本文說明 Compute Engine 執行個體意外關閉及重新啟動的常見原因和防範方式。
系統事件或管理員活動可能會導致執行個體關閉和重新啟動。系統事件關閉和重新啟動是由 Google 系統或執行個體的作業系統所造成。管理員活動關閉和重新啟動是由使用者或服務帳戶產生的 API 呼叫所造成。系統會記錄所有關機和重新啟動狀況,但從執行個體內展開的重新啟動作業除外。
事前準備
-
如果尚未設定驗證,請先完成設定。
驗證可確認您的身分,以便存取 Google Cloud 服務和 API。如要從本機開發環境執行程式碼或範例,可以選取下列任一選項,向 Compute Engine 進行驗證:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
安裝 Google Cloud CLI。 安裝完成後,執行下列指令初始化 Google Cloud CLI:
gcloud init如果您使用外部識別資訊提供者 (IdP),請先 使用聯合身分登入 gcloud CLI。
- Set a default region and zone.
診斷執行個體關機和重新啟動的問題
如要診斷執行個體自行關閉或重新啟動的原因,您必須查詢執行個體的記錄檔。如要快速找出日後 VM 關機或重新啟動的原因,請建立含有記錄的資訊主頁。查詢記錄檔後,請查看
method和principalEmail欄位,找出是哪些事件和使用者/服務展開關閉/重新啟動作業。查詢 Cloud 稽核記錄
查詢 Cloud 稽核記錄,以便列出可能造成關機或重新啟動的系統事件和管理活動。
主控台
前往 Google Cloud 控制台的「Logs Explorer」頁面。
在「Query」(查詢) 欄位中,輸入下列查詢:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")將
VM_NAME替換為關閉或重新啟動的 VM 名稱。如果要搜尋的事件發生在超過 1 小時前,請按一下時鐘符號,然後輸入自訂時間範圍。
按一下 [Run query] (執行查詢)。查詢結果會顯示在「Query results」(查詢結果) 部分中。
按一下任何結果旁的展開箭頭,即可查看詳細資訊。
如要進一步瞭解與關機和重新啟動相關的
method和principalEmail欄位,以及如何防止這類情況發生,請參閱「查看 Cloud 稽核記錄」。
gcloud
使用
gcloud logging read指令查看 Cloud 稽核記錄:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'更改下列內容:
TIME:要查詢的時間長度。舉例來說,1h會查詢過去一小時內的記錄項目。如要瞭解日期和時間格式,請參閱 gcloud topic datetimes。VM_NAME:關機或重新啟動的 VM 名稱。
結果隨即顯示。
如要進一步瞭解與關機和重新啟動相關的
method和principalEmail欄位,以及如何防止這類情況發生,請參閱「查看 Cloud 稽核記錄」。
查看 Cloud 稽核記錄
查看 Cloud 稽核記錄的
method和principalEmail欄位,瞭解 VM 關閉或重新啟動的原因。請查看 Cloud 稽核記錄的
method欄位,並與下表列出的方法進行比較。方法 關機類型 說明 compute.instances.repair.recreateInstance系統事件 如果 VM 屬於代管執行個體群組 (MIG),且 VM 的狀態從
RUNNING變更,但 MIG 並未啟動狀態變更,MIG 就會重新建立 VM。不是由 MIG 引發的執行個體狀態變更包括:
compute.instances.hostError系統事件 主機錯誤 (
compute.instances.hostError) 表示託管運算執行個體的實體機器或資料中心基礎架構發生硬體或軟體問題,導致執行個體當機。如果主機發生硬體全面故障或其他硬體問題,可能導致執行個體即時遷移失敗。如果執行個體設為自動重新啟動 (預設設定),Compute Engine 通常會在偵測到錯誤後三分鐘內重新啟動執行個體。視問題而定,重新啟動最多可能需要 5.5 分鐘。有時,運算執行個體可能會在主機錯誤發出信號前停止回應。您可以設定主機錯誤復原逾時,縮短 Compute Engine 等待重新啟動或終止執行個體的時間。詳情請參閱「設定供應情形政策」。
實體硬體和軟體錯誤可能不時會發生,但並不常見。如要保護應用程式和服務,不受這類可能會造成干擾的系統事件影響,請參閱下列資源:
Google 還提供代管服務,例如 App Engine 和 App Engine 彈性環境。
compute.instances.automaticRestart系統事件 如果 VM 的
automaticRestart主機維護政策設為true,則會在hostError或terminateOnHostMaintenance事件後發生這個事件。在記錄中,hostError或terminateOnHostMaintenance記錄項目會出現在這項記錄之前。如要變更 VM 的主機維護政策,請參閱 更新執行個體的選項。
compute.instances.guestTerminate系統事件 VM 的作業系統啟動關機程序。 compute.instances.terminateOnHostMaintenance系統事件 如果將 VM 的
onHostMaintenance主機維護政策設為TERMINATE,當發生 Google 必須將 VM 移至其他主機的維護事件時,Compute Engine 會停止 VM。如要變更 VM 的
onHostMaintenance政策,請參閱「 更新執行個體的選項」。compute.instances.preempted系統事件 Compute Engine 先占了 Spot VM 或舊版先占 VM:
- 當 Compute Engine 先占 Spot VM 時,Compute Engine 會根據 Spot VM 的 終止動作停止或刪除該 VM。Spot VM 沒有執行時間上限。
- 當 Compute Engine 先占 VM 時,Compute Engine 會在 VM 最長執行 24 小時後停止 VM。如要避免這些限制,請改用 Spot VM。
Spot VM 和先占 VM 是額外的 Compute Engine 容量,因此 Compute Engine 可能隨時搶佔這些 VM,以供其他地方使用。如要減輕搶占作業的影響,請遵循最佳做法。或者,如果您需要使用可由使用者控制的執行階段的 VM,請改為建立標準 VM。
compute.instances.stop管理員活動 使用者或服務帳戶停止了 VM。
請繼續執行下一個步驟,找出停止 VM 的使用者或服務帳戶。如要瞭解如何重新啟動 VM,請參閱「 重新啟動已停止的執行個體」。
compute.instances.delete管理員活動或系統事件 使用者或服務帳戶刪除了 VM,或 VM 設定為自動刪除。
具體來說,
compute.instances.delete方法的記錄可能表示 VM 的下列任何要求:- 使用者或服務帳戶直接刪除 VM 的要求只會以使用者或服務帳戶的
compute.instances.delete方法表示。 系統會以
compute.instances.delete方法從system@google.com指出自動刪除 VM 的要求,但說明自動刪除原因的方法可能會或可能不會出現在 Cloud 稽核記錄中。舉例來說,如果 Spot VM 設定為在先占期間自動刪除,且遭到先占,您會看到
system@google.com中的compute.instances.delete方法,但可能也會看到compute.instances.preempted方法。在
compute.instances.delete方法前後不久發生的 VM 要求,可能會或可能不會出現在 Cloud 稽核記錄中。舉例來說,如果 VM 即將刪除,但主機維護作業在刪除前不久停止了 VM,您會看到
compute.instances.delete方法,但可能也會看到compute.instances.terminateOnHostMaintenance方法。
繼續下一個步驟,找出刪除 VM 的使用者或服務帳戶。如要瞭解如何建立新的 VM,請參閱「 建立及啟動 VM」。
compute.instances.insert管理員活動 使用者或服務帳戶建立了您的 VM。
請繼續下一個步驟,找出建立 VM 的使用者或服務帳戶。如要瞭解如何建立新的 VM,請參閱「 建立及啟動 VM」。
compute.instances.reset管理員活動 使用者或服務帳戶重設了 VM。
請繼續下一個步驟,找出停止 VM 的使用者或服務帳戶。
查看 Cloud 稽核記錄的
principalEmail欄位,找出是哪些使用者或服務展開關閉/重新啟動作業。下表列出會啟動關機或重新啟動程序的常見 Google 代管服務。電子郵件 說明 system@google.com系統事件導致關機或重新啟動。 project-number@cloudservices.gserviceaccount.com服務代理啟動了關機程序。
如要判斷服務從哪個專案啟動關機程序,請查看服務代理程式的
project-number。如要判斷是哪個 Google 服務提出要求,請檢查
protoPayload.requestMetadata.callerSuppliedUserAgent欄位。如果使用者觸發關機或重新啟動,他們的電子郵件地址會顯示在
principalEmail欄位中。例如:cloudysanfrancisco@gmail.com。管理員可以變更使用者帳戶的 Identity and Access Management 權限,禁止使用者變更專案 VM 的狀態。詳情請參閱授予、變更及撤銷資源的存取權。
監控 VM 生命週期事件
您可以建立 Cloud Monitoring 資訊主頁,監控 VM 生命週期事件 (包括關機、重新啟動和主機錯誤)。
這個資訊主頁可讓您以視覺化方式呈現系統事件和管理員活動,詳情請參閱本文的「查看稽核記錄」一節。
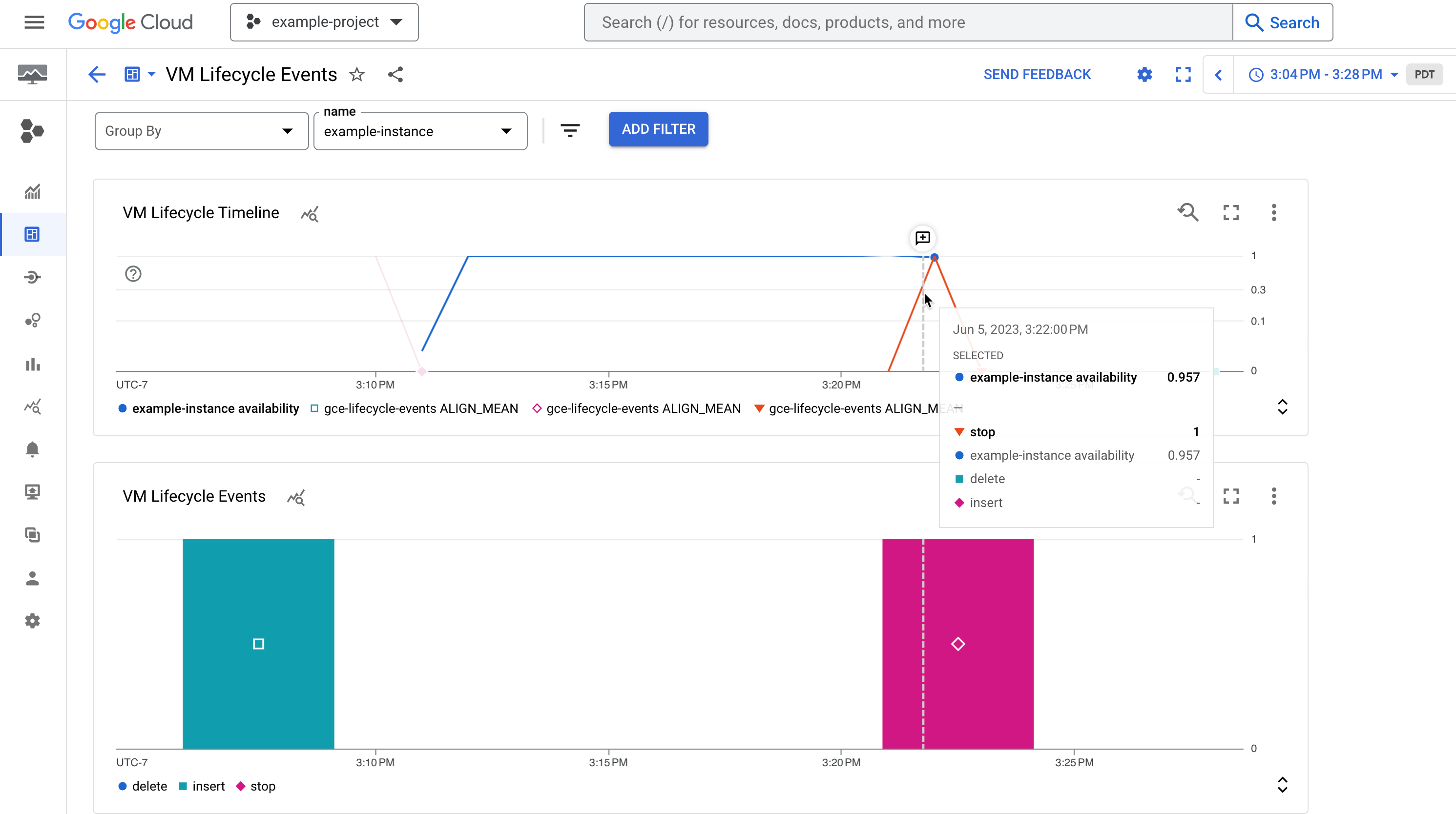 圖 1. 資訊主頁範例,顯示執行個體的可用性及其生命週期事件,例如已停止的執行個體。
圖 1. 資訊主頁範例,顯示執行個體的可用性及其生命週期事件,例如已停止的執行個體。建立記錄指標
如要擷取 VM 生命週期事件,請建立使用者定義的記錄指標。這項指標會使用稽核記錄,計算特定 VM 生命週期事件發生的次數。
如要取得建立指標所需的權限,請要求管理員授予您專案的「記錄檔寫入者」 (
roles/logging.logWriter) IAM 角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。如要建立使用者定義的記錄指標,請按照下列步驟操作:
前往 Google Cloud 控制台的「記錄指標」頁面。
按一下 [建立指標]。
在「指標類型」部分,執行下列操作:
- 選取「
Counter」。 - 保留「發布」的預設設定 (未選取)。
在「詳細資料」部分中,輸入下列資訊:
- 記錄指標名稱:
vm-lifecycle-events。您必須使用這個確切名稱,資訊主頁才能正常運作。 - 說明:選填,輸入這項指標的說明。
- 單位:
1
在「選取篩選條件」部分中,指定下列項目:
- 在「選取專案或記錄檔 bucket」選單中,選取「專案記錄」。
- 在「Build filter」(建構篩選器) 中輸入:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
在「標籤」部分中,按一下「新增標籤」。
指定下列屬性:
- 標籤名稱:
method - 標籤類型:
STRING - 欄位名稱:
protoPayload.methodName - 規則運算式:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- 標籤名稱:
然後按一下 [完成]。
點選「建立指標」。
使用資訊主頁
在執行個體發生系統事件或管理員活動前,資訊主頁不會顯示任何資料。如要測試資訊主頁是否正常運作,請執行系統管理員活動,例如
stop和start作業:- 對任何現有執行個體執行
stop和start作業,或建立新的 VM 以進行測試。
如要取得使用資訊主頁所需的權限,請要求管理員授予專案的「Monitoring 資訊主頁檢視者」 (
roles/monitoring.dashboardViewer) IAM 角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。在 Google Cloud 控制台中開啟「資訊主頁」。
在「資訊主頁清單」分頁中,開啟
GCE VM Lifecycle Events Monitoring資訊主頁。從「名稱」下拉式選單中選取 VM。
將時間序列縮小至相關時間範圍。
如要瞭解更多篩選資訊主頁的方式,請參閱「新增臨時篩選器」。
資訊主頁包含兩個圖表,分別顯示執行個體上發生的系統事件和管理員活動時間軸:
「VM Lifecycle Timeline」(虛擬機器生命週期時間軸) 圖表會顯示下列資訊:
compute.googleapis.com/instance/uptime指標,表示 VM 在特定時間點是否正在執行,其中 1 代表執行中,0 代表停止執行。請注意,這項指標反映的是使用者活動和系統事件造成的可用性,並非Compute Engine 服務等級協議的指標。vm-lifecycle-events記錄指標,用於計算生命週期動作的數量,例如在特定時間點對執行個體執行的stop或start
「事件」圖表會顯示相同的
vm-lifecycle-events記錄式指標,但會放大顯示,方便您閱讀。請注意,雖然 X 軸已對齊,但兩張圖表之間的顏色並未同步。
調查跨專案的大量 VM 關閉情況
如果共用虛擬私有雲主專案的計費功能未啟用或遭停用,Compute Engine 可能會關閉連至共用虛擬私有雲主專案的多個 VM。
如要判斷 VM 是否因大量關閉要求而關機,請確認是否具有透過
cloud-cluster-manager@prod.google.com展開的停止作業。啟動受影響的執行個體時,會傳回類似下列的錯誤:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.如要解決這個問題,請按照下列步驟操作:
使用
gcloud compute instances describe指令,找出 VM 使用的共用虛擬私有雲:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
輸出結果會與下列內容相似:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
在共用 VPC 的主專案中,確認計費功能是否已停用。
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"如適用,請啟用主專案的計費功能。
為避免這個問題再次發生,請參閱「確保專案與帳單帳戶之間的連結安全無虞」。
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2025-10-18 (世界標準時間)。
-