Vertex AI 嵌入模型可以为各种任务类型(例如文档检索、问答和事实验证)生成经过优化的嵌入。任务类型是根据您的预期用例优化模型生成的嵌入的标签。本文档介绍了如何为嵌入选择最合适的任务类型。
支持的模型
以下模型支持任务类型:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
任务类型的优势
任务类型可以提高嵌入模型生成的嵌入的质量。
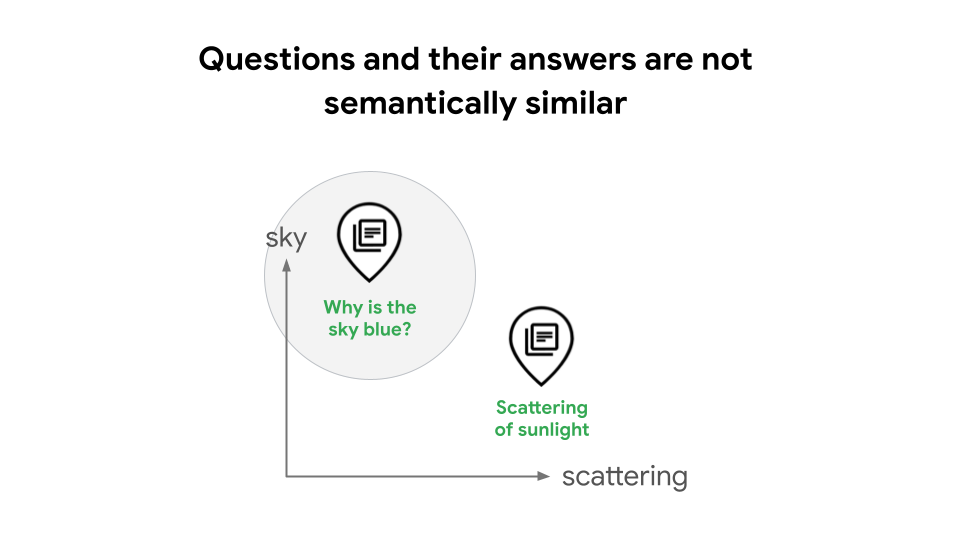
例如,在构建检索增强生成 (RAG) 系统时,一种常见的设计是使用文本嵌入和向量搜索来执行相似性搜索。在某些情况下,这可能会导致搜索质量下降,因为问题及其答案在语义上并不相似。例如,“为什么天空是蓝色的?”这一问题及其答案“阳光的散射会导致天空呈现蓝色”作为陈述的含义截然不同,这意味着 RAG 系统不会自动识别它们之间的关系,如图 1 所示。如果没有任务类型,RAG 开发者需要训练模型以了解查询与答案之间的关系,这需要高级数据科学技能和经验,或者使用基于 LLM 的查询扩展或 HyDE,这可能会导致高延迟和高成本。
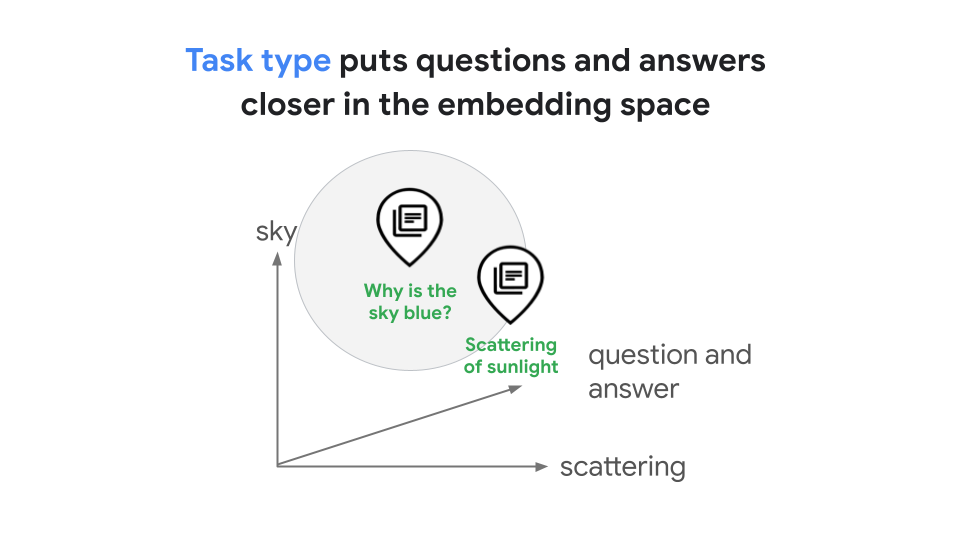
借助任务类型,您可以为特定任务生成经过优化的嵌入,从而节省开发您自己的特定于任务的嵌入所需的时间和费用。针对查询“为什么天空是蓝色的?”及其答案“阳光的散射会导致天空呈现蓝色”所生成的嵌入空间将位于共享嵌入空间中,该空间表示两者之间的关系,如图 2 所示。在此 RAG 示例中,经过优化的嵌入会提高相似搜索的效果。
除了查询和答案用例之外,任务类型还为分类、聚类和事实验证等任务提供了优化的嵌入空间。
支持的任务类型
使用任务类型的嵌入模型支持以下任务类型:
| 任务类型 | 说明 |
|---|---|
CLASSIFICATION |
用于生成经过优化的嵌入,以便根据预设标签对文本进行分类 |
CLUSTERING |
用于生成经过优化的嵌入,以便根据文本的相似性对文本进行分组 |
RETRIEVAL_DOCUMENT、RETRIEVAL_QUERY、QUESTION_ANSWERING 和 FACT_VERIFICATION |
用于生成针对文档搜索或信息检索进行了优化的嵌入 |
CODE_RETRIEVAL_QUERY |
用于根据自然语言查询检索代码块,例如“对数组进行排序”或“反转链表”。代码块的嵌入是使用 RETRIEVAL_DOCUMENT 计算的。 |
SEMANTIC_SIMILARITY |
用于生成经过优化以评估文本相似度的嵌入。此方法不适用于检索用例。 |
嵌入作业最适合的任务类型取决于您对嵌入的用例。在选择任务类型之前,请确定您的嵌入用例。
确定嵌入用例
嵌入用例通常属于以下四类之一:评估文本相似度、对文本进行分类、对文本进行聚类或从文本中检索信息。如果您的用例不属于上述任何类别,则默认使用 RETRIEVAL_QUERY 任务类型。
任务指令格式分为两种:非对称格式和对称格式。您需要根据自己的用例使用正确的格式。
| 检索用例 (非对称格式) |
查询任务类型 | 文档任务类型 |
|---|---|---|
| 搜索查询 | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| 问答 | QUESTION_ANSWERING | |
| 事实核查 | FACT_VERIFICATION | |
| 代码检索 | CODE_RETRIEVAL_QUERY |
| 单输入源用例 (对称格式) |
输入任务类型 |
|---|---|
| 分类 | 分类 |
| 聚簇 | CLUSTERING |
| 语义相似度 (不适用于检索用例; 适用于 STS) |
SEMANTIC_SIMILARITY |
对文本进行分类
如果您想使用嵌入来根据预设标签对文本进行分类,请使用 CLASSIFICATION 任务类型。此任务类型会在针对分类进行了优化的嵌入空间中生成嵌入。
例如,假设您想为社交媒体帖子生成嵌入,然后使用这些嵌入将帖子的情感分类为正面、负面或中性。当对包含“I don't like traveling on airplanes”字样的社交媒体帖子的嵌入式内容进行分类时,情绪会被归类为负面。
集群文本
如果您想使用嵌入来根据文本的相似性对文本进行分组,请使用 CLUSTERING 任务类型。此任务类型会生成经过优化的嵌入,以便根据相似性进行分组。
例如,假设您想为新闻报道生成嵌入,以便向用户显示与他们之前阅读的报道主题相关的报道。生成并对嵌入式内容进行分组后,您可以向阅读大量体育相关文章的用户推荐其他体育相关文章。
聚类的其他用例包括:
- 客户细分:将通过其个人资料或活动生成的类似嵌入数据进行分组,以便进行有针对性的营销和提供个性化体验。
- 产品细分:根据产品标题和说明、产品图片或客户评价对产品嵌入进行聚类,可以帮助企业对其产品进行细分分析。
- 市场调研:对消费者调查问卷答案或社交媒体数据嵌入进行聚类分析,可以揭示消费者意见、偏好和行为中的隐藏模式和趋势,有助于进行市场调研并制定产品开发策略。
- 医疗保健:对从医疗数据中提取的患者嵌入进行聚类有助于识别具有类似病情或治疗反应的群体,从而提供更个性化的医疗保健方案和有针对性的治疗方案。
- 客户反馈趋势:将来自各种渠道(调查问卷、社交媒体、支持工单)的客户反馈汇总到各个群组中,有助于找出常见的痛点、功能请求和需要改进的方面。
从文本中检索信息
构建搜索或检索系统时,您需要处理两种类型的文本:
- 语料库:您要搜索的文档集合。
- 查询:用户提供的用于在语料库中搜索信息的文本。
为获得最佳性能,您必须使用不同的任务类型来为语料库和查询生成嵌入。
首先,为整个文档集合生成嵌入。这是将通过用户查询检索到的内容。嵌入这些文档时,请使用 RETRIEVAL_DOCUMENT 任务类型。您通常只需执行一次此步骤,即可为整个语料库编制索引,然后将生成的嵌入存储在向量数据库中。
接下来,当用户提交搜索内容时,您需要实时生成其查询文本的嵌入。为此,您应使用与用户意图匹配的任务类型。然后,系统将使用此查询嵌入在向量数据库中查找最相似的文档嵌入。
以下任务类型用于查询:
RETRIEVAL_QUERY:如果您想查找相关文档,则使用此任务类型发出标准搜索查询。模型会查找在语义上与查询嵌入相似的文档嵌入。QUESTION_ANSWERING:如果所有查询均为完整问句,例如“为什么天空是蓝色的?”或“如何系鞋带?”,则使用此任务类型。FACT_VERIFICATION:如果您想从语料库中检索一篇用以证实或证伪某个陈述的文档,则使用此任务类型。例如,对于“苹果长在地下”这个查询,系统可能会检索到一篇关于苹果的文章,而该文章最终会证伪此陈述。
请考虑以下真实场景,其中检索查询会很有用:
- 对于电子商务平台,您可以使用嵌入,让用户能够同时使用文本查询和图片来搜索商品,从而提供更直观、更具吸引力的购物体验。
- 对于教育平台,您希望构建一个问答系统,该系统可以根据教科书内容或教育资源回答学生的问题,从而提供个性化的学习体验,并帮助学生理解复杂的概念。
代码检索
text-embedding-005 支持新的任务类型 CODE_RETRIEVAL_QUERY,可用于使用纯文本查询检索相关代码块。如需使用此功能,应使用 RETRIEVAL_DOCUMENT 任务类型嵌入代码块,同时使用 CODE_RETRIEVAL_QUERY 嵌入文本查询。
如需了解所有任务类型,请参阅模型参考。
示例如下:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
评估文本相似度
如果您想使用嵌入来评估文本相似度,请使用 SEMANTIC_SIMILARITY 任务类型。此任务类型会生成经过优化以生成相似度得分的嵌入。
例如,假设您要生成嵌入以用于比较以下文本的相似性:
- 猫在睡觉
- 猫咪在午睡
使用嵌入来创建相似度得分时,相似度得分很高,因为这两段文本的含义几乎相同。
请考虑以下评估输入相似度很有用的真实场景:
- 对于推荐系统,您需要识别与用户偏好内容语义相似的内容(例如产品、文章、电影),以提供个性化推荐并提高用户满意度。
使用这些模型时,存在以下限制:
- 请勿在任务关键型系统或生产系统中使用这些预览版模型。
- 这些模型仅在
us-central1中提供。 - 不支持批量预测。
- 不支持自定义。
后续步骤
- 了解如何获取文本嵌入。