Après avoir développé un agent, vous pouvez utiliser le service d'évaluation de l'IA générative pour évaluer sa capacité à accomplir des tâches et à atteindre des objectifs pour un cas d'utilisation donné.
Définir des métriques d'évaluation
Commencez par une liste vide de métriques (metrics = []) et ajoutez-y les métriques pertinentes. Pour inclure des métriques supplémentaires:
Réponse finale
L'évaluation de la réponse finale suit le même processus que l'évaluation basée sur un modèle. Pour en savoir plus, consultez Définir vos métriques d'évaluation.
Correspondance exacte
metrics.append("trajectory_exact_match")
Si la trajectoire prévue est identique à la trajectoire de référence, avec les mêmes appels d'outils dans le même ordre, la métrique trajectory_exact_match renvoie un score de 1, sinon 0.
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Correspondance dans l'ordre
metrics.append("trajectory_in_order_match")
Si la trajectoire prévue contient tous les appels d'outils de la trajectoire de référence dans le même ordre et peut également contenir des appels d'outils supplémentaires, la métrique trajectory_in_order_match renvoie un score de 1, sinon 0.
Paramètres d'entrée:
predicted_trajectory: trajectoire prévue utilisée par l'agent pour atteindre la réponse finale.reference_trajectory: trajectoire prévue pour que l'agent réponde à la requête.
Correspondance dans n'importe quel ordre
metrics.append("trajectory_any_order_match")
Si la trajectoire prévue contient tous les appels d'outil de la trajectoire de référence, mais que l'ordre n'a pas d'importance et qu'elle peut contenir des appels d'outil supplémentaires, la métrique trajectory_any_order_match renvoie un score de 1, sinon 0.
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Précision
metrics.append("trajectory_precision")
La métrique trajectory_precision mesure le nombre d'appels d'outils dans la trajectoire prévue qui sont réellement pertinents ou corrects par rapport à la trajectoire de référence. Il s'agit d'une valeur float comprise dans la plage [0, 1]: plus le score est élevé, plus la trajectoire prévue est précise.
La précision est calculée comme suit: comptez le nombre d'actions de la trajectoire prévue qui apparaissent également dans la trajectoire de référence. Divisez ce nombre par le nombre total d'actions dans la trajectoire prévue.
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Rappel
metrics.append("trajectory_recall")
La métrique trajectory_recall mesure le nombre d'appels d'outils essentiels de la trajectoire de référence qui sont réellement capturés dans la trajectoire prévue. Il s'agit d'une valeur float comprise dans la plage [0, 1]: plus le score est élevé, meilleur est le rappel de la trajectoire prévue.
Le rappel est calculé comme suit: comptez le nombre d'actions de la trajectoire de référence qui apparaissent également dans la trajectoire prédite. Divisez ce nombre par le nombre total d'actions dans la trajectoire de référence.
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Utilisation d'un seul outil
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
La métrique trajectory_single_tool_use vérifie si un outil spécifique spécifié dans la spécification de la métrique est utilisé dans la trajectoire prévue. Il ne vérifie pas l'ordre des appels d'outils ni le nombre de fois où l'outil est utilisé, mais simplement s'il est présent ou non. Il s'agit de la valeur 0 si l'outil est absent, ou de 1 dans le cas contraire.
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.
Personnalisé
Vous pouvez définir une métrique personnalisée comme suit:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
Les deux métriques de performances suivantes sont toujours incluses dans les résultats. Vous n'avez pas besoin de les spécifier dans EvalTask:
latency(float): temps (en secondes) nécessaire à l'agent pour répondre.failure(bool):0si l'appel de l'agent a réussi,1dans le cas contraire.
Préparer l'ensemble de données d'évaluation
Pour préparer votre ensemble de données à l'évaluation finale de la réponse ou de la trajectoire:
Réponse finale
Le schéma de données pour l'évaluation de la réponse finale est semblable à celui de l'évaluation de la réponse du modèle.
Correspondance exacte
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Correspondance dans l'ordre
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: trajectoire prévue utilisée par l'agent pour atteindre la réponse finale.reference_trajectory: trajectoire prévue pour que l'agent réponde à la requête.
Correspondance dans n'importe quel ordre
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Précision
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Rappel
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.reference_trajectory: utilisation attendue de l'outil pour que l'agent réponde à la requête.
Utilisation d'un seul outil
L'ensemble de données d'évaluation doit fournir les entrées suivantes:
Paramètres d'entrée:
predicted_trajectory: liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale.
À des fins d'illustration, voici un exemple d'ensemble de données d'évaluation.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Exemples d'ensembles de données
Nous avons fourni les exemples d'ensembles de données suivants pour vous montrer comment évaluer les agents:
"on-device": ensemble de données d'évaluation pour un Home Assistant sur l'appareil. L'agent répond aux requêtes telles que "Programmez la climatisation de la chambre pour qu'elle soit allumée entre 23h et 8h, et éteinte le reste du temps.""customer-support": ensemble de données d'évaluation pour un agent du service client. L'agent répond à des questions telles que "Pouvez-vous annuler les commandes en attente et escalader les demandes d'assistance ouvertes ?""content-creation": ensemble de données d'évaluation pour un agent de création de contenu marketing. L'agent peut vous aider à répondre à des requêtes telles que "Reprogrammer la campagne X en tant que campagne ponctuelle sur le site de réseau social Y avec un budget réduit de 50 %, uniquement le 25 décembre 2024".
Pour importer les exemples d'ensembles de données:
Installez et initialisez la CLI
gcloud.Téléchargez l'ensemble de données d'évaluation.
Appareil
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Service client
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Création de contenu
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Charger les exemples d'ensemble de données
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Générer les résultats de l'évaluation
Pour générer les résultats de l'évaluation, exécutez le code suivant:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
Afficher et interpréter les résultats
Les résultats de l'évaluation s'affichent comme suit:
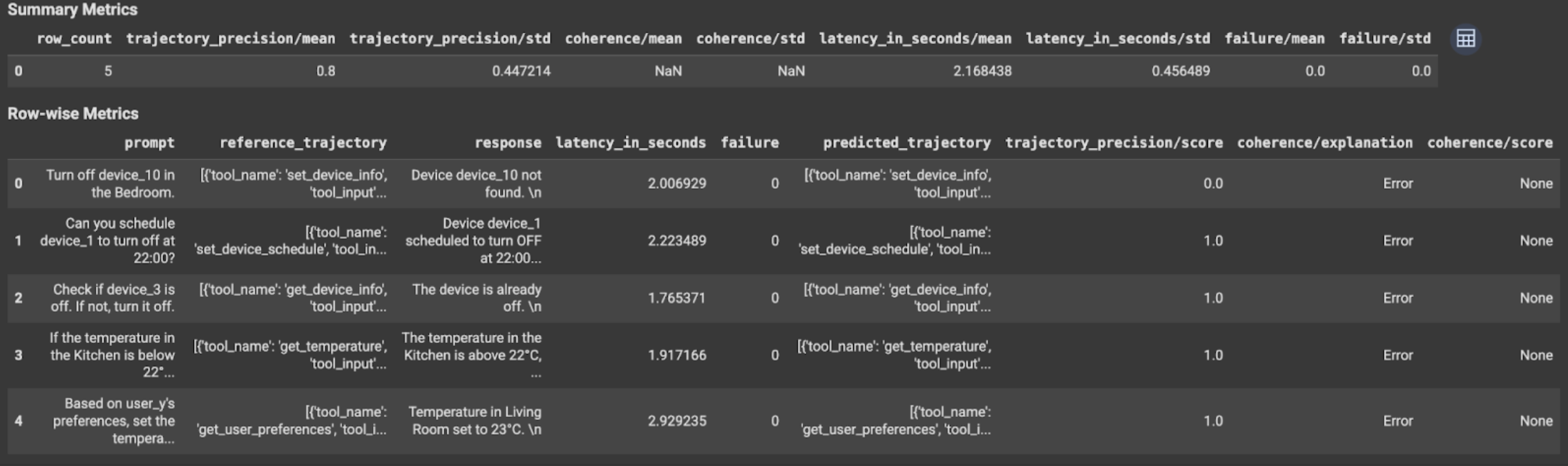
Les résultats de l'évaluation contiennent les informations suivantes:
Métriques de réponse finale
Métriques par ligne:
response: réponse finale générée par l'agent.latency_in_seconds: temps nécessaire (en secondes) pour générer la réponse.failure: indique si une réponse valide a été générée ou non.score: score calculé pour la réponse spécifiée dans la spécification de la métrique.explanation: explication du score spécifié dans la spécification de la métrique.
Métriques récapitulatives:
mean: note moyenne pour toutes les instances.standard deviation: écart type pour tous les scores.
Métriques de trajectoire
Métriques par ligne:
predicted_trajectory: séquence d'appels d'outils suivie par l'agent pour obtenir la réponse finale.reference_trajectory: séquence d'appels d'outils attendus.score: score calculé pour la trajectoire prédite et la trajectoire de référence spécifiées dans la spécification de la métrique.latency_in_seconds: temps nécessaire (en secondes) pour générer la réponse.failure: indique si une réponse valide a été générée ou non.
Métriques récapitulatives:
mean: note moyenne pour toutes les instances.standard deviation: écart type pour tous les scores.
Étape suivante
Essayez les notebooks suivants: