En este documento se describen los tipos de eventos que se pueden mostrar como anotaciones en los gráficos. Un evento es una actividad, como un reinicio o un fallo, que afecta al funcionamiento de un sistema. Mostrar eventos puede ayudarte a correlacionar datos de diferentes fuentes cuando estés solucionando un problema.
En cada evento, se proporcionan enlaces a referencias o documentación para solucionar problemas, así como información sobre cómo consultar el evento. Por ejemplo, cuando se identifican eventos analizando sus registros, se proporciona una consulta adecuada para usarla con el Explorador de registros o con una política de alertas basada en registros.
Para añadir anotaciones a los gráficos, configura el panel de control o la pestaña en la que se muestra el gráfico. Por ejemplo, puede configurar la mayoría de los paneles de control que aparecen en la página Paneles de control de la consola Google Cloud para que muestren eventos. Del mismo modo, puedes configurar algunas pestañas Observabilidad específicas de un servicio, como las de Compute Engine y Google Kubernetes Engine, para que muestren eventos. Para obtener información sobre la configuración, consulta el artículo Mostrar eventos en un panel de control.
En la siguiente captura de pantalla se muestra un gráfico con varios eventos identificados mediante el análisis de entradas de registro y un evento de estado del servicio:
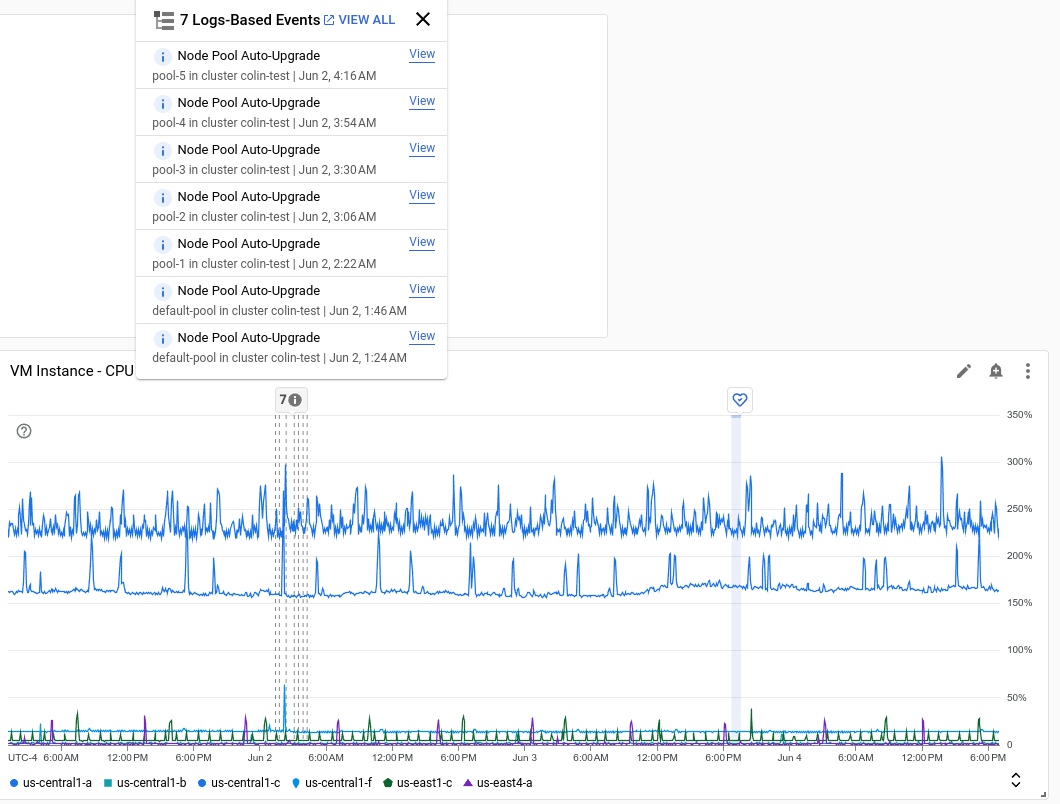
Cada anotación puede incluir varios eventos. En la captura de pantalla anterior, se muestra un evento de una implementación de GKE.
Tipos de eventos de alerta
En esta sección se describen los tipos de eventos de alerta que se pueden mostrar en un panel de control.
Alerta abierta
Las alertas de eventos abiertos te ayudan a relacionar los datos representados en gráficos con el momento en el que se han abierto los incidentes. El evento de alerta abierta se muestra cuando se cumplen las siguientes condiciones:
- El incidente correspondiente se abrió durante el periodo especificado en el panel de control.
- El incidente correspondiente no se ha cerrado.
No se muestran las anotaciones de los incidentes que se han abierto fuera del intervalo de tiempo especificado en el panel de control. Del mismo modo, no se muestra un evento de alerta abierta cuando el incidente correspondiente se ha abierto y cerrado en el intervalo de tiempo especificado en el panel de control.
La descripción emergente de un evento de alerta abierta incluye lo siguiente:
- Nombre de la política de alertas.
- Información de resumen, cuando esté disponible. Por ejemplo, esta información puede incluir el umbral y el valor medido.
- La duración del incidente, así como la fecha y la hora en las que se abrió.
- Etiquetas de métricas y recursos. Es posible que la descripción emergente no muestre todas las etiquetas.
- Un botón Ver, que abre la página Detalles del incidente.
Tipos de eventos de Google Kubernetes Engine
En esta sección se describen los tipos de eventos de Google Kubernetes Engine que se pueden mostrar en un panel de control.
Carga de trabajo de GKE actualizada o parcheada
Este tipo de evento le ayuda a solucionar problemas de implementación de cargas de trabajo de GKE o cambios de StatefulSet, ya que estos eventos pueden estar relacionados con regresiones del rendimiento u otros problemas de rendimiento. Este tipo de evento se muestra cuando se crea, actualiza o elimina una carga de trabajo.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
Para obtener más información, consulta la descripción general de la implementación de cargas de trabajo y Ver métricas de observabilidad.
Fallo de un pod de GKE
Este tipo de evento te ayuda a identificar y solucionar problemas de fallos de pods de GKE. Los fallos de los pods pueden deberse a que se ha agotado la memoria o a un error de la aplicación. Este tipo de evento se muestra cuando se produce alguna de las siguientes situaciones:
- El estado del pod es
CrashLoopBackoff - El pod finaliza con un código de salida distinto de cero.
- El pod finaliza con una condición de falta de memoria.
- Se expulsa el pod.
- Falla la comprobación de preparación o de actividad.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Para obtener información sobre cómo solucionar problemas, consulta Solucionar problemas: CrashLoopBackOff.
No se puede programar un pod de GKE
Este tipo de evento le ayuda a identificar y solucionar problemas cuando no se pueden programar pods en un nodo. Este tipo de evento se muestra cuando falla la programación de pods por alguno de los siguientes motivos:
- CPU de nodo insuficiente.
- Memoria de nodo insuficiente.
- No hay nodos para tolerancias ni taint.
- Nodos con el límite máximo de pods.
- El grupo de nodos ha alcanzado el tamaño máximo.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Para obtener información sobre cómo solucionar problemas, consulta Solucionar problemas: no se puede programar el pod.
No se ha podido crear un contenedor de GKE
Este tipo de evento le ayuda a identificar y solucionar los errores al crear un contenedor de GKE. Puede que no se pueda crear el contenedor por motivos como errores al montar volúmenes o al extraer imágenes.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Para obtener información sobre cómo solucionar problemas relacionados con las extracciones de imágenes, consulta el artículo Solucionar problemas de extracción de imágenes.
Escalar verticalmente la herramienta de adaptación dinámica de pods
Este evento te permite ver los cambios de escala del autoescalador de pods horizontal, que aumenta o reduce el número de pods en ejecución de una carga de trabajo. Para obtener más información, consulta Autoescalado horizontal de pods.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Escalar y reducir verticalmente la herramienta de adaptación dinámica de clústeres
Este evento te permite ver cuándo la herramienta de adaptación dinámica de clústeres aumenta o reduce el número de nodos de un grupo de nodos de tu clúster. Para obtener más información, consulte Acerca del escalado automático de clústeres y Consultar los eventos de la herramienta de adaptación dinámica de clústeres.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Creación y eliminación de clústeres
Este evento registra las acciones de creación y eliminación de clústeres de GKE. Para obtener más información, consulta los artículos Crear un clúster de Autopilot, Crear un clúster zonal y Eliminar un clúster.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Actualización de clúster
Este evento registra las actualizaciones de clústeres de GKE. Las actualizaciones incluyen actualizaciones automáticas de la versión del plano de control, así como actualizaciones manuales y cambios en la configuración del clúster. Para obtener más información, consulta los artículos Actualizar manualmente un clúster o un grupo de nodos y Actualizaciones de clústeres estándar.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Actualización de grupos de nodos
Este evento registra las actualizaciones del grupo de nodos de GKE. Las actualizaciones incluyen las de la versión del grupo de nodos automáticas, así como las manuales, los cambios de configuración y los cambios de tamaño. Para obtener más información, consulta los artículos Actualizar manualmente un clúster o un grupo de nodos y Actualizaciones de clústeres estándar.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Tipos de eventos de Cloud Run
En esta sección se describen los tipos de eventos de Cloud Run que se pueden mostrar en un panel de control.
Despliegue de Cloud Run
Este tipo de evento te ayuda a identificar y solucionar problemas de fallos de implementación de Cloud Run. El despliegue puede fallar por motivos como la eliminación de una cuenta de servicio, permisos incorrectos, un error al importar un contenedor o un error al iniciar un contenedor.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Para obtener información sobre cómo solucionar problemas, consulta Solucionar problemas de Cloud Run.
Tipos de eventos de Cloud SQL
En esta sección se describen los tipos de eventos de Cloud SQL que se pueden mostrar en un panel de control.
Conmutación por error de Cloud SQL
Este tipo de evento te ayuda a identificar cuándo se producen conmutaciones por error manuales o automáticas. Se produce una conmutación por error cuando falla una instancia o una zona y la instancia de espera se convierte en la nueva instancia principal. Durante una conmutación por error, Cloud SQL cambia automáticamente a la instancia de espera para que proporcione los datos.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Para obtener más información, consulta Acerca de la alta disponibilidad.
Inicio o detención de Cloud SQL
Este tipo de evento te ayuda a identificar si una instancia de Cloud SQL se ha iniciado, detenido o reiniciado manualmente. Cuando se detiene una instancia, también se detienen todas las conexiones, los archivos abiertos y las operaciones en ejecución.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Para obtener más información, consulta los artículos Acerca de la alta disponibilidad y Iniciar, detener y reiniciar instancias.
Almacenamiento de Cloud SQL
Este tipo de evento le ayuda a identificar eventos relacionados con el almacenamiento de Cloud SQL, como cuando el almacenamiento de la base de datos está lleno y cuando se cierra una base de datos por haber alcanzado la capacidad de almacenamiento. Las bases de datos que alcancen su capacidad de almacenamiento y no tengan habilitado el almacenamiento automático podrían cerrarse para evitar que se dañen los datos.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Tipos de eventos de Compute Engine
En esta sección se describen los tipos de eventos de Compute Engine que se pueden mostrar en un panel de control.
Cancelaciones de máquinas virtuales
Este tipo de evento le ayuda a identificar las finalizaciones de máquinas virtuales (VM), incluidos los reinicios y las detenciones activados manualmente, las finalizaciones del SO invitado, las finalizaciones por mantenimiento y los errores del host.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Para obtener más información, consulta los artículos Detener e iniciar una VM y Solucionar problemas de apagados y reinicios de VMs.
Fallo al iniciar la instancia de VM
Este evento registra los fallos de inicio de instancias de VM de Compute Engine. El evento muestra errores de inicio debido a falta de stock, agotamiento del espacio de IP, superación de la cuota o errores de integridad de la VM blindada.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Error del SO invitado de la instancia de VM
Este evento monitoriza errores específicos del SO invitado de instancias de VM de Compute Engine registrados en los registros de la consola en serie. Los errores registrados son los siguientes: disco lleno, error al montar el sistema de archivos y errores de arranque que activan el modo de emergencia de Linux.
Para que estos eventos sean visibles, debe habilitar el registro de salida del puerto serie en Cloud Logging configurando serial-port-logging-enable=true en la VM o en los metadatos del proyecto. Para obtener más información, consulta Habilitar e inhabilitar el registro de salida del puerto serie.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Actualización de grupo de instancias gestionado
Este tipo de evento te ayuda a identificar cuándo se ha actualizado tu grupo de instancias gestionado (MIG). Por ejemplo, si se han añadido o quitado máquinas virtuales, o si se ha actualizado el límite de tamaño. Para obtener más información, consulta Aplicar automáticamente las actualizaciones de configuración de VM en un MIG.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Para obtener más información, consulta Trabajar con instancias gestionadas y Solucionar problemas de grupos de instancias gestionadas.
Herramienta de ajuste automático de escala de grupos de instancias gestionados
Este evento registra las decisiones de escalado que toma la herramienta de escalado automático de un MIG. Estas decisiones pueden incluir cambios en el tamaño recomendado de un MIG o en el estado del propio escalador automático. Para obtener más información, consulta Grupos de instancias con autoescalado.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Tipos de eventos de Personalized Service Health
En esta sección se describen los tipos de Personalized Service Health que se pueden mostrar en un panel de control.
Google Cloud incident
Cuando solucionas problemas, puede que quieras diferenciar entre los errores causados por un servicio que te pertenece y los causados por unGoogle Cloud servicio que usas. Cuando habilitas las anotaciones de Personalized Service Health en un panel de control, puedes ver las interrupciones o los eventos de estado de los servicios de Google Cloud . Para ver una lista de los servicios integrados con Estado del servicio, consulta Productos de Google compatibles.
A diferencia de otros tipos de eventos, Google Cloud los incidentes no se identifican analizando las entradas de registro. Si quieres recibir una notificación cuando se produzcan estos eventos, crea una política de alertas. Puedes seleccionar una política de alertas preconfigurada usando las opciones de la página Panel de estado del servicio. Para obtener más información, consulta Guía de inicio rápido: configura una alerta.
La monitorización identifica los Google Cloud incidentes enviando una solicitud a la API Service Health y, a continuación, filtrando la respuesta para mostrar solo los incidentes que sean relevantes para los datos que estás viendo. La solicitud tiene la siguiente configuración:
La enumeración
Relevancetiene el valorRELATED,IMPACTEDoPARTIALLY_RELATED. Esta restricción asegura que en el panel de control solo se muestren los eventos de los servicios que utilice tu proyecto. Google Cloud Google CloudLa enumeración
DetailedStateno tiene el valorFALSE_POSITIVE.
Las anotaciones de Service Health se muestran con una hora de inicio y una duración. La duración se muestra cambiando el color de fondo del gráfico. La descripción emergente de un Google Cloud incidente identifica lo siguiente:
- El servicio Google Cloud .
- Si el incidente está abierto o resuelto.
- Fecha y hora de inicio del evento.
- Chips que muestran el número de productos y ubicaciones afectados. Para ver los productos o las ubicaciones afectados, coloca el puntero sobre el chip correspondiente.
- Un botón Ver que, al seleccionarlo, abre la página de detalles del incidente.
Para obtener información sobre cómo enviar una solicitud a la API Service Health, consulta Comprobar si hay interrupciones con Service Health.
Para obtener información sobre cómo solucionar problemas, consulta el artículo Solucionar problemas habituales en el estado del servicio.
Tipos de eventos de comprobación de disponibilidad del servicio
En esta sección se describen los tipos de eventos de comprobación del tiempo de actividad que se pueden mostrar en un panel de control.
Fallo de comprobación de disponibilidad del servicio
Este tipo de evento le ayuda a identificar los fallos de comprobación del tiempo de actividad de las regiones configuradas.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Para obtener información sobre cómo solucionar problemas, consulta Solucionar problemas de monitores sintéticos y comprobaciones de disponibilidad.
Tipos de eventos del agente de SAP
En esta sección se describen los tipos de eventos de Agent for SAP que se pueden mostrar en un panel de control.
Disponibilidad de SAP
Este tipo de evento le ayuda a identificar eventos relacionados con la disponibilidad de Agent for SAP. Estos eventos se activan cuando cambia la disponibilidad de SAP HANA, SAP NetWeaver o Pacemaker Cluster.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
Este tipo de evento le ayuda a identificar eventos relacionados con Agent for SAP Backint. Cualquier copia de seguridad o recuperación de Backint escribe un evento que detalla si se ha realizado correctamente o no, junto con las estadísticas de transferencia. Las copias de seguridad y las recuperaciones de registros solo se muestran cuando se produce un fallo, mientras que las copias de seguridad y las recuperaciones de datos se muestran tanto si se realizan correctamente como si no.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
Operaciones de SAP
Este tipo de evento le ayuda a identificar eventos relacionados con las operaciones de Agent for SAP. Estos eventos se activan cuando cambia el estado de la replicación de SAP HANA.
Si quieres crear una política de alertas basada en registros para este tipo de evento, usa la siguiente consulta:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
Siguientes pasos
Para saber cómo mostrar eventos en sus paneles de control, consulte Mostrar eventos en un panel de control.