本教學課程說明如何跨兩個 Google Cloud 區域部署及管理 Microsoft SQL Server 資料庫系統,做為災難復原 (DR) 解決方案,以及如何從發生故障的資料庫執行個體容錯移轉至正常運作的執行個體。在本文件中,災害是指主要資料庫發生故障或無法使用的事件。
如果主要資料庫所在的區域發生故障或無法存取,主要資料庫就會發生故障。即使區域可用且運作正常,主要資料庫仍可能因系統錯誤而發生故障。在這些情況下,災難復原是指讓次要資料庫可供用戶使用,以繼續處理資料的程序。
本教學課程適用於資料庫架構師、管理員和工程師。
瞭解災難復原
在 Google Cloud,災難復原 (DR) 是指提供持續處理作業的能力,尤其是在區域發生故障或無法存取時。對於資料庫管理系統等系統,您至少要在兩個區域部署系統,才能實作 DR。完成這項設定後,即使某個區域無法使用,系統仍可繼續運作。
資料庫系統災難復原
在主要資料庫執行個體發生故障時,讓次要資料庫代為提供服務的過程就稱為「資料庫災難復原」 (或「資料庫 DR」)。如要深入瞭解這個概念,請參閱「Microsoft SQL Server 的災難復原」。在理想情況下,次要資料庫的狀態會和主要資料庫不可用時的資料狀態一致,或者只遺失主要資料庫中一小部分的最新交易事件資料。
災難復原架構
針對 Microsoft SQL Server,下圖顯示支援資料庫 DR 的最低架構。
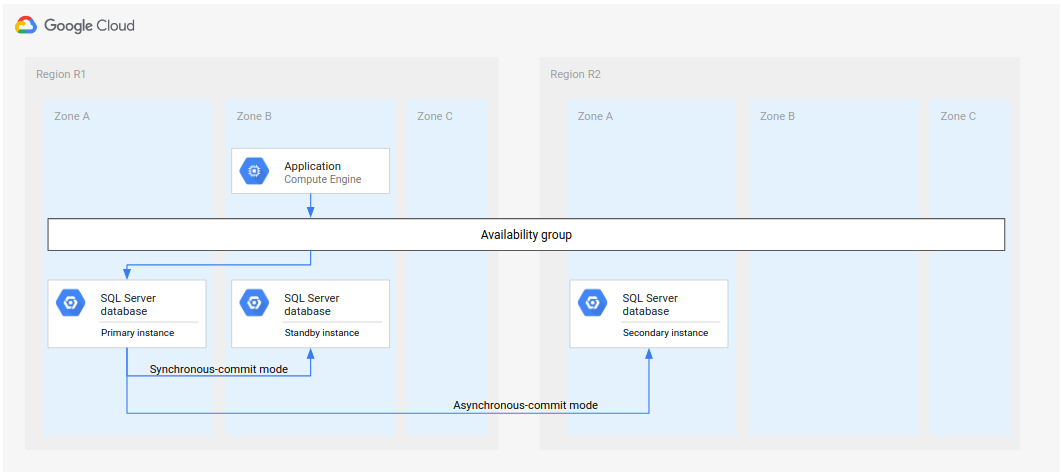
圖 1. Microsoft SQL Server 的標準災難復原架構。
架構的運作方式如下:
- 兩個 Microsoft SQL Server 執行個體 (主要執行個體和待命執行個體) 位於相同地區 (R1),但不同區域 (區域 A 和 B)。R1 中的兩個執行個體會使用同步提交模式協調狀態。由於同步模式支援高可用性,且可維持一致的資料狀態,因此採用這種模式。
- Microsoft SQL Server 的一個執行個體 (次要或災難復原執行個體) 位於第二個區域 (R2)。在 DR 中,R2 中的次要執行個體會使用非同步提交模式,與 R1 中的主要執行個體同步。由於非同步模式的效能較佳 (不會減緩主要執行個體中的提交處理程序),因此會使用這種模式。
在上圖中,架構顯示可用性群組。如果搭配接聽程式使用,可用性群組會為用戶端提供相同的連線字串,前提是這些用戶端是由下列項目提供服務:
- 主要執行個體
- 待命執行個體 (區域故障後)
- 次要執行個體 (區域發生故障後,次要執行個體會成為新的主要執行個體)
在上述架構的變體中,您會將第一個區域 (R1) 中的兩個執行個體部署到同一個區域。這個方法可能會提升效能,但可用性不高;您可能需要單一可用區中斷服務,才能啟動 DR 程序。
基本災難復原程序
當某個區域無法使用,且主要資料庫容錯移轉至其他運作中的區域以繼續處理作業時,就會啟動災難復原程序。DR 程序會規定必須採取的手動或自動作業步驟,以減輕區域故障的影響,並在可用區域中建立執行中的主要執行個體。
基本的資料庫災難復原程序包含下列步驟:
- 執行主要資料庫執行個體的第一個區域 (R1) 無法使用。
- 營運團隊會確認並正式承認發生災害,並決定是否需要容錯移轉。
- 如果需要容錯移轉,第二個區域 (R2) 中的次要資料庫執行個體會成為新的主要執行個體。
- 用戶端會在新的主要資料庫上繼續處理作業,並存取 R2 中的主要執行個體。
雖然這個基本程序可以重新建立可運作的主要資料庫,但無法建立完整的 DR 架構,也就是新的主要資料庫具有待命和次要資料庫執行個體。
完成災難復原程序
完整的 DR 程序會擴充基本 DR 程序,在容錯移轉後新增建立完整 DR 架構的步驟。下圖顯示完整的資料庫 DR 架構。
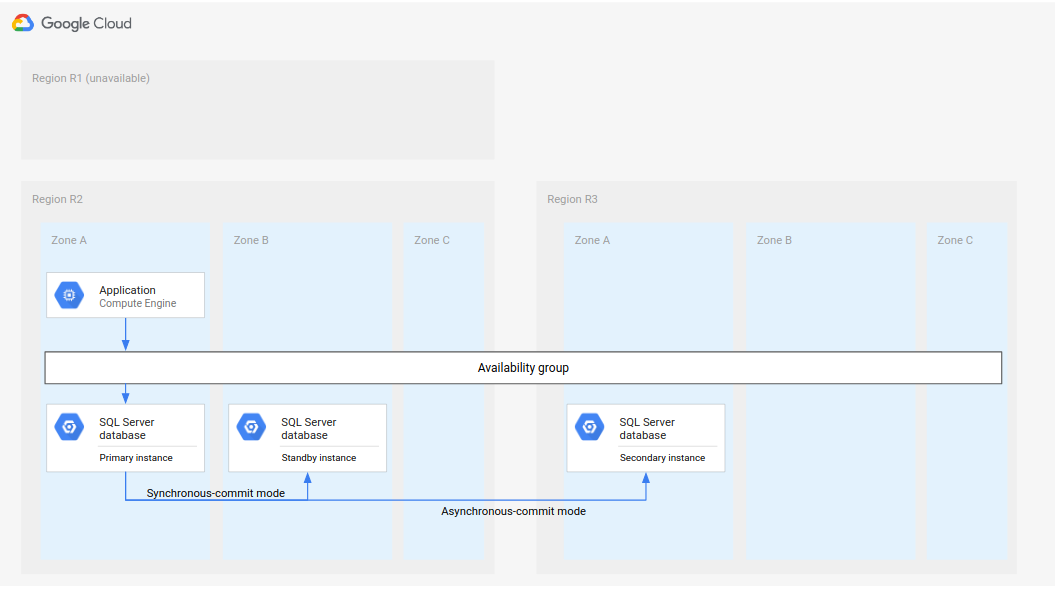
圖 2:主要區域 (R1) 無法使用時的災難復原。
這個完整的資料庫 DR 架構運作方式如下:
- 執行主要資料庫執行個體的第一個區域 (R1) 無法使用。
- 營運團隊會確認並正式承認發生災害,並決定是否需要容錯移轉。
- 如果需要容錯移轉,第二個區域 (R2) 中的次要資料庫執行個體會成為主要執行個體。
- 系統會在 R2 中建立並啟動另一個次要執行個體 (即新的待命執行個體),並新增至主要執行個體。備用執行個體與主要執行個體位於不同區域。主要資料庫現在由兩個高可用性執行個體 (主要和待命) 組成。
- 在第三個區域 (R3) 中,系統會建立並啟動新的次要 (待命) 資料庫執行個體。這個次要執行個體會以非同步方式連線至 R2 中的新主要執行個體。此時,原始的災難復原架構會重新建立並運作。
改用復原的區域
第一個區域 (R1) 恢復連線後,即可代管新的次要資料庫。如果 R1 很快就能恢復運作,您可以在 R1 (而非第三個地區 R3) 實作完整復原程序中的步驟 5。在這種情況下,不需要第三個區域。
下圖顯示 R1 準時推出時的架構。

圖 3:區域 R1 恢復運作後,進行災難復原。
在這個架構中,復原步驟與先前在「完成災害復原程序」一節中說明的步驟相同,差別在於 R1 會成為次要執行個體的位置,而不是 R3。
選擇 SQL Server 版本
本教學課程支援下列 Microsoft SQL Server 版本:
- SQL Server 2016 Enterprise 版
- SQL Server 2017 Enterprise 版
- SQL Server 2019 Enterprise 版
- SQL Server 2022 Enterprise 版
本教學課程會使用 SQL Server 中的 AlwaysOn 可用性群組功能。
如果您不需要高可用性 (HA) Microsoft SQL Server 主要資料庫,且單一資料庫執行個體就足以做為主要資料庫,則可以使用下列版本的 SQL Server:
- SQL Server 2016 Standard 版
- SQL Server 2017 Standard 版
- SQL Server 2019 Standard 版
- SQL Server 2022 Standard 版
SQL Server 2016、2017、2019 和 2022 版的映像檔已安裝 Microsoft SQL Server Management Studio,因此您不需要另外安裝。不過,在實際執行環境中,建議您在每個區域的獨立 VM 上安裝一個 Microsoft SQL Server Management Studio 執行個體。如果您設定高可用性環境,請為每個區域安裝一次 Microsoft SQL Server Management Studio,確保在其他區域無法使用時,該環境仍可運作。
設定 Microsoft SQL Server,以進行多區域災難復原
本節使用下列 Microsoft SQL Server 映像檔:
sql-ent-2016-win-2016,適用於 Microsoft SQL Server 2016 Enterprise 版sql-ent-2017-win-2016,適用於 Microsoft SQL Server 2017 Enterprise 版- Microsoft SQL Server 2019 Enterprise 版
sql-ent-2019-win-2019 sql-ent-2022-win-2022,適用於 Microsoft SQL Server 2022 Enterprise 版
如需完整清單,請參閱「圖片」。
設定雙例項高可用性叢集
如要為 SQL Server 設定多區域資料庫 DR 架構,請先在某個區域中建立雙執行個體高可用性 (HA) 叢集。一個執行個體做為主要執行個體,另一個執行個體則做為次要執行個體。如要完成這個步驟,請按照「設定 SQL Server AlwaysOn 可用性群組」一文中的操作說明進行。
本教學課程使用 us-central1 做為主要區域 (稱為 R1)。開始之前,請先詳閱下列注意事項:
如果您已按照「設定 SQL Server AlwaysOn 可用性群組」一文中的步驟操作,應該已在同一個區域 (
us-central1) 中建立兩個 SQL Server 執行個體。您會在us-central1-a中部署主要 SQL Server 執行個體 (node-1),並在us-central1-b中部署待命執行個體 (node-2)。雖然您在本教學課程中實作圖 4 的架構,但最佳做法是在多個區域中設定網域控制器。這種做法可確保您建立啟用 HA 和 DR 的資料庫架構。舉例來說,如果某個區域發生服務中斷情形,該區域不會成為您部署架構的單一故障點。

圖 4:本教學課程中實作的標準災難復原架構。
新增次要執行個體以進行災難復原
接著,您要設定第三個 SQL Server 執行個體 (名為 node-3 的次要執行個體),並設定網路,如下所示:
為 Windows Server 容錯移轉叢集節點建立專屬指令碼。這個指令碼會安裝必要的 Windows 功能,並為 WSFC 和 SQL Server 建立防火牆規則。此外,這項指令也會格式化資料磁碟,並為 SQL Server 建立資料和記錄檔資料夾:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
初始化下列變數:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8其中:
VPC_NAME:虛擬私有雲名稱SUBNET_NAME:us-east1地區的子網路名稱
建立 SQL Server 執行個體:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1為新的 SQL Server 執行個體設定 Windows 密碼:
在 Google Cloud 控制台中,前往 Compute Engine 頁面。
在 Compute Engine 叢集
node-3的「Connect」(連線) 欄中,選取「Set windows password」(設定 Windows 密碼) 下拉式清單。設定使用者名稱和密碼。請記下這些值,稍後會用到。
按一下「RDP」RDP即可連線至
node-3執行個體。輸入上一個步驟中的使用者名稱和密碼,然後按一下「確定」。
將執行個體加入 Windows 網域:
以滑鼠右鍵按一下「開始」按鈕 (或按下 Win+X 鍵),然後按一下「Windows PowerShell (系統管理員)」。
按一下「是」,確認提升權限提示。
將電腦加入 Active Directory 網域,然後重新啟動:
Add-Computer -Domain
DOMAIN -Restart將
DOMAIN換成 Active Directory 網域的 DNS 名稱。等待約 1 分鐘,讓裝置完成重新啟動。
將次要執行個體新增至容錯移轉叢集
接著,將次要執行個體 (node-3) 新增至 Windows 容錯移轉叢集:
使用遠端桌面協定連線至
node-1或node-2執行個體,並以管理員使用者身分登入。以管理員身分開啟 PowerShell 視窗,並為本教學課程中的叢集環境設定變數:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of cluster將
SQLSRV_CLUSTER替換成 SQL Server 叢集的名稱。將次要執行個體新增至叢集:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3這個指令可能需要一段時間才能執行,由於程序可能會停止回應,且不會自動返回,請偶爾按下
Enter。在節點中啟用 AlwaysOn 高可用性功能:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
節點現在是容錯移轉叢集的一部分。
將次要執行個體新增至現有可用性群組
接著,將 SQL Server 執行個體 (次要執行個體) 和資料庫新增至可用性群組:
node-3使用遠端桌面連線。 使用網域使用者帳戶登入。開啟 SQL Server 設定管理員。
在導覽窗格中,選取「SQL Server Services」
在服務清單中,以滑鼠右鍵按一下「SQL Server (MSSQLSERVER)」,然後選取「內容」。
在「登入身分」下方,變更帳戶:
- 帳戶名稱:
DOMAIN\sql_server其中DOMAIN是 Active Directory 網域的 NetBIOS 名稱。 - 「Password」(密碼):輸入您先前為 sql_server 網域帳戶選擇的密碼。
- 帳戶名稱:
按一下 [確定]。
系統提示重新啟動 SQL Server 時,請選取「是」。
在任一執行個體節點
node-1、node-2或node-3中,開啟 Microsoft SQL Server Management Studio,並連線至主要執行個體node-1。- 前往「物件總管」。
- 選取「連結」下拉式清單。
- 選取「資料庫引擎」。
- 在「伺服器名稱」下拉式清單中,選取
node-1。如果叢集未列出,請在欄位中輸入。
按一下「新查詢」。
貼上下列指令,將 IP 位址新增至節點使用的接聽器,然後按一下「執行」:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))將
LOAD_BALANCER_IP_ADDRESS替換為us-east1區域中負載平衡器的 IP 位址。在物件總管中,展開「AlwaysOn High Availability」節點,然後展開「Availability Groups」節點。
在名為
bookshelf-ag的可用性群組上按一下滑鼠右鍵,然後選取「新增副本」。在「Introduction」(簡介) 頁面上,按一下「AlwaysOn High Availability」(AlwaysOn 高可用性) 節點,然後按一下「Availability Groups」(可用性群組) 節點。
在「Connect to Replicas」(連線至副本) 頁面中,按一下「Connect」(連線),即可連線至現有的次要副本
node-2。在「Specify Replicas」(指定副本) 頁面中,按一下「Add Replica」(新增副本),然後新增節點
node-3。請勿選取「自動容錯移轉」,因為自動容錯移轉會導致同步提交。這類設定會跨越區域界線,因此我們不建議使用。在「Select Data Synchronization」(選取資料同步處理) 頁面上,選取「Automatic seeding」(自動播種)。
由於沒有接聽程式,「Validation」(驗證) 頁面會產生警告,您可以忽略這個警告。
完成精靈步驟。
node-1 和 node-2 的容錯移轉模式為自動,node-3 則為手動。這項差異是區分高可用性和災難復原的方法之一。
可用性群組現在已準備就緒。您設定了兩個節點來確保高可用性,並設定第三個節點來進行災難復原。
模擬災難復原
在本節中,您將測試本教學課程的災難復原架構,並考慮選用的 DR 實作方式。
模擬服務中斷並執行 DR 容錯移轉
模擬主要區域發生故障或服務中斷情形:
在 Microsoft SQL Server Management Studio 中,連線至
node-1。node-1建立表格。在後續步驟中新增副本後,請檢查是否有這個表格,確認副本是否正常運作。
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GO在 Cloud Shell 中,關閉主要區域
us-central1中的兩部伺服器:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
在
node-3的 Microsoft SQL Server Management Studio 中,連線至node-3。執行容錯移轉,並將可用性模式設為同步提交。節點處於非同步提交模式,因此必須強制執行容錯移轉。
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO您可以繼續處理,因為
node-3現在是主要執行個體。(選用) 在
node-3中建立新表格。將備用資源與新的主要執行個體同步處理後,請檢查這個資料表是否已複製到備用資源。USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
雖然此時 node-3 是主要區域,但您可能想還原至原始區域,或設定新的次要執行個體和待命執行個體,以便再次重建完整的 DR 架構。下一節將討論這些選項。
(選用) 重新建立可完整複製交易的 DR 架構
這個用途是解決主要資料庫故障前,所有交易都已從主要資料庫複製到次要資料庫的情況。在這種理想情況下,資料不會遺失,次要資料庫的狀態與主要資料庫在故障時的狀態一致。
在此情境中,您可以透過下列兩種方式,重新建立完整的 DR 架構:
- 還原為原始主要節點和原始待命節點 (如有)。
- 如果原始主要和待命執行個體無法使用,請為
node-3建立新的待命和次要執行個體。
方法 1:還原為原始的主要和備用伺服器
在 Cloud Shell 中,啟動原始 (舊) 主要和待命執行個體:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quiet在 Microsoft SQL Server Management Studio 中,將
node-1和node-2加回做為次要副本:在
node-3上,以非同步提交模式新增兩個伺服器:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO在
node-1上,再次開始同步處理資料庫:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO在
node-2上,再次開始同步處理資料庫:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
再次將
node-1設為主要:在
node-3中,將node-1的可用性模式變更為 synchronous-commit。執行個體會再次成為主要執行個體。node-1USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO在
node-1上,將node-1變更為主要節點,另外兩個節點則變更為次要節點:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
所有指令都成功執行後,node-1 會成為主要節點,其他節點則為次要節點,如下圖所示。
方法 2:設定新的主要和待命執行個體
您可能無法從故障中復原原始主要和待命執行個體,或復原時間過長,或無法存取該區域。其中一種做法是保留 node-3 做為主要執行個體,然後建立新的待命和次要執行個體,如下圖所示。
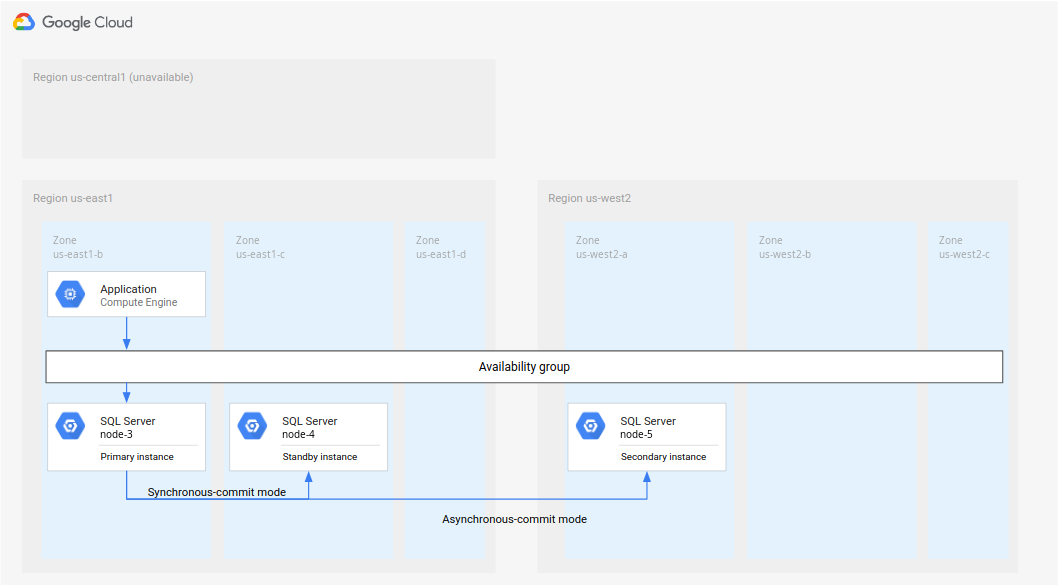
圖 5. 災難復原,但原始主要區域 R1 無法使用。
如要實作這項功能,您必須完成下列步驟:
將
node-3設為us-east1中的主要項目。在
us-east1的不同區域中新增備援執行個體 (node-4)。這個步驟會將新部署作業設為高可用性。在其他區域建立新的次要執行個體 (
node-5),例如us-west2。這個步驟會設定新的部署作業,以進行災難復原。整體部署作業現已完成。資料庫架構全面支援高可用性和災難復原。
(選用) 交易遺失時執行備援
如果主要資料庫上已確認的一或多筆交易,在發生故障時未複製到次要資料庫 (也稱為硬體故障),就屬於不理想的故障情況。在容錯移轉中,所有未複製的已提交交易都會遺失。
如要測試這個情境的容錯移轉步驟,您需要產生硬體故障。產生硬體故障的最佳方法如下:
- 變更網路,讓主要和次要執行個體之間沒有連線。
- 以某種方式變更主要檔案,例如新增表格或插入一些資料。
- 按照先前的說明逐步完成容錯移轉程序,將次要資料庫設為新的主要資料庫。
容錯移轉程序的步驟與理想情況相同,但網路連線中斷後新增至主要執行個體的資料表,不會顯示在次要執行個體中。
處理硬體故障的唯一方法是從可用性群組中移除副本 (node-1 和 node-2),然後再次同步副本。同步作業會變更狀態,以符合次要裝置的狀態。失敗前未複製的任何交易都會遺失。
如要新增 node-1 做為次要執行個體,請按照先前新增 node-3 的步驟操作 (請參閱先前的「將次要執行個體新增至容錯移轉叢集」一節),但有以下差異:node-3 現在是主要執行個體,而非 node-1。您必須將所有 node-3 執行個體取代為您新增至可用性群組的伺服器名稱。如果重複使用相同的 VM (node-1 和 node-2),則不需要將伺服器新增至 Windows Server 容錯移轉叢集,只要將 SQL Server 執行個體加回可用性群組即可。
此時,node-3 是主要節點,node-1 和 node-2 是次要節點。現在可以回復為 node-1,將 node-2 設為待機,並將 node-3 設為次要。系統現在的狀態與發生故障前相同。
自動容錯移轉
自動容錯移轉至次要執行個體做為主要執行個體可能會造成問題。原始主要執行個體恢復運作後,如果部分用戶端存取次要執行個體,而其他用戶端寫入還原的主要執行個體,就可能發生腦裂情況。在這種情況下,主要和次要項目可能會平行更新,且狀態會有所差異。為避免發生這種情況,本教學課程提供手動容錯移轉的操作說明,讓您決定是否 (或何時) 要進行容錯移轉。
如果您實作自動容錯移轉,請務必確保只有一個設定的執行個體是主要執行個體,且可以修改。任何待命或次要執行個體都不得提供任何用戶端寫入權限 (狀態複製的主要執行個體除外)。此外,請避免在短時間內快速連續進行容錯移轉。舉例來說,每五分鐘執行一次容錯移轉,並非可靠的災難復原策略。對於自動容錯移轉程序,您可以建立防護措施,避免發生這類問題情境,甚至在必要時請資料庫管理員協助做出複雜決策。
其他部署架構
本教學課程會設定災難復原架構,其中包含一個次要執行個體,在容錯移轉時會成為主要執行個體,如下圖所示。

圖 6:使用 Microsoft SQL Server 的標準災難復原架構。
也就是說,如果發生容錯移轉,在可以回復或設定待命 (適用於高可用性) 和次要 (適用於災害復原) 執行個體之前,產生的部署作業只會有一個執行個體。
另一種部署架構是設定兩個次要執行個體。兩個執行個體都是主要執行個體的副本。如果發生容錯移轉,您可以將其中一個次要備用資源重新設定為待命資源。下圖顯示容錯移轉前後的部署架構。

圖 7. 標準災難復原架構,包含兩個次要執行個體。
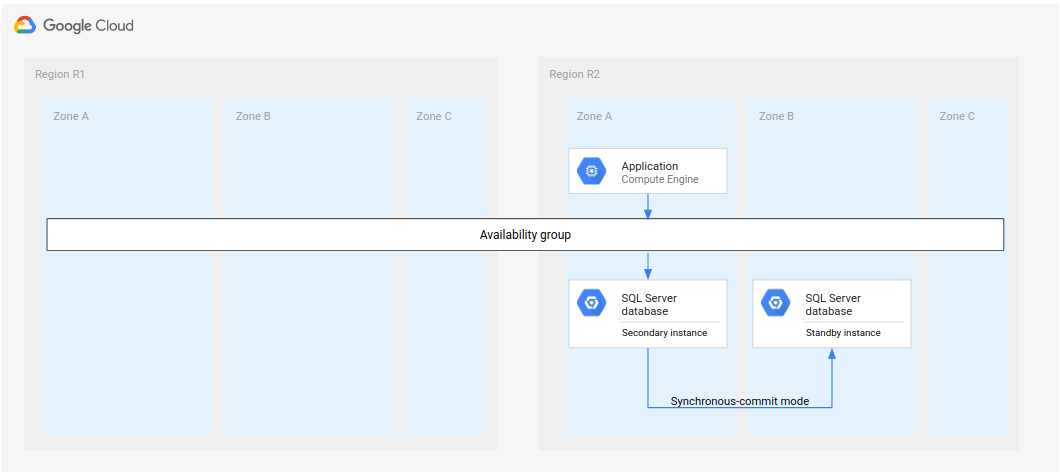
圖 8. 標準災難復原架構,故障轉移後有兩個次要執行個體。
您仍須將其中一個次要執行個體設為待命狀態 (圖 8),但這個程序比從頭建立及設定新的待命執行個體快得多。
您也可以使用類似於這個架構的設定來處理 DR,也就是使用兩個次要執行個體。除了在第二個區域中擁有兩個次要資料庫 (圖 7),您還可以在第三個區域中部署另外兩個次要資料庫。設定完成後,您就能在主要區域發生故障時,有效率地建立啟用 HA 和 DR 的部署架構。