Erstellen Sie einen Kubernetes-Cluster, um die Bereitstellung von Containerarbeitslasten zu ermöglichen. Cluster sind eine zonale Ressource und können sich nicht über mehrere Zonen erstrecken. Wenn Sie Cluster in einer Bereitstellung mit mehreren Zonen betreiben möchten, müssen Sie Cluster in jeder Zone manuell erstellen.
Hinweise
Bitten Sie Ihren IAM-Administrator der Organisation, Ihnen die Rolle „Administrator für Nutzercluster“ (user-cluster-admin) zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen eines Kubernetes-Clusters benötigen. Diese Rolle ist nicht an einen Namespace gebunden.
Für Google Distributed Cloud (GDC) mit Air Gap gelten die folgenden Limits für Kubernetes-Cluster:
- 16 Cluster pro Organisation
- 42 Worker-Knoten pro Cluster und mindestens drei Worker-Knoten
- 4.620 Pods pro Cluster
- 110 Pods pro Knoten
Pod-CIDR-Block konfigurieren
Der Cluster folgt dieser Logik beim Zuweisen von IP-Adressen:
- Kubernetes weist jedem Knoten einen /24-CIDR-Block mit 256 Adressen zu. Diese Menge entspricht dem Standardmaximum von 110 Pods pro Knoten für Nutzercluster.
- Die Größe des CIDR-Blocks, der einem Knoten zugewiesen wird, hängt von der maximalen Anzahl von Pods pro Knoten ab.
- Der Block enthält immer mindestens doppelt so viele Adressen wie die maximale Anzahl von Pods pro Knoten.
Im folgenden Beispiel sehen Sie, wie der Standardwert von Maskengröße pro Knoten= /24 berechnet wurde, um 110 Pods zu unterstützen:
Maximum pods per node = 110
Total number of IP addresses required = 2 * 110 = 220
Per node mask size = /24
Number of IP addresses in a /24 = 2(32 - 24) = 256
Bestimmen Sie die erforderliche Pod-CIDR-Maske, die für den Nutzercluster konfiguriert werden soll, basierend auf der erforderlichen Anzahl von Knoten. Planen Sie beim Konfigurieren des CIDR-Bereichs zukünftige Knotenerweiterungen des Clusters ein:
Total number of nodes supported = 2(Per node mask size - pod CIDR mask)
Da wir standardmäßig Maskengröße pro Knoten= /24 haben , finden Sie in der folgenden Tabelle die Zuordnung der Pod-CIDR-Maske zur Anzahl der unterstützten Knoten.
| Pod-CIDR-Maske | Berechnung: 2(Größe der Maske pro Knoten – CIDR-Maske) | Maximale Anzahl der unterstützten Knoten, einschließlich Knoten der Steuerungsebene |
|---|---|---|
| /21 | 2(24–21) | 8 |
| /20 | 2(24–20) | 16 |
| /19 | 2(24 – 19) | 32 |
| /18 | 2(24 – 18) | 64 |
Kubernetes-Cluster erstellen
Führen Sie die folgenden Schritte aus, um einen Kubernetes-Cluster zu erstellen:
Console
Wählen Sie im Navigationsmenü Kubernetes Engine > Cluster aus.
Klicken Sie auf Cluster erstellen.
Geben Sie im Feld Name einen Namen für den Cluster an.
Wählen Sie die Kubernetes-Version für den Cluster aus.
Wählen Sie die Zone aus, in der der Cluster erstellt werden soll.
Klicken Sie auf Projekt anhängen und wählen Sie ein vorhandenes Projekt aus, das Sie an Ihren Cluster anhängen möchten. Klicken Sie dann auf Speichern. Sie können Projekte nach der Erstellung des Clusters auf der Seite mit den Projektdetails anhängen oder trennen. Sie müssen Ihrem Cluster ein Projekt zuweisen, bevor Sie Containerarbeitslasten darin bereitstellen können.
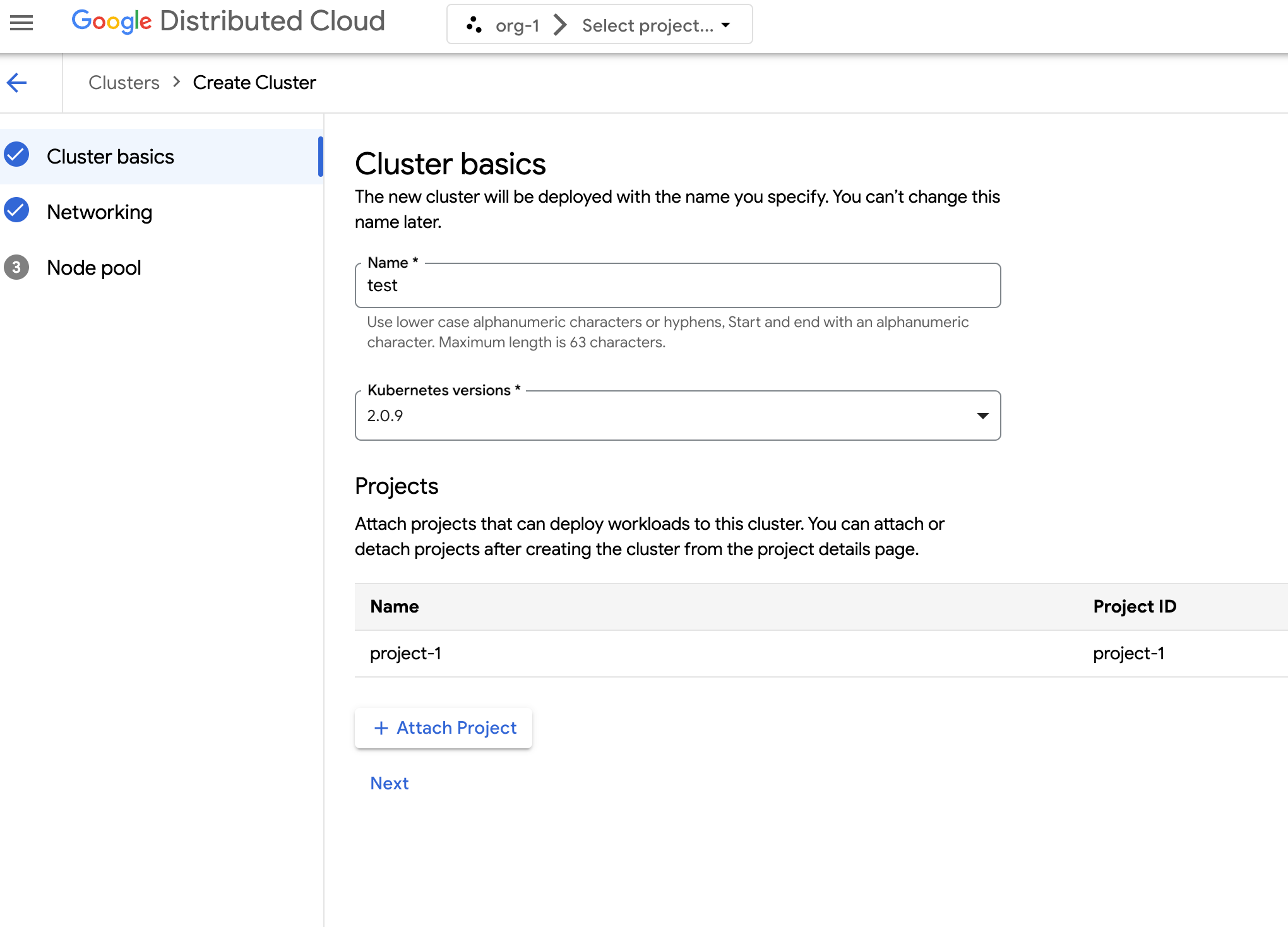
Klicken Sie auf Weiter.
Konfigurieren Sie die Netzwerkeinstellungen für Ihren Cluster. Diese Netzwerkeinstellungen können nach dem Erstellen des Clusters nicht mehr geändert werden. Das Standard- und einzige unterstützte Internetprotokoll für Kubernetes-Cluster ist Internet Protocol Version 4 (IPv4).
Wenn Sie dedizierte Load-Balancer-Knoten erstellen möchten, geben Sie die Anzahl der Knoten ein, die erstellt werden sollen. Standardmäßig erhalten Sie keine Knoten und der Load-Balancer-Traffic wird über die Steuerungsknoten geleitet.
Wählen Sie den Service-CIDR-Bereich (Classless Inter-Domain Routing) aus, den Sie verwenden möchten. Ihren bereitgestellten Diensten, z. B. Load-Balancern, werden IP-Adressen aus diesem Bereich zugewiesen.
Wählen Sie den zu verwendenden Pod-CIDR aus. Der Cluster weist Ihren Pods und VMs IP-Adressen aus diesem Bereich zu.
Klicken Sie auf Weiter.
Prüfen Sie die Details des automatisch generierten Standardknotenpools für den Cluster. Klicken Sie auf edit Bearbeiten, um den Standardknotenpool zu ändern.
Wenn Sie zusätzliche Knotenpools erstellen möchten, wählen Sie Knotenpool hinzufügen aus. Wenn Sie den Standardknotenpool bearbeiten oder einen neuen Knotenpool hinzufügen, können Sie ihn mit den folgenden Optionen anpassen:
- Weisen Sie dem Knotenpool einen Namen zu. Sie können den Namen nach dem Erstellen des Knotenpools nicht mehr ändern.
- Geben Sie die Anzahl der Worker-Knoten an, die im Knotenpool erstellt werden sollen.
Wählen Sie die Maschinenklasse aus, die Ihren Arbeitslastanforderungen am besten entspricht. Hier finden Sie eine Liste der folgenden Einstellungen:
- Maschinentyp
- CPU
- Arbeitsspeicher
Klicken Sie auf Speichern.
Klicken Sie auf Erstellen, um den Cluster zu erstellen.
API
Wenn Sie einen neuen Cluster direkt über die API erstellen möchten, wenden Sie eine benutzerdefinierte Ressource auf Ihre GDC-Instanz an:
Erstellen Sie eine benutzerdefinierte Ressource vom Typ
Clusterund speichern Sie sie als YAML-Datei, z. B.cluster.yaml:apiVersion: cluster.gdc.goog/v1 kind: Cluster metadata: name: CLUSTER_NAME namespace: platform spec: clusterNetwork: podCIDRSize: POD_CIDR serviceCIDRSize: SERVICE_CIDR initialVersion: kubernetesVersion: KUBERNETES_VERSION loadBalancer: ingressServiceIPSize: LOAD_BALANCER_POOL_SIZE nodePools: - machineTypeName: MACHINE_TYPE name: NODE_POOL_NAME nodeCount: NUMBER_OF_WORKER_NODES taints: TAINTS labels: LABELS acceleratorOptions: gpuPartitionScheme: GPU_PARTITION_SCHEME releaseChannel: channel: UNSPECIFIEDErsetzen Sie Folgendes:
CLUSTER_NAME: Der Name des Clusters. Der Clustername darf nicht mit-systemenden. Das Suffix-systemist für von GDC erstellte Cluster reserviert.POD_CIDR: Die Größe der Netzwerkbereiche, aus denen virtuelle IP-Adressen für Pods zugewiesen werden. Wenn kein Wert angegeben ist, wird der Standardwert21verwendet.SERVICE_CIDR: Die Größe der Netzwerkbereiche, aus denen virtuelle Dienst-IP-Adressen zugewiesen werden. Wenn kein Wert angegeben ist, wird der Standardwert23verwendet.KUBERNETES_VERSION: Die Kubernetes-Version des Clusters, z. B.1.26.5-gke.2100. Eine Liste der verfügbaren Kubernetes-Versionen, die Sie konfigurieren können, finden Sie unter Verfügbare Kubernetes-Versionen für einen Cluster auflisten.LOAD_BALANCER_POOL_SIZE: Die Größe der nicht überlappenden IP-Adresspools, die von Load-Balancer-Diensten verwendet werden. Wenn nicht festgelegt, wird der Standardwert20verwendet.MACHINE_TYPE: Der Maschinentyp für die Worker-Knoten des Knotenpools. Hier finden Sie die verfügbaren Maschinentypen.NODE_POOL_NAME: Der Name des Knotenpools.NUMBER_OF_WORKER_NODES: Die Anzahl der Worker-Knoten, die im Knotenpool bereitgestellt werden sollen.TAINTS: Die Markierungen, die auf die Knoten dieses Knotenpools angewendet werden sollen. Dieses Feld ist optional.LABELS: Die Labels, die auf die Knoten dieses Knotenpools angewendet werden sollen. Sie enthält eine Liste von Schlüssel/Wert-Paaren. Dieses Feld ist optional.GPU_PARTITION_SCHEME: Das GPU-Partitionierungsschema, wenn Sie GPU-Arbeitslasten ausführen. Beispiel:mixed-2. Die GPU wird nicht partitioniert, wenn dieses Feld nicht festgelegt ist. Informationen zu verfügbaren MIG-Profilen (Multi-Instance GPU) finden Sie unter Unterstützte MIG-Profile.
Wenden Sie die benutzerdefinierte Ressource auf Ihre GDC-Instanz an:
kubectl apply -f cluster.yaml --kubeconfig MANAGEMENT_API_SERVERErsetzen Sie
MANAGEMENT_API_SERVERdurch den kubeconfig-Pfad des zonalen API-Servers. Wenn Sie noch keine kubeconfig-Datei für den API-Server in Ihrer Zielzone generiert haben, lesen Sie die Informationen unter Anmelden.
Terraform
Fügen Sie in eine Terraform-Konfigurationsdatei das folgende Code-Snippet ein:
provider "kubernetes" { config_path = "MANAGEMENT_API_SERVER" } resource "kubernetes_manifest" "cluster-create" { manifest = { "apiVersion" = "cluster.gdc.goog/v1" "kind" = "Cluster" "metadata" = { "name" = "CLUSTER_NAME" "namespace" = "platform" } "spec" = { "clusterNetwork" = { "podCIDRSize" = "POD_CIDR" "serviceCIDRSize" = "SERVICE_CIDR" } "initialVersion" = { "kubernetesVersion" = "KUBERNETES_VERSION" } "loadBalancer" = { "ingressServiceIPSize" = "LOAD_BALANCER_POOL_SIZE" } "nodePools" = [{ "machineTypeName" = "MACHINE_TYPE" "name" = "NODE_POOL_NAME" "nodeCount" = "NUMBER_OF_WORKER_NODES" "taints" = "TAINTS" "labels" = "LABELS" "acceleratorOptions" = { "gpuPartitionScheme" = "GPU_PARTITION_SCHEME" } }] "releaseChannel" = { "channel" = "UNSPECIFIED" } } } }Ersetzen Sie Folgendes:
MANAGEMENT_API_SERVER: Der kubeconfig-Pfad des zonalen API-Servers. Wenn Sie noch keine kubeconfig-Datei für den API-Server in der Zielzone generiert haben, finden Sie weitere Informationen unter Anmelden.CLUSTER_NAME: Der Name des Clusters. Der Clustername darf nicht mit-systemenden. Das Suffix-systemist für von GDC erstellte Cluster reserviert.POD_CIDR: Die Größe der Netzwerkbereiche, aus denen virtuelle IP-Adressen für Pods zugewiesen werden. Wenn kein Wert angegeben ist, wird der Standardwert21verwendet.SERVICE_CIDR: Die Größe der Netzwerkbereiche, aus denen virtuelle Dienst-IP-Adressen zugewiesen werden. Wenn kein Wert angegeben ist, wird der Standardwert23verwendet.KUBERNETES_VERSION: Die Kubernetes-Version des Clusters, z. B.1.26.5-gke.2100. Eine Liste der verfügbaren Kubernetes-Versionen, die Sie konfigurieren können, finden Sie unter Verfügbare Kubernetes-Versionen für einen Cluster auflisten.LOAD_BALANCER_POOL_SIZE: Die Größe der nicht überlappenden IP-Adresspools, die von Load-Balancer-Diensten verwendet werden. Wenn nicht festgelegt, wird der Standardwert20verwendet.MACHINE_TYPE: Der Maschinentyp für die Worker-Knoten des Knotenpools. Hier finden Sie die verfügbaren Maschinentypen.NODE_POOL_NAME: Der Name des Knotenpools.NUMBER_OF_WORKER_NODES: Die Anzahl der Worker-Knoten, die im Knotenpool bereitgestellt werden sollen.TAINTS: Die Markierungen, die auf die Knoten dieses Knotenpools angewendet werden sollen. Dieses Feld ist optional.LABELS: Die Labels, die auf die Knoten dieses Knotenpools angewendet werden sollen. Sie enthält eine Liste von Schlüssel/Wert-Paaren. Dieses Feld ist optional.GPU_PARTITION_SCHEME: Das GPU-Partitionierungsschema, wenn Sie GPU-Arbeitslasten ausführen. Beispiel:mixed-2. Die GPU wird nicht partitioniert, wenn dieses Feld nicht festgelegt ist. Informationen zu verfügbaren MIG-Profilen (Multi-Instance GPU) finden Sie unter Unterstützte MIG-Profile.
Wenden Sie den neuen Kubernetes-Cluster mit Terraform an:
terraform apply
Verfügbare Kubernetes-Versionen für einen Cluster auflisten
Sie können die verfügbaren Kubernetes-Versionen in Ihrer GDC-Instanz mit der kubectl CLI auflisten:
kubectl get userclustermetadata.upgrade.private.gdc.goog \
-o=custom-columns=K8S-VERSION:.spec.kubernetesVersion \
--kubeconfig MANAGEMENT_API_SERVER
Ersetzen Sie MANAGEMENT_API_SERVER durch den kubeconfig-Pfad des zonalen API-Servers Ihres Clusters.
Die Ausgabe sieht dann ungefähr so aus:
K8S-VERSION
1.25.10-gke.2100
1.26.5-gke.2100
1.27.4-gke.500
GPU-Arbeitslasten in einem Cluster unterstützen
Distributed Cloud bietet Unterstützung für NVIDIA-GPUs für Kubernetes-Cluster und führt Ihre GPU-Geräte als Nutzerarbeitslasten aus. Beispielsweise möchten Sie möglicherweise Notebooks für künstliche Intelligenz (KI) und maschinelles Lernen (ML) in einer GPU-Umgebung ausführen. Prüfen Sie, ob Ihr Cluster GPU-Geräte unterstützt, bevor Sie KI- und ML-Notebooks verwenden. Die GPU-Unterstützung ist standardmäßig für Cluster aktiviert, für die GPU-Maschinen bereitgestellt wurden.
Cluster können über die GDC-Konsole oder direkt über die API erstellt werden. Stellen Sie sicher, dass Sie GPU-Maschinen für Ihren Cluster bereitstellen, um GPU-Arbeitslasten in den zugehörigen Containern zu unterstützen. Weitere Informationen finden Sie unter Kubernetes-Cluster erstellen.
GPUs werden statisch zugewiesen. Die ersten vier GPUs sind immer für Arbeitslasten wie vortrainierte APIs für künstliche Intelligenz (KI) und maschinelles Lernen (ML) vorgesehen. Diese GPUs werden nicht auf einem Kubernetes-Cluster ausgeführt. Die verbleibenden GPUs sind für Kubernetes-Cluster verfügbar. KI- und ML-Notebooks werden auf Kubernetes-Clustern ausgeführt.
Weisen Sie GPU-Maschinen den richtigen Clustertypen zu, damit Komponenten wie KI- und ML-APIs und Notebooks verwendet werden können.