This page describes Spanner compute capacity and the two units of measure used to quantify it: nodes and processing units.
Compute capacity
When you create an instance, you choose an instance configuration and an amount of compute capacity for your instance. Your instance's compute capacity has the following characteristics:
- It determines the amount of server and storage resources, that are available to the databases in your instance, including disk load. Disk load applies only to workloads that access data stored on HDD storage. For more information, see Tiered storage overview.
It is measured in processing units (PUs) or nodes, with 1000 PUs being equal to 1 node.
- A node or 1000 PUs is a logical unit of compute capacity and doesn't represent a single physical server. The compute resources for each node are distributed across multiple underlying physical machines, or servers. The number of servers per node depends on your instance configuration. For example, a regional instance uses at least three servers per node, while a multi-region instance uses at least five. For more information, see Compute capacity and instance configurations.
- When you define or change compute capacity on an instance, you must specify PUs in multiples of 100 (for example, 100, 200, 300). When the number of PUs reaches 1000, you can specify larger quantities either as multiples of 1000 PUs (for example, 1000, 2000, 3000) or as nodes (for example, 1, 2, 3).
Spanner makes the specified compute capacity available (replicated) in its entirety within each zone that hosts a replica of your data. For example, if you provision 1000 PUs for a regional instance, which typically has replicas in three zones, each of those three zones has the full 1000 PUs of compute power available to serve its replica. Spanner doesn't divide or distribute the total PUs among the zones. The measurement unit you use doesn't matter unless you are creating an instance whose compute capacity is smaller than 1000 PUs (1 node). In this case, you must use PUs to specify the compute capacity of the instance.
Instances with fewer than 1000 PUs are built for smaller data sizes, queries, and workloads. They have limited compute resources, which can result in non-linear scaling and performance issues for some workloads. These instances might also experience intermittent increases in latencies.
Spanner availability
Spanner is designed for high availability. Because the compute capacity of each instance is spread across multiple servers in different zones, Spanner is resilient to the failure of any one server. The loss of an individual server doesn't constitute a node failure. Spanner manages its underlying resources automatically to provide continuous availability for your instance.
Data storage limits
As detailed in Quotas & limits, to provide high availability and low latency when accessing a database, Spanner uses the compute capacity of an instance as a basis for determining storage limits, using the following guidelines:
- For instances smaller than 1 node (1000 PUs), Spanner allots 1024.0 GiB of data for every 100 PUs in the database.
- For instances of 1 node and larger, Spanner allots 10 TiB of data for each node.
For example, to create an instance for a 300 GB database, you can set its compute capacity to 100 PUs. This amount of compute capacity keeps the instance below the limit until the database grows to more than 1024.0 GiB. After the database reaches this size, you need to add another 100 PUs to allow the database to grow. Otherwise, Spanner might reject writes to the database. For more information, see Recommendations for database storage utilization.
Spanner bills for the storage that instances actually utilize, and not their total storage allotment.
Performance
The peak read and write throughput values that a given amount of compute capacity can provide depend on the instance configuration, as well as on schema design and dataset characteristics. For more information, see the Performance overview.
You use instances with fewer than 1000 PUs for smaller data sizes, queries, and workloads. For larger workloads, their limited compute resources might result in non-linear scaling and performance, with intermittent increases in latencies.
Compute capacity and instance configurations
As described in Regional, dual-region, and multi-region configurations, Spanner distributes an instance across zones of one or more regions to provide high performance and high availability. Consequently, Spanner also distributes server resources provided by the instance's compute capacity.
Here is a diagram that illustrates this distribution of server resources.
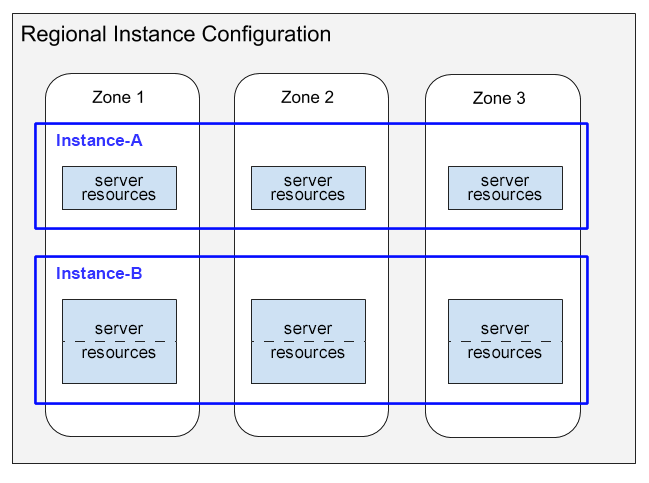
This diagram depicts two instances that have regional configurations:
- Instance-A shows an instance of 1000 PUs (1 node) with its compute capacity distribution consuming server resources in each of the three zones.
- Instance-B shows an instance of 2000 PUs (2 nodes) with its compute capacity distribution consuming server resources in each of the three zones.
Note the following in this diagram:
For each instance, Spanner allocates server resources in each zone of the regional configuration. Each per-zone server resource uses the data replica in its zone. For information about data replicas in instance configurations, see Regional, dual-region, and multi-region configurations. For information about how Spanner keeps these data replicas in sync, see Replication.
The server resources for Instance-A are shown in single boxes, while the resources for Instance-B are shown in boxes subdivided into two parts. This difference illustrates that Spanner allocates server resources differently for different-sized instances:
- For instances of 1000 PUs (1 node) and smaller, Spanner allocates server resources in a single server task per zone.
- For instances larger than 1000 PUs (1 node), Spanner allocates server resources in multiple server tasks per zone, with one task for each 1000 PUs. Using multiple server tasks per zone provides better performance and enables Spanner to create database splits and provide even better performance.
Change the compute capacity
After you create an instance, you can increase its compute capacity later. In most cases, requests complete within a few minutes. On rare occasions, a scale up might take up to an hour to complete.
You can reduce the compute capacity of a Spanner instance except in the following scenarios:
You can't store more than 10 TiB of data per node (1000 processing units).
There are a large number of splits for your instance's data. In this scenario, Spanner might not be able to manage the splits after you reduce compute capacity. You can try reducing the compute capacity by progressively smaller amounts until you find the minimum capacity that Spanner needs to manage all of the instance's splits.
Spanner can create a large number of splits to accommodate your usage patterns. If your usage patterns change, then after one or two weeks, Spanner might merge some splits together and you can try to reduce the instance's compute capacity.
When removing compute capacity, monitor your CPU utilization and request latencies in Cloud Monitoring to ensure CPU utilization stays under 65% for regional instances and 45% for each region in multi-region instances. You might experience a temporary increase in request latencies while removing compute capacity.
Spanner doesn't have a suspend mode. Spanner compute capacity is a dedicated resource and, even when you are not running a workload, Spanner frequently performs background work to optimize and protect your data.
You can use the Google Cloud console, Google Cloud CLI, or the Spanner client libraries to change compute capacity. For more information, see Change the compute capacity.
Compute capacity versus replicas
If you need to scale up the server and storage resources in your instance, increase the compute capacity of the instance. Note that increasing compute capacity doesn't increase the number of replicas (which are fixed for a given instance configuration), but rather increases the resources each replica has in the instance. Increasing compute capacity gives each replica more CPU and RAM, which increases the replica's throughput (that is, more reads and writes per second can occur).
What's next
- Learn how to Create and manage instances.