En este documento se describe cómo acceder a las métricas de las máquinas virtuales (VMs) y consultarlas. También se describe cómo revisar las métricas de las VMs para obtener más información sobre ellas o solucionar problemas específicos de una VM.
Monitorizar las instancias de máquina virtual (VM) es fundamental para mantener los recursos de VM. Compute Engine ofrece una vista general de las métricas de tus VMs mediante la pestaña Observabilidad de la Google Cloud consola. Esta pestaña proporciona un panel de control predefinido que usa datos de telemetría para que puedas monitorizar tus máquinas virtuales y tomar decisiones fundamentadas sobre tus recursos de Compute Engine. También puedes personalizar el panel de control predefinido para ver solo las métricas específicas que quieras.
Todas las máquinas virtuales tienen datos de uso de procesos básicos disponibles cuando se crean. Sin embargo, si instalas el agente de operaciones, obtendrás información más detallada sobre el comportamiento de las VMs.
Para obtener más información sobre cómo crear una política de alertas de monitorización o usar el explorador de métricas, o para consultar información general sobre cómo funcionan la monitorización y las métricas en Google Cloud, consulta los documentos de Cloud Monitoring.
Antes de empezar
Opcional: Instala el Agente de operaciones para recoger datos más detallados de tus instancias de Compute Engine.
Para comprobar en qué instancias de VM está instalado el Agente de operaciones, haz lo siguiente:
En la Google Cloud consola, ve a Paneles de control de Monitoring.
Selecciona Instancias de VM en la lista del panel de control.
Haz clic en Lista para ver las VMs en forma de lista.
Se muestran todas las VMs de tu proyecto. La columna Agente muestra el estado de la instalación del agente de operaciones. Puedes instalar o actualizar el agente desde esta página.
Opcional: Para actualizar el panel de control Predefinido para que muestre eventos, como los que indican una actualización de un grupo de instancias gestionado, haz clic en event_available Seleccionar eventos y, a continuación, completa el cuadro de diálogo.
Para obtener más información sobre los eventos, consulte Tipos de eventos.
Acceder a métricas de observabilidad de máquinas virtuales
Accede a la información de una o varias VMs mediante la pestaña Observabilidad de la consola Google Cloud . De forma predeterminada, un panel predefinido muestra las métricas de la máquina virtual. Si solo quiere ver las métricas que le interesan, puede crear un panel de control personalizado.
Ver métricas de observabilidad de una sola máquina virtual
Cuando creas una máquina virtual, tienes a tu disposición métricas básicas de la máquina virtual, como la utilización de la CPU y el tráfico de red. Las métricas de utilización de memoria y procesos solo están disponibles si se instala el Agente de operaciones, que es el agente principal para recoger telemetría de tus instancias de Compute Engine.
Para ver las métricas de una sola máquina virtual, haz lo siguiente:
En la consola de Google Cloud , ve a la página Instancias de VM.
Selecciona una VM para abrir la página Detalles.
Haga clic en la pestaña Observabilidad para ver información sobre la VM.
Opcional: Restablece el periodo predeterminado de una hora al periodo que quieras monitorizar.
Opcional: Para actualizar el panel de control Predefinido para que muestre eventos, como los que indican una actualización de un grupo de instancias gestionado, haz clic en event_available Seleccionar eventos y, a continuación, completa el cuadro de diálogo.
Para obtener más información sobre los eventos, consulte Tipos de eventos.
La información de la figura 1 muestra los detalles de la VM sin el agente de operaciones instalado en la VM. Observa que los gráficos Memoria y Uso del espacio en disco no tienen datos.
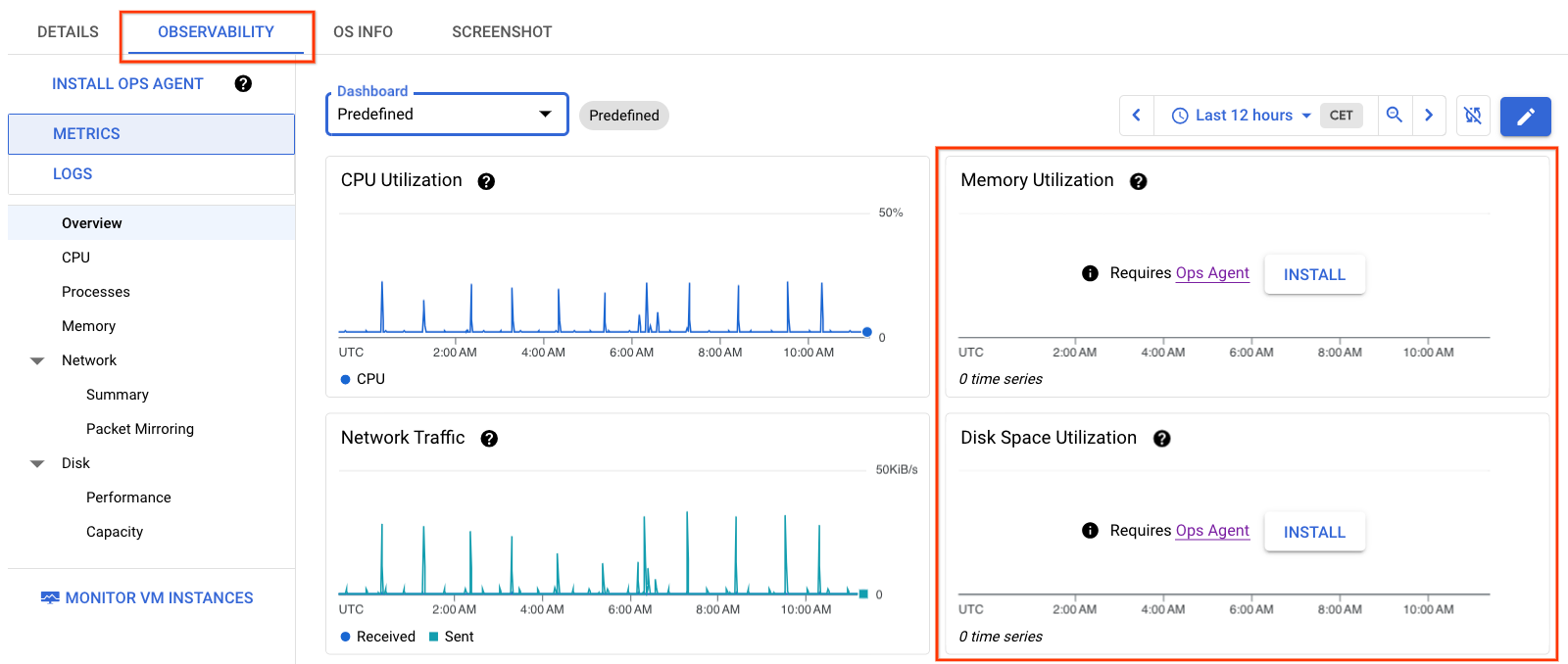
Ver métricas de observabilidad de varias máquinas virtuales
La observabilidad a nivel de flota muestra las métricas de las cinco VMs con la mayor utilización de procesos. Las cinco primeras máquinas virtuales que se muestran varían según la métrica. Es posible que no veas las mismas cinco máquinas virtuales en cada proceso. Aunque hay más datos disponibles a nivel de flota sin instalar el agente de operaciones que la cantidad de datos disponibles para una sola VM, instalar el agente proporciona más datos para futuras tareas de solución de problemas.
Para ver las métricas de varias máquinas virtuales, haz lo siguiente:
En la consola de Google Cloud , ve a la página Instancias de VM.
Haz clic en la pestaña Observabilidad.
Opcional: Restablece el periodo predeterminado de una hora al periodo que quieras monitorizar.
Filtra los resultados con una o varias de las siguientes opciones:
- ID
- Nombre
- Tipo de máquina
- Zona
- Región
- Grupo de instancias
- Etiquetas
- Estado
La información de la figura 2 muestra un ejemplo de la pestaña Observabilidad cuando hay varias VMs en un proyecto con el agente de Ops instalado. Ten en cuenta que hay más métricas disponibles sobre estas VMs.
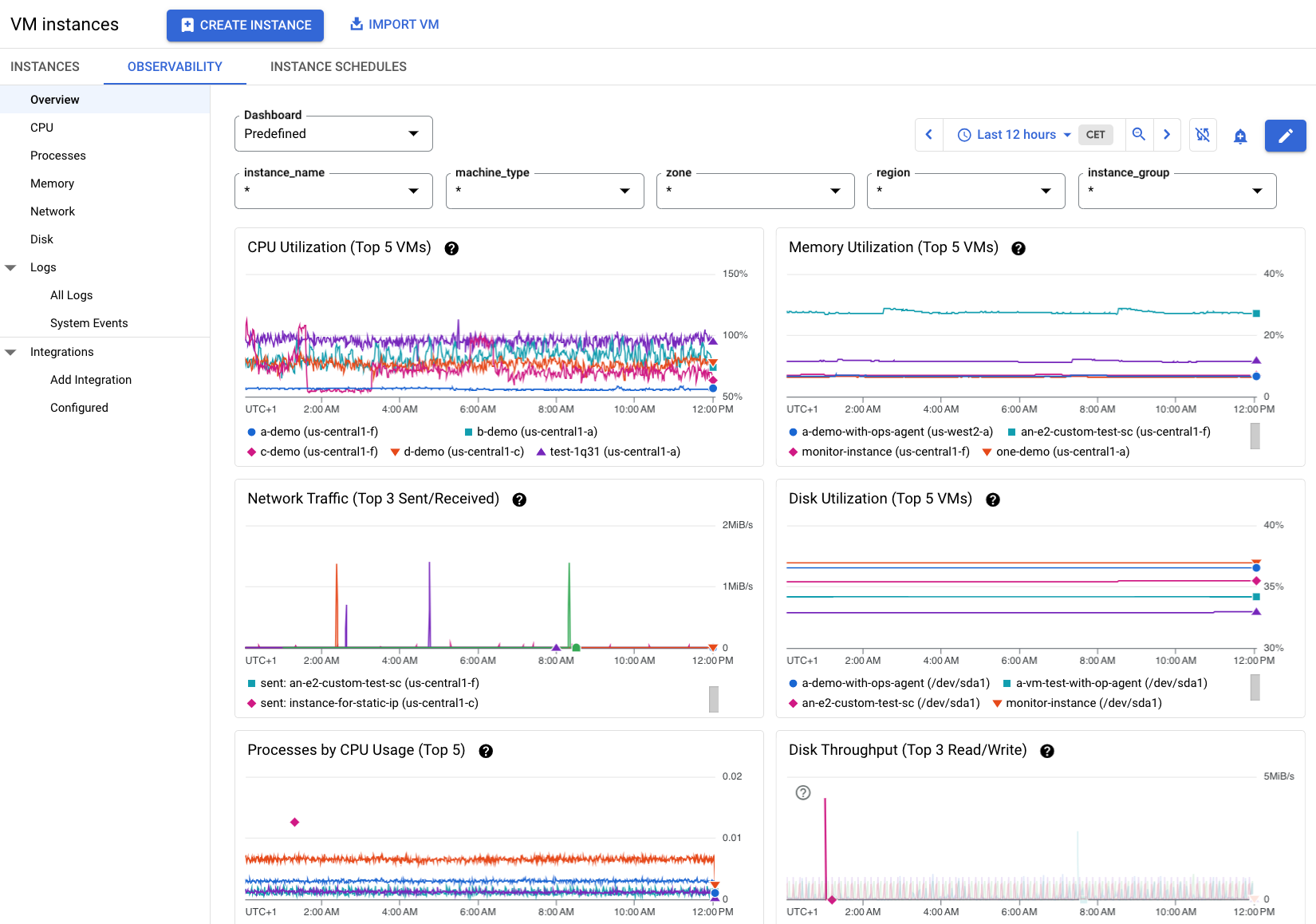
Ver métricas detalladas de una VM
Cada métrica de proceso de la MV se representa mediante una línea en un gráfico. En el siguiente ejemplo, la máquina virtual uptime-demo tiene instalado el agente de operaciones. Los datos de uso de memoria están disponibles para solucionar problemas. Si una VM no aparece en la tarjeta, filtra por el nombre de la VM para encontrarla.
Para obtener información sobre esta u otra de las cinco VMs principales desde la pestaña Observabilidad, haz lo siguiente:
- Mantén el puntero sobre la línea del gráfico de cualquier máquina virtual. Aparecerá una tarjeta con una lista de las cinco máquinas virtuales principales que usan el proceso, cada una con una métrica.
- Para obtener más información sobre el comportamiento de la máquina virtual, haga clic en la línea del gráfico de la máquina virtual o en el nombre de una máquina virtual específica de la lista.
La VM uptime-demo que se muestra en la tarjeta de la figura 3 revela algunas métricas que podrían requerir una revisión.
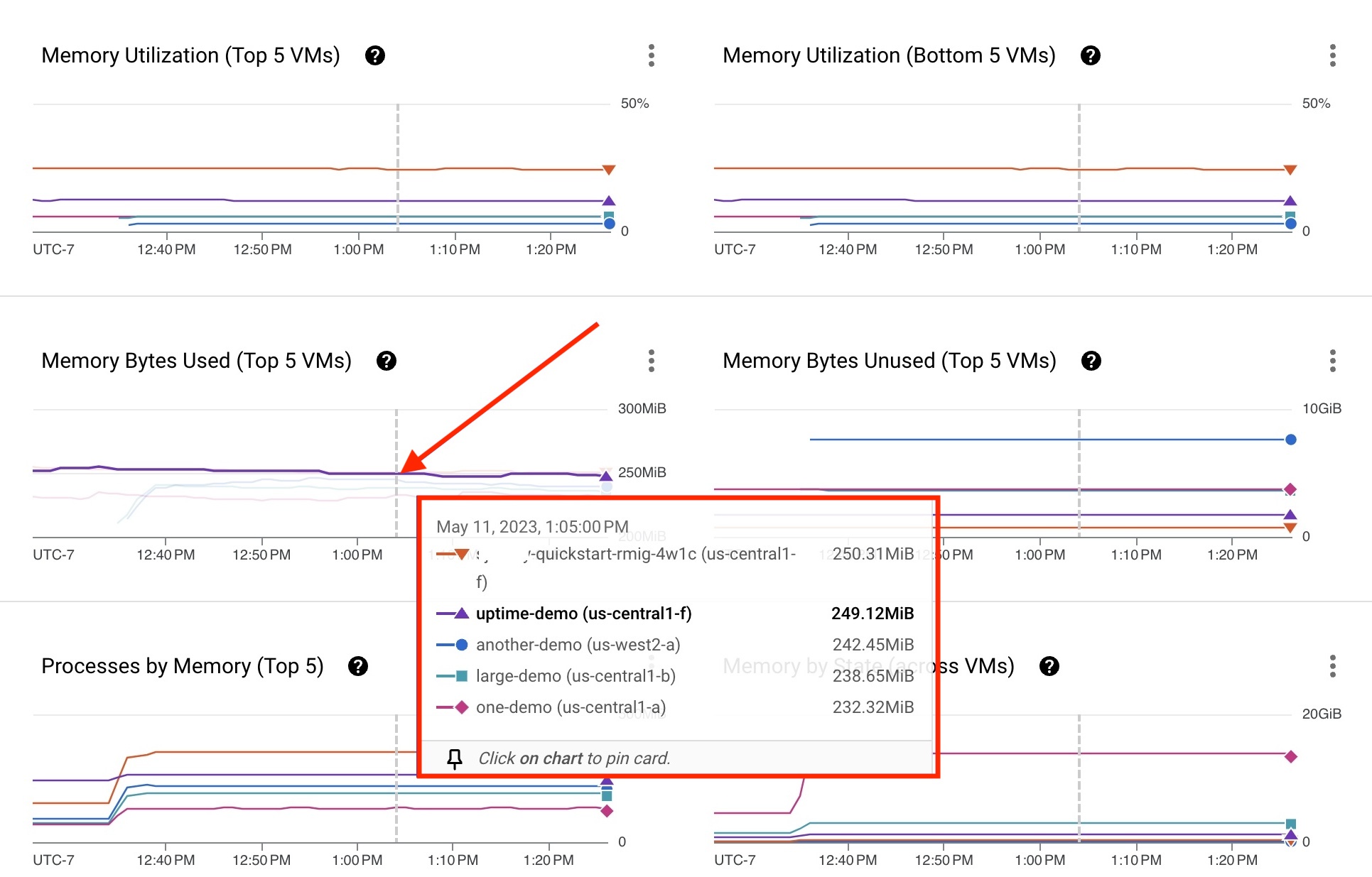
Haz clic en la VM uptime-demo para abrir la página Detalles de la VM, que se muestra en la figura 4 y proporciona la siguiente información:
- El estado del agente de operaciones.
- Las opciones contextuales para crear alertas, consultar eventos o crear comprobaciones de disponibilidad.
- Opción para ver los detalles de las configuraciones, las métricas y los registros de la máquina virtual.
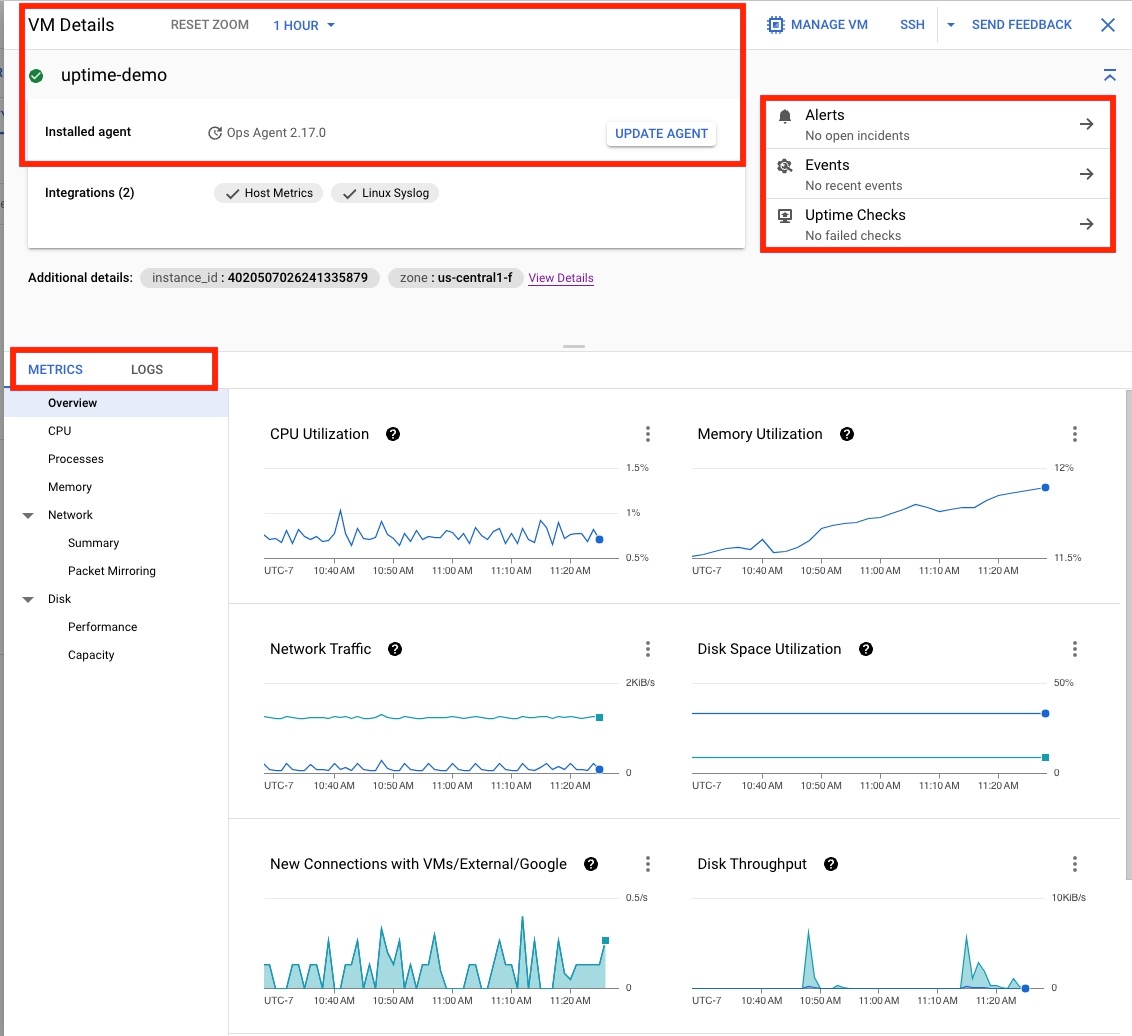
Crear un panel de control personalizado para ver métricas específicas
De forma predeterminada, la pestaña Observabilidad de Compute Engine proporciona un panel de control predefinido que muestra métricas básicas de las VMs. Para ver solo las métricas específicas que quieras, puedes modificar el panel de control predefinido y guardarlo como panel de control personalizado. Puedes personalizar aún más el panel como consideres oportuno.
Para crear un panel de control personalizado, siga estos pasos:
En la consola de Google Cloud , ve a la página Instancias de VM.
Ve a la pestaña Observabilidad de la siguiente manera:
- En el caso de una sola VM: en la página Instancias de VM, haz clic en el nombre de la VM para abrir su página Detalles y, a continuación, haz clic en la pestaña Observabilidad de esa VM.
- Para varias VMs: en la página Instancias de VM, haz clic en la pestaña Observabilidad.
Si el menú desplegable Panel de control está habilitado, habrá paneles de control personalizados disponibles. Para modificar una vista personalizada, selecciona una en el menú desplegable y, a continuación, en la barra de herramientas del panel de control, haz clic en .
De lo contrario, para personalizar el panel predefinido, en la barra de herramientas del panel, haz clic en .
Compute Engine crea una copia del panel de control predefinido y, a continuación, la abre en modo de edición.
En el editor, puedes añadir, modificar, eliminar, cambiar de posición o cambiar el tamaño de las visualizaciones del panel de control. Las visualizaciones se denominan en conjunto widgets. Para obtener más información sobre los distintos tipos de widgets, consulta el artículo Descripción general de los paneles de control.
Para añadir un widget, en la barra de herramientas del panel de control, haz clic en Añadir widget y completa la configuración.
Por ejemplo, para ver los registros con los datos de sus métricas, haga clic en Añadir widget, seleccione Registros y, a continuación, haga clic en Aplicar.
Para modificar un widget, coloca el puntero sobre él para activar la barra de herramientas, haz clic en Editar widget y, a continuación, usa el cuadro de diálogo Configurar widget. Para aplicar los cambios al panel de control, haz clic en Aplicar en la barra de herramientas. Para descartar los cambios, haz clic en Cancelar.
Para eliminar un widget, coloca el puntero sobre él para activar la barra de herramientas, haz clic en Más opciones de gráfico y, a continuación, selecciona Eliminar.
Para cambiar la posición de un widget, usa el puntero para arrastrarlo por su encabezado hasta una nueva ubicación.
Para cambiar el tamaño de un widget, usa el puntero para cambiar la posición de la esquina derecha del widget.
Cuando hayas terminado de modificar el panel de control, haz clic en Guardar.
En el cuadro de diálogo que confirma los cambios, haga clic en Ver panel de control personalizado para ir a la vista personalizada.
Para volver a la vista predefinida, seleccione Predefinida en el menú desplegable Panel de control.
Revisar las métricas de recursos
Para obtener más información sobre cada métrica de recursos, haz clic en cada proceso del menú de la pestaña Observabilidad:
- Consulta el uso de CPU, Procesos, Memoria, el tráfico de Red y el uso de Disco.
- Para ver los datos de registro, busca Registros para identificar y ver los eventos del sistema.
- Añade integraciones de terceros y comprueba si hay integraciones configuradas.
En el resto de esta sección se describen ejemplos de cómo pueden afectar algunos procesos a tus cargas de trabajo. Esta información presupone que el Agente de operaciones está instalado en tus VMs.
Uso de CPU
Un ejemplo de uso extremo de la CPU podría ser cuando un servidor está sometido a una carga inesperadamente pesada, como cuando un sitio web experimenta un aumento repentino del tráfico o cuando se está llevando a cabo una tarea de procesamiento de datos a gran escala. En estas situaciones, la CPU puede funcionar al 100% de su capacidad durante un periodo prolongado, lo que puede provocar que el servidor se ralentice o deje de responder.
En este ejemplo, el problema es la saturación. Si la utilización de la CPU es del 100%, puede que sea adecuada para tus cargas de trabajo, pero te recomendamos que examines otras métricas para saber si requiere alguna intervención. En este caso, te recomendamos que crees una política de alertas para recibir una notificación cuando la utilización de la CPU de una máquina virtual aumente de forma repentina.
Si tienes los permisos adecuados, puedes conectarte a tus VMs mediante SSH para investigar el problema. Sin embargo, si el agente de Ops está instalado, puede ver más datos históricos para ayudarle a solucionar problemas.
Utilización de procesos
Un ejemplo de comportamiento extremo de un proceso podría ser cuando un proceso consume una cantidad excesiva de recursos, como CPU, memoria o E/S de disco, hasta el punto de que provoca una degradación del rendimiento o incluso un fallo de la máquina virtual.
Por ejemplo, si un proceso que se ejecuta en una VM tiene una fuga de memoria, puede que empiece a consumir cantidades de memoria cada vez mayores con el tiempo, lo que acabará provocando que la VM se quede sin memoria y falle. Del mismo modo, si un proceso usa el disco de forma intensiva, puede provocar que la E/S del disco de la VM se sature, lo que conlleva tiempos de respuesta lentos para otros procesos.
Uso de memoria
Las bases de datos requieren una gran cantidad de memoria para realizar operaciones como la indexación, la ordenación y la combinación de tablas.
Un ejemplo de uso elevado de memoria en una VM es cuando ejecutas un servidor de bases de datos, como Cloud SQL para MySQL o Cloud SQL para PostgreSQL, con un conjunto de datos de gran tamaño. Si la memoria disponible de tu VM es demasiado pequeña, volver a cargar un conjunto de datos en la memoria puede provocar que la base de datos funcione lentamente o falle.
Rendimiento de la red
Los problemas de rendimiento de la red se deben a diferentes factores: congestión, limitaciones de ancho de banda, problemas de hardware o software y latencia. Para diagnosticar el problema, monitoriza las métricas de rendimiento de tu red, soluciona los problemas de hardware y software, y analiza los patrones de tráfico de la red para identificar y resolver la causa principal del problema.
Uso de disco
Una máquina virtual tiene una utilización de disco alta cuando se lee o se escribe una gran cantidad de datos en el disco virtual, lo que provoca un retraso en el acceso al disco y puede afectar al rendimiento de la máquina virtual.
Monitorizar métricas de utilización del disco, como las operaciones de E/S del disco por segundo (IOPS), la longitud de la cola del disco y el tiempo de respuesta medio del disco, puede ayudar a identificar y diagnosticar problemas de alta utilización del disco en una VM.
Comprobar registros y eventos del sistema
La página Todos los registros proporciona datos de registro sobre tus recursos. Ordena por gravedad para identificar los problemas e inspeccionar la carga útil.
Los registros de auditoría registran los eventos administrativos que se producen en tus recursos. Los registros pueden indicarte qué ha ocurrido para activar el evento. Se registran y se conservan varios registros en la misma fila. Por ejemplo, si tienes 20 registros idénticos, la información se almacena en una fila en lugar de en 20 filas independientes.
Puedes considerar Eventos del sistema como un término general para los eventos que se producen a un nivel superior, pero que pueden afectar a tus recursos de Compute Engine. Un evento del sistema se produce cuando se activa un error que no está relacionado con un evento planificado. Los eventos del sistema se registran a nivel de flota.
Usar integraciones de terceros
Monitoring ofrece integraciones con aplicaciones de terceros. Estas integraciones te permiten recoger telemetría de aplicaciones como Apache Web Server, Cloud SQL para MySQL, Memorystore para Redis y otras para las implementaciones que se ejecutan en Compute Engine y GKE. Cuando usas Compute Engine, el agente de operaciones recoge la telemetría de terceros.