Cette page présente la reprise après sinistre dans Cloud SQL.
Présentation
Dans Google Cloud, la reprise après sinistre (DR, disaster recovery) de base de données consiste à assurer la continuité du traitement, en particulier en cas de défaillance ou d'indisponibilité d'une région. Cloud SQL est un service régional (lorsque Cloud SQL est configuré pour la haute disponibilité). Par conséquent, si la région Google Cloud qui héberge une base de données Cloud SQL devient indisponible, la base de données Cloud SQL devient elle aussi indisponible.
Pour assurer la continuité du traitement, vous devez rendre la base de données disponible dans une région secondaire dès que possible. Le plan de reprise après sinistre nécessite la configuration d'une instance dupliquée interrégionale avec accès en lecture dans Cloud SQL. Un basculement basé sur l'exportation/importation ou sur la sauvegarde/restauration est également possible, mais cette approche prend plus de temps, en particulier pour les bases de données volumineuses.
Les scénarios métier suivants sont des exemples qui justifient une configuration de basculement interrégionale :
- Le contrat de niveau de service de l'application métier garantit une disponibilité supérieure à celle du contrat de niveau de service Cloud SQL régional (disponibilité de 99,99 %, selon votre édition de Cloud SQL). En basculant vers une région secondaire, vous pouvez limiter l'impact d'une indisponibilité de service.
- Tous les niveaux de l'application métier sont déjà multirégionaux et peuvent poursuivre les traitements en cours en cas de panne régionale. La configuration de basculement interrégionale permet de garantir la disponibilité continue d'une base de données.
- L'objectif de temps de récupération (RTO) et l'objectif de point de récupération (RPO) attendus sont exprimés en minutes, et non en heures. Il est plus rapide de basculer vers une autre région que de recréer une base de données.
En général, il existe deux variantes pour le processus de reprise après sinistre :
- La base de données bascule vers une région secondaire. Une fois que la base de données basculée est prête et qu'elle est utilisée par une application, elle devient la nouvelle base de données principale et conserve ce statut.
- Une base de données bascule vers une région secondaire, mais repasse à la région principale une fois que celle-ci est à nouveau disponible.
Cette présentation de la reprise après sinistre de base de données Google Cloud SQL décrit la deuxième variante : lorsqu'une base de données défaillante est récupérée et revient à la région principale. Cette variante du processus de reprise après sinistre est particulièrement pertinent pour les bases de données devant s'exécuter dans la région principale en raison de la latence du réseau, ou parce que certaines ressources ne sont disponibles que dans cette région. Avec cette variante, la base de données ne s'exécute dans la région secondaire que pour la durée de l'indisponibilité du service dans la région principale.
Deux tutoriels sont associés au présent document de reprise après sinistre :- Reprise après sinistre de Cloud SQL pour MySQL : processus complet de basculement et de remplacement
- Reprise après sinistre de Cloud SQL pour PostgreSQL : processus complet de basculement et de remplacement
Architecture de reprise après sinistre
Le schéma suivant illustre l'architecture minimale permettant la reprise après sinistre de la base de données pour une instance Cloud SQL à haute disponibilité :
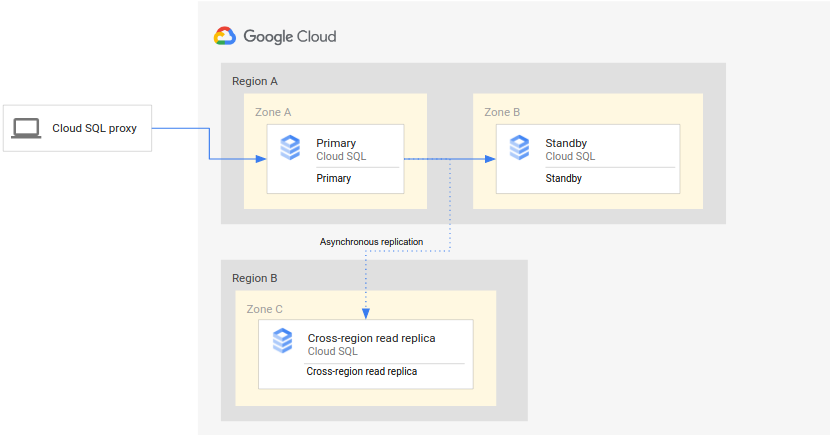
L'architecture fonctionne comme suit :
- Deux instances Cloud SQL (une instance principale et une instance de secours) sont situées dans deux zones distinctes d'une même région (la région principale). Les instances sont synchronisées par le biais de disques persistants régionaux.
- Une instance Cloud SQL (instance dupliquée interrégionale avec accès en lecture) est située dans une deuxième région (la région secondaire). Pour la reprise après sinistre, l'instance dupliquée interrégionale avec accès en lecture est configurée pour se synchroniser (via la réplication asynchrone) avec l'instance principale à l'aide d'une configuration d'instance dupliquée avec accès en lecture.
Les instances principale et de secours partagent le même disque régional, leurs états sont donc identiques.
Étant donné que cette configuration utilise une réplication asynchrone, il est possible que l'instance dupliquée interrégionale avec accès en lecture accuse un léger retard sur l'instance principale. Par conséquent, lorsqu'un basculement se produit, le RPO de l'instance dupliquée interrégionale avec accès en lecture est probablement différent de zéro.
Processus de reprise après sinistre
Le processus de reprise après sinistre commence lorsque la région principale devient indisponible. Pour reprendre le traitement dans une région secondaire, vous devez déclencher un basculement de l'instance principale en promouvant une instance répliquée interrégionale avec accès en lecture. Le processus de reprise après sinistre définit les étapes opérationnelles qui doivent être effectuées, manuellement ou automatiquement, afin de minimiser l'impact de la défaillance régionale et de lancer l'exécution d'une instance principale dans une région secondaire.
Le schéma suivant illustre le processus de reprise après sinistre :
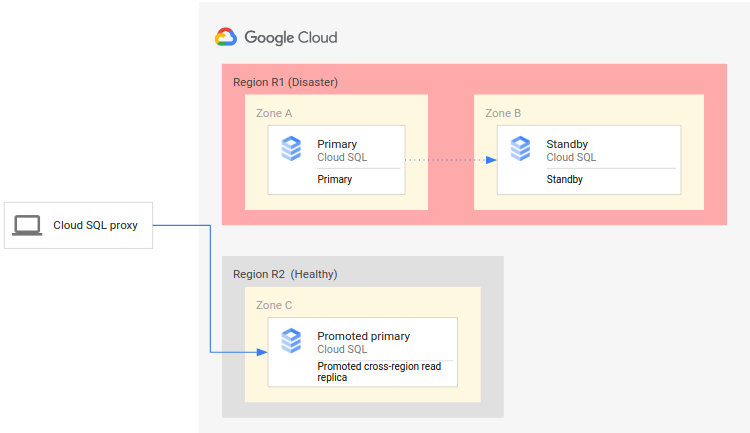
Le processus de reprise après sinistre comprend les étapes suivantes.
- La région principale (R1), dans laquelle l'instance principale est exécutée, devient indisponible.
- L'équipe en charge des opérations reconnaît officiellement le sinistre et décide si un basculement est nécessaire.
- Si un basculement est nécessaire, vous pouvez promouvoir l'instance répliquée interrégionale avec accès en lecture dans la région secondaire (R2) en tant que nouvelle instance principale.
- Les connexions client sont reconfigurées pour reprendre le traitement sur la nouvelle instance principale et accéder à l'instance principale dans la région R2.
Ce processus initial permet de retrouver une base de données principale opérationnelle. Toutefois, il n'établit pas une architecture de reprise après sinistre complète, dans laquelle la nouvelle instance principale dispose à son tour d'une instance de secours et d'une instance dupliquée interrégionale avec accès en lecture.
Un processus de reprise après sinistre complet garantit que l'instance unique, la nouvelle instance principale, est activée pour la haute disponibilité et dispose d'une instance dupliquée interrégionale avec accès en lecture. Un processus de reprise après sinistre complet fournit également une solution de remplacement pour le déploiement d'origine dans la région principale d'origine.
Basculer vers une région secondaire
Un processus complet de reprise après sinistre étend le processus de base en ajoutant des étapes qui permettent d'établir une architecture complète de reprise après sinistre après un basculement. Le schéma suivant illustre une architecture complète de reprise après sinistre pour une base de données après le basculement :
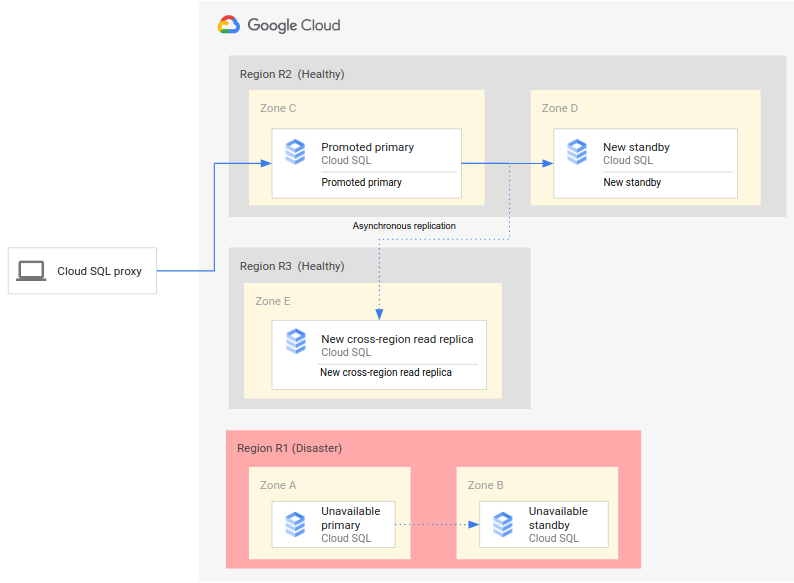
Le processus complet de reprise après sinistre pour une base de données comprend les étapes suivantes :
- La région principale (R1), dans laquelle la base de données principale est exécutée, devient indisponible.
- L'équipe en charge des opérations reconnaît officiellement le sinistre et décide si un basculement est nécessaire.
- Si un basculement est nécessaire, vous pouvez promouvoir l'instance dupliquée interrégionale avec accès en lecture dans la région secondaire (R2) en tant que nouvelle instance principale.
- Les connexions client sont configurées de manière à accéder à la nouvelle instance principale (R2) et à travailler dessus.
- Une nouvelle instance de secours est créée et démarrée dans R2 et ajoutée à l'instance principale. L'instance de secours se trouve dans une zone différente de celle de l'instance principale. L'instance principale offre désormais une disponibilité élevée, car une instance de secours a été créée pour elle.
- Une nouvelle instance dupliquée interrégionale avec accès en lecture est créée dans une troisième région (R3), puis elle est associée à l'instance principale. À ce stade, vous disposez d'une architecture de reprise après sinistre complète et opérationnelle.
Si la région principale d'origine (R1) redevient disponible avant la mise en œuvre de l'étape 6, l'instance dupliquée interrégionale avec accès en lecture peut être placée directement dans la région R1 plutôt que dans la région R3. Notez qu'en ce cas, la mise en œuvre d'une solution de remplacement vers la région principale d'origine (R1) est moins complexe et nécessite moins d'étapes.
Éviter toute situation de split-brain
Une défaillance de la région principale (R1) ne signifie pas que l'instance principale d'origine et son instance de secours sont automatiquement arrêtées ou supprimés, ou qu'elles seront toujours inaccessibles lorsque la région R1 redeviendra disponible. Si R1 redevient disponible, les clients peuvent lire et écrire des données (même par accident) sur l'instance principale d'origine. Dans ce cas, une situation de split-brain peut se produire. Certains clients peuvent accéder à des données obsolètes dans l'ancienne base de données principale, tandis que d'autres accèdent à des données actualisées dans la nouvelle base de données principale, ce qui peut perturber vos activités.
Pour éviter toute situation de split-brain, vous devez vous assurer que les clients ne pourront plus accéder à l'instance principale d'origine une fois que R1 redeviendra disponible. Idéalement, vous devez rendre l'instance principale d'origine inaccessible avant que les clients ne commencent à utiliser la nouvelle instance principale, puis supprimer l'instance principale d'origine immédiatement après l'avoir rendue inaccessible.
Établir une sauvegarde initiale après le basculement
Lorsque vous promouvez l'instance dupliquée interrégionale avec accès en lecture en tant que nouvelle instance principale dans le cadre d'un basculement, il est possible que les transactions de la nouvelle instance principale ne soient pas entièrement synchronisées avec les transactions de l'instance principale d'origine. Par conséquent, les transactions "d'origine" peuvent ne pas être disponibles dans la nouvelle instance.
Il est recommandé de sauvegarder immédiatement la nouvelle instance principale dès le début du basculement et avant que les clients n'accèdent à la base de données. Cette sauvegarde représente un état cohérent et connu au moment du basculement. De telles sauvegardes peuvent être importantes à des fins réglementaires, ou pour effectuer la récupération d'un état connu si les clients rencontrent des problèmes lors de l'accès à la nouvelle instance principale.
Rebasculer sur la région principale d'origine
Comme décrit précédemment, ce document précise les étapes nécessaires pour revenir à la région d'origine (R1). Il existe deux versions différentes du processus de remplacement.
- Si vous avez créé la nouvelle instance dupliquée interrégionale avec accès en lecture dans une troisième région (R3), vous devez créer une autre (une deuxième) instance dupliquée interrégionale avec accès en lecture dans la région principale (R1).
- Si vous avez créé la nouvelle instance dupliquée interrégionale avec accès en lecture dans la région principale (R1), vous n'avez pas besoin de créer une autre instance dupliquée interrégionale avec accès en lecture dans la région R1.
Une fois que l'instance dupliquée interrégionale avec accès en lecture est créée dans la région R1, l'instance Cloud SQL peut rebasculer vers la région R1. Comme le remplacement est déclenché manuellement et non basé sur une panne, vous pouvez choisir un jour et une heure appropriés pour cette activité de maintenance.
Ainsi, pour obtenir une solution de reprise après sinistre complète comprenant une instance principale, une instance de secours et instance dupliquée interrégionale avec accès en lecture, vous avez besoin de deux basculements. Le premier basculement est déclenché par l'interruption de service (il s'agit d'un véritable basculement). Quant au second, il rétablit le déploiement de départ (il s'agit d'une opération de remplacement).
Le retour à la région principale d'origine (R1) comprend les étapes suivantes :
- Promouvoir l'instance répliquée interrégionale nouvellement créée dans la région principale d'origine (R1).
- Si l'instance promue n'a pas été créée à l'origine en tant qu'instance répliquée haute disponibilité, activez la haute disponibilité sur l'instance pour vous protéger contre les défaillances de zone.
- Reconfigurer vos applications pour qu'elles se connectent à la nouvelle instance principale.
- Créer une instance répliquée interrégionale pour la nouvelle instance principale dans la région de reprise après sinistre (R2).
- (Facultatif) Pour éviter d'exécuter plusieurs instances principales indépendantes, nettoyer l'instance principale dans la région de reprise après sinistre (R2).
Reprise après sinistre (DR) avancée
Si vous utilisez l'édition Cloud SQL Enterprise Plus, vous pouvez tirer parti de la DR (reprise après sinistre avancée. La reprise après sinistre avancée simplifie la récupération et le repli après un basculement interrégional. Comme décrit dans le processus de reprise après sinistre, lorsque vous effectuez une reprise après sinistre, vous supprimez la connexion entre la région défaillante de l'ancienne instance principale et la région opérationnelle de la nouvelle instance principale. Avec la reprise après sinistre, pour restaurer les connexions à la région de déploiement d'origine et récupérer votre ancienne instance principale, vous devez effectuer une série d'étapes de remplacement manuelles.
Avec la reprise après sinistre avancée, en cas de défaillance régionale, vous pouvez appeler un basculement d'instance répliquée. Avec le basculement d'instance répliquée, vous promouvez une instance répliquée interrégionale avec accès en lecture de la même manière qu'une reprise après sinistre standard, à la différence que vous promouvez l'instance répliquée désignée de reprise après sinistre. La promotion de l'instance répliquée de reprise après sinistre est immédiate.
Au lieu de supprimer l'ancienne instance principale, l'instance reste intégrée à la topologie de réplication asynchrone de Cloud SQL. L'ancienne instance principale (instance A) devient une instance répliquée de son instance répliquée de reprise après sinistre (instance B) une fois que l'instance répliquée de reprise après sinistre a été promue en nouvelle instance principale.
Une fois que l'ancienne instance principale (A) a été transformée en instance répliquée, vous pouvez effectuer la dernière étape de la reprise après sinistre avancée. Vous pouvez rétablir l'état d'origine de votre déploiement Cloud SQL et restaurer l'ancienne instance principale (A) à son ancien rôle d'instance principale, sans aucune perte de données. Pour effectuer cette restauration de l'ancienne instance principale (A) sans perte de données, vous pouvez utiliser l'opération de commutation. Lorsque vous effectuez une commutation, il n'y a aucune perte de données, car l'instance principale (B) reste en mode lecture seule jusqu'à ce que son instance répliquée de reprise après sinistre désignée (A) rattrape l'instance principale (B). Une fois que l'instance répliquée de reprise après sinistre (A) a reçu toutes les mises à jour de réplication, l'instance répliquée de reprise après sinistre (A) assume le rôle d'instance principale, tandis que l'instance principale précédente (B) est automatiquement reconfigurée en tant qu'instance répliquée de reprise après sinistre de l'instance principale actuelle (A). Les instances reviennent à leur rôle d'origine, renvoyant ainsi la topologie à son état d'origine avant la reprise après sinistre et le basculement des instances répliquées.
Tout au long de la reprise après sinistre avancée, toutes les instances impliquées dans les opérations de basculement et de commutation d'instances répliquées conservent leurs adresses IP.
Vous pouvez également utiliser l'opération de basculement de reprise après sinistre avancée pour effectuer des tests de routine de reprise après sinistre afin de tester et de préparer votre topologie Cloud SQL pour le basculement interrégional avant qu'un sinistre ne se produise. En cas de sinistre, vous pouvez effectuer le basculement de l'instance répliquée interrégionale que vous avez déjà testé.
Instance répliquée de reprise après sinistre
En tant que composant requis pour la reprise après sinistre avancée, l'instance répliquée de reprise après sinistre présente les caractéristiques suivantes :
- Une instance répliquée de reprise après sinistre est une instance répliquée interrégionale avec accès en lecture directement connectée.
- Vous pouvez modifier la désignation de l'instance répliquée de reprise après sinistre plusieurs fois.
- Vous pouvez modifier la désignation de l'instance répliquée de reprise après sinistre à tout moment, sauf lors d'une opération de basculement ou de basculement d'instance répliquée.
En outre, pour réduire le RTO après l'utilisation de la reprise après sinistre avancée, nous vous recommandons d'effectuer les opérations suivantes :
- Configurez l'instance répliquée de reprise après sinistre de la même taille que l'instance principale.
- Si la haute disponibilité est activée sur l'instance principale, nous vous recommandons également d'activer la haute disponibilité sur l'instance répliquée de DR. Pour ce faire, commencez par vérifier que la haute disponibilité est activée sur l'instance principale. Effectuez ensuite la commutation vers l'instance répliquée de reprise après sinistre. Une fois l'opération de commutation terminée, activez la haute disponibilité sur la nouvelle instance principale. Vous pouvez ensuite revenir à l'ancienne instance principale. L'instance répliquée de reprise après sinistre conserve sa configuration haute disponibilité même après qu'elle redevient une instance répliquée.
Basculement d'instance répliquée
En résumé, un basculement d'instance répliquée comprend les événements suivants :
- Vous créez et attribuez une instance répliquée de reprise après sinistre.
- La région principale devient indisponible.
- Vous effectuez le basculement d'instance répliquée vers l'instance répliquée de reprise après sinistre.
- Le point de terminaison d'écriture est mis à jour et commence à pointer vers la nouvelle instance principale.
- Lorsque l'instance principale d'origine redevient en ligne, elle devient une instance répliquée avec accès en lecture de la nouvelle instance principale.
- Vous pouvez utiliser l'opération de commutation pour restaurer la topologie d'origine de votre déploiement.
Pour afficher les détails et les schémas d'une opération de basculement d'instance répliquée, cliquez sur les onglets suivants.
Attribuer une instance répliquée de reprise après sinistre
Avant d'effectuer un basculement d'instance répliquée, vous avez attribué une instance répliquée de reprise après sinistre à l'instance principale et vous avez peut-être testé le processus en effectuant un basculement.

Une indisponibilité se produit
La région principale, dans laquelle la base de données principale est exécutée, devient indisponible.

Basculement d'instance répliquée
Après avoir déterminé qu'une reprise après sinistre est nécessaire, vous effectuez un basculement d'instance répliquée vers l'instance répliquée de reprise après sinistre désignée interrégionale.
L'instance répliquée de reprise après sinistre interrégionale désignée devient immédiatement l'instance principale et commence à accepter les lectures et les écritures entrantes. Le point de terminaison d'écriture est mis à jour et commence à pointer vers la nouvelle instance principale.

L'instance principale d'origine devient une instance répliquée
Une fois l'instance répliquée promue, Cloud SQL vérifie régulièrement si l'instance principale d'origine est de nouveau en ligne. Si l'instance principale d'origine est en ligne, Cloud SQL recrée l'ancienne instance principale en tant qu'instance répliquée de l'instance promue. L'ancienne instance principale conserve son adresse IP.

Restauration automatique à la version d'origine
Une fois que vous avez effectué un basculement d'instance répliquée, vous pouvez restaurer l'instance principale dans votre région d'origine en effectuant l'opération de commutation, en inversant la même paire d'instances répliquées de reprise après sinistre et d'instance principale.

Commutation
En résumé, une opération de basculement comprend les événements suivants :
- Vous créez et attribuez une instance répliquée de reprise après sinistre.
- Vous lancez une commutation.
- Lorsque le délai de réplication est réduit à zéro, la nouvelle instance principale commence à accepter les connexions entrantes.
- L'ancienne instance principale devient une instance répliquée avec accès en lecture.
- Si un point de terminaison d'écriture DNS est utilisé, il est mis à jour pour pointer vers la nouvelle instance principale.
Pour afficher les détails et les schémas d'une opération de permutation, cliquez sur les onglets suivants.
Attribuer une instance répliquée de reprise après sinistre
Avant de lancer l'opération de *commutation*, vous devez attribuer une instance répliquée de reprise après sinistre à l'instance principale.
Vérifiez que l'instance principale est opérationnelle. Vous ne pouvez effectuer un basculement que lorsque l'instance principale et l'instance répliquée de reprise après sinistre sont en ligne.
Lancer la commutation
Vous lancez la commutation. Lorsque vous lancez une commutation, l'instance principale cesse d'accepter des écritures et passe en lecture seule. Cloud SQL attend que les journaux de transactions soient copiés dans Cloud Storage. L'instance répliquée de reprise après sinistre désignée rattrape l'instance principale.
Lorsque le délai de réplication est réduit à zéro, l'instance répliquée de reprise après sinistre est promue en tant que nouvelle instance principale. La nouvelle instance principale commence à accepter les connexions entrantes, y compris les lectures et les écritures d'applications.
Point de terminaison modifié
Une fois l'instance répliquée de reprise après sinistre promue en nouvelle instance principale, le point de terminaison d'écriture DNS est mis à jour et commence à pointer vers la nouvelle instance principale. Si vous n'utilisez pas de point de terminaison d'écriture DNS, vous devez configurer vos applications pour qu'elles pointent vers l'adresse IP de la nouvelle instance principale.
L'ancienne instance principale est reconfigurée en tant qu'instance répliquée avec accès en lecture.
La récupération PITR est activée automatiquement pour la nouvelle instance principale. La récupération PITR n'est possible qu'après la première sauvegarde automatique.
Point de terminaison d'écriture
Un point de terminaison d'écriture est un nom de service de nom de domaine (DNS) global qui pointe automatiquement vers l'adresse IP de l'instance principale actuelle. Ce point de terminaison redirige automatiquement les connexions entrantes vers la nouvelle instance principale en cas d'opération de basculement d'instance répliquée ou de commutation. Vous pouvez utiliser le point de terminaison d'écriture dans une chaîne de connexion SQL au lieu d'une adresse IP. En utilisant un point de terminaison d'écriture, vous pouvez éviter d'avoir à modifier la connexion de l'application en cas de panne régionale.
Un point de terminaison d'écriture nécessite que l'API Cloud DNS soit activée sur le projet dans lequel vous créez ou disposez de votre instance principale Cloud SQL Enterprise Plus. Lorsque vous créez une instance Cloud SQL Enterprise Plus avec une adresse IP privée et des réseaux autorisés, Cloud SQL génère automatiquement un point de terminaison d'écriture pour l'instance. Si vous disposez déjà d'une instance principale de l'édition Cloud SQL Enterprise Plus, Cloud SQL génère le point de terminaison d'écriture lorsque vous créez l'instance répliquée de reprise après sinistre (une instance répliquée interrégionale que vous désignez pour l'instance principale). Si l'instance principale change en raison d'une opération de commutation ou de commutation d'instance répliquée, Cloud SQL attribue le point de terminaison d'écriture à l'instance répliquée de reprise après sinistre lorsque celle-ci devient la nouvelle instance principale.
Pour en savoir plus sur l'utilisation d'un point de terminaison d'écriture pour vous connecter à une instance, consultez Se connecter à une instance à l'aide d'un point de terminaison d'écriture.
Étapes suivantes
- Utilisez la reprise après sinistre avancée.
- Suivez le tutoriel sur la reprise après sinistre Cloud SQL pour MySQL.
- Découvrez des architectures de référence, des schémas, des tutoriels et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.