée sur une instance Cloud SQL, telle qu'une opération de sauvegarde.
- La zone secondaire et l'instance de secours doivent toutes deux se trouver dans un état sain. Lorsque l'instance de secours ne répond pas, les opérations de basculement sont bloquées. Une fois que Cloud SQL a réparé l'instance de secours et que la zone secondaire est disponible, Cloud SQL autorise le basculement.
Sauvegarde et restauration
Les sauvegardes automatiques et la récupération à un moment précis doivent être activées pour les instances à haute disponibilité, à l'exclusion des instances dupliquées avec accès en lecture.
Options de récupération pour les instances autonomes
Cloud SQL ne récupère pas automatiquement les instances autonomes en cas d'indisponibilité zonale. Pour rétablir une instance non configurée pour la haute disponibilité dans une zone saine, vous devez restaurer manuellement toutes les instances zonales. Vous pouvez récupérer manuellement une instance autonome à partir d'une panne zonale à l'aide de l'une des options suivantes :
Effectuez une récupération à un moment précis sur l'instance vers une nouvelle instance que vous créez. Pour utiliser cette option, vous devez avoir activé la récupération à un moment précis sur l'instance zonale avant la panne zonale. Les journaux de transactions de l'instance doivent être stockés dans Cloud Storage. Si les journaux de transactions sont stockés sur le disque, vous pouvez les transférer vers Cloud Storage. Pour utiliser cette option, suivez les étapes décrites dans Effectuer une récupération PITR sur une instance indisponible.
Si l'instance possède une instance dupliquée avec accès en lecture dans une autre zone, vous pouvez promouvoir cette instance dupliquée avec accès en lecture pour remplacer l'instance autonome qui est affectée par la panne zonale. Pour utiliser cette option, suivez les étapes décrites dans Promouvoir une réplique.
Pour les deux options, les considérations suivantes s'appliquent :
Il est possible que certaines transactions récentes validées sur l'instance principale n'apparaissent pas sur l'instance nouvellement récupérée. L'intervalle de temps pendant lequel des transactions ont pu être perdues correspond à l'objectif de point de récupération (RPO, Recovery Point Objective).
- Pour la récupération PITR, lRPO est généralement de cinq minutes ou moins.
- Pour la promotion d'une instance répliquée en lecture, le RPO varie en fonction de la charge de travail de la base de données. Pour savoir comment surveiller et réduire le délai avant réplication, consultez Délai avant réplication.
Après avoir effectué l'une des options de restauration, vous devez reconfigurer tous les clients des instances concernées par l'indisponibilité zonale, car les instances récupérées auront des adresses IP et des noms de connexion différents.
Applications et instances
Comme le fonctionnement des instances standards et des instances haute disponibilité est identique, vous n'avez pas besoin de configurer votre application d'une manière spécifique. Lors du basculement, toutes les connexions existantes à l'instance principale et aux instances dupliquées avec accès en lecture sont fermées. Le rétablissement des connexions à l'instance principale prend environ 60 secondes. Votre application se reconnecte à l'aide de la même chaîne de connexion ou de la même adresse IP. Vous n'avez pas besoin de mettre à jour votre application une fois le basculement terminé.
Pour découvrir comment le basculement affecte vos applications, lancez le processus manuellement.
Temps d'arrêt pour maintenance
Les événements de maintenance affectent les instances principales configurées pour la haute disponibilité de la même manière que les autres instances. Vous pouvez vous attendre à ce que les instances principales soient indisponibles pendant une courte période. Pour en savoir plus sur l'impact de la maintenance sur les instances à haute disponibilité, consultez la section Fonctionnement de la maintenance. Pour minimiser l'impact sur votre service, modifiez les paramètres de maintenance pour contrôler le moment où les temps d'arrêt surviennent.
Performances
Les performances des disques persistants régionaux dépendent de nombreux facteurs. Vos opérations d'entrée/sortie par seconde (IOPS) peuvent être réduites à l'aide du disque persistant régional par rapport au disque persistant zonal. Examinez la taille du type d'instance de VM, ainsi que l'entrée et la sortie de la charge de travail. Notez également que la latence d'un disque persistant régional avec des disques durs SSD est supérieure à celle d'un disque persistant zonal avec des disques durs SSD. Cela signifie que si votre charge de travail n'est pas une charge de travail en streaming et est sensible à la latence, elle ne peut pas atteindre la limite d'IOPS car le disque persistant régional avec SSD a une latence plus élevée qu'un disque persistant zonal avec SSD. Cela est dû à la réplication synchrone des données sur plusieurs zones impliquées dans un disque persistant régional pour fournir plusieurs copies de données sur les zones d'une même région.
Ancienne option de haute disponibilité MySQL
L'ancien processus d'ajout de la haute disponibilité aux instances MySQL utilise une instance dupliquée de basculement. L'ancienne fonctionnalité n'est pas disponible dans la console Google Cloud . Consultez les sections Ancienne configuration : Créer une instance configurée pour la haute disponibilité ou Ancienne configuration : Configurer la haute disponibilité d'une instance existante.
Étapes suivantes
- Activer et désactiver la haute disponibilité sur une instance
- Lancez le basculement.
- Apprenez-en plus sur la gestion des connexions de base de données.
- Apprenez-en plus sur les régions et les zones dans Cloud SQL.