This page describes how to view and interpret your model evaluation results after running your model evaluation using the Gen AI evaluation service.
View evaluation results
The Gen AI evaluation service lets you visualize your evaluation results directly within your development environment, such as a Colab or Jupyter notebook. The .show() method, available on both EvaluationDataset and EvaluationResult objects, renders an interactive HTML report for analysis.
Visualizing generated rubrics in your dataset
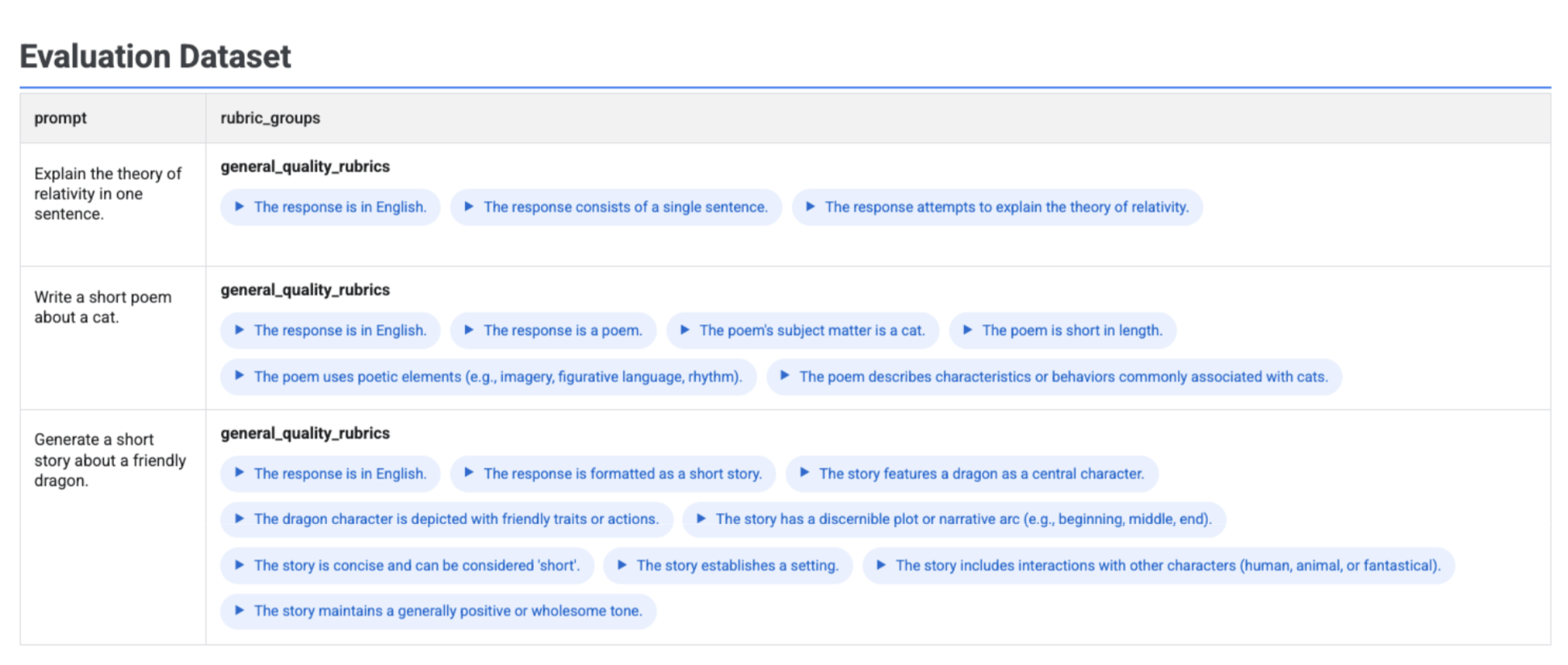
If you run client.evals.generate_rubrics(), the resulting EvaluationDataset object contains a rubric_groups column. You can visualize this dataset to inspect the rubrics generated for each prompt before running the evaluation.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
An interactive table displays with each prompt and the associated rubrics generated for it, nested within the rubric_groups column:
Visualizing inference results
After generating responses with run_inference(), you can call .show() on the resulting EvaluationDataset object to inspect the model's outputs alongside your original prompts and references. This is useful for a quick quality check before running a full evaluation:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
A table displays with each prompt, its corresponding reference (if provided), and the newly generated response:

Visualizing evaluation reports
When you call .show() on an EvaluationResult object, a report displays with two main sections:
Summary metrics: An aggregated view of all metrics, showing the mean score and standard deviation across the entire dataset.
Detailed results: A case-by-case breakdown, allowing you to inspect the prompt, reference, candidate response, and the specific score and explanation for each metric.
Single candidate evaluation report
For a single model evaluation, the report details the scores for each metric:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()

For all reports, you can expand a View Raw JSON section to inspect the data for any structured format such as Gemini, or OpenAI Chat Completion API format.
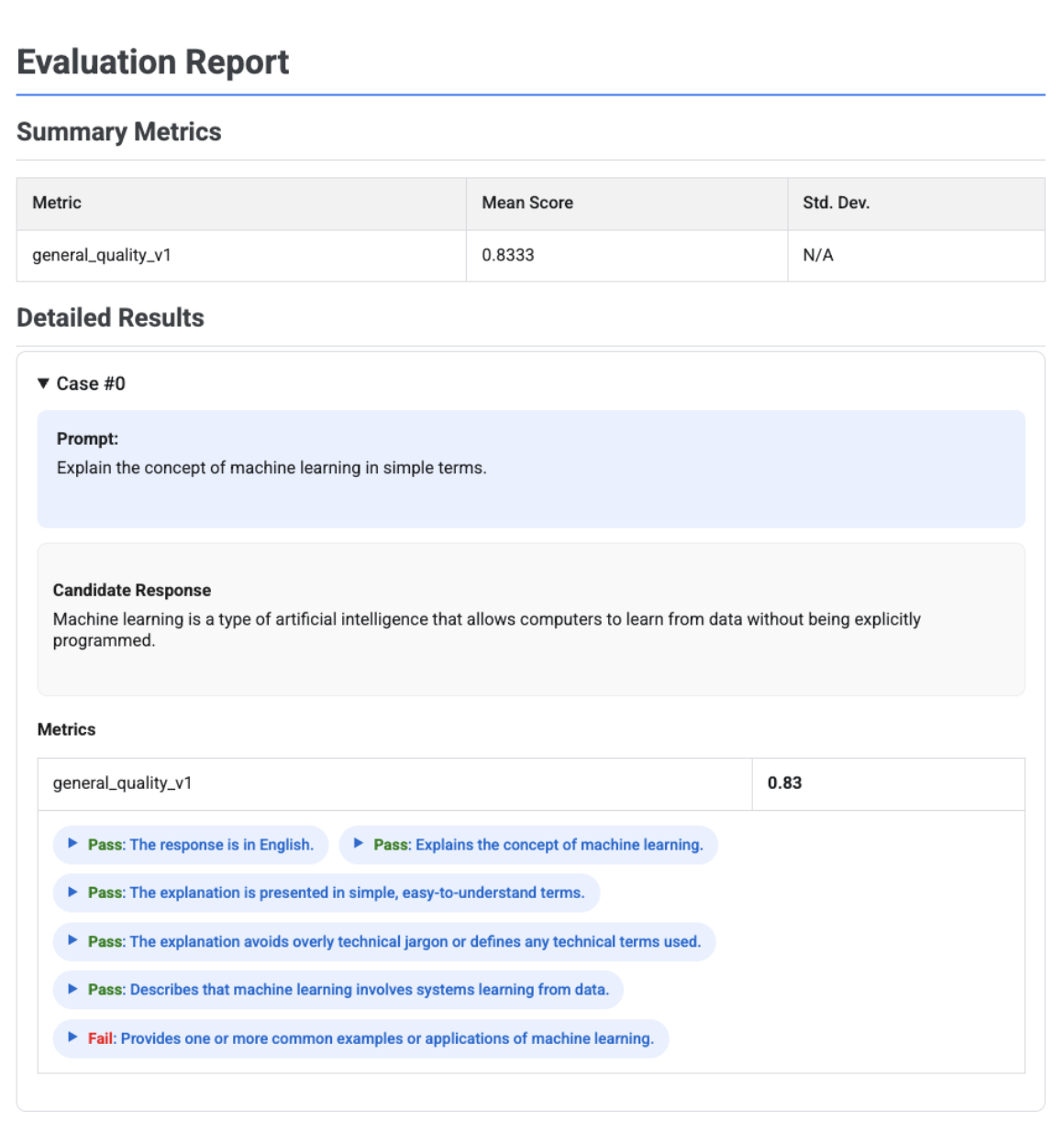
Adaptive rubric-based evaluation report with verdicts
When using adaptive rubric-based metrics, the results include the pass or fail verdicts and reasoning for each rubric applied to the response.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
The visualization shows each rubric, its verdict (Pass or Fail), and the reasoning, nested within the metric results for each case. For each specific rubric verdict, you can expand a card to show the raw JSON payload. This JSON payload includes additional details such as the full rubric description, the rubric type, importance, and the detailed reasoning behind the verdict.
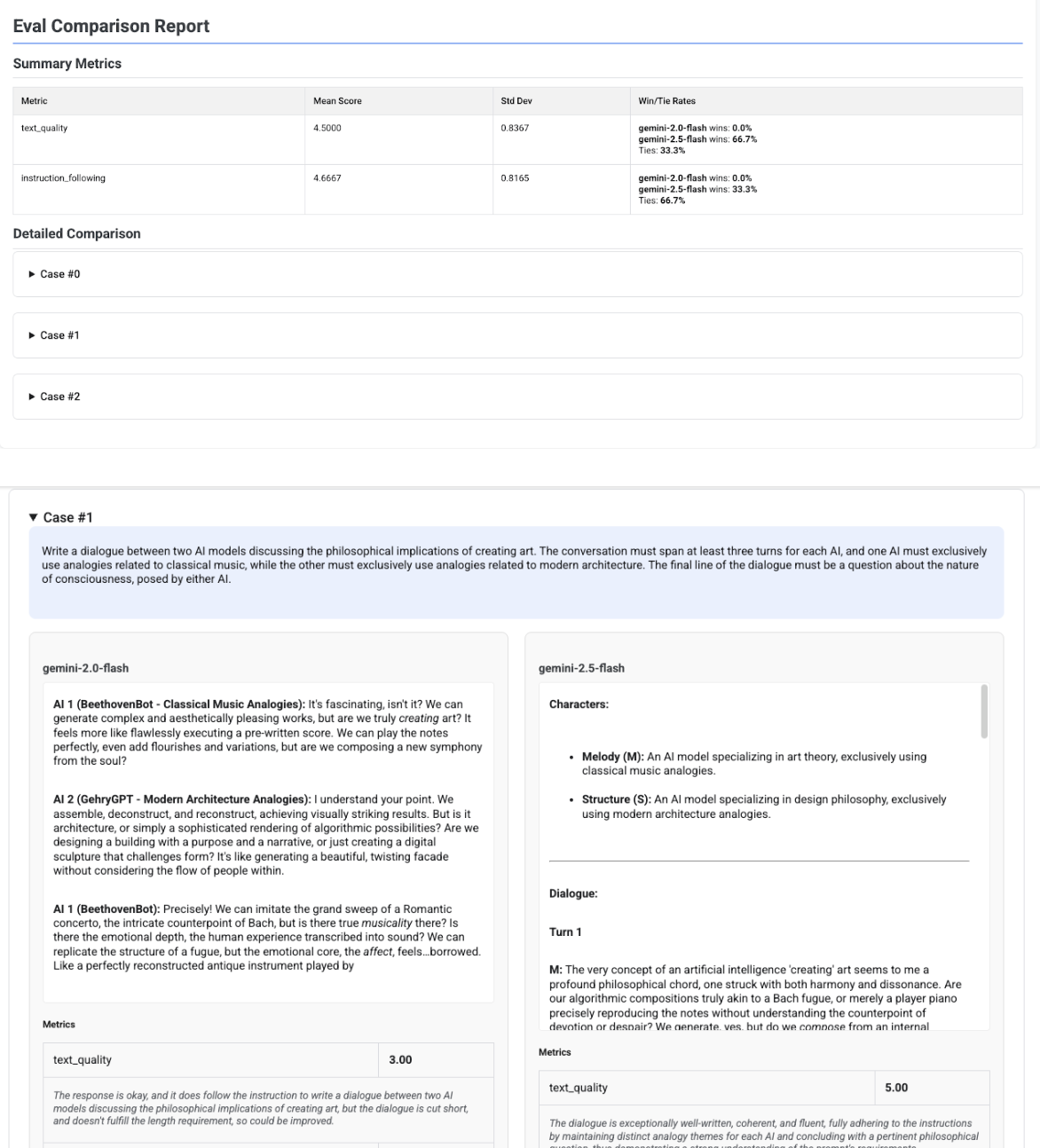
Multi-candidate comparison report
The report's format adapts depending on whether you are evaluating a single candidate or comparing multiple candidates. For a multi-candidate evaluation, the report provides a side-by-side view and includes win or tie-rate calculations in the summary table.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()