This page describes various ways to implement multi-tenancy in Spanner. It also discusses data management patterns and tenant lifecycle management. It is intended for database architects, data architects, and engineers that implement multi-tenant applications on Spanner as their relational database. Using that context, it outlines various approaches to store multi-tenant data. The terms "tenant", "customer", and "organization" are used interchangeably throughout the article to indicate the entity that's accessing the multi-tenant application. The examples provided on this page are based on a human resources (HR) SaaS provider's implementation of its multi-tenant application on Google Cloud. One requirement is that several customers of the HR SaaS provider must access the multi-tenant application. These customers are called tenants.
Multi-tenancy
Multi-tenancy is when a single instance, or a few instances, of a software application serves multiple tenants or customers. This software pattern can scale from a single tenant or customer to hundreds or thousands. This approach is fundamental to cloud computing platforms where the underlying infrastructure is shared among multiple organizations.
Think of multi-tenancy as a form of partitioning based on shared computing resources, like databases. An analogy is tenants in an apartment building: the tenants share the infrastructure, such as water pipes and electrical lines, but each tenant has dedicated tenant space in an apartment. Multi-tenancy is part of most, if not all, software-as-a-service (SaaS) applications.
Spanner is Google Cloud's fully managed, enterprise-grade, distributed, and consistent database which combines the benefits of the relational database model with non-relational horizontal scalability. Spanner has relational semantics with schemas, enforced data types, strong consistency, multi-statement ACID transactions, and a SQL query language implementing ANSI 2011 SQL. It provides zero-downtime for planned maintenance or region failures, with an availability SLA of 99.999%. Spanner also supports modern, multi-tenant applications by providing high availability and scalability.
Criteria for tenant data-mapping criteria
In a multi-tenant application, each tenant's data is isolated in one of several architecture approaches in the underlying Spanner database. The following list outlines the different architecture approaches used to map a tenant's data to Spanner:
- Instance: A tenant resides exclusively in one Spanner instance, with exactly one database for that tenant.
- Database: A tenant resides in a database in a single Spanner instance containing multiple databases.
- Table: A tenant resides in exclusive tables within a database, and several tenants can be located in the same database.
- Row: Tenant data are rows in database tables. Those tables are shared with other tenants.
The preceding criteria are called data management patterns and are discussed in detail in the Multi-tenancy data management patterns section. That discussion is based on the following criteria:
- Data isolation: The degree of data isolation across multiple tenants is a major consideration for multi-tenancy. For example, whether data needs to be physically or logically separated, and whether there are independent ACLs (Access Control Lists) that can be set for each tenant's data. Isolation is driven by the choices made for the criteria under other categories. For example, certain regulatory and compliance requirements might dictate a greater degree of isolation.
- Agility: The ease of onboarding and offboarding activities for a tenant with respect to creating an instance, database, table, or row.
- Operations: The availability or complexity of implementing typical, tenant-specific, database operations, and administration activities. For example, regular maintenance, logging, backups, or disaster recovery operations.
- Scale: The ability to scale seamlessly to allow for future growth. The description of each pattern contains the number of tenants the pattern can support.
- Performance:
- Resource isolation: The ability to allocate exclusive resources to each tenant, address the noisy neighbor phenomenon, and enable predictable read and write performance for each tenant.
- Minimum resources per tenant: The average minimum amount of resources per tenant. This doesn't necessarily mean that you need to pay at least this amount for each individual tenant, but rather you need to pay at least N * this amount for all the N tenants together.
- Resource efficiency: The ability to use idle resources of other tenants to save overall cost.
- Location selection for latency optimization: The ability to pick specific replication topology for each tenant so that the data for each tenant can be placed in the location that provides the best latency for the tenant.
- Regulations and compliance: The ability to address the requirements of highly regulated industries and countries that require the complete isolation of resources and maintenance operations. For example, data residency requirements for France require that personally identifiable information is physically stored exclusively within France. Financial industries usually require customer-managed encryption keys (CMEK), and each tenant might want to use its own encryption key.
Each data management pattern as it relates to these criteria is detailed in the next section. Use the same criteria when selecting a data management pattern for a specific set of tenants.
Multi-tenancy data management patterns
The following sections describe the four main data management patterns: instance, database, table, and row.
Instance
To provide complete isolation, the instance data management pattern stores each tenant's data in its own Spanner instance and database. A Spanner instance can have one or more databases. In this pattern, only one database is created. For the HR application discussed earlier, a separate Spanner instance with one database is created for each customer organization.
As seen in the following diagram, the data management pattern has one tenant per instance.
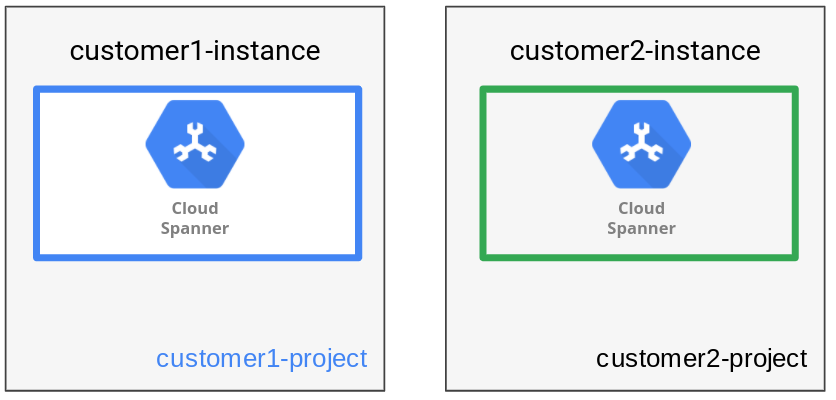
Having separate instances for each tenant allows the use of separate Google Cloud projects to achieve separate trust boundaries for different tenants. An extra benefit is that each instance configuration can be chosen based on each tenant's location (either regionally or multi-regionally), optimizing location flexibility and performance.
The architecture can scale to any number of tenants. SaaS providers can create any number of instances in the wanted regions, without any hard limits.
The following table outlines how the instance data management pattern affects different criteria.
| Criteria | Instance — one tenant per instance data management pattern |
|---|---|
| Data isolation |
|
| Agility |
|
| Operations |
|
| Scale |
|
| Performance |
|
| Regulatory and compliance requirements |
|
In summary, the key takeaways are:
- Advantage: Highest level of isolation
- Disadvantage: Greatest operational overhead and potentially higher cost due to the 100 PU minimum per tenant. Sharing resources across tenants is unsupported.
The instance data management pattern is best suited for the following scenarios:
- Different tenants are spread across a wide range of regions and need a localized solution.
- Regulatory and compliance requirements for some tenants demand greater levels of security and auditing protocols.
- Tenant size varies significantly, such that sharing resources among high-volume, high-traffic tenants might cause contention and mutual degradation.
Database
In the database data management pattern, each tenant resides in a database within a single Spanner instance. Multiple databases can reside in a single instance. If one instance is insufficient for the number of tenants, create multiple instances. This pattern implies that a single Spanner instance is shared among multiple tenants.
Spanner has a hard limit of 100 databases per instance. This limit means that if the SaaS provider needs to scale beyond 100 customers, they need to create and use multiple Spanner instances.
For the HR application, the SaaS provider creates and manages each tenant with a separate database in a Spanner instance.
As seen in the following diagram, the data management pattern has one tenant per database.
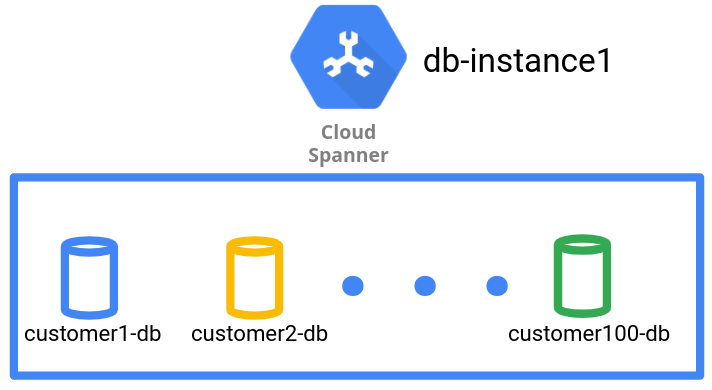
The database data management pattern achieves logical isolation on a database level for different tenants' data. However, because it's a single Spanner instance, all the tenant databases share the same replication topology and underlying compute and storage setup unless the geo-partitioning feature is used. You can use the Spanner geo-partitioning feature to create instance partitions in different locations and use different instance partitions for different databases in the same instance.
The following table outlines how the database data management pattern affects different criteria.
| Criteria | Database — one tenant per database data management pattern |
|---|---|
| Data isolation |
|
| Agility |
|
| Operations |
|
| Scale |
|
| Performance |
|
| Regulatory and compliance requirements |
|
In summary, the key takeaways are:
- Advantage: Moderate level of data isolation, and resource isolation; moderate level of resource efficiency; each tenant can have its own backup and CMEK.
- Disadvantage: Limited number of tenants per instance; location inflexibility if not using the geo-partitioning feature.
The database data management pattern is best suited for the following scenarios:
- Multiple customers are in the same data residency or are under the same regulatory authority.
- Tenants require system-based data separation and the ability to backup and restore their data, but are fine with infrastructure resource sharing.
- Tenants require their own CMEK.
- Cost is an important consideration. The minimum resources needed per tenant are less than the cost of an instance. It is desirable for tenants to use the idle resources of other tenants.
Table
In the table data management pattern, a single database, which implements a
single schema, is used for multiple tenants and a separate set of tables is used
for each tenant's data. These tables can be differentiated by including the
tenant ID in the table names as either a prefix, a suffix, or as
named schemas.
This data management pattern of using a separate set of tables for each tenant provides a much lower level of isolation compared to the preceding options (the instance and database management patterns). Onboarding involves creating new tables and associated referential integrity and indexes.
There's a limit of 5,000 tables per database. For some customers, that limit might restrict their use of the application.
Furthermore, using separate tables for each customer can result in a large backlog of schema update operations. Such a backlog takes a long time to resolve.
For the HR application, the SaaS provider can create a set of tables for each
customer with tenant ID as the prefix in the table names. For example,
customer1_employee, customer1_payroll, and customer1_department.
Alternatively, they can use tenant ID as a named schema and name their table as
customer1.employee, customer1.payroll, and customer1.department.
As seen in the following diagram, the table data management pattern has one set of tables for each tenant.
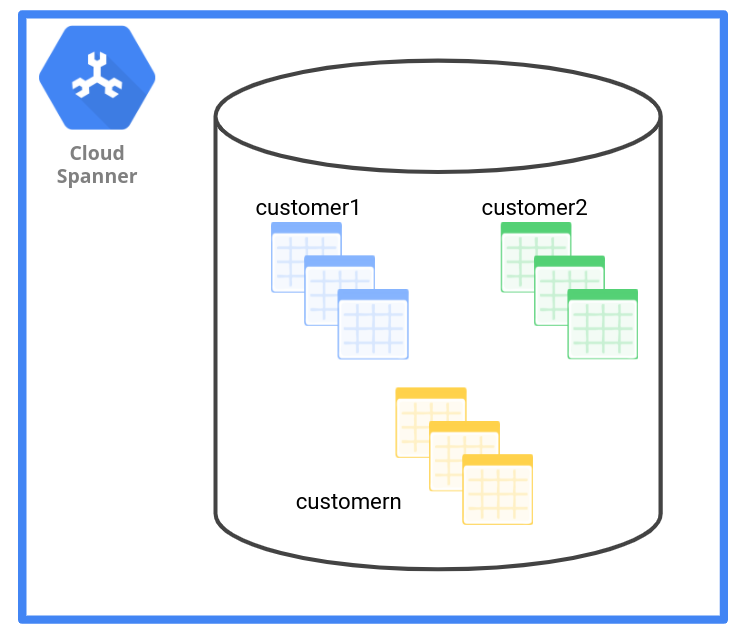
The following table outlines how the table data management pattern affects different criteria.
| Criteria | Table — one set of tables for each tenant data management pattern |
|---|---|
| Data isolation |
|
| Agility |
|
| Operations |
|
| Scale |
|
| Performance |
|
| Regulatory and compliance requirements |
|
In summary, the key takeaways are:
- Advantage: Moderate level of scalability and resource efficiency.
- Disadvantage:
- Moderate level of data isolation, and resource isolation.
- Location inflexibility if not using the new geo-partitioning feature.
- Inability to separately monitor tenants. The only available table level resource consumption info is table size statistics.
- Tenants can't have their own CMEK and backups.
The table data management pattern is best suited for the following scenarios:
- Multi-tenant applications that doesn't legally require data separation, but you want logical separation and security control.
- Cost is an important consideration. The minimum per tenant cost is cheaper than per database cost.
Row
The final data management pattern serves multiple tenants with a common set of
tables, with each row belonging to a specific tenant. This data management pattern
represents an extreme level of multi-tenancy where everything—from
infrastructure to schema to data model—is shared among multiple tenants. Within
a table, rows are partitioned based on primary keys, with tenant ID as the
first element of the key. From a scaling perspective, Spanner
supports this pattern best because it can scale tables without limitation.
For the HR application, the payroll table's primary key can be a combination of
customerID and payrollID.
As seen in the following diagram, the row data management pattern has one table for several tenants.

Unlike all the other patterns, data access in the row pattern can't be controlled separately for different tenants. Using fewer tables means schema update operations complete faster when each tenant has their own database tables. To a large extent, this approach simplifies onboarding, offboarding, and operations.
The following table outlines how the row data management pattern affects different criteria.
| Criteria | Row — one set of rows for each tenant data management pattern |
|---|---|
| Data isolation |
|
| Agility |
|
| Operations |
|
| Scale |
|
| Performance |
|
| Regulatory and compliance requirements |
|
In summary, the key takeaways are:
- Advantage: Highly scalable; has low operational overhead; simplified schema management.
- Disadvantage: High resource contention; lack of security controls and monitoring for each tenant.
This pattern is best suited for the following scenarios:
- Internal applications that cater to different departments where strict data security isolation isn't a prominent concern when compared to ease of maintenance.
- Maximum resource sharing for tenants using free-tier application when minimizing resource provisioning at the same time.
Data management patterns and tenant lifecycle management
The following table compares the various data management patterns across all criteria at a high level.
| Instance | Database | Table | Row | |
|---|---|---|---|---|
| Data isolation | Complete | High | Moderate | Low |
| Agility | Low | Moderate | Moderate | Highest |
| Ease of operations | High | High | Low | Low |
| Scale | High | Limited (unless using additional instances when reaching limit) | Limited (unless using additional databases when reaching limit) | Highest |
| Performance1 - Resource isolation | High | Low | Low | Low |
| Performance1 - Minimum resources per tenant | High | Moderate High | Moderate | No minimum per tenant |
| Performance1 - Resource efficiency | Low | High | High | High |
| Performance1 - Location selection for latency optimization | High | Moderate | Moderate | Moderate |
| Regulations and compliance | Highest | High | Moderate | Low |
1 Performance is heavily dependent on the schema design and query best practices. The values here are only an average expectation.
The best data management patterns for a specific multi-tenant application are those that satisfy most of its requirements based on the criteria. If a particular criterion isn't required, you can ignore the row it's in.
Combined data management patterns
Often, a single data management pattern is sufficient to address the requirements of a multi-tenant application. When that's the case, the design can assume a single data management pattern.
Some multi-tenant applications require several data management patterns at the same time. For example, a multi-tenant application that supports a free tier, a regular tier, and an enterprise tier.
Free tier:
- Must be cost effective
- Must have an upper data-volume limit
- Usually supports limited features
- The row data management pattern is a good free-tier candidate
- Tenant management is straightforward
- No need to create specific or exclusive tenant resources
Regular tier:
- Good for paying clients who have no specifically strong scaling or isolation requirements.
- The table data management pattern or the database data management
pattern is a good regular-tier candidate:
- Tables and indexes are exclusive for the tenant.
- Backup is straightforward in the database data management pattern
- Backup isn't supported for the table data management pattern.
- Tenant backup must be implemented as a utility outside Spanner.
Enterprise tier:
- Usually a high-end tier with full autonomy in all aspects.
- Tenant has dedicated resources that include dedicated scaling and full isolation.
- The instance data management pattern is well suited for the enterprise tier.
A best practice is to keep different data management patterns in different databases. While it's possible to combine different data management patterns in a Spanner database, doing so makes it difficult to implement the application's access logic and lifecycle operations.
The Application design section outlines some multi-tenant application design considerations that apply when using a single data management pattern or several data management patterns.
Manage the tenant lifecycle
Tenants have a lifecycle. Therefore, you must implement the corresponding management operations within your multi-tenant application. Beyond the basic operations of creating, updating, and deleting tenants, consider the following additional data-related operations:
Export tenant data:
- When deleting a tenant, it's a best practice to export their data first and possibly make the dataset available to them.
- When using the row or table data management pattern, the multi-tenant application system must implement the export or map it to the database feature (database export), and implement custom logic to take the portion of the data that corresponds to the tenant out.
Back up tenant data:
- When using the instance or database data management pattern and backing up data for individual tenants, use the database's export or backup functions.
- When using the table or row data management pattern and backing up data for individual tenants, the multi-tenant application must implement this operation. The Spanner database can't determine which data belongs to which tenant.
Move tenant data:
Moving a tenant from one data management pattern to another (or moving a tenant within the same data management pattern between instances or databases) requires extracting the data from one data management pattern and inserting that data into the new data management pattern.
- When application downtime is possible, perform an export/import.
- When downtime isn't possible, perform a zero downtime database migration.
Mitigating a noisy-neighbor situation is another reason to move tenants.
Application design
When designing a multi-tenant application, implement tenant-aware business logic. That means each time the application runs business logic, it must always be in the context of a known tenant.
From a database perspective, application design means that each query must be run against the data management pattern in which the tenant resides. The following sections highlight some of the central concepts of multi-tenant application design.
Dynamic tenant connection and query configuration
Dynamically mapping tenant data to tenant application requests uses a mapping configuration:
- For database data management patterns or instance data management patterns, a connection string is sufficient to access a tenant's data.
- For table data management patterns, the correct table names have to be determined.
- For row data management patterns, use the appropriate predicates to retrieve a specific tenant's data.
A tenant can reside in any of the four data management patterns. The following mapping implementation addresses a connection configuration for the general case of a multi-tenant application that uses all the data management patterns at the same time. When a given tenant resides in one pattern, some multi-tenant applications use one data management pattern for all tenants. This case is covered implicitly by the following mapping.
If a tenant executes business logic (for example, an employee logging in with their tenant ID) then the application logic must determine the tenant's data management pattern, the location of the data for a given tenant ID, and, optionally, the table-naming convention (for the table pattern).
This application logic requires tenant-to-data-management pattern mapping. In
the following code sample, the connection string refers to the database where
the tenant data resides. The sample identifies the Spanner
instance and the database. For the data management pattern instance and
database, the following code is sufficient for the application to connect and
execute queries:
tenant id -> (data management pattern,
database connection string)
Additional design is required for the table and row data management patterns.
Table data management pattern
For the table data management pattern, there are several tenants within the same database. Each tenant has its own set of tables. The tables are distinguished by their name. Which table belongs to which tenant is deterministic.
One approach is to place each tenant's table in a namespace named after the
tenant, and fully qualify your table name with
namespace.name. For example, you put
an EMPLOYEE table inside the namespace T356 for the tenant with the ID
356, and your application can use T356.EMPLOYEE to address the requests
to the table.
Another approach is to prepend the table names with the tenant ID. For example,
the EMPLOYEE table is called T356_EMPLOYEE for the tenant with the ID 356.
The application has to prepend each table with the prefix tenant
ID before sending the query to the database that the mapping returned.
If you want to use some other text instead of the tenant ID, you can maintain a mapping from the tenant ID to the named schema namespace or to the table prefix.
To simplify the application logic, you might introduce one level of indirection. For example, you can use a common library with your application to automatically attach the namespace or table prefix for the call from the tenant.
Row data management pattern
A similar design is required for the row data management pattern. In this pattern, there's a single schema. Tenant data are stored as rows. To properly access the data, append a predicate to each query to select the appropriate tenant.
One approach to find the appropriate tenant is to have a column called TENANT
in each table. For better data isolation, this column value should be part of
the primary key. The column value is tenant ID. Each query must append a
predicate AND TENANT = tenant ID to an existing WHERE
clause or add a WHERE clause with the predicate AND TENANT = tenant
ID.
To connect to the database and to create the proper queries, the tenant identifier must be available in the application logic. It can be passed in as parameter or stored as thread context.
Some lifecycle operations require you to modify the tenant-to-data-management-pattern mapping configuration—for example, when you move a tenant between data management patterns, you must update the data management pattern and the database connection string. You might also have to update the table prefix.
Query generation and attribution
A fundamental underlying principle of multi-tenant applications is that several tenants can share a single cloud resource. The preceding data management patterns fall into this category, except for the case where a single tenant is allocated to a single Spanner instance.
The sharing of resources goes beyond sharing data. Monitoring and logging is also shared. For example, in the table data management pattern and row data management pattern, all queries for all tenants are recorded in the same audit log.
If a query is logged, then the query text has to be examined to determine which tenant the query was executed for. In the row data management pattern, you must parse the predicate. In the table data management pattern, you must parse one of the table names.
In the database data management pattern or the instance data management pattern, the query text doesn't have any tenant information. To get tenant information for these patterns, you must query the tenant-to-data-management-pattern mapping table.
It would be easier to analyze logs and queries by determining the tenant for a
given query without parsing the query text. One way to uniformly identify a
tenant for a query across all data management patterns is to add a comment to
the query text that has the tenant ID, and (optionally) a label.
The following query selects all employee data for the tenant identified by
TENANT 356. To avoid parsing the SQL syntax and extracting the tenant ID from
the predicate, the tenant ID is added as a comment. A comment can be extracted
without having to parse the SQL syntax.
SELECT * FROM EMPLOYEE
-- TENANT 356
WHERE TENANT = 'T356';
or
SELECT * FROM T356_EMPLOYEE;
-- TENANT 356
With this design, every query run for a tenant is attributed to that tenant independent of the data management pattern. If a tenant is moved from one data management pattern to another, the query text might change, but the attribution remains the same in the query text.
The preceding code sample is only one method. Another method is to insert a JSON object as a comment instead of a label and value:
SELECT * FROM T356_EMPLOYEE;
-- {"TENANT": 356}
You can also use tags
to attribute queries to tenants, and view the statistics in the built-in
spanner_sys tables.
Tenant access lifecycle operations
Depending on your design philosophy, a multi-tenant application can directly implement the data lifecycle operations described earlier, or it can create a separate tenant-administration tool.
Independent of the implementation strategy, lifecycle operations might have to be run without the application logic running at the same time—for example, while moving a tenant from one data management pattern to another, the application logic can't run because the data isn't in a single database. When data isn't in a single database, it requires two additional operations from an application perspective:
- Stopping a tenant: Disables all application logic access while permitting data lifecycle operations.
- Starting a tenant: Application logic can access a tenant's data while the lifecycle operations that would interfere with the application logic are disabled.
While not often used, an emergency tenant shutdown might be another important lifecycle operation. Use this shut down when you suspect a breach, and you need to prohibit all access to a tenant's data—not only application logic, but lifecycle operations as well. A breach can originate from inside or outside the database.
A matching lifecycle operation that removes the emergency status must also be available. Such an operation can require two or more administrators to sign in at the same time in order to implement mutual control.
Application isolation
The various data management patterns support different degrees of tenant-data isolation. From the most isolated level (instance) to the least isolated level (row), different degrees of isolation are possible.
In the context of a multi-tenant application, a similar deployment decision must be made: do all tenants access their data (in possibly different data management patterns) using the same application deployment? For example, a single Kubernetes cluster might support all tenants and when a tenant accesses its data, the same cluster runs the business logic.
Alternatively, as in the case of the data management patterns, different tenants might be directed to different application deployments. Large tenants might have access to an application deployment exclusive to them, while smaller tenants or tenants in the free tier share an application deployment.
Instead of directly matching the data management patterns discussed in this document with equivalent application-data management patterns, you can use the database data management pattern so that all tenants share a single application deployment. It's possible to have the database data management pattern and all these tenants share a single application deployment.
Multi-tenancy is an important application-design-data management pattern, especially when resource efficiency plays a vital role. Spanner supports several data management patterns—use it for implementing multi-tenant applications. It provides zero-downtime for planned maintenance or region failures, with an availability SLA of 99.999%. It also supports modern, multi-tenant applications by providing high availability and scalability.