Depois de criar e avaliar seu modelo de IA generativa, você pode usá-lo para criar um agente, como um chatbot. O serviço de avaliação de IA generativa permite medir a capacidade do seu agente de concluir tarefas e metas para seu caso de uso.
Visão geral
Você tem as seguintes opções para avaliar seu agente:
Avaliação da resposta final: avalia a saída final de um agente (se ele atingiu ou não a meta).
Avaliação da trajetória: avalia o caminho (sequência de chamadas de ferramentas) que o agente seguiu para chegar à resposta final.
Com o serviço de avaliação de IA generativa, é possível acionar a execução de um agente e receber métricas para avaliação de trajetória e de resposta final em uma consulta do SDK da Vertex AI.
Agentes compatíveis
O serviço de avaliação de IA generativa é compatível com as seguintes categorias de agentes:
| Agentes compatíveis | Descrição |
|---|---|
| Agente criado com o modelo do Agent Engine | O Agent Engine (LangChain na Vertex AI) é uma plataforma Google Cloud em que você pode implantar e gerenciar agentes. |
| Agentes do LangChain criados com o modelo personalizável do Agent Engine | O LangChain é uma plataforma de código aberto. |
| Função personalizada do agente | A função de agente personalizada é uma função flexível que recebe um comando para o agente e retorna uma resposta e uma trajetória em um dicionário. |
Definir métricas para avaliação de agentes
Defina as métricas para avaliação da resposta final ou da trajetória:
Avaliação da resposta final
A avaliação da resposta final segue o mesmo processo da avaliação da resposta do modelo. Para mais informações, consulte Definir métricas de avaliação.
Avaliação de trajetória
As métricas a seguir ajudam você a avaliar a capacidade do modelo de seguir a trajetória esperada:
Correspondência exata
Se a trajetória prevista for idêntica à de referência, com as mesmas chamadas de função na mesma ordem, a métrica trajectory_exact_match vai retornar uma pontuação de 1. Caso contrário, será 0.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelo agente para chegar à resposta final. |
reference_trajectory |
O uso esperado da ferramenta para que o agente atenda à consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A trajetória prevista não corresponde à referência. |
| 1 | A trajetória prevista corresponde à referência. |
Correspondência na ordem
Se a trajetória prevista contiver todas as chamadas de função da trajetória de referência na mesma ordem e também puder ter chamadas de função extras, a métrica trajectory_in_order_match vai retornar uma pontuação de 1. Caso contrário, ela vai retornar 0.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A trajetória prevista usada pelo agente para chegar à resposta final. |
reference_trajectory |
A trajetória prevista esperada para o agente atender à consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | As chamadas de ferramenta na trajetória prevista não correspondem à ordem na trajetória de referência. |
| 1 | A trajetória prevista corresponde à referência. |
Correspondência em qualquer ordem
Se a trajetória prevista contiver todas as chamadas de função da trajetória de referência, mas a ordem não importar e puder conter chamadas de função extras, a métrica trajectory_any_order_match vai retornar uma pontuação de 1, caso contrário, 0.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelo agente para chegar à resposta final. |
reference_trajectory |
O uso esperado da ferramenta para que o agente atenda à consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A trajetória prevista não contém todas as chamadas de função na trajetória de referência. |
| 1 | A trajetória prevista corresponde à referência. |
Precisão
A métrica trajectory_precision mede quantas das chamadas de ferramenta na trajetória prevista são realmente relevantes ou corretas de acordo com a trajetória de referência.
A precisão é calculada da seguinte forma: conte quantas ações na trajetória prevista também aparecem na trajetória de referência. Divida essa contagem pelo número total de ações na trajetória prevista.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelo agente para chegar à resposta final. |
reference_trajectory |
O uso esperado da ferramenta para que o agente atenda à consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| Um ponto flutuante no intervalo de [0,1] | Quanto maior a pontuação, mais precisa será a trajetória prevista. |
Recall
A métrica trajectory_recall mede quantas das chamadas de ferramentas essenciais da trajetória de referência são capturadas na trajetória prevista.
O recall é calculado da seguinte maneira: conte quantas ações na trajetória de referência também aparecem na trajetória prevista. Divida essa contagem pelo número total de ações na trajetória de referência.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelo agente para chegar à resposta final. |
reference_trajectory |
O uso esperado da ferramenta para que o agente atenda à consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| Um ponto flutuante no intervalo de [0,1] | Quanto maior a pontuação, melhor o recall da trajetória prevista. |
Uso de uma única ferramenta
A métrica trajectory_single_tool_use verifica se uma ferramenta específica, especificada na especificação da métrica, é usada na trajetória prevista. Ela não verifica a ordem das chamadas de função nem quantas vezes a ferramenta é usada, apenas se ela está presente ou não.
Parâmetros de entrada da métrica
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelo agente para chegar à resposta final. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A ferramenta não está disponível |
| 1 | A ferramenta está presente. |
Além disso, as duas métricas de desempenho do agente a seguir são adicionadas aos resultados da avaliação por padrão. Não é necessário especificá-los em EvalTask.
latency
Tempo gasto pelo agente para retornar uma resposta.
| Valor | Descrição |
|---|---|
| Um ponto flutuante | Calculado em segundos. |
failure
Um booleano para descrever se a invocação do agente resultou em um erro ou foi concluída.
Pontuações de saída
| Valor | Descrição |
|---|---|
| 1 | Erro |
| 0 | Resposta válida retornada |
Preparar o conjunto de dados para avaliação do agente
Prepare o conjunto de dados para a resposta final ou avaliação de trajetória.
O esquema de dados para avaliação da resposta final é semelhante ao da avaliação da resposta do modelo.
Para a avaliação de trajetória baseada em computação, o conjunto de dados precisa fornecer as seguintes informações:
| Tipo de entrada | Conteúdo do campo de entrada |
|---|---|
predicted_trajectory |
A lista de chamadas de função usadas pelos agentes para chegar à resposta final. |
reference_trajectory (não obrigatório para trajectory_single_tool_use metric) |
O uso esperado da ferramenta para que o agente atenda à consulta. |
Exemplos de conjuntos de dados de avaliação
Os exemplos a seguir mostram conjuntos de dados para avaliação de trajetórias. reference_trajectory é obrigatório para todas as métricas, exceto trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Importar o conjunto de dados de avaliação
É possível importar o conjunto de dados nos seguintes formatos:
Arquivo JSONL ou CSV armazenado no Cloud Storage
Tabela do BigQuery
DataFrames da Pandas
O serviço de avaliação de IA generativa oferece exemplos de conjuntos de dados públicos para demonstrar como você pode avaliar seus agentes. O código a seguir mostra como importar os conjuntos de dados públicos de um bucket do Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
em que dataset é um dos seguintes conjuntos de dados públicos:
"on-device"para um Assistente residencial no dispositivo, que controla os aparelhos da casa. O agente ajuda com consultas como "Programe o ar-condicionado do quarto para que ele fique ligado entre 23h e 8h e desligado no restante do tempo"."customer-support"para um representante do suporte ao cliente. O agente ajuda com consultas como "Você pode cancelar todos os pedidos pendentes e encaminhar todos os tíquetes de suporte abertos?""content-creation"para um agente de criação de conteúdo de marketing. O agente ajuda com consultas como "Remarque a campanha X para ser uma campanha única no site de mídia social Y com um orçamento 50% menor, apenas em 25 de dezembro de 2024".
Executar avaliação de agente
Execute uma avaliação de trajetória ou de resposta final:
Para a avaliação do agente, é possível misturar métricas de avaliação de resposta e de trajetória, como no código a seguir:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Personalização de métricas
É possível personalizar uma métrica baseada em um modelo de linguagem grande para avaliação de trajetória usando uma interface com modelo ou do zero. Para mais detalhes, consulte a seção sobre métricas baseadas em modelo. Confira um exemplo de modelo:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Também é possível definir uma métrica personalizada baseada em computação para avaliação de trajetória ou resposta da seguinte maneira:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Conferir e interpretar os resultados
Para avaliação de trajetória ou de resposta final, os resultados são mostrados da seguinte forma:
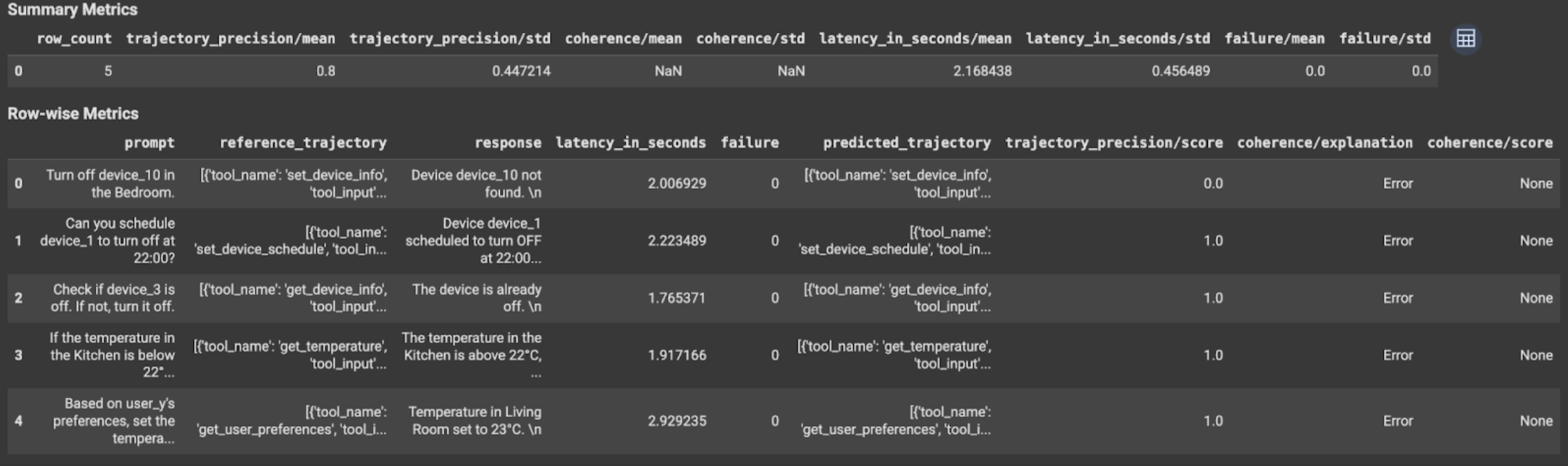
Os resultados da avaliação contêm as seguintes informações:
Métricas de resposta final
Resultados no nível da instância
| Coluna | Descrição |
|---|---|
| resposta | Resposta final gerada pelo agente. |
| latency_in_seconds | Tempo gasto para gerar a resposta. |
| falha | Indica se uma resposta válida foi gerada ou não. |
| score | Uma pontuação calculada para a resposta especificada na especificação da métrica. |
| explicação | A explicação da pontuação especificada na especificação da métrica. |
Resultados agregados
| Coluna | Descrição |
|---|---|
| média | Pontuação média de todas as instâncias. |
| desvio padrão | O desvio padrão para todas as pontuações. |
Métricas de trajetória
Resultados no nível da instância
| Coluna | Descrição |
|---|---|
| predicted_trajectory | Sequência de chamadas de ferramentas seguidas pelo agente para chegar à resposta final. |
| reference_trajectory | Sequência de chamadas de função esperadas. |
| score | Uma pontuação calculada para a trajetória prevista e a trajetória de referência especificadas na especificação da métrica. |
| latency_in_seconds | Tempo gasto para gerar a resposta. |
| falha | Indica se uma resposta válida foi gerada ou não. |
Resultados agregados
| Coluna | Descrição |
|---|---|
| média | Pontuação média de todas as instâncias. |
| desvio padrão | O desvio padrão para todas as pontuações. |
Protocolo Agent2Agent (A2A)
Se você estiver criando um sistema multiagente, recomendamos revisar o protocolo A2A. O protocolo A2A é um padrão aberto que permite a comunicação e a colaboração perfeitas entre agentes de IA, independentemente dos frameworks subjacentes. Ele foi doado pela Google Cloud à Linux Foundation em junho de 2025. Para usar os SDKs A2A ou testar as amostras, confira o repositório do GitHub.
A seguir
Teste os seguintes notebooks de avaliação de agente: