您可以使用 Ops Agent 追蹤虛擬機器 (VM) 執行個體的指標,例如 GPU 使用率和 GPU 記憶體。這是 Google 建議用於 Compute Engine 的遙測資料收集解決方案。使用 Ops Agent 時,您可以透過下列方式管理 GPU VM:
- 透過預先設定的資訊主頁,以視覺化方式呈現 NVIDIA GPU 機群的健康狀態。
- 找出未充分運用的 GPU 並整合工作負載,以最佳化成本。
- 查看趨勢來規劃調度資源,決定何時擴充 GPU 容量或升級現有 GPU。
- 使用 NVIDIA Data Center GPU Manager (DCGM) 剖析指標,找出 GPU 內的瓶頸和效能問題。
- 設定代管執行個體群組 (MIG),自動調度資源。
- 接收 NVIDIA GPU 指標的快訊。
本文說明如何使用 Ops Agent 監控 Linux VM 的 GPU。此外,GitHub 上也提供報表指令碼,可用於監控 Linux VM 的 GPU 使用量,請參閱compute-gpu-monitoring監控指令碼。我們不會積極維護這個指令碼。
如要監控 Windows VM 的 GPU,請參閱「監控 GPU 效能 (Windows)」。
總覽
只要在 Linux VM 安裝 2.38.0 以上版本的 Ops Agent,即可自動追蹤 GPU 使用率和 GPU 記憶體用量。這些指標是從 NVIDIA 管理程式庫 (NVML) 取得,會針對使用 GPU 的任何程序,追蹤每個 GPU 和程序的指標。如要查看作業套件代理程式監控的指標,請參閱「代理程式指標:gpu」。
您也可以透過 Ops Agent 設定 NVIDIA Data Center GPU Manager (DCGM) 整合。這項整合可讓 Ops Agent 使用 GPU 上的硬體計數器追蹤指標。DCGM 可存取 GPU 裝置層級指標。包括串流多重處理器 (SM) 區塊使用率、SM 占用率、SM 管道使用率、PCIe 流量速率和 NVLink 流量速率。如要查看 Ops Agent 監控的指標,請參閱「第三方應用程式指標:NVIDIA Data Center GPU Manager (DCGM)」。
如要使用 Ops Agent 查看 GPU 指標,請完成下列步驟:
- 檢查每個 VM 是否符合需求。
- 在每個 VM 上安裝作業套件代理程式。
- 選用:在每個 VM 上設定 NVIDIA Data Center GPU Manager (DCGM) 整合。
- 在 Cloud Monitoring 中查看指標。
限制
- 如果 VM 使用 Container-Optimized OS,Ops Agent 就不會追蹤 GPU 使用率。
需求條件
檢查每個 VM 是否符合下列要求:
- 每個 VM 都必須連結 GPU。
- 每個 VM 都必須安裝 GPU 驅動程式。
- 每個 VM 的 Linux 作業系統和版本都必須支援 Ops Agent。請參閱這篇文章,瞭解作業套件代理程式支援的 Linux 作業系統。
- 確認您有權存取每個 VM。
sudo
安裝作業套件代理程式
如要安裝作業套件代理程式,請完成下列步驟:
如果您先前使用
compute-gpu-monitoring監控指令碼追蹤 GPU 使用率,請先停用該服務,再安裝 Ops Agent。如要停用監控指令碼,請執行下列指令:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
安裝最新版本的作業套件代理程式。如需詳細操作說明,請參閱安裝 Ops 代理程式。
安裝 Ops Agent 後,如需使用 Compute Engine 提供的安裝指令碼安裝或升級 GPU 驅動程式,請參閱「限制」一節。
在 Compute Engine 中查看 NVML 指標
您可以透過 Compute Engine Linux VM 執行個體的「可觀測性」分頁,查看 Ops Agent 收集的 NVML 指標。
如要查看單一 VM 的指標,請按照下列步驟操作:
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面。
選取 VM,開啟「詳細資料」頁面。
按一下「可觀測性」分頁標籤,即可顯示 VM 相關資訊。
選取「GPU」快速篩選器。
如要查看多部 VM 的指標,請按照下列步驟操作:
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面。
點選「Observability」(觀測能力) 分頁標籤。
選取「GPU」快速篩選器。
選用:設定 NVIDIA Data Center GPU Manager (DCGM) 整合
此外,Ops Agent 也提供 NVIDIA Data Center GPU Manager (DCGM) 的整合功能,可收集重要的進階 GPU 指標,例如串流多處理器 (SM) 區塊使用率、SM 占用率、SM 管道使用率、PCIe 流量速率和 NVLink 流量速率。
系統不會從 NVIDIA P100 和 P4 型號收集這些進階 GPU 指標。
如需在每個 VM 上設定及使用這項整合功能的詳細操作說明,請參閱「NVIDIA Data Center GPU Manager (DCGM)」。
在 Cloud Monitoring 中查看 DCGM 指標
在 Google Cloud 控制台中,前往「Monitoring > Dashboards」頁面。
選取「範例庫」分頁標籤。
在「Filter」欄位中,輸入「NVIDIA」。系統會顯示「NVIDIA GPU Monitoring Overview (GCE and GKE)」資訊主頁。
如果您已設定 NVIDIA Data Center GPU Manager (DCGM) 整合,系統也會顯示「NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only)」(NVIDIA GPU 監控進階 DCGM 指標 (僅限 GCE)) 資訊主頁。
按一下所需資訊主頁的「預覽」。畫面上會顯示「預覽樣本資訊主頁」頁面。
在「預覽樣本資訊主頁」頁面中,按一下「匯入樣本資訊主頁」。
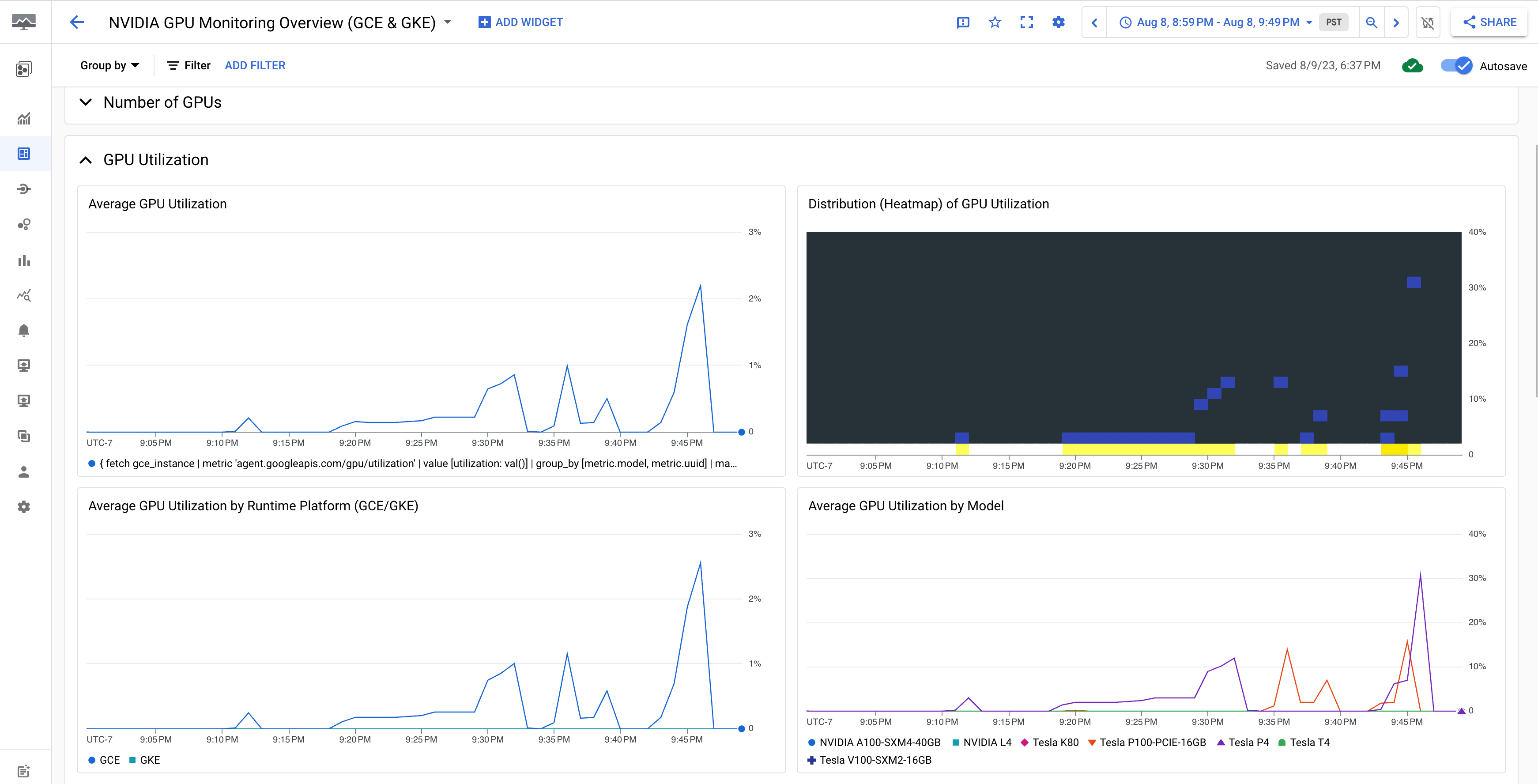
NVIDIA GPU 監控總覽 (GCE 和 GKE) 資訊主頁會顯示 GPU 指標,例如 GPU 使用率、NIC 流量速率和 GPU 記憶體用量。
您的 GPU 使用率顯示畫面應類似下列輸出內容:
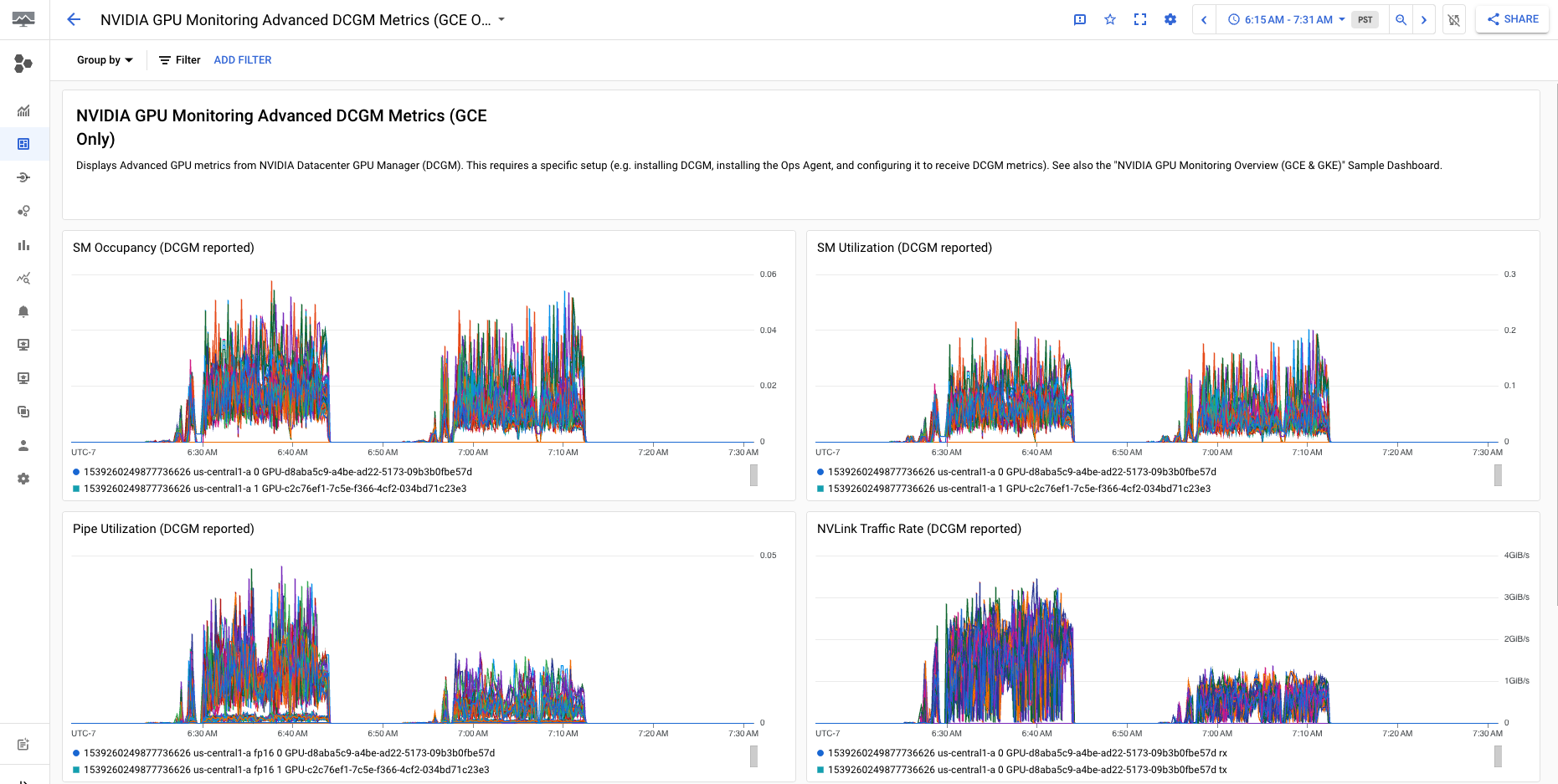
「NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only)」資訊主頁會顯示重要的進階指標,例如 SM 使用率、SM 占用率、SM 管道使用率、PCIe 流量速率和 NVLink 流量速率。
進階 DCGM 指標顯示畫面應類似下列輸出內容:
後續步驟
- 如要處理 GPU 主機維護作業,請參閱「處理 GPU 主機維護事件」。
- 如要提升網路效能,請參閱「使用較高的網路頻寬」。