This tutorial shows you how to serve large language models (LLMs) using Tensor Processing Units (TPUs) on Google Kubernetes Engine (GKE) with the vLLM serving framework. In this tutorial, you serve Llama 3.1 70b, use TPU Trillium, and set up horizontal Pod autoscaling using vLLM server metrics.
This document is a good starting point if you need the granular control, scalability, resilience, portability, and cost-effectiveness of managed Kubernetes when you deploy and serve your AI/ML workloads.
Background
By using TPU Trillium on GKE, you can implement a robust, production-ready serving solution with all the benefits of managed Kubernetes, including efficient scalability and higher availability. This section describes the key technologies used in this guide.
TPU Trillium
TPUs are Google's custom-developed application-specific integrated circuits (ASICs). TPUs are used to accelerate machine learning and AI models built using frameworks such as TensorFlow, PyTorch, and JAX. This tutorial uses TPU Trillium, which is Google's sixth generation TPU.
Before you use TPUs in GKE, we recommend that you complete the following learning path:
- Learn about TPU Trillium system architecture.
- Learn about TPUs in GKE.
vLLM
vLLM is a highly optimized, open-source framework for serving LLMs. vLLM can increase serving throughput on TPUs, with features such as the following:
- Optimized transformer implementation with PagedAttention.
- Continuous batching to improve the overall serving throughput.
- Tensor parallelism and distributed serving on multiple TPUs.
To learn more, refer to the vLLM documentation.
Cloud Storage FUSE
Cloud Storage FUSE provides access from your GKE cluster to Cloud Storage for model weights that reside in object storage buckets. In this tutorial, the created Cloud Storage bucket will initially be empty. When vLLM starts up, GKE downloads the model from Hugging Face and caches the weights to the Cloud Storage bucket. On Pod restart, or deployment scale-up, subsequent model loads will download cached data from the Cloud Storage bucket, leveraging parallel downloads for optimal performance.
To learn more, refer to the Cloud Storage FUSE CSI driver documentation.
Objectives
This tutorial is intended for MLOps or DevOps engineers or platform administrators who want to use GKE orchestration capabilities for serving LLMs.
This tutorial covers the following steps:
- Create a GKE cluster with the recommended TPU Trillium topology based on the model characteristics.
- Deploy the vLLM framework on a node pool in your cluster.
- Use the vLLM framework to serve Llama 3.1 70b using a load balancer.
- Set up horizontal Pod autoscaling using vLLM server metrics.
- Serve the model.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminCheck for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
- Click Grant access.
-
In the New principals field, enter your user identifier. This is typically the email address for a Google Account.
- In the Select a role list, select a role.
- To grant additional roles, click Add another role and add each additional role.
- Click Save.
-
- Create a Hugging Face account, if you don't already have one.
- Ensure your project has sufficient quota for Cloud TPU in GKE.
Prepare the environment
In this section, you provision the resources that you need to deploy vLLM and the model.
Get access to the model
You must sign the consent agreement to use Llama 3.1 70b in the Hugging Face repository.
Generate an access token
If you don't already have one, generate a new Hugging Face token:
- Click Your Profile > Settings > Access Tokens.
- Select New Token.
- Specify a Name of your choice and a Role of at least
Read. - Select Generate a token.
Launch Cloud Shell
In this tutorial, you use Cloud Shell to manage resources hosted on
Google Cloud. Cloud Shell comes preinstalled with the software you need
for this tutorial, including
kubectl and the
gcloud CLI.
To set up your environment with Cloud Shell, follow these steps:
In the Google Cloud console, launch a Cloud Shell session by clicking
 Activate Cloud Shell in the Google Cloud console. This launches a session in the
bottom pane of the Google Cloud console.
Activate Cloud Shell in the Google Cloud console. This launches a session in the
bottom pane of the Google Cloud console.Set the default environment variables:
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACEReplace the following values:
- PROJECT_ID : your Google Cloud project ID.
- CLUSTER_NAME : the name of your GKE cluster.
- CONTROL_PLANE_LOCATION: the Compute Engine region of the control plane of your cluster. Provide a region that supports TPU Trillium (v6e).
- ZONE : a zone that supports TPU Trillium (v6e).
- CLUSTER_VERSION : the GKE version, which must support the machine type that you want to use. Note that the default GKE version might not have availability for your target TPU. TPU Trillium (v6e) is supported in GKE versions 1.31.2-gke.1115000 or later.
- GSBUCKET : the name of the Cloud Storage bucket to use for Cloud Storage FUSE.
- KSA_NAME : the name of the Kubernetes ServiceAccount that's used to access Cloud Storage buckets. Bucket access is needed for Cloud Storage FUSE to work.
- NAMESPACE : the Kubernetes namespace where you want to deploy the vLLM assets.
Create a GKE cluster
You can serve LLMs on TPUs in a GKE Autopilot or Standard cluster. We recommend that you use a Autopilot cluster for a fully managed Kubernetes experience. To choose the GKE mode of operation that's the best fit for your workloads, see Choose a GKE mode of operation.
Autopilot
Create a GKE Autopilot cluster:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
Create a GKE Standard cluster:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverCreate a TPU slice node pool:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE creates the following resources for the LLM:
- A GKE Standard cluster that uses Workload Identity Federation for GKE and has Cloud Storage FUSE CSI driver enabled.
- A TPU Trillium node pool with a
ct6e-standard-8tmachine type. This node pool has one node, eight TPU chips, and autoscaling enabled.
Configure kubectl to communicate with your cluster
To configure kubectl to communicate with your cluster, run the following command:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Create a Kubernetes Secret for Hugging Face credentials
Create a namespace. You can skip this step if you are using the
defaultnamespace:kubectl create namespace ${NAMESPACE}Create a Kubernetes Secret that contains the Hugging Face token, run the following command:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Create a Cloud Storage bucket
In Cloud Shell, run the following command:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
This creates a Cloud Storage bucket to store the model files you download from Hugging Face.
Set up a Kubernetes ServiceAccount to access the bucket
Create the Kubernetes ServiceAccount:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Grant read-write access to the Kubernetes ServiceAccount in order to access the Cloud Storage bucket:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Alternatively, you can grant read-write access to all Cloud Storage buckets in the project:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE creates the following resources for the LLM:
- A Cloud Storage bucket to store the downloaded model and the compilation cache. A Cloud Storage FUSE CSI driver reads the content of the bucket.
- Volumes with file caching enabled and the parallel download feature of Cloud Storage FUSE.
Best practice: Use a file cache backed by
tmpfsorHyperdisk / Persistent Diskdepending on the expected size of the model contents, for example, weight files. In this tutorial, you use Cloud Storage FUSE file cache backed by RAM.
Deploy vLLM model server
To deploy the vLLM model server, this tutorial uses a Kubernetes Deployment. A Deployment is a Kubernetes API object that lets you run multiple replicas of Pods that are distributed among the nodes in a cluster..
Inspect the following Deployment manifest saved as
vllm-llama3-70b.yaml, that uses a single replica:If you scale up the Deployment to multiple replicas, the concurrent writes to the
VLLM_XLA_CACHE_PATHwill cause the error:RuntimeError: filesystem error: cannot create directories. To prevent this error, you have two options:Remove the XLA cache location by removing the following block from the Deployment YAML. This means all replicas will recompile the cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Scale the Deployment to
1, and wait for the first replica to become ready and write to the XLA cache. Then scale to additional replicas. This allows the remainder of the replicas to read the cache, without attempting to write it.
Apply the manifest by running the following command:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}View the logs from the running model server:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}The output should look similar to the following:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Serve the model
To get the external IP address of the VLLM service, run the following command:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interact with the model using
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'The output should be similar to the following:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Set up the custom autoscaler
In this section, you set up horizontal Pod autoscaling using custom Prometheus metrics. You use the Google Cloud Managed Service for Prometheus metrics from the vLLM server.
To learn more, see Google Cloud Managed Service for Prometheus. This should be enabled by default on the GKE cluster.
Set up the Custom Metrics Stackdriver Adapter on your cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAdd the Monitoring Viewer role to the service account that the Custom Metrics Stackdriver Adapter uses:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSave the following manifest as
vllm_pod_monitor.yaml:Apply it to the cluster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Create load on the vLLM endpoint
Create load to the vLLM server to test how GKE autoscales with a custom vLLM metric.
Run a bash script (
load.sh) to sendNnumber of parallel requests to the vLLM endpoint:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitReplace PARALLEL_PROCESSES with the number of parallel processes that you want to run.
Run the bash script:
chmod +x load.sh nohup ./load.sh &
Verify that Google Cloud Managed Service for Prometheus ingests the metrics
After Google Cloud Managed Service for Prometheus scrapes the metrics and you're adding load to the vLLM endpoint, you can view metrics on Cloud Monitoring.
In the Google Cloud console, go to the Metrics explorer page.
Click < > PromQL.
Enter the following query to observe traffic metrics:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
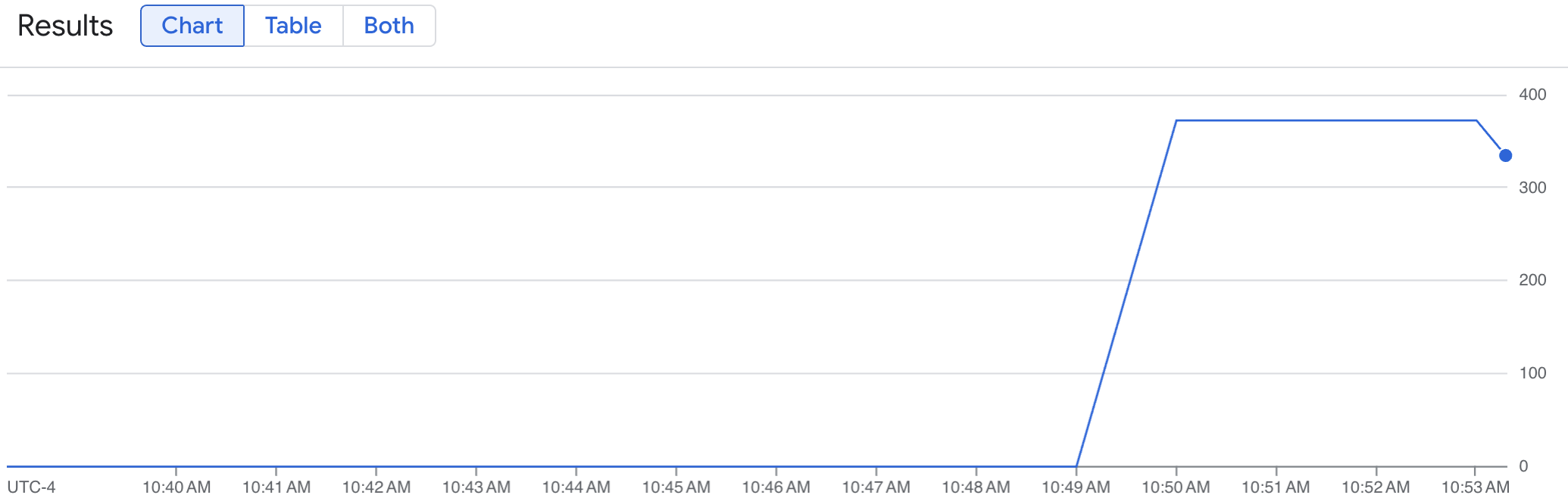
A line graph shows your vLLM metric (num_requests_waiting) measured over time. The vLLM metric scales up from 0 (pre-load) to a value (post-load). This graph confirms your vLLM metrics are being ingested into Google Cloud Managed Service for Prometheus. The following example graph shows a starting pre-load value of 0, which reaches a maximum post-load value of close to 400 within one minute.
Deploy the Horizontal Pod Autoscaler configuration
When deciding which metric to autoscale on, we recommend the following metrics for vLLM TPU:
num_requests_waiting: This metric relates to the number of requests waiting in the model server's queue. This number starts to noticeably grow when the kv cache is full.gpu_cache_usage_perc: This metric relates to the kv cache utilization, which directly correlates to the number of requests being processed for a given inference cycle on the model server. Note that this metric works the same on GPUs and TPUs, though it is tied to the GPU naming schema.
We recommend that you use num_requests_waiting when optimizing for throughput and cost, and when your latency targets are achievable with your model server's maximum throughput.
We recommend that you use gpu_cache_usage_perc when you have latency-sensitive workloads where queue-based scaling isn't fast enough to meet your requirements.
For further explanation, check out Best practices for autoscaling large language model (LLM) inference workloads with TPUs.
When selecting an averageValue target for your HPA config, you will have to determine this experimentally. Check out the Save on GPUs: Smarter autoscaling for your GKE inferencing workloads blog post for additional ideas on how to optimize this part. The profile-generator used in this blog post works for vLLM TPU as well.
In the following instructions, you deploy your HPA configuration by using the num_requests_waiting metric. For demonstration purposes, you set the metric to a low value so that the HPA configuration scales your vLLM replicas to two. To deploy the Horizontal Pod Autoscaler configuration using num_requests_waiting, follow these steps:
Save the following manifest as
vllm-hpa.yaml:The vLLM metrics in Google Cloud Managed Service for Prometheus follow the
vllm:metric_nameformat.Best practice: Use
num_requests_waitingfor scaling throughput. Usegpu_cache_usage_percfor latency-sensitive TPU use cases.Deploy the Horizontal Pod Autoscaler configuration:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE schedules another Pod to deploy, which triggers the node pool autoscaler to add a second node before it deploys the second vLLM replica.
Watch the progress of the Pod autoscaling:
kubectl get hpa --watch -n ${NAMESPACE}The output is similar to the following:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sWait for 10 minutes and repeat the steps in the Verify that Google Cloud Managed Service for Prometheus ingests the metrics section. Google Cloud Managed Service for Prometheus ingests the metrics from both vLLM endpoints now.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete the deployed resources
To avoid incurring charges to your Google Cloud account for the resources that you created in this guide, run the following commands:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CONTROL_PLANE_LOCATION}
What's next
- Learn more about TPUs in GKE.
- Learn more about the available metrics to set up your Horizontal Pod Autoscaler.
- Explore the vLLM GitHub repository and documentation.