Beim Autoscaling werden Ihrer verwalteten Instanzgruppe (MIG) automatisch VMs hinzugefügt (hochskaliert) oder VMs werden daraus entfernt (herunterskaliert). In diesem Dokument wird erläutert, wie Autoscaling bestimmt, wann Ihre MIGs skaliert werden.
Wie das Autoscaling die empfohlene Größe berechnet und die Zielgröße beeinflusst
Wenn Sie Autoscaling für eine MIG konfigurieren, überwacht das Autoscaling die Gruppe fortlaufend und legt für die empfohlene Größe der Gruppe die Anzahl der VM-Instanzen fest, die zur Verarbeitung der Spitzenlast im Stabilisierungszeitraum erforderlich ist.
Die empfohlene Größe wird durch die Mindest- und Höchstzahl von Instanzen begrenzt, die Sie in der Autoscaling-Richtlinie festlegen.
Wenn Ihre Autoscaling-Richtlinie Skalierungssteuerelemente enthält, wird die empfohlene Größe zusätzlich durch die Steuerelemente für das Herunterskalieren begrenzt.
Wenn Sie das vorausschauende Autoscaling aktivieren, verwendet das Autoscaling historische CPU-Auslastungsmuster, um die zukünftige Arbeitslast vorherzusagen. Es legt dann die empfohlene Größe der Gruppe anhand der Vorhersage fest.
Die Reaktion der verwalteten Instanzgruppe auf die empfohlene Größe des Autoscalings hängt davon ab, wie Sie den mode des Autoscalings konfigurieren:
ON: Die MIG legt die Zielgröße auf die empfohlene Größe fest und Compute Engine skaliert die MIG dann automatisch horizontal, um die Zielgröße zu erreichen.ONLY_SCALE_OUT: Die Zielgröße der MIG kann nur als Reaktion auf eine erhöhte empfohlene Größe gesteigert werden.OFF: Die empfohlene Größe hat keine Auswirkungen auf die Zielgröße. Die empfohlene Größe wird aber dennoch berechnet.
Wenn die Autoscaling-Konfiguration gelöscht wird, wird keine empfohlene Größe berechnet.
Differenz zwischen Soll- und Ist-Auslastungsmesswerten
Wenn Sie eine Autoscaling-Richtlinie mit messwertenbasierten Signalen verwenden, stellen Sie eventuell fest, dass die tatsächliche Auslastung von kleineren Instanzgruppen stark von der Zielauslastung abweicht. Dies liegt daran, dass das Autoscaling beim Interpretieren der Auslastungsdaten und bei der Entscheidung, wie viele Instanzen hinzugefügt oder entfernt werden, durch Auf- oder Abrunden immer konservativ handelt. So wird verhindert, dass das Autoscaling eine unzureichende Anzahl von Ressourcen hinzufügt oder zu viele Ressourcen entfernt.
Wenn Sie zum Beispiel ein Auslastungsziel von 0,7 festlegen und Ihre Anwendung das Auslastungsziel überschreitet, bestimmt das Autoscaling möglicherweise, dass das Hinzufügen von 1,5 VM-Instanzen die Auslastung auf etwa 0,7 verringern würde. Da es nicht möglich ist, 1,5 VM-Instanzen hinzuzufügen, rundet das Autoscaling auf und fügt 2 Instanzen hinzu. Dies könnte die durchschnittliche CPU-Auslastung auf einen Wert unter 0,7 verringern, sorgt jedoch dafür, dass Ihre Anwendung immer genügend Ressourcen hat.
Wenn das Autoscaling entsprechend bestimmt, dass das Entfernen von 1,5 VM-Instanzen Ihre Auslastung auf etwa 0,7 erhöht, wird nur 1 Instanz entfernt.
Bei größeren Gruppen mit mehreren VM-Instanzen wird die Auslastung auf eine größere Anzahl von Instanzen aufgeteilt und das Hinzufügen oder Entfernen von VM-Instanzen verursacht nur eine kleinere Differenz zwischen tatsächlicher Auslastung und Zielauslastung.
Wenn Sie ein zeitbasiertes Autoscaling mit einem anderen Autoscaling-Signal verwenden, benötigt ein aktiver Zeitplan möglicherweise mehr VMs als Ihre Auslastung. In diesen Fällen ist Ihre tatsächliche Auslastung geringer als die Zielauslastung, da der Autoscaling-Zeitplan die empfohlene Größe der Instanzgruppe bestimmt.
Verzögerungen beim Hochskalieren
Wenn Sie das Autoscaling konfigurieren, geben Sie eine Initialisierungsphase an, der die Zeitspanne widerspiegelt, die Ihre VMs für die Initialisierung benötigen. Das Autoscaling empfiehlt nur dann eine Skalierung, wenn die durchschnittliche Auslastung von Instanzen, die nicht initialisiert werden, höher als die Zielauslastung ist.
Wenn Sie einen Wert für die Initialisierungsphase festlegen, der deutlich länger ist als die Initialisierungszeit einer Instanz, ignoriert Ihr Autoscaling möglicherweise legitime Nutzungsdaten und unterschätzt möglicherweise die erforderliche Gruppengröße.
Verzögerungen beim Herunterskalieren
Zum Herunterskalieren wird beim Autoscaling die empfohlene Zielgröße der Gruppe basierend auf der Spitzenlast in den letzten 10 Minuten oder der von Ihnen festgelegten Initialisierungsphase berechnet, je nachdem, welcher Zeitraum länger ist. Dieser Zeitraum wird als Stabilisierungszeitraum bezeichnet.
Wenn Sie die Nutzung während des Stabilisierungszeitraums beobachten, kann der Autoscaler:
- Sicherzustellen, dass die gesammelten Informationen aus der Instanzgruppe stabil sind.
- Zu verhindern, dass das Autoscaling kontinuierlich Instanzen zu schnell hinzufügt oder entfernt.
- Instanzen sicher zu entfernen, indem ermittelt wird, ob die kleinere Gruppengröße für die Spitzenlast der Stabilisierungsphase ausreicht.
- Wenn die Initialisierung Ihrer Anwendung auf einer neuen VM länger als 10 Minuten dauert, verwendet die Gruppe die Initialisierungsphase als Stabilisierungszeitraum. So wird sichergestellt, dass bei der Entscheidung des Autoscalings zum Löschen einer VM berücksichtigt wird, wie lange es dauert, bis die Bereitstellungskapazität wiederhergestellt ist.
Der Stabilisierungszeitraum kann beim Herunterskalieren als Verzögerung wahrgenommen werden. Tatsächlich handelt es sich jedoch um ein integriertes Feature des Autoscalings. Der Stabilisierungszeitraum sorgt auch dafür, dass beim Hinzufügen einer neuen Instanz zur verwalteten Instanzgruppe die Initialisierungsphase der Instanz abgeschlossen wird oder sie mindestens 10 Minuten lang ausgeführt wird, bevor sie gelöscht werden kann.
Initialisierungsphasen für neue Instanzen werden bei der Entscheidung, ob eine Gruppe herunterskaliert wird, ignoriert.
Verbindungsausgleich verursacht Verzögerungen
Wenn die Gruppe Teil eines Back-End-Dienstes ist, für den der Verbindungsausgleich aktiviert ist, kann es nach Ablauf des Verbindungsausgleichs bis zu 60 Sekunden dauern, bis die VM-Instanz entfernt oder gelöscht wird.
Steuerelemente für die Herunterskalierung
Wenn Sie die Autoscaling-Steuerelemente für die Herunterskalierung konfigurieren, steuern Sie damit, wie schnell herunterskaliert wird. Das Autoscaling skaliert nie schneller herunter als die konfigurierte Rate:

- Wenn die Last sinkt, behält das Autoscaling die Größe der Gruppe auf einem Niveau bei, das erforderlich ist, um die beobachtete Spitzenlast zu bewältigen (Stabilisierungszeitraum). Dies funktioniert mit und ohne Steuerelemente für die Herunterskalierung.
- Autoscaling ohne Steuerelemente für die Herunterskalierung hält nur so viele Instanzen bereit, wie für die kürzlich beobachtete Last erforderlich sind. Nach dem Stabilisierungszeitraum entfernt das Autoscaling alle nicht benötigten Instanzen in einem Schritt. Wenn die Last plötzlich abfällt, kann dies zu einer drastischen Reduzierung der Instanzgruppengröße führen.
- Autoscaling mit Steuerelementen für die Herunterskalierung schränkt ein, wie viele VM-Instanzen in einem konfigurierten Zeitraum entfernt werden können (hier 10 VMs in 20 Minuten). Dadurch wird die Instanzreduzierungsrate verlangsamt.
- Mit einem neuen Lastanstieg fügt das Autoscaling neue Instanzen hinzu, um die Last zu verarbeiten. Aufgrund der langen Initialisierungszeit sind die neuen VMs jedoch nicht bereit, die Last zu verarbeiten. Mit den Steuerelementen für die Herunterskalierung wurde die vorherige Kapazität beibehalten, sodass vorhandene VMs den Spitzenwert bewältigen konnten.
Konfigurieren Sie die maximal zulässige Reduzierung des Autoscalings innerhalb eines Nachlaufzeitfensters, um die Skalierungsrate zu steuern. Insbesondere:
- Maximal zulässige Reduzierung (
maxScaledInReplicas: Anzahl oder % der VM-Instanzen) Die Anzahl der Instanzen, die Ihre Arbeitslast innerhalb des angegebenen Nachlaufzeitfensters maximal verlieren darf (aus der Spitzengröße der Gruppe). Verwenden Sie diesen Parameter, um einzuschränken, in welchem Umfang Ihre Gruppe skaliert werden kann. Auf diese Weise kann weiterhin ein wahrscheinlicher Lastanstieg bedient werden, bis mehr Instanzen bereitstehen. Je niedriger die maximal zulässige Reduzierung ist, desto kleiner ist die Skalierungsrate. - Nachlaufzeitfenster (
timeWindowSec: Sekunden). Zeit, in der ein Lastanstieg wahrscheinlich einem vorübergehenden Rückgang folgt und in der Ihre Gruppengröße nicht über die maximal zulässige Reduzierung hinaus herunterskaliert werden soll. Verwenden Sie diesen Parameter, um das Zeitfenster zu definieren, in dem das Autoscaling nach der Spitzengröße sucht, die für die bisherige Last ausreicht. Autoscaling verkleinert die Größe nicht unter die maximal zulässige Reduzierung, die von der im Nachlaufzeitfenster beobachteten Spitzengröße abgezogen wird. Bei einem längeren Nachlaufzeitfenster berücksichtigt das Autoscaling mehr bisherige Spitzenlasten, wodurch die Herunterskalierung konservativer und stabiler wird.
Wenn Sie Steuerelemente für die Herunterskalierung festlegen, beschränkt das Autoscaling Herunterskalierungsvorgänge auf die maximal zulässige Reduzierung basierend auf der Spitzengröße im Nachlaufzeitfenster. Das Autoscaling führt die folgenden Schritte aus:
- Überwacht kontinuierlich die bisherige Spitzengröße im Nachlaufzeitfenster.
- Verwendet die maximal zulässige Reduzierung, um die beschränkte Größe fürs Herunterskalieren zu berechnen (Spitzengröße:
maxScaledInReplicas) - Legt die empfohlene Größe der Gruppe auf die beschränkte Größe fürs Herunterskalieren fest. Wenn Autoscaling beispielsweise die Größe einer Instanzgruppe auf 20 VMs ändern würde, die Größenbeschränkungen fürs Herunterskalieren jedoch nur eine Skalierung auf 40 VMs zulassen, wird die empfohlene Größe auf 40 VMs festgelegt.
Mit Steuerelementen für die Herunterskalierung überwacht das Autoscaling kontinuierlich die Spitzengröße einer Instanzgruppe innerhalb des konfigurierten Nachlaufzeitfensters, um die Größe zu ermitteln, die für die bisherige Auslastung ausreicht. Autoscaling skaliert nicht über die maximal zulässige Reduzierung hinaus (anhand der beobachteten Spitzengröße gemessen):

Im obigen Diagramm sind die Steuerelemente für die Herunterskalierung beispielsweise für eine maximal zulässige Reduzierung von 20 VMs in einem Nachlaufzeitfenster von 30 Minuten konfiguriert:
- Wenn die Last herunterfährt, entfernt das Autoscaling 20 VMs. Dies ist die maximal zulässige Reduzierung, die in den Steuerelementen für die Herunterskalierung konfiguriert ist.
- Wenn die Last wächst und fällt, überwacht das Autoscaling ständig das Nachlaufzeitfenster der letzten 30 Minuten auf die Spitzengröße, die ausreicht, um die bisherige Last zu verarbeiten. Diese Spitzengröße wird als Basis für die Skalierung verwendet, um die Herunterskalierungsrate zu begrenzen. Wenn die Spitzengröße in den letzten 30 Minuten 70 VMs betrug und die maximal zulässige Reduzierung auf 20 VMs festgelegt ist, kann das Autoscaling auf 50 VMs skalieren. Wenn die aktuelle Größe 65 VMs beträgt, kann das Autoscaling nur 15 VMs entfernen.
- Bei abnehmender Last entfernt das Autoscaling weiterhin VM-Instanzen, begrenzt jedoch die Rate auf maximal 20 VMs von der in den letzten 30 Minuten gemessenen maximalen Instanzgruppengröße.
Die maximal zulässige Reduzierung der Gruppengröße kann sofort erfolgen. Daher sollten Sie die maximal zulässige Reduzierung so konfigurieren, dass Ihre Anwendung es sich leisten kann, so viele Instanzen gleichzeitig zu verlieren. Verwenden Sie den Parameter für die maximal zulässige Reduzierung, um anzugeben, wie viel Reduzierung der Bereitstellungskapazität Ihre Anwendung tolerieren kann.
Die Begrenzung der Anzahl von VM-Instanzen, die durch Autoscaling entfernt werden können, und die Erhöhung des beobachteten Nachlaufzeitfensters sollte für Anwendungen mit Lastspitzen und langen Initialisierungszeiten die Verfügbarkeit verbessern. Insbesondere sinkt die Größe der Instanzgruppe nicht abrupt als Reaktion auf einen signifikanten Lastabfall und nimmt stattdessen mit der Zeit allmählich ab. Wenn die Last kurz nach einer Skalierung ansteigt, sollte die verbleibende Anzahl von VMs die Spitze dennoch innerhalb Ihrer Toleranz aufnehmen können. Außerdem müssen weniger VMs gestartet werden, um den Spitzenwert ausreichend zu verarbeiten.
Sie können Steuerelemente für die Herunterskalierung für das Autoscaling von zonalen und regionalen MIGs konfigurieren. Die Konfiguration ist in beiden Fällen identisch. Die Steuerelemente für die Herunterskalierung funktionieren für jede Gruppengröße.
Steuerelemente für die Herunterskalierung und Autoscaling-Stabilität
Das Konfigurieren von Steuerelementen für die Herunterskalierung bedeutet nicht, dass der integrierte Stabilisierungsmechanismus des Autoscalings deaktiviert wird. Autoscaling hält die Instanzgruppengröße immer auf einem Niveau, das erforderlich ist, um die Spitzenlast zu bedienen, die während des Stabilisierungszeitraums beobachtet wird. Mit den Steuerelementen für die Herunterskalierung können Sie die Größe der Instanzgruppe anpassen.
| Integriertes Autoscaling: Stabilisierungszeitraum |
Steuerelemente für die Herunterskalierung: Nachlaufzeitfenster |
|
|---|---|---|
| Konfigurierbar? | Nein, nicht konfigurierbar | Ja, konfigurierbar |
| Was wird überwacht? | Überwacht die Spitzenlast in den letzten 10 Minuten oder die Initialisierungsphase, je nachdem, welcher Zeitraum länger ist. | Überwacht die Spitzengröße der Instanzgruppe im vorherigen Zeitraum, der durch ein Nachlaufzeitfenster festgelegt wurde |
| Wie hilft das? | Sorgt dafür, dass die Größe der Instanzgruppe ausreicht, um die Spitzenlast zu bewältigen, die in den letzten 10 Minuten oder die Initialisierungsphase beobachtet wurde, je nachdem, welcher Zeitraum länger ist. | Sorgt dafür, dass die Größe der Instanzgruppe nicht um mehr VM-Instanzen reduziert wird, als Ihre Arbeitslast bei der Verarbeitung von Lastspitzen über ein bestimmtes Zeitfenster hinnehmen kann. |
Steuerelemente für die Herunterskalierung mit Autoscaling-Modus
Es gibt zwei ähnliche, aber leicht unterschiedliche Szenarien, wenn Ihre MIG nicht automatisch skaliert wird und Sie die automatische Skalierung aktivieren möchten. Diese hängen davon ab, ob Sie Autoscaling zum ersten Mal konfigurieren oder ob Autoscaling konfiguriert, aber vorübergehend eingeschränkt oder deaktiviert ist.
Autoscaling zum ersten Mal konfigurieren
Wenn Sie eine nicht automatisch skalierte MIG haben und Autoscaling von Grund auf neu konfigurieren, verwendet das Autoscaling die aktuelle MIG-Größe als Ausgangspunkt. Vor dem Herunterskalieren verwendet das Autoscaling den Stabilisierungszeitraum und verwendet dann Steuerelemente für die Herunterskalierung, um die Skalierungsrate zu beschränken:

Autoscaling-Modus ändern
Mit dem Autoscaling-Modus können Sie Autoscaling-Aktivitäten vorübergehend deaktivieren oder einschränken. Die Autoscaling-Konfiguration bleibt bestehen und das Autoscaling führt weiterhin Hintergrundberechnungen durch, während das Autoscaling deaktiviert oder eingeschränkt ist. Wenn Autoscaling sich im deaktivierten oder eingeschränkten Modus befindet, berücksichtigt es in seinen Hintergrundberechnungen die Steuerelemente für die Herunterskalierung. Alle Autoscaling-Aktivitäten werden mit den neuesten Berechnungen fortgesetzt, wenn Sie Autoscaling wieder aktivieren oder die Einschränkung aufheben:

- Das AKTIVIERTE Autoscaling funktioniert wie gewohnt (in diesem Fall mit Steuerelementen für die Herunterskalierung).
- Wenn Sie das Autoscaling DEAKTIVIEREN, wird die empfohlene Größe der Instanzgruppe basierend auf der Auslastung berechnet. Bei Autoscaling-Berechnungen werden weiterhin Steuerelemente für die Herunterskalierung berücksichtigt. Das Autoscaling wendet jedoch keine Größenberechnungen an, wenn das Autoscaling DEAKTIVIERT ist. Die Größe der Instanzgruppe bleibt konstant, bis das Autoscaling wieder AKTIVIERT ist.
- Wenn Sie das Autoscaling wieder AKTIVIEREN, wird sofort die zuvor berechnete Größe angewendet. Dies ermöglicht eine schnellere Skalierung auf die richtige Größe. Das erneute Aktivieren des Autoscalings kann zu einer sprunghaften Skalierung führen (hier von 80 auf 40 VM-Instanzen). Dies ist sicher, da bei Hintergrundberechnungen bereits Steuerelemente für die Herunterskalierung berücksichtigt werden.
Vorausschauendes Autoscaling
Weitere Informationen zum vorausschauenden Autoscaling, einschließlich seiner Funktionsweise, finden Sie unter Anhand von Vorhersagen skalieren.
Stoppen von Instanzen vorbereiten
Wenn das Autoscaling herunterskaliert, bestimmt es die Anzahl der VM-Instanzen, die gelöscht werden sollen. Das Autoscaling priorisiert die zu löschenden VM-Instanzen anhand verschiedener Faktoren, darunter:
- VMs, die aus irgendeinem Grund nicht ausgeführt werden
- VMs, die störend sind oder geplant sind, z. B. aktualisieren, neu starten oder ersetzen.
- VMs, die noch nicht auf die beabsichtigte Version der Instanzvorlage aktualisiert wurden.
- VMs mit dem niedrigsten Autoscaling-Signal. Wenn Sie beispielsweise Ihre MIG so konfigurieren, dass sie anhand der CPU-Auslastung skaliert, und die Gruppe herunterskaliert werden muss, versucht das Autoscaling, die VMs mit der geringsten CPU-Auslastung zu entfernen.
Bevor eine Instanz beendet wird, sollten Sie prüfen, ob diese Instanz bestimmte Aufgaben ausführt, z. B. bestehende Verbindungen schließen, Anwendungen oder Anwendungsserver ordnungsgemäß herunterfahren, Logs hochladen usw. Sie können Ihrer Instanz über ein Shutdown-Skript die Anweisung geben, diese Aufgaben auszuführen. Das Shutdown-Skript läuft in dem kurzen Zeitraum zwischen erfolgter Beendigungsanfrage und tatsächlicher Beendigung der Instanz auf einer Best-Effort-Basis. In diesem Zeitraum versucht Compute Engine, Ihr Shutdown-Skript und alle in dem Skript angegebenen Aufgaben auszuführen.
Dies ist besonders nützlich, wenn Sie Load-Balancing für Ihre verwaltete Instanzgruppe verwenden. Wenn die Instanz fehlerhaft ist, kann es einige Zeit dauern, bis der Lastenausgleich erkennt, dass die Instanz fehlerhaft ist. Dies führt dazu, dass der Lastenausgleich weiterhin neue Anfragen an die Instanz sendet. Mit einem Shutdown-Skript kann die Instanz berichten, dass sie fehlerhaft ist, während sie heruntergefahren wird, sodass der Lastausgleich aufhören kann, Daten zur Instanz zu senden. Weitere Informationen zu Load-Balancing-Systemdiagnosen finden Sie unter Systemdiagnosen – Übersicht.
Weitere Informationen zu Shutdown-Skripts finden Sie unter Shutdown-Skripts.
Weitere Informationen zum Herunterfahren einer Instanz finden Sie in der Dokumentation zum Anhalten oder Löschen einer Instanz.
Autoscaling-Diagramme und -Logs überwachen
Compute Engine bietet mehrere Diagramme und Logs, mit denen Sie das Verhalten Ihrer verwalteten Instanzgruppe jederzeit überwachen können.
Sie können in der Google Cloud Console auf die Diagramme und Logs zugreifen.
- Rufen Sie in der Google Cloud Console die Seite Instanzgruppen auf.
- Klicken Sie auf den Namen der verwalteten Instanzgruppe, die Sie aufrufen möchten.
- Wählen Sie auf der Seite "Verwaltete Instanzgruppe" den Tab Monitoring aus.
In den Monitoring-Diagrammen wird die Entwicklung der folgenden Messwerte dargestellt:
- Gruppengröße
- Autoscaler-Verwendung
- CPU-Auslastung
- Laufwerks-E/A (Byte)
- Laufwerks-E/A (Vorgänge)
- Netzwerk-Byte
- Netzwerkpakete
Eine Kurzinfo neben dem Titel jedes Diagramms enthält zusätzliche kontextbezogene Details zum angezeigten Messwert.
Unten auf der Seite finden Sie das Feld Logs. Dort finden Sie eine Liste der Ereignislogs für die verwaltete Instanzgruppe. Klicken Sie zum Anzeigen der Logs auf den Erweiterungspfeil.
Alle Diagramme und Logs sind an einen einzelnen Zeitraum gebunden, den Sie mithilfe der Zeitraumauswahl anpassen können. Sie können auf jedes Diagramm klicken und es verschieben, um ein bestimmtes Ereignis zu vergrößern und die Diagramme und Logs innerhalb des ausgewählten Zeitraums zu analysieren.
Vorausschauendes Autoscaling überwachen
Compute Engine bietet ein Diagramm, mit dem die Autoscaling-Vorhersagen überwacht werden können. Klicken Sie dazu im ersten Diagramm auf den Titel Gruppengröße und wählen Sie Predictive Autoscaling aus.
Wenn Autoscaling aktiviert ist, können Sie sehen, wie das Autoscaling die Vorhersagen Ihrer Instanzgruppe festlegt. Auch wenn Autoscaling nicht aktiviert ist, können Sie die Autoscaling-Vorhersagen sehen und dazu nutzen, um Entscheidungen hinsichtlich der Gruppengröße zu treffen.
Im Folgenden finden Sie Informationen zu diesem Diagramm.
- Die blaue Linie zeigt die Anzahl der Instanzen in der verwalteten Instanzgruppe an.
- Die grüne Linie zeigt die Anzahl der Instanzen, die durch Autoscaling vorhergesagt wurden.
- Wenn sich die grüne Linie unterhalb der blauen Linie befindet, steht eine große Menge an Kapazität zur Verfügung und die VM-Instanzen sind wahrscheinlich unverhältnismäßig gering ausgelastet.
- Wenn sich die grüne Linie über der blauen Linie befindet, ist sehr wenig oder gar keine Kapazität mehr vorhanden und Sie sollten der Instanzgruppe weitere Instanzen hinzufügen.
- Die gestrichelten horizontalen roten Linien geben die Mindest- und Höchstzahl von Instanzen an, die in Ihrer Instanzgruppe zulässig sind.
Statusmeldungen ansehen
Wenn im Autoscaling bei der Skalierung ein Problem auftritt, wird eine Warnung oder eine Fehlermeldung ausgegeben. Sie können diese Statusmeldungen auf zwei Arten prüfen.
Statusmeldungen auf der Seite "Instanzgruppen" ansehen
Statusmeldungen können Sie sich direkt auf der Seite Instanzgruppen in der Google Cloud Console ansehen.
- Rufen Sie in der Google Cloud Console die Seite Instanzgruppen auf.
Suchen Sie nach Instanzgruppen, vor deren Namen das Warnsymbol steht.
Beispiel:
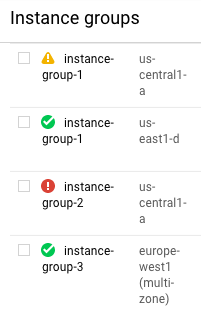
Bewegen Sie den Mauszeiger auf ein Statussymbol, um Details zur Statusmeldung zu sehen.
Statusmeldungen auf der Seite der Instanzgruppenübersicht ansehen
Sie können direkt zur Übersicht einer bestimmten Instanzgruppe wechseln, um relevante Statusmeldungen zu sehen.
- Rufen Sie in der Google Cloud Console die Seite Instanzgruppen auf.
- Klicken Sie auf die Instanzgruppe, für die Sie Statusmeldungen sehen möchten.
- Rufen Sie auf der Seite "Instanzgruppen" die Statusmeldung unter dem Namen der Instanzgruppe auf.
Gängige Statusrückmeldungen
Wenn im Autoscaling bei der Skalierung ein Problem auftritt, wird eine Warnung oder eine Fehlermeldung ausgegeben. Hier sind einige der häufigsten Rückmeldungen und deren Bedeutung.
All instances in the instance group are unhealthy (not in RUNNING state). If this is an error, check the instances.- Alle Instanzen in der Instanzgruppe haben einen anderen Status als
RUNNING. Wenn dies beabsichtigt ist, können Sie diese Meldung ignorieren. Falls dies nicht beabsichtigt ist, beheben Sie den Fehler in der Instanzgruppe. The number of instances has reached the maxNumReplicas. The autoscaler cannot add more instances.- Bei der Erstellung des Autoscalings haben Sie die maximale Anzahl der Instanzen für die Instanzgruppe angegeben. Autoscaling versucht derzeit, die Instanzgruppe nach Bedarf hochzuskalieren, hat jedoch die
maxNumReplicaserreicht. Informationen zum Ändern des Werts vonmaxNumReplicasin eine größere Zahl finden Sie unter Autoscaling aktualisieren. The monitoring metric that was specified does not exist or does not have the required labels. Check the metric.Sie führen ein Autoscaling mit einem Cloud Monitoring-Messwert durch, aber der von Ihnen angegebene Messwert existiert nicht, verfügt nicht über die erforderlichen Labels oder ist nicht für den Compute Engine System-Dienst-Agent zugänglich.
- Je nachdem, ob der Messwert ein Standard- oder benutzerdefinierter Messwert ist, sind unterschiedliche Label erforderlich. Weitere Informationen finden Sie in der Dokumentation zur Skalierung basierend auf einem Monitoring-Messwert.
- Prüfen Sie, ob der Dienst-Agent von Compute Engine die IAM-Rolle
compute.serviceAgenthat. Informationen zum Hinzufügen der Rolle finden Sie unter Voraussetzungen für das Autoscaling.
- Prüfen Sie, ob der Dienst-Agent von Compute Engine die IAM-Rolle
Quota for some resources is exceeded. Increase the quota or delete resources to free up more quota.Sie können sich Informationen zu Ihren verfügbaren Kontingenten auf der Kontingentseite der Google Cloud Console ansehen.
Autoscaling does not work with an HTTP/S load balancer configured for maxRate.Das Load-Balancing der Instanzgruppe erfolgt mit der
maxRate-Konfiguration, aber das Autoscaling unterstützt diesen Modus nicht. Ändern Sie die Konfiguration oder deaktivieren Sie das Autoscaling. Weitere Informationen zumaxRatefinden Sie in der Dokumentation zum Load-Balancing unter Einschränkungen und Richtlinien.The autoscaler is configured to scale based on a load balancing signal but the instance group has not received any queries from the load balancer. Check that the load balancing configuration is working.Für die Instanzgruppe erfolgt gerade ein Load-Balancing, aber es gibt keine eingehenden Abfragen für die Gruppe. Der Dienst befindet sich möglicherweise im Leerlauf. In diesem Fall besteht kein Grund zur Sorge. Diese Meldung kann jedoch auch durch fehlerhafte Konfiguration verursacht werden. Beispielsweise kann eine automatisch skalierte Instanzgruppe das Ziel von mehr als einem Load-Balancer sein, was nicht unterstützt wird. Eine vollständige Liste der Richtlinien finden Sie unter Einschränkungen und Richtlinien in der Dokumentation zum Load-Balancing.