Vertex AI Vector Search allows users to search for semantically similar items using vector embeddings. Using the Spanner To Vertex AI Vector Search Workflow, you can integrate your Spanner database with Vector Search to perform a vector similarity search on your Spanner data.
The following diagram shows the end-to-end application workflow of how you can enable and use Vector Search on your Spanner data:
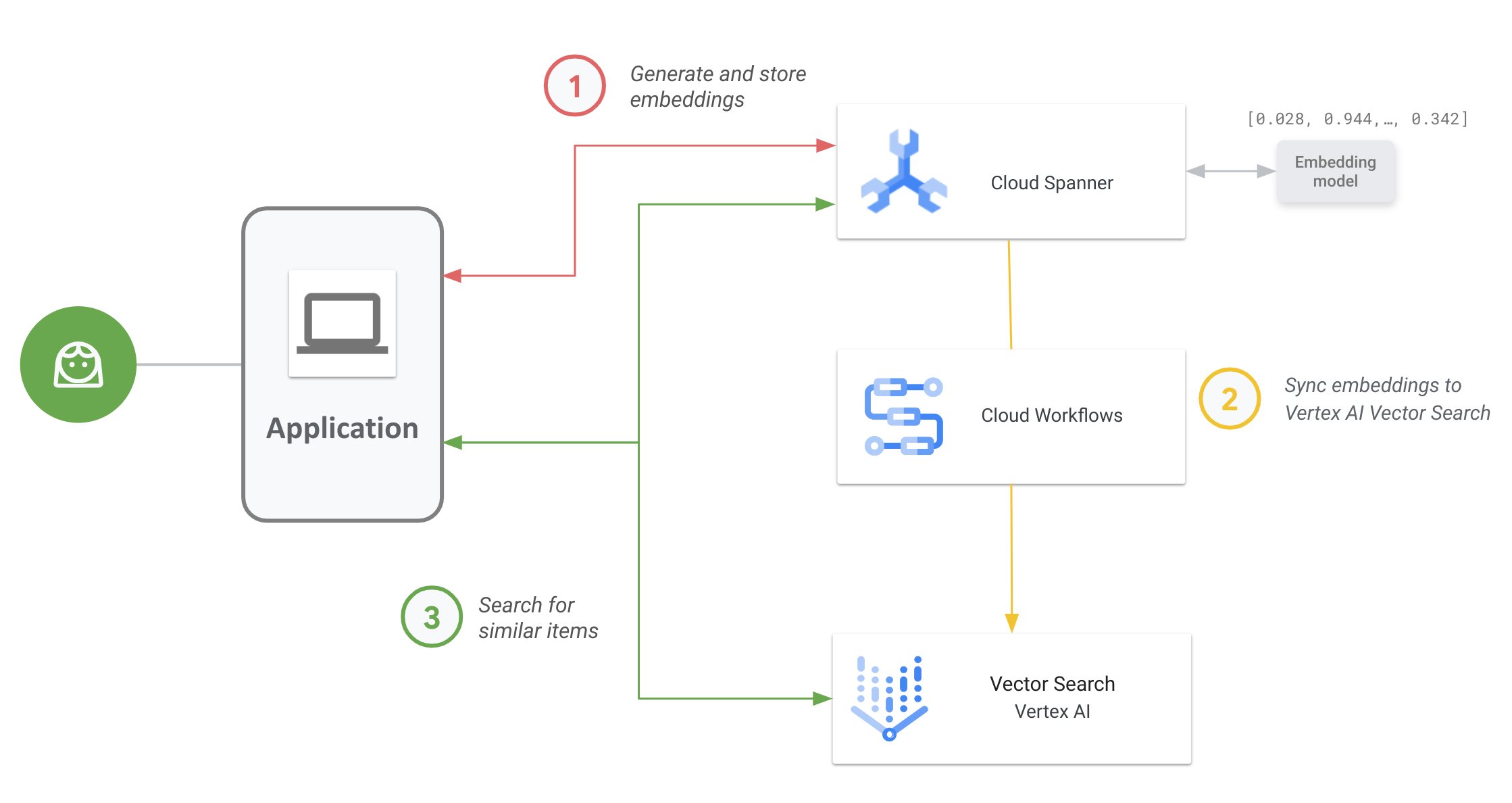
The general workflow is as follows:
Generate and store vector embeddings.
You can generate vector embeddings of your data, then store and manage them in Spanner with your operational data. You can generate embeddings with Spanner's
ML.PREDICTSQL function to access the Vertex AI text embedding model or use other embedding models deployed to Vertex AI.Sync embeddings to Vector Search.
Use the Spanner To Vertex AI Vector Search Workflow, which is deployed using Workflows to export and upload embeddings into a Vector Search index. You can use Cloud Scheduler to periodically schedule this workflow to keep your Vector Search index up to date with the latest changes to your embeddings in Spanner.
Perform vector similarity search using your Vector Search index.
Query the Vector Search index to search and find results for semantically similar items. You can query using a public endpoint or through VPC peering.
Example use case
An illustrative use case for Vector Search is an online retailer who has an inventory of hundreds of thousands of items. In this scenario, you are a developer for an online retailer, and you would like to use vector similarity search on your product catalog in Spanner to help your customers find relevant products based on their search queries.
Follow step 1 and step 2 presented in the general workflow to generate vector embeddings for your product catalog, and sync these embeddings to Vector Search.
Now imagine a customer browsing your application performs a search such as
"best, quick-drying sports shorts that I can wear in the water". When your
application receives this query, you need to generate a request embedding for
this search request using the Spanner ML.PREDICT
SQL function. Make sure to use the same embedding model used to generate the
embeddings for your product catalog.
Next, query the Vector Search index for product IDs whose corresponding embeddings are similar to the request embedding generated from your customer's search request. The search index might recommend product IDs for semantically similar items such as wakeboarding shorts, surfing apparel, and swimming trunks.
After Vector Search returns these similar product IDs, you can query Spanner for the products' descriptions, inventory count, price, and other metadata that are relevant, and display them to your customer.
You can also use generative AI to process the returned results from Spanner before displaying them to your customer. For example, you might use Google's large generative AI models to generate a concise summary of the recommended products. For more information, see this tutorial on how to use Generative AI to get personalized recommendations in an ecommerce application.
What's next
- Learn how to generate embeddings using Spanner.
- Learn more about AI's multitool: Vector embeddings
- Learn more about machine learning and embeddings in our crash course on embeddings.
- Learn more about the Spanner To Vertex AI Vector Search Workflow, see the GitHub repository.
- Learn more about the open source spanner-analytics package that facilitates common data-analytic operations in Python and includes integrations with Jupyter Notebooks.