Une fois que vous avez créé et évalué votre modèle d'IA générative, vous pouvez l'utiliser pour créer un agent, comme un chatbot. Le service d'évaluation de l'IA générative vous permet de mesurer la capacité de votre agent à accomplir des tâches et à atteindre des objectifs pour votre cas d'utilisation.
Présentation
Vous disposez des options suivantes pour évaluer votre agent :
Évaluation de la réponse finale : évaluez la sortie finale d'un agent (s'il a atteint ou non son objectif).
Évaluation de la trajectoire : évaluez le chemin (séquence d'appels d'outils) emprunté par l'agent pour obtenir la réponse finale.
Avec le service d'évaluation de l'IA générative, vous pouvez déclencher l'exécution d'un agent et obtenir des métriques pour l'évaluation de la trajectoire et de la réponse finale dans une seule requête du SDK Vertex AI.
Agents acceptés
Le service d'évaluation de l'IA générative est compatible avec les catégories d'agents suivantes :
| Agents acceptés | Description |
|---|---|
| Agent créé avec le modèle d'Agent Engine | Agent Engine (LangChain sur Vertex AI) est une plate-forme Google Cloud sur laquelle vous pouvez déployer et gérer des agents. |
| Agents LangChain créés à l'aide du modèle personnalisable d'Agent Engine | LangChain est une plate-forme Open Source. |
| Fonction d'agent personnalisée | Une fonction d'agent personnalisée est une fonction flexible qui accepte une invite pour l'agent et renvoie une réponse et une trajectoire dans un dictionnaire. |
Définir des métriques pour l'évaluation des agents
Définissez vos métriques pour l'évaluation de la réponse finale ou de la trajectoire :
Évaluation de la réponse finale
L'évaluation des réponses finales suit le même processus que l'évaluation des réponses du modèle. Pour en savoir plus, consultez Définir vos métriques d'évaluation.
Évaluation de la trajectoire
Les métriques suivantes vous aident à évaluer la capacité du modèle à suivre la trajectoire attendue :
Correspondance exacte
Si la trajectoire prédite est identique à la trajectoire de référence, avec exactement les mêmes appels d'outils dans le même ordre, la métrique trajectory_exact_match renvoie un score de 1, sinon 0.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale. |
reference_trajectory |
Utilisation prévue de l'outil par l'agent pour répondre à la requête. |
Scores de sortie
| Valeur | Description |
|---|---|
| 0 | La trajectoire prédite ne correspond pas à la référence. |
| 1 | La trajectoire prédite correspond à la référence. |
Correspondance dans l'ordre
Si la trajectoire prédite contient tous les appels d'outil de la trajectoire de référence dans le même ordre et peut également comporter des appels d'outil supplémentaires, la métrique trajectory_in_order_match renvoie un score de 1, sinon 0.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Trajectoire prédite utilisée par l'agent pour atteindre la réponse finale. |
reference_trajectory |
Trajectoire prédite attendue pour que l'agent réponde à la requête. |
Scores de sortie
| Valeur | Description |
|---|---|
| 0 | Les appels d'outils dans la trajectoire prédite ne correspondent pas à l'ordre de la trajectoire de référence. |
| 1 | La trajectoire prédite correspond à la référence. |
Correspondance dans n'importe quel ordre
Si la trajectoire prédite contient tous les appels d'outils de la trajectoire de référence, mais que l'ordre n'a pas d'importance et qu'elle peut contenir des appels d'outils supplémentaires, la métrique trajectory_any_order_match renvoie un score de 1, sinon 0.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale. |
reference_trajectory |
Utilisation prévue de l'outil par l'agent pour répondre à la requête. |
Scores de sortie
| Valeur | Description |
|---|---|
| 0 | La trajectoire prédite ne contient pas tous les appels d'outils de la trajectoire de référence. |
| 1 | La trajectoire prédite correspond à la référence. |
Précision
La métrique trajectory_precision mesure le nombre d'appels d'outils dans la trajectoire prédite qui sont réellement pertinents ou corrects par rapport à la trajectoire de référence.
La précision est calculée comme suit : comptez le nombre d'actions de la trajectoire prédite qui apparaissent également dans la trajectoire de référence. Divisez ce nombre par le nombre total d'actions dans la trajectoire prédite.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale. |
reference_trajectory |
Utilisation prévue de l'outil par l'agent pour répondre à la requête. |
Scores de sortie
| Valeur | Description |
|---|---|
| Valeur flottante comprise dans la plage de [0,1] | Plus le score est élevé, plus la trajectoire prédite est précise. |
Rappel
La métrique trajectory_recall mesure le nombre d'appels d'outils essentiels de la trajectoire de référence qui sont réellement capturés dans la trajectoire prédite.
Le rappel est calculé comme suit : comptez le nombre d'actions de la trajectoire de référence qui apparaissent également dans la trajectoire prédite. Divisez ce nombre par le nombre total d'actions dans la trajectoire de référence.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale. |
reference_trajectory |
Utilisation prévue de l'outil par l'agent pour répondre à la requête. |
Scores de sortie
| Valeur | Description |
|---|---|
| Valeur flottante comprise dans la plage de [0,1] | Plus le score est élevé, plus la trajectoire prédite a un bon rappel. |
Utilisation d'un seul outil
La métrique trajectory_single_tool_use vérifie si un outil spécifique indiqué dans la spécification de la métrique est utilisé dans la trajectoire prédite. Il ne vérifie pas l'ordre des appels d'outils ni le nombre de fois où l'outil est utilisé, mais seulement s'il est présent ou non.
Paramètres d'entrée des métriques
| Paramètre d'entrée | Description |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par l'agent pour obtenir la réponse finale. |
Scores de sortie
| Valeur | Description |
|---|---|
| 0 | L'outil est absent |
| 1 | L'outil est présent. |
De plus, les deux métriques de performances des agents suivantes sont ajoutées aux résultats de l'évaluation par défaut. Vous n'avez pas besoin de les spécifier dans EvalTask.
latency
Temps nécessaire à l'agent pour renvoyer une réponse.
| Valeur | Description |
|---|---|
| Un nombre à virgule flottante | Calculée en secondes. |
failure
Booléen indiquant si l'appel de l'agent a généré une erreur ou a réussi.
Scores de sortie
| Valeur | Description |
|---|---|
| 1 | Erreur |
| 0 | Réponse valide renvoyée |
Préparer votre ensemble de données pour l'évaluation de l'agent
Préparez votre ensemble de données pour l'évaluation de la réponse finale ou de la trajectoire.
Le schéma de données pour l'évaluation des réponses finales est semblable à celui de l'évaluation des réponses du modèle.
Pour l'évaluation de trajectoires basée sur des calculs, votre ensemble de données doit fournir les informations suivantes :
| Type d'entrée | Contenu du champ de saisie |
|---|---|
predicted_trajectory |
Liste des appels d'outils utilisés par les agents pour obtenir la réponse finale. |
reference_trajectory (non obligatoire pour trajectory_single_tool_use metric) |
Utilisation prévue de l'outil par l'agent pour répondre à la requête. |
Exemples d'ensembles de données d'évaluation
Les exemples suivants montrent des ensembles de données pour l'évaluation des trajectoires. Notez que reference_trajectory est obligatoire pour toutes les métriques, à l'exception de trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Importer votre ensemble de données d'évaluation
Vous pouvez importer votre ensemble de données dans les formats suivants:
Fichier JSONL ou CSV stocké dans Cloud Storage
Table BigQuery
DataFrame Pandas
Le service d'évaluation de l'IA générative fournit des exemples d'ensembles de données publics pour vous montrer comment évaluer vos agents. Le code suivant montre comment importer les ensembles de données publics à partir d'un bucket Cloud Storage :
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
où dataset est l'un des ensembles de données publics suivants :
"on-device"pour un Assistant pour la maison sur l'appareil, qui contrôle les appareils de la maison. L'agent aide à répondre à des requêtes telles que "Programme la climatisation de la chambre pour qu'elle soit allumée entre 23h et 8h, et éteinte le reste du temps"."customer-support"pour parler à un agent de l'assistance client. L'agent répond aux questions telles que "Pouvez-vous annuler les commandes en attente et escalader les demandes d'assistance ouvertes ?""content-creation"pour un agent de création de contenu marketing. L'agent aide à répondre à des requêtes telles que "Reprogramme la campagne X pour qu'elle soit diffusée une seule fois sur le site de réseaux sociaux Y avec un budget réduit de 50 %, uniquement le 25 décembre 2024".
Exécuter l'évaluation de l'agent
Exécutez une évaluation pour évaluer la trajectoire ou la réponse finale :
Pour l'évaluation des agents, vous pouvez combiner des métriques d'évaluation des réponses et des métriques d'évaluation des trajectoires, comme dans le code suivant :
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Personnalisation des métriques
Vous pouvez personnaliser une métrique basée sur un grand modèle linguistique pour l'évaluation de trajectoires à l'aide d'une interface de modèle ou à partir de zéro. Pour en savoir plus, consultez la section sur les métriques basées sur un modèle. Voici un exemple de modèle :
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Vous pouvez également définir une métrique personnalisée basée sur des calculs pour évaluer la trajectoire ou la réponse, comme suit :
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Afficher et interpréter les résultats
Pour l'évaluation de la trajectoire ou de la réponse finale, les résultats de l'évaluation s'affichent comme suit :
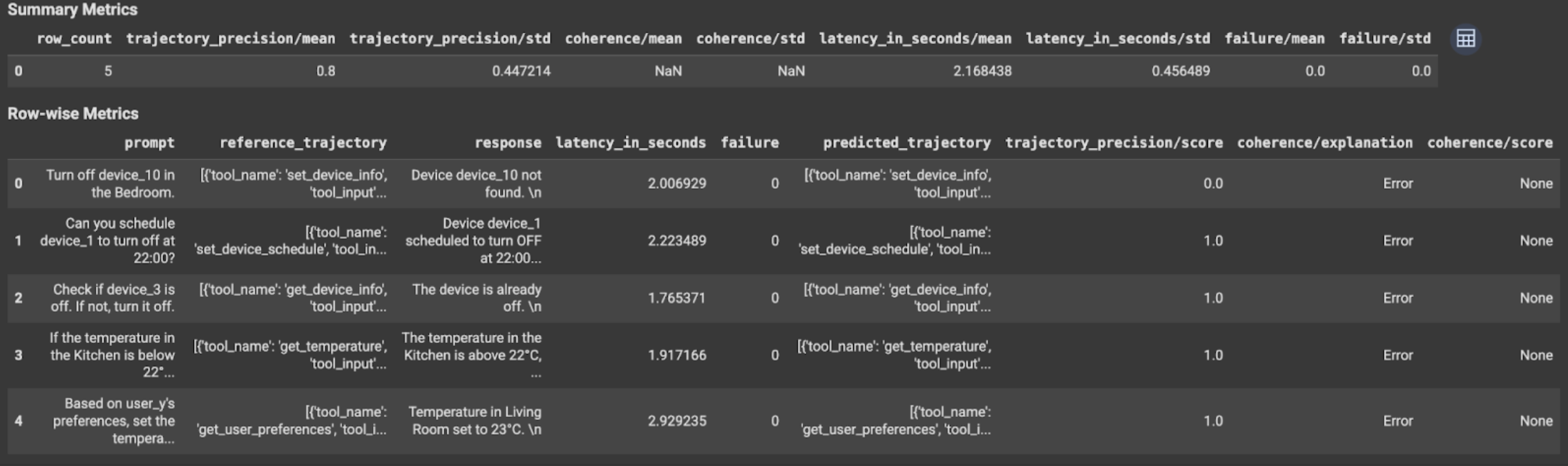
Les résultats de l'évaluation contiennent les informations suivantes :
Métriques de réponse finale
Résultats au niveau de l'instance
| Colonne | Description |
|---|---|
| réponse | Réponse finale générée par l'agent. |
| latency_in_seconds | Temps nécessaire pour générer la réponse. |
| échec | Indique si une réponse valide a été générée ou non. |
| score | Score calculé pour la réponse spécifiée dans la spécification de métrique. |
| Explication | Explication du score spécifié dans la spécification de la métrique. |
Résultats cumulés
| Colonne | Description |
|---|---|
| mean | Score moyen pour toutes les instances. |
| Écart type | Écart type pour tous les scores. |
Métriques de trajectoire
Résultats au niveau de l'instance
| Colonne | Description |
|---|---|
| predicted_trajectory | Séquence d'appels d'outils suivis par l'agent pour obtenir la réponse finale. |
| reference_trajectory | Séquence des appels d'outils attendus. |
| score | Score calculé pour la trajectoire prédite et la trajectoire de référence spécifiées dans la spécification de métrique. |
| latency_in_seconds | Temps nécessaire pour générer la réponse. |
| échec | Indique si une réponse valide a été générée ou non. |
Résultats cumulés
| Colonne | Description |
|---|---|
| mean | Score moyen pour toutes les instances. |
| Écart type | Écart type pour tous les scores. |
Protocole Agent2Agent (A2A)
Si vous créez un système multi-agents, nous vous recommandons vivement de consulter le protocole A2A. Le protocole A2A est une norme ouverte qui permet une communication et une collaboration fluides entre les agents d'IA, quels que soient leurs frameworks sous-jacents. Il a été donné par Google Cloud à la Linux Foundation en juin 2025. Pour utiliser les SDK A2A ou essayer les exemples, consultez le dépôt GitHub.
Étapes suivantes
Essayez les notebooks d'évaluation d'agent suivants :