Mit Sammlungen den Überblick behalten
Sie können Inhalte basierend auf Ihren Einstellungen speichern und kategorisieren.
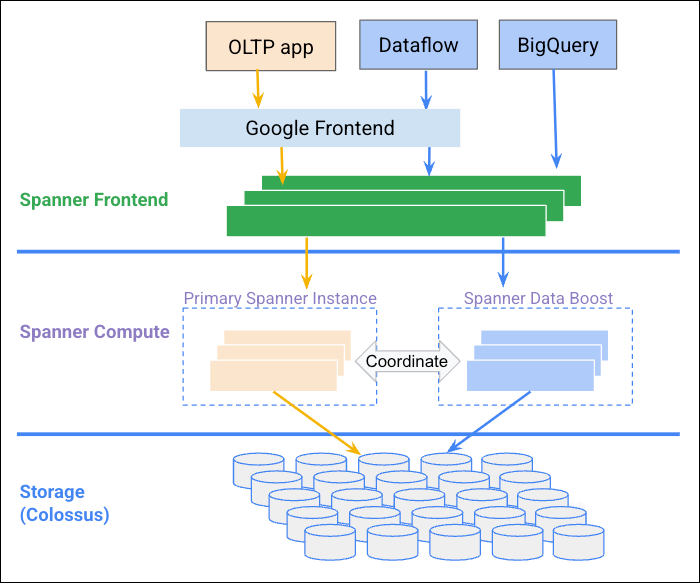
Spanner Data Boost ist ein vollständig verwalteter, serverloser Dienst, der unabhängige Rechenressourcen für unterstützte Spanner-Arbeitslasten bereitstellt.
Mit Data Boost können Sie Analyseabfragen und Datenexporte nahezu ohne Auswirkungen auf vorhandene Arbeitslasten auf der bereitgestellten Spanner-Instanz ausführen. Der Dienst besteht aus Spanner-Clustern, die von Google auf regionaler Ebene verwaltet werden. Bei geeigneten Abfragen, für die Data Boost angefordert wird, leitet Spanner die Arbeitslast transparent an diese Server weiter. Geeignete Abfragen sind solche, bei denen der erste Operator im Abfrageausführungsplan eine verteilte Union ist. Diese Abfragen müssen nicht geändert werden, um Data Boost zu nutzen.
Data Boost ist am wirkungsvollsten in den folgenden Fällen, in denen Sie negative Auswirkungen auf das vorhandene Transaktionssystem aufgrund von Ressourcenkonflikten vermeiden möchten:
Ad-hoc- oder seltene Abfragen, bei denen große Datenmengen verarbeitet werden.
Ein typisches Beispiel ist eine föderierte Abfrage von BigQuery nach Spanner.
Jobs für Berichte oder Datenexporte Ein Beispiel ist ein Dataflow-Job zum Exportieren von Spanner-Daten in Cloud Storage.
Das folgende Diagramm zeigt, wie Data Boost mit der Spanner-Instanz koordiniert wird, um unabhängige Rechenressourcen bereitzustellen.
Vorteile
Data Boost bietet folgende Vorteile:
Bietet Arbeitslastisolierung. Sie können unterstützte Abfragen auf die neuesten Daten ausführen, ohne dass sich dies auf vorhandene transaktionale Arbeitslasten auswirkt – unabhängig von der Abfragekomplexität oder der verarbeiteten Datenmenge.
Bietet eine gleichwertige oder bessere Latenz.
Verhindert die Überprovisionierung von Spanner-Instanzen nur zur Unterstützung gelegentlicher Analyseabfragen.
Bietet eine hohe Skalierbarkeit mit größerer Abfrageparallelität, die sich elastisch bei Spitzenlasten skaliert.
Bietet umfassende Messwerte, mit denen Administratoren die teuersten Abfragen ermitteln und die zu optimierende Kostenkomponente bestimmen können.
Administratoren können dann die Auswirkungen ihrer Optimierungen prüfen, indem sie den Verbrauch der serverlosen Verarbeitungseinheit der Abfrage bei der nächsten Ausführung beobachten.
Erfordert keinen zusätzlichen Betriebsaufwand. Es muss kein zusätzlicher Dienst verwaltet werden, es gibt keine Kapazitätsplanung oder Bereitstellung, Sie müssen nicht auf die Skalierung warten und es ist keine Wartung erforderlich.
Berechtigungen
Alle Hauptkonten, die eine Abfrage oder einen Export ausführen, für die der Daten-Boost angefordert wird, benötigen die IAM-Berechtigung (Identity and Access Management) spanner.databases.useDataBoost. Wir empfehlen die IAM-Rolle Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Abrechnung und Kontingente
Sie zahlen nur für die tatsächlichen Verarbeitungseinheiten, die von Abfragen verwendet werden, die mit Data Boost ausgeführt werden. Administratoren können Limits für die Nutzung festlegen, um Kostenüberschreitungen zu vermeiden.
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-08-11 (UTC)."],[],[],null,["# Data Boost overview\n\nSpanner Data Boost is a fully managed, serverless service that provides\nindependent compute resources for supported Spanner workloads.\nData Boost lets you execute analytics queries and data exports\nwith near-zero impact to existing workloads on the provisioned\nSpanner instance. The service consists of Spanner\nclusters that Google manages at the region level. For eligible queries that\nrequest Data Boost, Spanner routes the workload to\nthese servers transparently. Eligible queries are those for which the first\noperator in the query execution plan is a distributed union. These queries don't\nhave to change to take advantage of Data Boost.\n\nData Boost is most impactful in the following scenarios where you\nwant to avoid negative impacts to the existing transactional system due to\nresource contention:\n\n- Ad hoc or infrequent queries that involve processing large amounts of data. A typical example is a [federated\n query](/bigquery/docs/spanner-federated-queries) from BigQuery to Spanner.\n- Reporting or data export jobs. An example is a Dataflow job to export Spanner data to Cloud Storage.\n\nThe following diagram illustrates how Data Boost coordinates with\nthe Spanner instance to provide independent compute resources.\n\nBenefits\n--------\n\nData Boost offers the following benefits:\n\n- Provides workload isolation. You can run supported queries against the latest data with near-zero impact on existing transactional workloads regardless of query complexity or amount of data processed.\n- Provides equal or better latency.\n- Prevents over-provisioning of Spanner instances just to support occasional analytics queries.\n- Offers a high degree of scalability with greater query parallelism that scales elastically with burst loads.\n- Provides comprehensive metrics, which let administrators identify the most expensive queries and determine the cost component to optimize. Administrators can then verify the impact of their optimizations by monitoring the query's serverless processing unit consumption in its next execution.\n- Requires no additional operational overhead. There is no extra service to manage, no capacity planning or provisioning, no need to wait for scaling, and no maintenance.\n\nPermissions\n-----------\n\nAny principal that runs a query or export that requests Data Boost\nmust have the `spanner.databases.useDataBoost` Identity and Access Management (IAM)\npermission. We recommend that you use the\n`Cloud Spanner Database Reader With DataBoost` (`roles/spanner.databaseReaderWithDataBoost`)\nIAM role.\n\nBilling and quotas\n------------------\n\nYou pay only for actual processing units used by queries that run on\nData Boost. Administrators can set limits on usage to avoid cost\noverruns.\n\nWhat's next\n-----------\n\n- [Run federated queries with Data Boost](/spanner/docs/databoost/databoost-run-queries)\n- [Export data with Data Boost](/spanner/docs/databoost/databoost-export)\n- [Use Data Boost in your applications](/spanner/docs/databoost/databoost-applications)\n- [Monitor Data Boost usage](/spanner/docs/databoost/databoost-monitor)\n- [Monitor and manage Data Boost quota usage](/spanner/docs/databoost/databoost-quotas)"]]