Anda dapat melacak metrik seperti penggunaan GPU dan memori GPU dari instance virtual machine (VM) menggunakan Agen Operasional, yang merupakan solusi pengumpulan telemetri yang direkomendasikan Google untuk Compute Engine. Dengan menggunakan Agen Operasional, Anda dapat mengelola VM GPU sebagai berikut:
- Visualisasikan performa fleet GPU NVIDIA Anda dengan dasbor yang telah dikonfigurasi sebelumnya.
- Optimalkan biaya dengan mengidentifikasi GPU yang kurang dimanfaatkan dan menggabungkan workload.
- Rencanakan penskalaan dengan melihat tren untuk memutuskan kapan harus memperluas kapasitas GPU atau mengupgrade GPU yang ada.
- Gunakan metrik pembuatan profil NVIDIA Data Center GPU Manager (DCGM) untuk mengidentifikasi bottleneck dan masalah performa dalam GPU Anda.
- Siapkan grup instance terkelola (MIG) untuk menskalakan resource secara otomatis.
- Dapatkan pemberitahuan tentang metrik dari GPU NVIDIA Anda.
Dokumen ini membahas prosedur untuk memantau GPU pada VM Linux menggunakan
Agen Operasional. Selain itu, skrip pelaporan tersedia di GitHub yang juga dapat disiapkan untuk memantau penggunaan GPU di VM Linux. Lihat skrip pemantauan compute-gpu-monitoring.
Skrip ini tidak dikelola secara aktif.
Untuk memantau GPU di VM Windows, lihat Memantau performa GPU (Windows).
Ringkasan
Agen Operasional, versi 2.38.0 atau yang lebih baru, dapat otomatis melacak pemanfaatan GPU dan tingkat penggunaan memori GPU pada VM Linux yang telah menginstal agen. Metrik ini, yang diperoleh dari NVIDIA Management Library (NVML), dilacak per GPU dan per proses untuk setiap proses yang menggunakan GPU. Untuk melihat metrik yang dipantau oleh Agen Operasional, lihat Metrik agen: gpu.
Anda juga dapat menyiapkan integrasi NVIDIA Data Center GPU Manager (DCGM) dengan Agen Operasional. Integrasi ini memungkinkan Agen Operasional melacak metrik menggunakan penghitung hardware di GPU. DCGM menyediakan akses ke metrik tingkat perangkat GPU. Hal ini termasuk penggunaan blok Streaming Multiprocessor (SM), jumlah pengguna SM, penggunaan pipa SM, rasio traffic PCIe, dan rasio traffic NVLink. Untuk melihat metrik yang dipantau oleh Agen Operasional, lihat Metrik aplikasi pihak ketiga: NVIDIA Data Center GPU Manager (DCGM).
Untuk meninjau metrik GPU dengan menggunakan Agen Operasional, selesaikan langkah-langkah berikut:
- Di setiap VM, pastikan Anda telah memenuhi persyaratan.
- Di setiap VM, instal Agen Operasional.
- Opsional: Di setiap VM, siapkan integrasi NVIDIA Data Center GPU Manager (DCGM).
- Tinjau metrik di Cloud Monitoring.
Batasan
- Agen Operasional tidak melacak pemakaian GPU pada VM yang menggunakan Container-Optimized OS.
Persyaratan
Di setiap VM, pastikan Anda memenuhi persyaratan berikut:
- Setiap VM harus memiliki GPU yang terpasang.
- Setiap VM harus memiliki driver GPU yang terinstal.
- Sistem operasi dan versi Linux untuk setiap VM Anda harus mendukung Agen Operasional. Lihat daftar sistem operasi Linux yang mendukung Agen Operasional.
- Pastikan Anda memiliki akses
sudoke setiap VM.
Menginstal Agen Operasional
Untuk menginstal Agen Operasional, selesaikan langkah-langkah berikut:
Jika sebelumnya Anda menggunakan skrip pemantauan
compute-gpu-monitoringuntuk melacak penggunaan GPU, nonaktifkan layanan ini sebelum menginstal Agen Operasional. Untuk menonaktifkan skrip pemantauan, jalankan perintah berikut:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Instal Agen Operasional versi terbaru. Untuk petunjuk mendetail, lihat Menginstal Agen Operasional.
Setelah menginstal Agen operasional, jika Anda perlu menginstal atau mengupgrade driver GPU menggunakan skrip penginstalan yang disediakan oleh Compute Engine, tinjau bagian batasan.
Meninjau metrik NVML di Compute Engine
Anda dapat meninjau metrik NVML yang dikumpulkan Agen Operasional dari tab Observability untuk instance VM Linux Compute Engine.
Untuk melihat metrik satu VM, lakukan hal berikut:
Di konsol Google Cloud , buka halaman VM instances.
Pilih VM untuk membuka halaman Detail.
Klik tab Observability untuk menampilkan informasi tentang VM.
Pilih filter cepat GPU.
Untuk melihat metrik beberapa VM, lakukan hal berikut:
Di konsol Google Cloud , buka halaman VM instances.
Klik tab Observability.
Pilih filter cepat GPU.
Opsional: Menyiapkan integrasi NVIDIA Data Center GPU Manager (DCGM)
Agen Operasional juga menyediakan integrasi untuk NVIDIA Data Center GPU Manager (DCGM) untuk mengumpulkan metrik GPU lanjutan utama seperti penggunaan blok Streaming Multiprocessor (SM), jumlah pengguna SM, penggunaan pipa SM, rasio traffic PCIe, dan rasio traffic NVLink.
Metrik GPU lanjutan ini tidak dikumpulkan dari model NVIDIA P100 dan P4.
Untuk petunjuk terperinci cara menyiapkan dan menggunakan integrasi ini pada setiap VM, lihat NVIDIA Data Center GPU Manager (DCGM).
Meninjau metrik DCGM di Cloud Monitoring
Di konsol Google Cloud , buka halaman Monitoring > Dashboards.
Pilih tab Sample Library.
Di kolom Filter , ketik NVIDIA. Dasbor NVIDIA GPU Monitoring Overview (GCE dan GKE) akan ditampilkan.
Jika Anda telah menyiapkan integrasi NVIDIA Data Center GPU Manager (DCGM), dasbor NVIDIA GPU Monitoring Advanced DCGM Metrics (Khusus GCE) juga akan ditampilkan.
Untuk dasbor yang diperlukan, klik Preview. Halaman Sample dashboard preview akan ditampilkan.
Dari halaman Sample dashboard preview, klik Import sample dashboard.
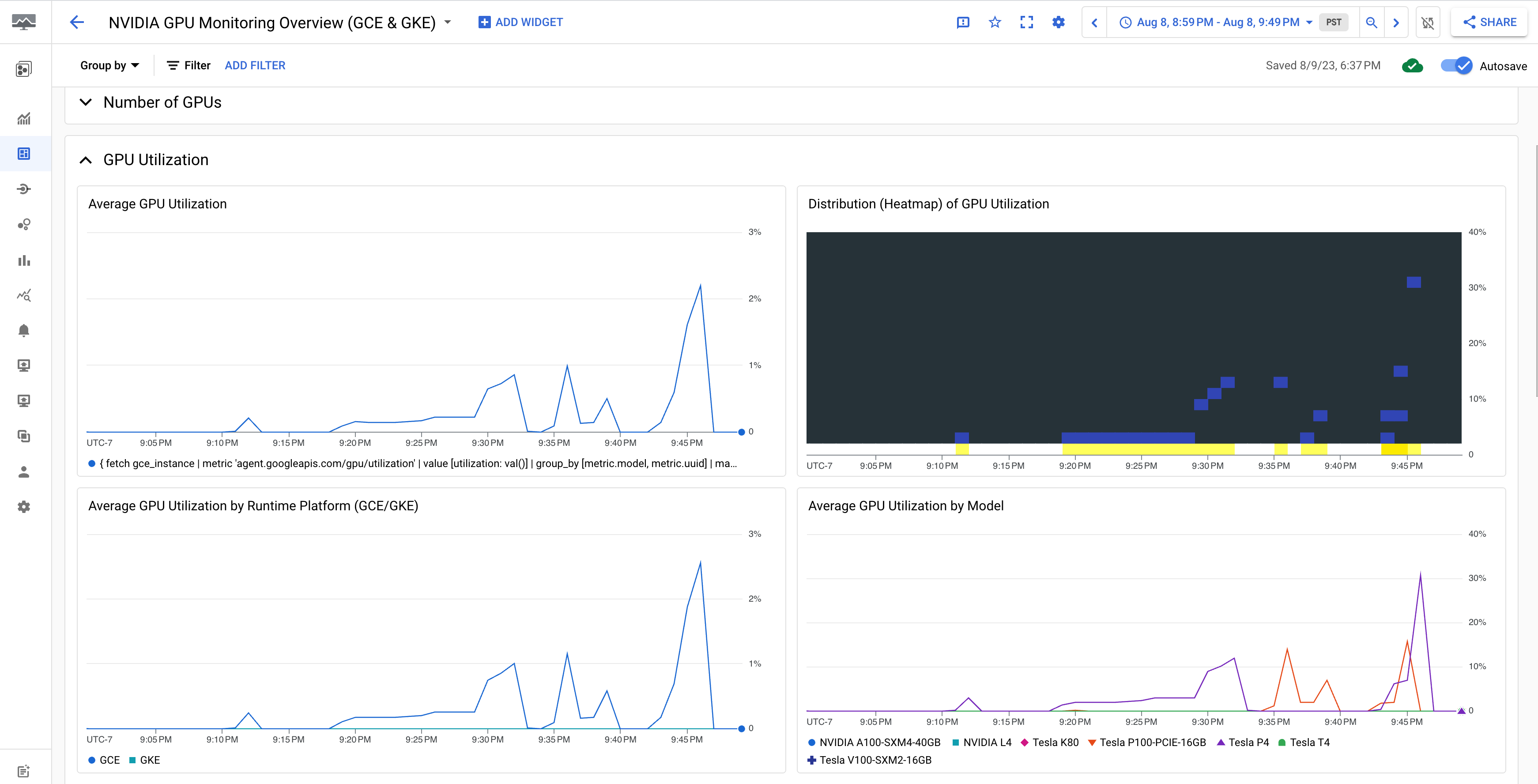
Dasbor NVIDIA GPU Monitoring Overview (GCE dan GKE) menampilkan metrik GPU seperti penggunaan GPU, rasio traffic NIC, dan penggunaan memori GPU.
Tampilan pemakaian GPU Anda mirip dengan output berikut:
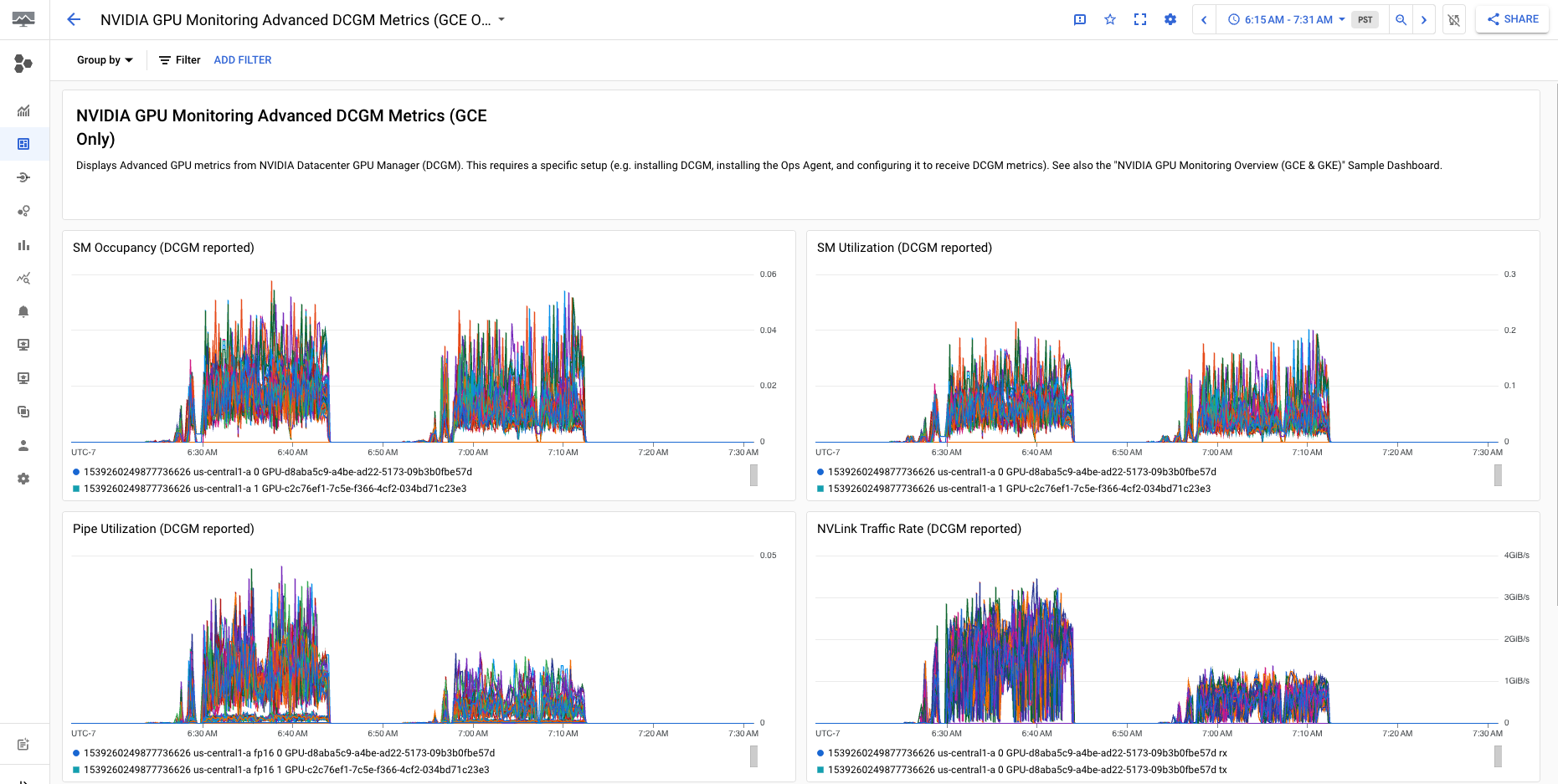
Dasbor NVIDIA GPU Monitoring Advanced DCGM Metrics (Khusus GCE) menampilkan metrik lanjutan utama seperti penggunaan SM, jumlah pengguna SM, penggunaan pipa SM, rasio traffic PCIe, dan rasio traffic NVLink.
Tampilan Metrik DCGM Lanjutan Anda mirip dengan output berikut:
Apa langkah selanjutnya?
- Untuk menangani pemeliharaan host GPU, lihat Menangani peristiwa pemeliharaan host GPU.
- Untuk meningkatkan performa jaringan, lihat Menggunakan bandwidth jaringan yang lebih tinggi.