Mit einem Glossar können Sie Begriffe definieren, die für Ihre Domain spezifisch sind. Mit einem Glossar können Sie Begriffspaare hinzufügen, darunter einen Begriff in der Quell- und einen in der Zielsprache. Die Begriffspaare sorgen dafür, dass der Vertex AI Translation-Dienst Ihre Terminologie konsistent übersetzt.
Hier sind einige Beispiele für Fälle, in denen Sie Glossareinträge definieren können:
- Produktnamen: Produktnamen identifizieren, damit sie in der Übersetzung beibehalten werden. Beispiel: Google Home muss in Google Home übersetzt werden.
- Mehrdeutige Wörter: Geben Sie die Bedeutung vager Wörter und Homonyme an. Das Wort Schläger kann beispielsweise ein Sportgerät oder ein Tier sein.
- Lehnwörter: Erläutern Sie die Bedeutung von Wörtern, die aus einer anderen Sprache übernommen wurden. Beispielsweise wird das französische Wort Bouillabaisse im Deutschen mit Bouillabaisse übersetzt, einem Fischeintopf.
Bei den Begriffen in einem Glossar kann es sich um einzelne Wörter (auch als Tokens bezeichnet) oder um kurze Phrasen (in der Regel weniger als fünf Wörter) handeln. Bei der Vertex AI Translation werden übereinstimmende Glossareinträge ignoriert, wenn die Wörter Stoppwörter sind.
Vertex AI Translation bietet die folgenden Glossarmethoden, die in Google Distributed Cloud (GDC) Air-Gap verfügbar sind:
| Methode | Beschreibung |
|---|---|
CreateGlossary |
Glossar erstellen |
GetGlossary |
Gibt ein gespeichertes Glossar zurück. |
ListGlossaries |
Gibt eine Liste der Glossar-IDs in einem Projekt zurück. |
DeleteGlossary |
Löschen Sie ein Glossar, das Sie nicht mehr benötigen. |
Hinweise
Bevor Sie ein Glossar erstellen, um Ihre Terminologie für die Übersetzung zu definieren, müssen Sie ein Projekt mit dem Namen translation-glossary-project haben. Die benutzerdefinierte Ressource des Projekts muss wie im folgenden Beispiel aussehen:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
Bitten Sie Ihren Projekt-IAM-Administrator, Ihnen die folgenden Rollen in Ihrem Projekt-Namespace zuzuweisen, um die Berechtigungen zu erhalten, die Sie zur Verwendung eines Glossars benötigen:
- AI Translation Developer: Weisen Sie sich selbst die Rolle „AI Translation Developer“ (
ai-translation-developer) zu, um auf den Vertex AI Translation-Dienst zuzugreifen. - Projekt-Bucket-Administrator: Mit der Rolle „Projekt-Bucket-Administrator“ (
project-bucket-admin) können Sie Storage-Buckets und Objekte in Buckets verwalten. Außerdem können Sie Dateien erstellen und hochladen.
Weitere Informationen zu den Voraussetzungen finden Sie unter Übersetzungsprojekt einrichten.
Glossardatei erstellen
Sie müssen eine Glossardatei erstellen, in der Sie die Begriffe für die Quell- und Zielsprache speichern. In diesem Abschnitt finden Sie die beiden verschiedenen Glossarlayouts, mit denen Sie Ihre Begriffe definieren können.
In der folgenden Tabelle werden die Limits für Glossardateien in Distributed Cloud beschrieben:
| Beschreibung | Limit |
|---|---|
| Maximale Dateigröße | 10,4 Millionen (10.485.760) UTF-8-Byte |
| Maximale Länge eines Glossarbegriffs | 1.024 UTF‑8-Bytes |
| Höchstzahl der Glossar-Ressourcen eines Projekts | 10.000 |
Wählen Sie eines der folgenden Layouts für Ihre Glossardatei aus:
- Unidirektionales Glossar: Geben Sie die erwartete Übersetzung für ein Paar aus Quell- und Zielbegriffen in einer bestimmten Sprache an. Unidirektionale Glossare unterstützen die Dateiformate TSV, CSV und TMX.
- Glossar mit Sets äquivalenter Begriffe: Geben Sie in jeder Zeile die erwartete Übersetzung in mehreren Sprachen an. Glossare mit Sets äquivalenter Begriffe unterstützen CSV-Dateiformate.
Unidirektionales Glossar
Die Vertex AI Translation API akzeptiert tabulatorgetrennte Werte (TSV) und kommagetrennte Werte (CSV). Jede Zeile enthält ein Paar von Begriffen, die durch einen Tabulator (\t) oder ein Komma (,) getrennt sind.
Die Vertex AI Translation API akzeptiert auch das Translation Memory eXchange-Format (TMX), ein XML-Standardformat zur Bereitstellung von Quell- und Zielbegriffspaaren für die Übersetzung. Die unterstützten Eingabedateien sind in einem Format, das auf TMX Version 1.4 basiert.
Die folgenden Beispiele zeigen die erforderliche Struktur für TSV-, CSV- und TMX-Dateiformate unidirektionaler Glossare:
TSV und CSV
Das folgende Bild zeigt zwei Spalten in einer TSV- oder CSV-Datei. Die erste Spalte enthält den Begriff in der Quellsprache und die zweite Spalte den Begriff in der Zielsprache.

Wenn Sie eine Glossardatei erstellen, können Sie eine Kopfzeile definieren. Mit der Glossaranfrage wird die Datei für die Vertex AI Translation API verfügbar gemacht.
TMX
Das folgende Beispiel veranschaulicht die erforderliche Struktur in einer TMX-Datei:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
Wenn Ihre Datei XML-Tags enthält, die in diesem Beispiel nicht aufgeführt sind, werden diese Tags von der Vertex AI Translation API ignoriert.
Fügen Sie die folgenden Elemente in Ihre TMX-Datei ein, damit die Vertex AI Translation API sie erfolgreich verarbeiten kann:
<header>: Identifizieren Sie die Ausgangssprache mit dem Attributsrclang.<tu>: Fügen Sie ein Paar von<tuv>-Elementen mit derselben Quell- und Zielsprache ein. Diese<tuv>-Elemente entsprechen den folgenden Anforderungen:- Jedes
<tuv>-Element identifiziert die Sprache des enthaltenen Texts mithilfe des Attributsxml:lang. Verwenden Sie ISO‑639‑1-Codes, um die Quell- und Zielsprachen zu identifizieren. Hier finden Sie eine Liste der unterstützten Sprachen und der entsprechenden Sprachcodes. - Wenn ein
<tu>-Element mehr als zwei<tuv>-Elemente enthält, verarbeitet die Vertex AI Translation API nur das erste<tuv>-Element, das der Ausgangssprache entspricht, und das erste<tuv>-Element, das der Zielsprache entspricht. Der Dienst ignoriert die restlichen<tuv>-Elemente. - Wenn ein
<tu>-Element kein übereinstimmendes<tuv>-Elementpaar hat, ignoriert die Vertex AI Translation API das ungültige<tu>-Element.
- Jedes
<seg>: Stellt verallgemeinerte Textstrings dar. Die Vertex AI Translation API schließt die Markup-Tags aus einem<seg>-Element aus, bevor die Datei verarbeitet wird. Wenn ein<tuv>-Element mehr als ein<seg>-Element enthält, verkettet die Vertex AI Translation API den Text zu einem einzelnen Element mit einem Leerzeichen zwischen den Textstrings.
Nachdem Sie die Glossarbegriffe in Ihrem unidirektionalen Glossar identifiziert haben, laden Sie die Datei in einen Speicher-Bucket hoch und stellen Sie sie der Vertex AI Translation API zur Verfügung, indem Sie ein Glossar erstellen und importieren.
Glossar mit Sets äquivalenter Begriffe
Die Vertex AI Translation API akzeptiert Glossardateien für entsprechende Sets äquivalenter Begriffe im CSV-Format. Zur Definition von Glossaren mit Sets äquivalenter Begriffe erstellen Sie eine mehrspaltige CSV-Datei und geben pro Zeile jeweils einen einzelnen Glossarbegriff in mehreren Sprachen an. Hier finden Sie eine Liste der unterstützten Sprachen und der entsprechenden Sprachcodes.
Das folgende Bild zeigt ein Beispiel für eine CSV-Datei mit mehreren Spalten. Jede Zeile steht für einen Glossarbegriff und jede Spalte für eine Übersetzung des Begriffs in verschiedene Sprachen.
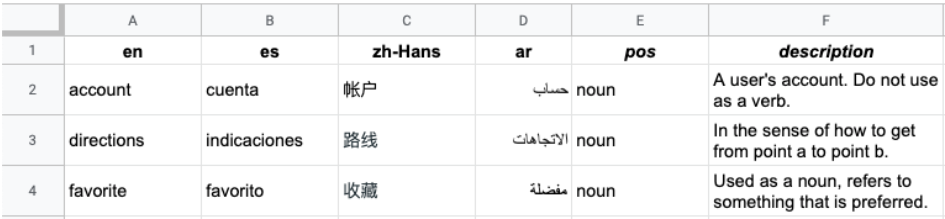
Die Kopfzeile ist die erste Zeile der Datei. Sie enthält die Sprache für jede Spalte. In der Kopfzeile werden die Sprachcodes gemäß ISO-639-1 oder BCP-47 verwendet. Die Vertex AI Translation API verwendet keine Informationen zum Redeteil (pos) und bestimmte Positionswerte werden nicht validiert.
In den darauffolgenden Zeilen stehen dann in den einzelnen Spalten die äquivalenten Glossarbegriffe in den Sprachen, die laut Kopfzeile vorgesehen sind. Sie können eine Spalte leer lassen, wenn der Begriff in der betreffenden Sprache nicht verfügbar ist.
Nachdem Sie die Glossarbegriffe in Ihrem entsprechenden Begriffssatz identifiziert haben, laden Sie die Datei in einen Speicher-Bucket hoch und stellen Sie sie der Vertex AI Translation API zur Verfügung, indem Sie ein Glossar erstellen und importieren.
Glossardatei in einen Speicher-Bucket hochladen
So laden Sie Ihre Glossardatei in einen Speicher-Bucket hoch:
- gcloud CLI für Objektspeicher konfigurieren
Erstellen Sie einen Storage-Bucket in Ihrem Projekt-Namespace. Verwenden Sie eine
Standard-Speicherklasse.Sie können den Speicher-Bucket erstellen, indem Sie eine
Bucket-Ressource in Ihrem Projekt-Namespace bereitstellen:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Gewähren Sie dem Dienstkonto (
ai-translation-system-sa), das vom Vertex AI Translation-Dienst verwendet wird, die Berechtigungenreadfür den Bucket.So erstellen Sie die Rolle und die Rollenbindung mit benutzerdefinierten Ressourcen:
Erstellen Sie die Rolle, indem Sie eine
Role-Ressource im Projekt-Namespace bereitstellen:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectErstellen Sie die Rollenbindung, indem Sie eine
RoleBinding-Ressource im Projekt-Namespace bereitstellen:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
Laden Sie die Glossardatei in den von Ihnen erstellten Storage-Bucket hoch. Weitere Informationen finden Sie unter Speicherobjekte in Projekten hoch- und herunterladen.
Glossar erstellen
Mit der Methode CreateGlossary wird ein Glossar erstellt und die Kennung für den Vorgang mit langer Ausführungszeit zurückgegeben, mit dem das Glossar generiert wird.
Ersetzen Sie die folgenden Werte, bevor Sie die Anfragedaten verwenden, um ein Glossar zu erstellen:
ENDPOINT: Der Vertex AI Translation-Endpunkt, den Sie für Ihre Organisation verwenden. Weitere InformationenPROJECT_ID: Ihre Projekt-ID.GLOSSARY_ID: Ihre Glossar-ID, die Ihr Ressourcenname ist.BUCKET_NAME: Der Name des Storage-Buckets, in dem sich Ihre Glossardatei befindet.GLOSSARY_FILENAME: Der Name Ihrer Glossardatei im Storage-Bucket.
Nachfolgend finden Sie die Syntax für eine HTTP-Anfrage zum Erstellen eines Glossars:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
Wählen Sie anhand der von Ihnen erstellten Glossardatei eine der folgenden Optionen aus, um ein Glossar zu erstellen:
Unidirektional
Wenn Sie ein unidirektionales Glossar erstellen möchten, geben Sie ein Sprachpaar (language_pair) mit einer Ausgangssprache (source_language_code) und einer Zielsprache (target_language_code) an.
So erstellen Sie ein unidirektionales Glossar:
Speichern Sie den folgenden Anfragetext in einer JSON-Datei mit dem Namen
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Ersetzen Sie Folgendes:
SOURCE_LANGUAGE: der Sprachcode der Quellsprache des Glossars. Hier finden Sie eine Liste der unterstützten Sprachen und der entsprechenden Sprachcodes.TARGET_LANGUAGE: der Sprachcode der Zielsprache des Glossars. Hier finden Sie eine Liste der unterstützten Sprachen und der entsprechenden Sprachcodes.
Stellen Sie die Anfrage. In den folgenden Beispielen werden eine REST API-Methode und die Befehlszeile verwendet. Sie können jedoch auch Clientbibliotheken verwenden, um ein unidirektionales Glossar zu erstellen.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
Sie müssen eine JSON-Antwort ähnlich der folgenden erhalten:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Set äquivalenter Begriffe
Wenn Sie ein Glossar mit Sets äquivalenter Begriffe erstellen möchten, geben Sie ein Sprachset (language_codes_set) mit den Sprachcodes (language_codes) des Glossars an.
So erstellen Sie ein Glossar mit Sets äquivalenter Begriffe:
Speichern Sie den folgenden Anfragetext in einer JSON-Datei mit dem Namen
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Ersetzen Sie
LANGUAGE_CODEdurch den Code der Sprache oder Sprachen des Glossars. Hier finden Sie eine Liste der unterstützten Sprachen und der entsprechenden Sprachcodes.Stellen Sie die Anfrage:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
Sie müssen eine JSON-Antwort ähnlich der folgenden erhalten:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
Sie müssen eine JSON-Antwort ähnlich der folgenden erhalten:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
Installieren Sie die neueste Version der Vertex AI Translation-Clientbibliothek.
Erforderliche Umgebungsvariablen in einem Python-Skript festlegen
Fügen Sie dem von Ihnen erstellten Python-Skript den folgenden Code hinzu:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Speichern Sie das Python-Skript.
Führen Sie das Python-Skript aus:
python SCRIPT_NAME
Ersetzen Sie SCRIPT_NAME durch den Namen, den Sie Ihrem Python-Skript gegeben haben, z. B. glossary.py.
Weitere Informationen zur create_glossary-Methode finden Sie in der Python-Clientbibliothek.
Je nach Größe der Glossardatei dauert das Erstellen eines Glossars in der Regel weniger als 10 Minuten. Sie können den Status dieses Vorgangs abrufen, um festzustellen, wann er abgeschlossen ist.
Glossar abrufen
Die Methode GetGlossary gibt ein gespeichertes Glossar zurück. Wenn das Glossar nicht vorhanden ist, wird der Wert NOT_FOUND zurückgegeben. Geben Sie zum Aufrufen der Methode GetGlossary Ihre Projekt-ID und die Glossar-ID an. Sowohl die Methode CreateGlossary als auch die Methode ListGlossaries geben die Glossar-ID zurück.
Die folgenden Anfragen geben beispielsweise Informationen zu einem bestimmten Glossar in Ihrem Projekt zurück:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
Glossare auflisten
Die Methode ListGlossaries gibt eine Liste von Glossar-IDs in einem Projekt zurück. Wenn kein Glossar vorhanden ist, wird im Ergebnis der Wert NOT_FOUND zurückgegeben. Wenn Sie die Methode ListGlossaries aufrufen möchten, geben Sie Ihre Projekt-ID und den Vertex AI Translation-Endpunkt an.
Die folgende Anfrage gibt beispielsweise eine Liste der Glossar-IDs in Ihrem Projekt zurück:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.
Glossar löschen
Mit der Methode DeleteGlossary wird ein Glossar gelöscht. Wenn das Glossar nicht vorhanden ist, wird der Wert NOT_FOUND zurückgegeben. Wenn Sie die Methode DeleteGlossary aufrufen möchten, geben Sie Ihre Projekt-ID, Glossar-ID und den Vertex AI Translation-Endpunkt an.
Sowohl die Methode CreateGlossary als auch die Methode ListGlossaries geben die Glossar-ID zurück.
Mit der folgenden Anfrage wird beispielsweise ein Glossar aus Ihrem Projekt gelöscht:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Ersetzen Sie TOKEN durch das Authentifizierungstoken, das Sie erhalten haben.