La fonctionnalité d'exécution de code de l'API Gemini permet au modèle de générer et d'exécuter du code Python ainsi que d'apprendre des résultats de façon itérative jusqu'à ce qu'il parvienne à une sortie finale. Vous pouvez vous servir de cette fonctionnalité pour créer des applications qui bénéficient d'un raisonnement basé sur du code et qui produisent des sorties textuelles. Par exemple, vous pouvez utiliser l'exécution de code dans une application qui résout des équations ou traite du texte.
L'API Gemini fournit l'exécution de code en tant qu'outil, tout comme l'appel de fonction. Ainsi, une fois que vous l'avez ajoutée en tant qu'outil, le modèle décide quand l'utiliser.
L'environnement d'exécution du code inclut les bibliothèques suivantes. Vous ne pouvez pas installer vos propres bibliothèques.
- Altair
- Chess
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulate
Modèles compatibles
Les modèles suivants sont compatibles avec l'exécution de code :
- Gemini 2.5 Flash (preview)
- Gemini 2.5 Flash-Lite (preview)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash avec l'API Live (Preview)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Premiers pas avec l'exécution de code
Cette section suppose que vous avez suivi les étapes de configuration décrites dans le guide de démarrage rapide de l'API Gemini.
Activer l'exécution de code sur le modèle
Vous pouvez activer l'exécution de code de base, comme indiqué ci-dessous :
Python
Installer
pip install --upgrade google-genai
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez les variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Découvrez comment installer ou mettre à jour le Go.
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez les variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Installer
npm install @google/genai
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez les variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Découvrez comment installer ou mettre à jour le Java.
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez les variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Avant d'utiliser les données de requête, remplacez les éléments suivants :
GENERATE_RESPONSE_METHOD: type de réponse que le modèle doit générer. Choisissez la méthode de renvoi de la réponse du modèle :streamGenerateContent: la réponse s'affiche progressivement à mesure qu'elle est générée afin que les utilisateurs ressentent moins la latence.generateContent: la réponse est renvoyée une fois qu'elle a été entièrement générée.
LOCATION: région dans laquelle traiter la requête. Les options disponibles incluent les suivantes :Cliquer pour développer la liste partielle des régions disponibles
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: ID de votre projet.MODEL_ID: ID du modèle que vous souhaitez utiliser.ROLE: rôle dans une conversation associée au contenu. La spécification d'un rôle est requise, même dans les cas d'utilisation à un seul tour. Les valeurs acceptées incluent les suivantes :USER: spécifie le contenu que vous envoyez.MODEL: spécifie la réponse du modèle.
TEXT
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json.
Exécutez la commande suivante dans le terminal pour créer ou écraser ce fichier dans le répertoire actuel :
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFExécutez ensuite la commande suivante pour envoyer votre requête REST :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json.
Exécutez la commande suivante dans le terminal pour créer ou écraser ce fichier dans le répertoire actuel :
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Exécutez ensuite la commande suivante pour envoyer votre requête REST :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Vous devriez recevoir une réponse JSON semblable à la suivante.
Utiliser l'exécution de code dans le chat
Vous pouvez également utiliser l'exécution de code dans un chat.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Exécution de code ou appel de fonction
L'exécution de code et l'appel de fonction sont des fonctionnalités similaires :
- L'exécution de code permet au modèle d'exécuter du code dans le backend de l'API au sein d'un environnement fixe et isolé.
- L'appel de fonction permet d'exécuter les fonctions demandées par le modèle, dans l'environnement de votre choix.
En général, il est préférable d'utiliser l'exécution de code si elle peut gérer votre cas d'utilisation. L'exécution de code est plus simple à utiliser (il suffit de l'activer) et se résout en une seule requête GenerateContent. L'appel de fonction nécessite une requête GenerateContent supplémentaire pour renvoyer la sortie de chaque appel de fonction.
Dans la plupart des cas, vous devez utiliser l'appel de fonction si vous devez exécuter vos propres fonctions en local, et l'exécution de code si vous souhaitez que l'API écrive et exécute du code Python, et renvoie le résultat.
Facturation
L'exécution de code à partir de l'API Gemini n'entraîne aucuns frais supplémentaires. Vous serez facturé au tarif actuel des jetons d'entrée et de sortie en fonction du modèle Gemini que vous utilisez.
Voici quelques autres points à connaître concernant la facturation de l'exécution du code :
- Vous ne serez facturé qu'une seule fois pour les jetons d'entrée que vous transmettez au modèle et les jetons d'entrée intermédiaires générés par l'outil d'exécution de code.
- Vous êtes facturé pour les jetons de sortie finaux qui vous sont renvoyés dans la réponse de l'API.
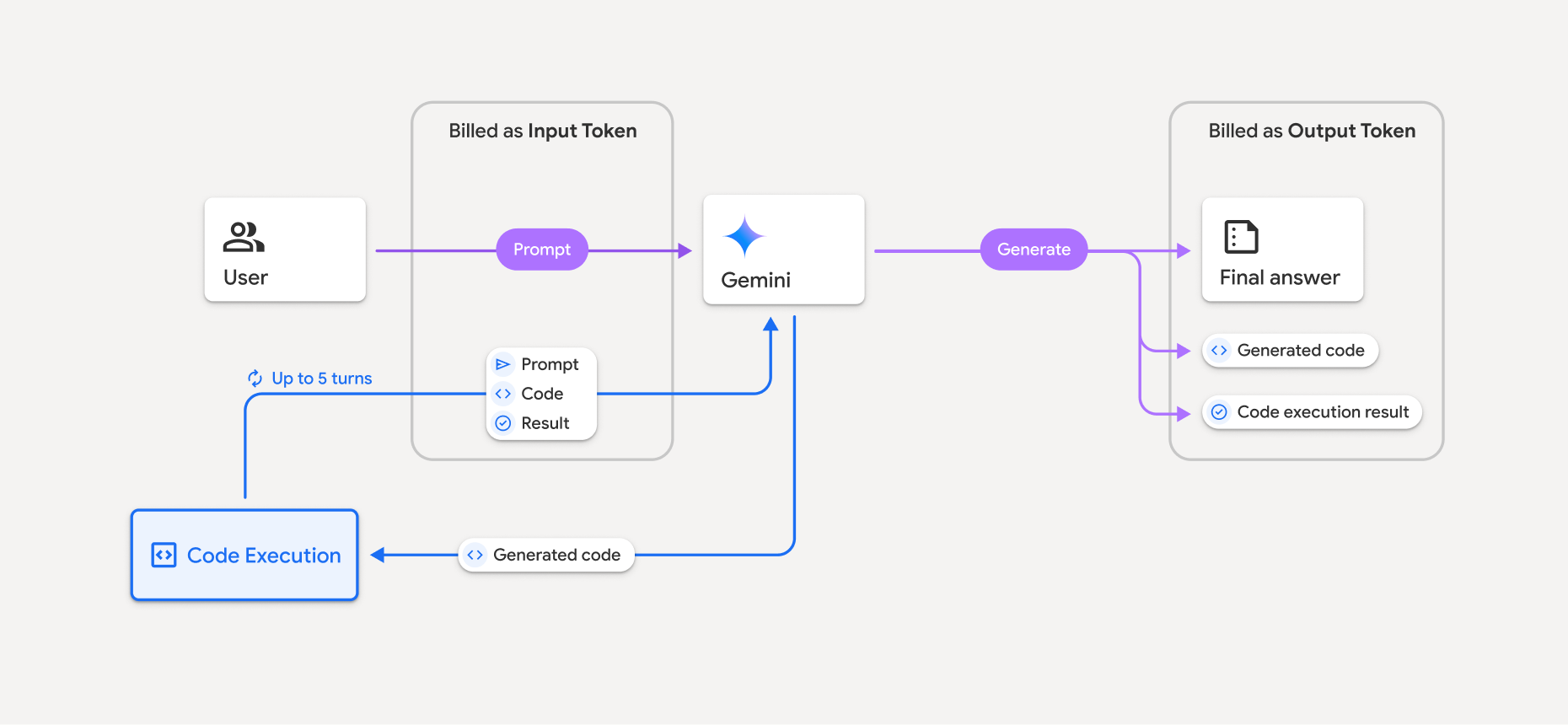
- Vous êtes facturé au tarif actuel des jetons d'entrée et de sortie en fonction du modèle Gemini que vous utilisez.
- Si Gemini utilise l'exécution de code pour générer votre réponse, la requête d'origine, le code généré et le résultat du code exécuté sont désignés comme des jetons intermédiaires et sont facturés en tant que jetons d'entrée.
- Gemini génère ensuite un résumé et renvoie le code généré, le résultat du code exécuté et le résumé final. Ils sont facturés en tant que jetons de sortie.
- L'API Gemini inclut un nombre de jetons intermédiaires dans la réponse de l'API. Vous pouvez ainsi suivre tous les jetons d'entrée supplémentaires au-delà de ceux transmis dans votre requête initiale.
Le code généré peut inclure des sorties textuelles et multimodales, comme des images.
Limites
- Le modèle ne peut que générer et exécuter du code. Il ne peut pas renvoyer d'autres artefacts tels que des fichiers multimédias.
- L'outil d'exécution de code n'accepte pas les URI de fichier en tant qu'entrée/sortie. Toutefois, il accepte l'entrée de fichier et la sortie de graphique en tant qu'octets intégrés. Grâce à ces fonctionnalités d'entrée et de sortie, vous pouvez importer des fichiers CSV et des fichiers texte, poser des questions sur les fichiers et générer des graphiques Matplotlib dans le résultat de l'exécution du code.
Les types MIME compatibles pour les octets intégrés sont
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tset.xml. - L'exécution du code peut durer au maximum 30 secondes avant l'expiration du délai.
- Dans certains cas, l'activation de l'exécution du code peut entraîner des régressions dans d'autres domaines de la sortie du modèle (par exemple, l'écriture d'une histoire).