Auf dieser Seite wird beschrieben, wie Cloud TPU mit Google Kubernetes Engine (GKE) funktioniert. Dazu gehören Terminologie, die Vorteile von Tensor Processing Units (TPUs) und Überlegungen zur Arbeitslastplanung. TPUs sind von Google speziell entwickelte anwendungsspezifische integrierte Schaltungen (Application-Specific Integrated Circuits, ASICs), die verwendet werden, um ML-Arbeitslasten zu beschleunigen, die Frameworks wie TensorFlow, PyTorch und JAX nutzen.
Diese Seite richtet sich an Plattformadministratoren und ‑operatoren sowie an Daten- und KI-Spezialisten, die ML-Modelle (maschinelles Lernen) ausführen, die sich durch Merkmale wie Skalierbarkeit, lange Laufzeiten oder Matrixberechnungen auszeichnen. Weitere Informationen zu gängigen Rollen und Beispielaufgaben, auf die wir in Google Cloud-Inhalten verweisen, finden Sie unter Häufig verwendete GKE-Nutzerrollen und ‑Aufgaben.
Bevor Sie diese Seite lesen, sollten Sie sich mit der Funktionsweise von ML-Beschleunigern vertraut machen. Weitere Informationen finden Sie unter Einführung in Cloud TPU.
Vorteile von TPUs in GKE
GKE bietet vollständige Unterstützung für die Verwaltung des TPU-Knoten- und Knotenpool-Lebenszyklus, einschließlich des Erstellens, Konfigurierens und Löschens von TPU-VMs. GKE unterstützt auch Spot-VMs sowie die Verwendung von reservierten Cloud TPU. Weitere Informationen finden Sie unter Cloud TPU-Nutzungsoptionen.
TPUs in GKE bieten folgende Vorteile:
- Einheitliche Betriebsumgebung:Sie können eine einzige Plattform für alle ML- und sonstigen Arbeitslasten verwenden.
- Automatische Upgrades:GKE automatisiert Versionsupdates, wodurch der operative Aufwand reduziert wird.
- Load-Balancing:GKE verteilt die Last, um die Latenz zu reduzieren und die Zuverlässigkeit zu verbessern.
- Responsive Skalierung:GKE skaliert TPU-Ressourcen automatisch entsprechend den Anforderungen Ihrer Arbeitslasten.
- Ressourcenverwaltung:Mit Kueue, einem nativen Kubernetes-Jobwarteschlangensystem, können Sie Ressourcen über mehrere Mandanten innerhalb Ihrer Organisation verwalten, indem Sie Warteschlangen, vorzeitiges Beenden, Priorisierung und faire Freigabe nutzen.
- Sandboxing-Optionen:GKE Sandbox schützt Ihre Arbeitslasten mit gVisor. Weitere Informationen finden Sie unter GKE Sandbox.
Vorteile der Verwendung von TPU Trillium
Trillium ist die TPU der sechsten Generation von Google. Trillium bietet folgende Vorteile:
- Trillium bietet im Vergleich zu TPU v5e eine höhere Rechenleistung pro Chip.
- Bei Trillium werden die Kapazität und Bandbreite des Speichers mit hoher Bandbreite (High Bandwidth Memory, HBM) sowie die Bandbreite der Interchip-Verbindung (Interchip Interconnect, ICI) im Vergleich zu TPU v5e erhöht.
- Trillium ist mit SparseCore der dritten Generation ausgestattet, einem speziellen Beschleuniger für die Verarbeitung extrem großer Einbettungen, wie sie bei anspruchsvollen Ranking- und Empfehlungs-Arbeitslasten üblich sind.
- Trillium ist über 67% energieeffizienter als TPU v5e.
- Trillium kann auf bis zu 256 TPUs in einem einzelnen TPU-Slice mit hoher Bandbreite und niedriger Latenz skaliert werden.
- Trillium unterstützt die Planung der Erfassung. Mit der Planung von Sammlungen können Sie eine Gruppe von TPUs (TPU-Slice-Knotenpools mit einem und mehreren Hosts) deklarieren, um eine hohe Verfügbarkeit für die Anforderungen Ihrer Inferenz-Arbeitslasten zu gewährleisten.
Auf allen technischen Oberflächen wie APIs und Logs sowie in bestimmten Teilen der GKE-Dokumentation verwenden wir v6e oder TPU Trillium (v6e), um auf Trillium-TPUs zu verweisen. Weitere Informationen zu den Vorteilen von Trillium finden Sie im Blogpost zur Ankündigung von Trillium. Informationen zum Einrichten von TPUs finden Sie unter TPUs in GKE planen.
Terminologie in Bezug auf TPUs in GKE
Auf dieser Seite werden die folgenden Begriffe im Zusammenhang mit TPUs verwendet:
- TPU-Typ:Der Cloud TPU-Typ, z. B. „v5e“.
- TPU-Slice-Knoten:Ein Kubernetes-Knoten, der durch eine einzelne VM mit einem oder mehreren verbundenen TPU-Chips dargestellt wird.
- TPU-Slice-Knotenpool:Eine Gruppe von Kubernetes-Knoten in einem Cluster, die alle dieselbe TPU-Konfiguration haben.
- TPU-Topologie:Die Anzahl und die physische Anordnung der TPU-Chips in einem TPU-Slice.
- Atomar:GKE behandelt alle miteinander verbundenen Knoten als eine Einheit. Bei Skalierungsvorgängen skaliert GKE alle Knoten auf 0 und erstellt neue Knoten. Wenn eine Maschine in der Gruppe ausfällt oder beendet wird, erstellt GKE den gesamten Satz von Knoten als neue Einheit neu.
- Unveränderlich:Sie können dem Satz verbundener Knoten nicht manuell neue Knoten hinzufügen. Sie können jedoch einen neuen Knotenpool mit der gewünschten TPU-Topologie erstellen und Arbeitslasten für den neuen Knotenpool planen.
Typen von TPU-Slice-Knotenpools
GKE unterstützt zwei Arten von TPU-Knotenpools:
Der TPU-Typ und die TPU-Topologie bestimmen, ob Ihr TPU-Slice-Knoten mehrere Hosts oder einen einzelnen Host haben kann. Unsere Empfehlungen lauten daher:
- Verwenden Sie für umfangreiche Modelle TPU-Slice-Knoten mit mehreren Hosts.
- Verwenden Sie für kleine Modelle TPU-Slice-Knoten mit einzelnen Hosts.
- Verwenden Sie für umfangreiches Training oder Inferenz Pathways. Pathways vereinfacht umfangreiche ML-Berechnungen, da ein einzelner JAX-Client Arbeitslasten auf mehreren großen TPU-Slices orchestrieren kann. Weitere Informationen finden Sie unter Pathways.
TPU-Slice-Knotenpools mit mehreren Hosts
Ein TPU-Slice-Knotenpool mit mehreren Hosts ist ein Knotenpool, der zwei oder mehr verbundene TPU-VMs enthält. Jeder VM ist ein TPU-Gerät zugeordnet. Die TPUs in einem TPU-Slice mit mehreren Hosts sind über eine Hochgeschwindigkeitsverbindung (ICI) verbunden. Nachdem ein TPU-Slice-Knotenpool mit mehreren Hosts erstellt wurde, können Sie ihm keine Knoten mehr hinzufügen. Sie können beispielsweise keinen v4-32-Knotenpool erstellen und ihm später einen Kubernetes-Knoten (TPU-VM) hinzufügen. Wenn Sie einem GKE-Cluster ein TPU-Slice hinzufügen möchten, müssen Sie einen neuen Knotenpool erstellen.
Die VMs in einem TPU-Slice-Knotenpool mit mehreren Hosts werden als eine atomare Einheit behandelt. Wenn GKE einen Knoten im Slice nicht bereitstellen kann, werden keine Knoten im TPU-Slice-Knoten bereitgestellt.
Wenn ein Knoten in einem TPU-Slice mit mehreren Hosts repariert werden muss, fährt GKE alle VMs im TPU-Slice herunter und erzwingt so das Entfernen aller Kubernetes-Pods in der Arbeitslast. Sobald alle VMs im TPU-Slice ausgeführt werden, können die Kubernetes-Pods auf den VMs im neuen TPU-Slice geplant werden.
Das folgende Diagramm zeigt einen TPU-Slice mit mehreren Hosts vom Typ v5litepod-16 (v5e). Dieses TPU-Slice hat vier VMs. Jede VM im TPU-Slice hat vier TPU v5e-Chips, die über Hochgeschwindigkeitsverbindungen (Inter-Chip Interconnect, ICI) verbunden sind. Jeder TPU v5e-Chip hat einen TensorCore:
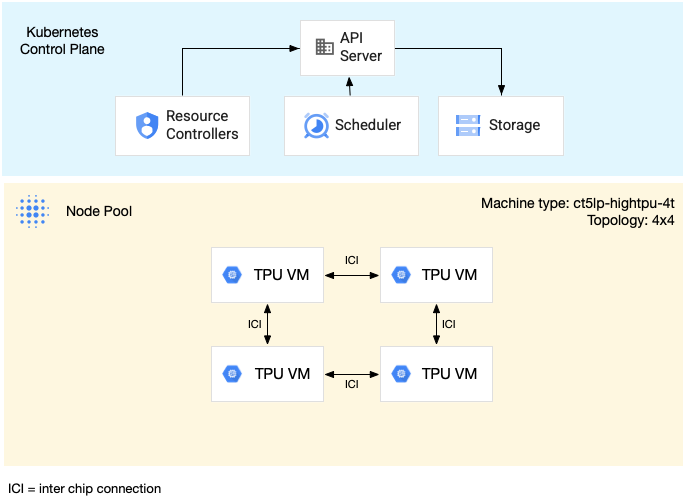
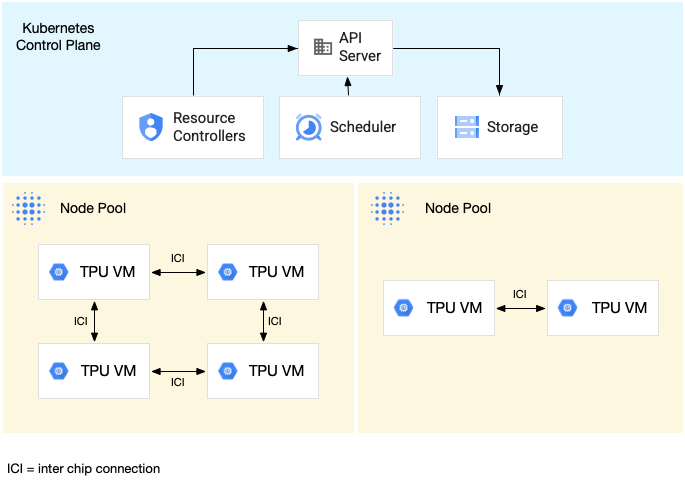
Das folgende Diagramm zeigt einen GKE-Cluster, der einen TPU-v5litepod-16-Slice (v5e) (Topologie: 4x4) und einen TPU-v5litepod-8-Slice (v5e) (Topologie: 2x4) enthält:
TPU-Slice-Knotenpools mit einem Host
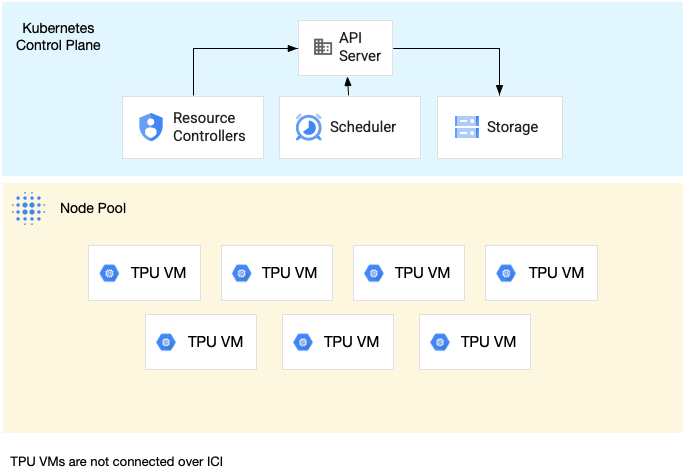
Ein Knotenpool mit TPU-Slice mit einem einzelnen Host ist ein Knotenpool, der eine oder mehrere unabhängige TPU-VMs enthält. Jeder VM ist ein TPU-Gerät zugeordnet. Die VMs in einem TPU-Slice-Knotenpool mit einzelnen Hosts können zwar über das Data Center Network (DCN) kommunizieren, die an die VMs angehängten TPUs sind jedoch nicht miteinander verbunden.
Das folgende Diagramm zeigt ein Beispiel für einen TPU-Slice mit einem einzelnen Host, der sieben v4-8-Maschinen enthält:
Merkmale von TPUs in GKE
TPUs haben besondere Merkmale, die eine spezielle Planung und Konfiguration erfordern.
TPU-Nutzung
Um die Ressourcenauslastung und die Kosten zu optimieren und gleichzeitig die Arbeitslastleistung auszugleichen, unterstützt GKE die folgenden Optionen für den TPU-Verbrauch:
- Flex-Start:Flex-Start-VMs werden für bis zu sieben Tage bereitgestellt. GKE weist die Hardware automatisch auf Best-Effort-Basis entsprechend der Verfügbarkeit zu. Weitere Informationen finden Sie unter GPU-, TPU- und H4D-Nutzung mit dem Bereitstellungsmodus „Flex-Start“.
- Spot-VMs:Wenn Sie Spot-VMs bereitstellen, können Sie erhebliche Rabatte erhalten. Spot-VMs können jedoch jederzeit vorzeitig beendet werden. Sie erhalten 30 Sekunden vor dem Beenden eine Warnung. Weitere Informationen finden Sie unter Spot-VMs.
- Vorausschauende Reservierung für bis zu 90 Tage (im Kalendermodus): Damit können Sie TPU-Ressourcen für bis zu 90 Tage für einen bestimmten Zeitraum bereitstellen. Weitere Informationen finden Sie unter TPUs mit vorausschauender Reservierung im Kalendermodus anfordern.
- TPU-Reservierungen:Vorausschauende Reservierung für ein Jahr oder länger anfordern
Informationen zum Auswählen der Nutzungsoption, die Ihren Arbeitslastanforderungen entspricht, finden Sie unter Beschleuniger-Nutzungsoptionen für KI-/ML-Arbeitslasten in GKE.
Bevor Sie TPUs in GKE verwenden, sollten Sie die Verbrauchsoption auswählen, die am besten zu den Anforderungen Ihrer Arbeitslast passt.
Topologie
Die Topologie definiert die physische Anordnung von TPUs in einem TPU-Slice. GKE stellt ein TPU-Slice in zwei- oder dreidimensionalen Topologien bereit, je nach TPU-Version. Sie geben eine Topologie als Anzahl der TPU-Chips in jeder Dimension an:
Für TPU v4 und v5p, das in TPU-Slice-Knotenpools mit mehreren Hosts geplant ist, definieren Sie die Topologie in 3-Tupeln ({A}x{B}x{C}), z. B. 4x4x4. Das Produkt von {A}x{B}x{C} definiert die Anzahl der TPU-Chips im Knotenpool. Beispielsweise können Sie kleine Topologien mit weniger als 64 TPU-Chips mit Topologieformen wie 2x2x2, 2x2x4 oder 2x4x4 definieren. Wenn Sie größere Topologien mit mehr als 64 TPU-Chips verwenden, müssen die Werte, die Sie {A}, {B} und {C} zuweisen, die folgenden Bedingungen erfüllen:
- {A}, {B} und {C} müssen Vielfache von vier sein.
- Die größte unterstützte Topologie für v4 ist
12x16x16und für v5p ist16x16x24. - Die zugewiesenen Werte müssen dem Muster A ≤ B ≤ C entsprechen. Beispiel:
4x4x8oder8x8x8.
Maschinentyp
Maschinentypen, die TPU-Ressourcen unterstützen, folgen einer Namenskonvention, die die TPU-Version und die Anzahl der TPU-Chips pro Knoten-Slice wie ct<version>-hightpu-<node-chip-count>t enthält. Der Maschinentyp ct5lp-hightpu-1t unterstützt beispielsweise TPU v5e und enthält nur einen TPU-Chip.
Privilegierter Modus
Wenn Sie GKE-Versionen vor 1.28 verwenden, müssen Sie Ihre Container mit speziellen Funktionen für den Zugriff auf TPUs konfigurieren. In Clustern im Standardmodus können Sie den privilegierten Modus verwenden, um diesen Zugriff zu gewähren. Im privilegierten Modus werden viele der anderen Sicherheitseinstellungen in der securityContext überschrieben. Weitere Informationen finden Sie unter Container ohne privilegierten Modus ausführen.
Für Version 1.28 und höher sind der privilegierte Modus oder spezielle Funktionen nicht erforderlich.
Funktionsweise von TPUs in GKE
Die Kubernetes-Ressourcenverwaltung und -Priorisierung behandelt VMs auf TPUs so wie andere VM-Typen. Sie fordern TPU-Chips über den Ressourcennamen google.com/tpu an:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Wenn Sie TPUs in GKE verwenden, müssen Sie die folgenden TPU-Eigenschaften beachten:
- Eine VM kann auf bis zu 8 TPU-Chips zugreifen.
- Ein TPU-Slice enthält eine feste Anzahl von TPU-Chips, die vom ausgewählten TPU-Maschinentyp abhängt.
- Die Anzahl der angeforderten
google.com/tpumuss der Gesamtzahl der verfügbaren TPU-Chips auf dem TPU-Slice-Knoten entsprechen. Jeder Container in einem GKE-Pod, der TPUs anfordert, muss alle TPU-Chips im Knoten nutzen. Andernfalls schlägt das Deployment fehl, da GKE die TPU-Ressourcen nicht teilweise nutzen kann. Sehen Sie sich die folgenden Szenarien an:- Der Maschinentyp
ct5lp-hightpu-4tmit einer2x4-Topologie enthält zwei TPU-Slice-Knoten mit jeweils vier TPU-Chips, also insgesamt acht TPU-Chips. Mit diesem Maschinentyp haben Sie folgende Möglichkeiten: - Ein GKE-Pod, für den acht TPU-Chips erforderlich sind, kann auf den Knoten in diesem Knotenpool nicht bereitgestellt werden.
- Es können zwei Pods bereitgestellt werden, die jeweils vier TPU-Chips erfordern. Jeder Pod wird auf einem der beiden Knoten in diesem Knotenpool bereitgestellt.
- TPU v5e mit der Topologie 4 × 4 hat 16 TPU-Chips auf vier Knoten. Für die GKE Autopilot-Arbeitslast, die diese Konfiguration auswählt, müssen in jedem Replikat vier TPU-Chips angefordert werden, und zwar für ein bis vier Replikate.
- Der Maschinentyp
- In Standardclustern können auf einer VM mehrere Kubernetes-Pods geplant werden, aber in jedem Pod kann nur ein Container auf die TPU-Chips zugreifen.
- Um kube-system-Pods wie kube-dns zu erstellen, muss jeder Standard-Cluster mindestens einen Nicht-TPU-Slice-Knotenpool haben.
- Standardmäßig haben TPU-Slice-Knoten die
google.com/tpu-Markierung, wodurch verhindert wird, dass Nicht-TPU-Arbeitslasten auf den TPU-Slice-Knoten geplant werden. Arbeitslasten, die keine TPUs verwenden, werden auf Nicht-TPU-Knoten ausgeführt. So werden TPU-Slice-Knoten für Code freigegeben, der TPUs verwendet. Die Markierung sorgt nicht automatisch dafür, dass TPU-Ressourcen vollständig genutzt werden. - GKE erfasst die Logs, die von Containern auf TPU-Slice-Knoten ausgegeben werden. Weitere Informationen finden Sie unter Logging.
- TPU-Auslastungsmesswerte wie Laufzeitleistung sind in Cloud Monitoring verfügbar. Weitere Informationen finden Sie unter Beobachtbarkeit und Messwerte.
- Sie können Ihre TPU-Arbeitslasten mit GKE Sandbox in einer Sandbox ausführen. GKE Sandbox funktioniert mit TPU-Modellen ab Version 4. Weitere Informationen finden Sie unter GKE Sandbox.
So funktioniert die Planung von Sammlungen
In TPU Trillium können Sie die Planung von Sammlungen verwenden, um TPU-Slice-Knoten zu gruppieren. Durch das Gruppieren dieser TPU-Slice-Knoten lässt sich die Anzahl der Replikate leichter an die Arbeitslastanforderungen anpassen. Google Cloud steuert Softwareupdates, um dafür zu sorgen, dass immer genügend Slices in der Sammlung verfügbar sind, um Traffic zu verarbeiten.
TPU Trillium unterstützt die Planung von Sammlungen für Knotenpools mit einem einzelnen Host und mehreren Hosts, auf denen Inferenz-Arbeitslasten ausgeführt werden. Im Folgenden wird beschrieben, wie sich die Planung von Sammlungen je nach verwendetem TPU-Slice-Typ verhält:
- TPU-Slice mit mehreren Hosts:GKE gruppiert TPU-Slices mit mehreren Hosts zu einer Sammlung. Jeder GKE-Knotenpool ist ein Replikat in dieser Sammlung. Wenn Sie eine Sammlung definieren möchten, erstellen Sie einen TPU-Slice mit mehreren Hosts und weisen Sie der Sammlung einen eindeutigen Namen zu. Wenn Sie der Sammlung weitere TPU-Slices hinzufügen möchten, erstellen Sie einen weiteren TPU-Slice-Knotenpool mit mehreren Hosts mit demselben Sammlungsnamen und Arbeitslasttyp.
- TPU-Slice mit einem Host:GKE betrachtet den gesamten TPU-Slice-Knotenpool mit einem Host als Sammlung. Wenn Sie der Sammlung weitere TPU-Slices hinzufügen möchten, können Sie die Größe des TPU-Slice-Knotenpools mit einem Host ändern.
Für die Planung von Erfassungen gelten die folgenden Einschränkungen:
- Sie können Sammlungen nur für TPU Trillium planen.
- Sie können Sammlungen nur bei der Erstellung von Knotenpools definieren.
- Spot-VMs werden nicht unterstützt.
- Für Sammlungen, die TPU-Slice-Knotenpools mit mehreren Hosts enthalten, müssen alle Knotenpools in der Sammlung denselben Maschinentyp, dieselbe Topologie und dieselbe Version verwenden.
Sie können die Planung der Erhebung in den folgenden Szenarien konfigurieren:
- Beim Erstellen eines TPU-Slice-Knotenpools in GKE Standard
- Arbeitslasten in GKE Autopilot bereitstellen
- Beim Erstellen eines Clusters, der die automatische Knotenbereitstellung ermöglicht
Nächste Schritte
Informationen zum Einrichten von Cloud TPU in GKE finden Sie auf den folgenden Seiten:
- TPUs in GKE planen, um die TPU-Einrichtung zu starten
- TPU-Arbeitslasten in GKE Autopilot bereitstellen
- TPU-Arbeitslasten in GKE Standard bereitstellen
- Best Practices für die Verwendung von Cloud TPU für Ihre ML-Aufgaben
- Video: Umfangreiches maschinelles Lernen auf Cloud TPU mit GKE erstellen
- Large Language Models mit KubeRay auf TPUs bereitstellen
- Informationen zum Sandboxing von GPU-Arbeitslasten mit GKE Sandbox