This tutorial explains how you can reduce costs by deploying a scheduled autoscaler on Google Kubernetes Engine (GKE). This kind of autoscaler scales clusters up or down according to a schedule based on time of day or day of the week. A scheduled autoscaler is useful if your traffic has a predictable ebb and flow—for example, if you are a regional retailer, or if your software is for employees whose working hours are limited to a specific part of the day.
The tutorial is for developers and operators who want to reliably scale up clusters before spikes arrive, and scale them down again to save money at night, on weekends, or any other time when fewer users are online. The article assumes you are familiar with Docker, Kubernetes, Kubernetes CronJobs, GKE, and Linux.
Introduction
Many applications experience uneven traffic patterns. For example, workers in an organization might engage with an application only during the day. As a result, data center servers for that application are idle at night.
Beyond other benefits, Google Cloud can help you save money by dynamically allocating infrastructure according to traffic load. In some cases, a simple autoscale configuration can manage the allocation challenge of uneven traffic. If that's your case, stick with it. However, in other cases, sharp changes in traffic patterns require more finely tuned autoscale configurations to avoid system instability during scale-ups and to avoid overprovisioning the cluster.
This tutorial focuses on scenarios where sharp changes in traffic patterns are well understood, and you want to give hints to the autoscaler that your infrastructure is about to experience spikes. This document shows how to scale GKE clusters up in the morning and down at night, but you can use a similar approach to increase and decrease capacity for any known events, such as peak scale events, ad campaigns, or weekend traffic.
Scaling down a cluster if you have committed use discounts
This tutorial explains how to reduce costs by scaling down your GKE clusters to the minimum during off-peak hours. However, if you've purchased a committed use discount, it's important to understand how these discounts work in conjunction with autoscaling.
Committed use contracts give you deeply discounted prices when you commit to paying for a set quantity of resources (vCPUs, memory, and others). However, to determine the quantity of resources to commit, you need to know in advance how many resources your workloads use over time. To help you to reduce your costs, the following diagram illustrates which resources you should and should not include in your planning.

As the diagram shows, allocation of resources under a committed use contract is flat. Resources covered by the contract must be in use most of the time to be worth the commitment you've made. Therefore, you should not include resources that are used during spikes in calculating your committed resources. For spiky resources, we recommend that you use GKE autoscaler options. These options include the scheduled autoscaler discussed in this paper or other managed options that are discussed in Best practices for running cost-optimized Kubernetes applications on GKE.
If you already have a committed use contract for a given amount of resources, you don't reduce your costs by scaling down your cluster below that minimum. In such scenarios, we recommend that you try to schedule some jobs to fill the gaps during periods of low computing demand.
Architecture
The following diagram shows the architecture for the infrastructure and scheduled autoscaler that you deploy in this tutorial. The scheduled autoscaler consists of a set of components that work together to manage scaling based on a schedule.

In this architecture, a set of Kubernetes CronJobs export known information about traffic patterns to a Cloud Monitoring custom metric. This data is then read by a Kubernetes Horizontal Pod Autoscaler (HPA) as input into when the HPA should scale your workload. Along with other load metrics, such as target CPU utilization, the HPA decides how to scale the replicas for a given deployment.
Objectives
- Create a GKE cluster.
- Deploy an example application that uses a Kubernetes HPA.
- Set up the components for the scheduled autoscaler and update your HPA to read from a scheduled custom metric.
- Set up an alert to trigger when your scheduled austoscaler is not working properly.
- Generate load to the application.
- Examine how the HPA responds to normal increases in traffic and to the scheduled custom metrics that you configure.
The code for this tutorial is in a GitHub repository.
Costs
In this document, you use the following billable components of Google Cloud:
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Prepare your environment
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
In Cloud Shell, configure your Google Cloud project ID, your email address, and your computing zone and region:
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fReplace the following:
YOUR_PROJECT_ID: the Google Cloud project name for the project you're using.YOUR_EMAIL_ADDRESS: an email address for being notified when the scheduled autoscaler is not working as properly.
You can choose a different region and zone for this tutorial if you want.
Clone the
kubernetes-engine-samplesGitHub repository:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerThe code in this example is structured into the following folders:
- Root: Contains the code that's used by the CronJobs to export custom metrics to Cloud Monitoring.
k8s/: Contains a deployment example that has a Kubernetes HPA.k8s/scheduled-autoscaler/: Contains the CronJobs that export a custom metric and an updated version of the HPA to read from a custom metric.k8s/load-generator/: Contains a Kubernetes Deployment that has an application to simulate hourly usage. A Deployment is a Kubernetes API object that lets you run multiple replicas of Pods that are distributed among the nodes in a cluster..monitoring/: Contains the Cloud Monitoring components that you configure in this tutorial.
Create the GKE cluster
In Cloud Shell, create a GKE cluster for running the scheduled autoscaler:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationThe output is similar to the following:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGThis is not a production configuration, but it's a configuration that's suitable for this tutorial. In this setup, you configure the cluster autoscaler with a minimum of 1 node and a maximum of 10 nodes. You also enable the
optimize-utilizationprofile to speed up the process of scaling down.
Deploy the example application
Deploy the example application without the scheduled autoscaler:
kubectl apply -f ./k8sOpen the
k8s/hpa-example.yamlfile.The following listing shows the content of the file.
Notice that the minimum number of replicas (
minReplicas) is set to 10. This configuration also sets the cluster to scale based on CPU utilization (thename: cpuandtype: Utilizationsettings).Wait for the application to become available:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPWhen the application is available, the output is as follows:
OK!Verify the settings:
kubectl get hpa php-apacheThe output is similar to the following:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hThe
REPLICAScolumn displays10, which matches the value of theminReplicasfield in thehpa-example.yamlfile.Check whether the number of nodes has increased to 4:
kubectl get nodesThe output is similar to the following:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504When you created the cluster, you set a minimum configuration using the
min-nodes=1flag. However, the application that you deployed at the beginning of this procedure is requesting more infrastructure becauseminReplicasin thehpa-example.yamlfile is set to 10.Setting
minReplicasto a value like 10 is a common strategy used by companies such as retailers, which expect a sudden increase in traffic in the first few hours of the business day. However, setting high values for HPAminReplicascan increase your costs because the cluster can't shrink, not even at night when application traffic is low.
Set up a scheduled autoscaler
In Cloud Shell, install the Custom Metrics - Cloud Monitoring adapter in your GKE cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsThis adapter enables Pod autoscaling based on Cloud Monitoring custom metrics.
Create a repository in Artifact Registry and give read permissions:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerBuild and push the custom metric exporter code:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterDeploy the CronJobs that export custom metrics and deploy the updated version of the HPA that reads from these custom metrics:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerOpen and examine the
k8s/scheduled-autoscaler/scheduled-autoscale-example.yamlfile.The following listing shows the content of the file.
This configuration specifies that the CronJobs should export the suggested Pod replicas count to a custom metric called
custom.googleapis.com/scheduled_autoscaler_examplebased on the time of day. To facilitate the monitoring section of this tutorial, the schedule field configuration defines hourly scale-ups and scale-downs. For production, you can customize this schedule to match your business needs.Open and examine the
k8s/scheduled-autoscaler/hpa-example.yamlfile.The following listing shows the contents of the file.
This configuration specifies that the HPA object should replace the HPA that was deployed earlier. Notice that the configuration reduces the value in
minReplicasto 1. This means that the workload can be scaled down to its minimum. The configuration also adds an external metric (type: External). This addition means that autoscaling is now triggered by two factors.In this multiple-metrics scenario, the HPA calculates a proposed replica count for each metric and then chooses the metric that returns the highest value. It's important to understand this—your scheduled autoscaler can propose that at a given moment the Pod count should be 1. But if the actual CPU utilization is higher than expected for one Pod, the HPA creates more replicas.
Check the number of nodes and HPA replicas again by running each of these commands again:
kubectl get nodes kubectl get hpa php-apacheThe output you see depends on what the scheduled autoscaler has done recently—in particular, the values of
minReplicasandnodeswill be different at different points in the scaling cycle.For example, at approximately minutes 51 to 60 of each hour (which represents a period of peak traffic), the HPA value for
minReplicaswill be 10 and the value ofnodeswill be 4.In contrast, for minutes 1 to 50 (which represents a period of lower traffic), the HPA
minReplicasvalue will be 1 and thenodesvalue will be either 1 or 2, depending on how many Pods have been allocated and removed. For the lower values (minutes 1 to 50), it might take up to 10 minutes for the cluster to finish scaling down.
Configure alerts for when the scheduled autoscaler is not working properly
In a production environment, you typically want to know when CronJobs are not
populating the custom metric. For this purpose, you can create an alert that
triggers when any custom.googleapis.com/scheduled_autoscaler_example stream is
absent for a five-minute period.
In Cloud Shell, create a notification channel:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}The output is similar to the following:
Created notification channel NOTIFICATION_CHANNEL_ID.This command creates a notification channel of type
emailto simplify the tutorial steps. In production environments, we recommend that you use a less asynchronous strategy by setting the notification channel tosmsorpagerduty.Set a variable that has the value that was displayed in the
NOTIFICATION_CHANNEL_IDplaceholder:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDDeploy the alert policy:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDThe
alert-policy.yamlfile contains the specification to send an alert if the metric is absent after five minutes.Go to the Cloud Monitoring Alerting page to view the alert policy.
Click Scheduled Autoscaler Policy and verify the details of the alert policy.
Generate load to the example application
In Cloud Shell, deploy the load generator:
kubectl apply -f ./k8s/load-generatorThe following listing shows the
load-generatorscript:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;This script runs in your cluster until you delete the
load-generatordeployment. It makes requests to yourphp-apacheservice every few milliseconds. Thesleepcommand simulates load-distribution changes during the day. By using a script that generates traffic in this way, you can understand what happens when you combine CPU utilization and custom metrics in your HPA configuration.
Visualize scaling in response to traffic or scheduled metrics
In this section, you review visualizations that show you the effects of scaling up and scaling down.
In Cloud Shell, create a new dashboard:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlGo to the Cloud Monitoring Dashboards page:
Click Scheduled Autoscaler Dashboard.
The dashboard displays three graphs. You need to wait at least 2 hours (ideally, 24 hours or more) to see the dynamics of scale-ups and scale-downs, and to see how different load distribution during the day affects autoscaling.
To give you an idea of what the graphs show, you can study the following graphs, which present a full-day view:
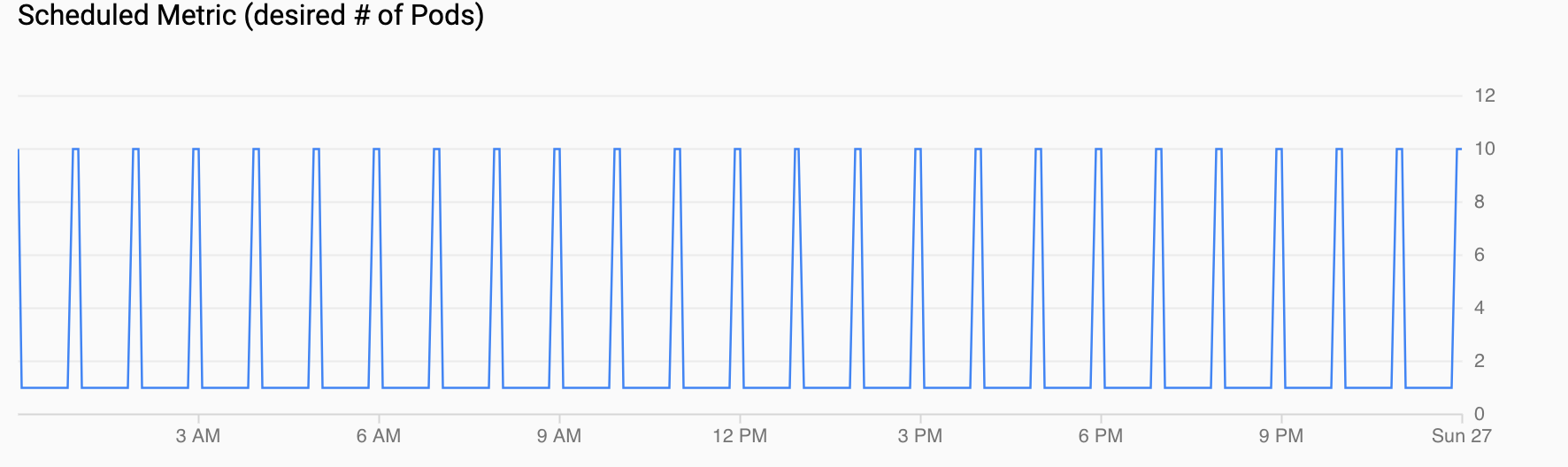
Scheduled Metric (desired # of Pods) shows a time series of the custom metric that's being exported to Cloud Monitoring through CronJobs that you configured in Setting up a scheduled autoscaler.
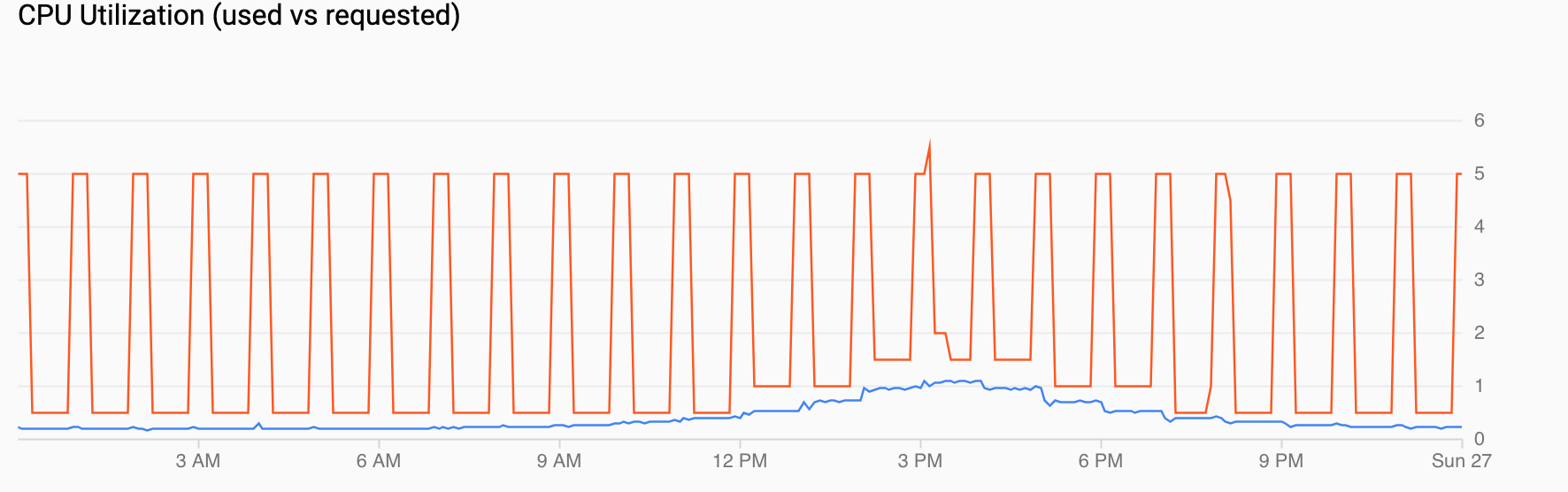
CPU Utilization (requested vs used) shows a time series of requested CPU (red) and actual CPU utilization (blue). When the load is low, the HPA honors the utilization decision by the scheduled autoscaler. However, when traffic increases, the HPA increases the number of Pods as needed, as you can see for the data points between 12 PM and 6 PM.
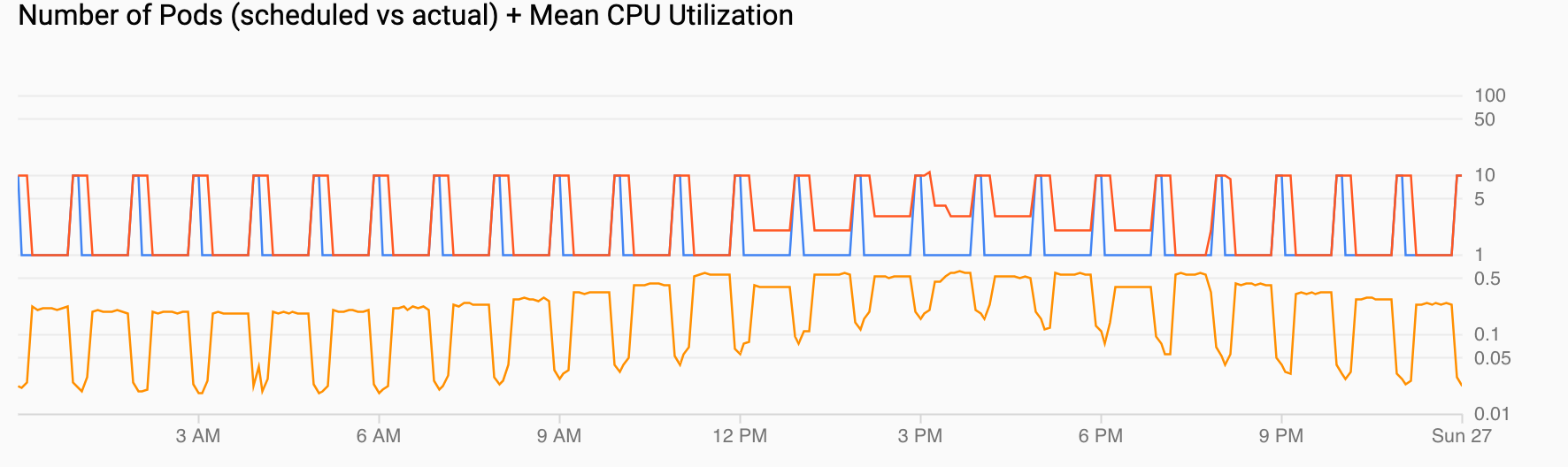
Number of Pods (scheduled vs actual) + Mean CPU Utilization shows a view similar to the previous ones. The Pod count (red) increases to 10 every hour as scheduled (blue). Pod count naturally increases and decreases over time in response to load (12 PM and 6 PM). Average CPU utilization (orange) remains below the target that you set (60%).
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete the project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- Learn more about GKE cost optimization in Best practices for running cost-optimized Kubernetes applications on GKE.
- Find design recommendations and best practices to optimize the cost of Google Cloud workloads in Google Cloud Well-Architected Framework: Cost optimization.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.