Para verificar a integridade de um disco permanente ou de um volume do Hyperdisk do Google Cloud, analise a métrica de status de desempenho do disco. Essa métrica indica se o desempenho do disco pode ser afetado por eventos adversos no Compute Engine.
Um problema que afeta o status de desempenho do disco também pode aparecer no painel Personalized Service Health (PSH) do seu projeto ou no painel Google Cloud Service Health.
Este documento aborda o status de desempenho do disco e como usá-lo para resolver problemas de desempenho.
Quando verificar a integridade de um disco
Se você notar um problema de desempenho com um disco, verifique a integridade dele analisando a métrica de status de desempenho do disco. A métrica de status de desempenho do disco é atualizada a cada minuto e representa o desempenho do disco durante todo o minuto anterior. Para conferir as etapas de verificação da integridade do disco, consulte Ver o status de desempenho do disco.
A tabela a seguir resume os valores possíveis do status de desempenho do disco.
| Status | Significado |
|---|---|
Healthy |
O desempenho do disco está dentro do esperado. |
Degraded |
Talvez você observe temporariamente uma latência de E/S maior do que o esperado. |
Severely degraded |
Ocorrem alta latência de E/S ou outros erros. |
Se o status de performance não for Healthy, consulte Entenda cada status para saber as próximas etapas.
Se o status de performance for Healthy, o disco estará funcionando normalmente e você precisará verificar outras causas para o problema de performance.
Verifique se há erros no aplicativo ou no sistema operacional e se o disco está otimizado corretamente. Para diretrizes de otimização, consulte Otimizar o Hyperdisk e Otimizar o Persistent Disk.
Como a integridade do disco se relaciona a outras métricas de desempenho
A integridade do disco, conforme indicado pela métrica de status de performance, mostra o status interno do disco na perspectiva do Google. Se o status de um disco for
Degraded ou Severely Degraded, a causa raiz sempre estará na
infraestrutura do Compute Engine.
Em geral, não é possível mudar a integridade de um disco modificando a carga de trabalho. No entanto, em casos raros, uma mudança na carga de trabalho pode acionar um problema interno. Por isso, é possível atenuar um problema modificando a carga de trabalho.
Para saber mais sobre as outras métricas de desempenho de disco disponíveis, consulte Analisar métricas de desempenho de disco.
Cenários que não afetam o status de desempenho do disco
O status de desempenho do disco não está relacionado a problemas de desempenho causados pelos seguintes fatores:
- Otimização incompleta ou insuficiente do disco
- Limite de desempenho associado ao disco e ao tipo de máquina (se o tipo de máquina escolhido não atender aos requisitos de desempenho da sua carga de trabalho)
- Aumento da carga no disco devido ao tráfego da carga de trabalho
- Erro de usuário, aplicativo ou sistema operacional
- Discos cheios ou corrompidos
- Para volumes do Hyperdisk e do Extreme Persistent Disk, IOPS ou capacidade de processamento provisionadas de forma insuficiente.
Nessas situações, é sua responsabilidade melhorar o desempenho, por exemplo, otimizando o disco, escalonando a carga de trabalho, mudando o tipo de máquina e provisionando mais capacidade, IOPS ou capacidade de processamento.
Conferir a integridade de um disco no Cloud Monitoring
Para conferir a integridade de um disco, crie um gráfico no Metrics Explorer.
Papéis e permissões necessárias
Para ter as permissões necessárias para verificar a métrica de status de desempenho do disco, peça ao administrador para conceder a você os seguintes papéis do IAM no projeto:
-
Leitor do Monitoring (
roles/monitoring.viewer) -
Para salvar um gráfico em um painel:
Editor do Monitoring (
roles/monitoring.editor)
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Também é possível conseguir as permissões necessárias usando papéis personalizados ou outros papéis predefinidos.
Criar um gráfico no Metrics Explorer
Para criar um gráfico, crie uma consulta com a interface orientada por menu ou o PromQL.
Interface orientada por menus
Para conferir a integridade de um ou mais discos em um gráfico, siga estas instruções.
-
No console Google Cloud , acesse a página do leaderboard Metrics explorer:
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Monitoring.
- Na barra de ferramentas do console Google Cloud , selecione seu projeto Google Cloud . Para configurações do App Hub, selecione o projeto host do App Hub ou o projeto de gerenciamento da pasta habilitada para apps.
- No elemento Metric, expanda o menu Selecionar uma métrica,
digite
VM Instancena barra de filtro e use os submenus para selecionar um tipo de recurso e métrica específicos:- No menu Recursos ativos, selecione Instância de VM.
- No menu Categorias de métrica ativas, selecione Instância.
- No menu Métricas ativas, selecione Status de desempenho do disco.
- Clique em Aplicar.
compute.googleapis.com/instance/disk/performance_status. Para adicionar filtros que removem séries temporais dos resultados da consulta, use o elemento Filtro.
- Configure a visualização dos dados.
Desative a agregação. Verifique se, no elemento Agregação, o primeiro menu está definido como Não agregado e o segundo como Nenhum.
Para conferir a integridade de um disco específico, filtre pordevice_name.
Para mais informações sobre como configurar um gráfico, consulte Selecionar métricas ao usar o Metrics Explorer.
PromQL
Abra o editor de consultas: siga as etapas em Escrever consultas em PromQL.
Digite a consulta no Editor de consultas. Por exemplo, para conferir o status de desempenho de um disco específico, insira a seguinte consulta:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
Substitua DISK_NAME pelo nome do disco, por exemplo, disk-1.
Se você visualizar os resultados em um gráfico, haverá três linhas para cada disco, uma para cada status possível. Da mesma forma, se você visualizar o resultado da consulta em uma tabela, ela terá três linhas para cada disco.
Se você criou a consulta com PromQL, cada linha ou linha terá um valor de 1 ou 0. Para consultas criadas com os menus, os valores de
serão 100% ou 0.
A integridade atual do disco é representada pela linha ou linha cujo valor é 100%
ou 1.
Por exemplo, a captura de tela a seguir mostra o gráfico de um disco chamado a-test-VM,
cujo status é Healthy:
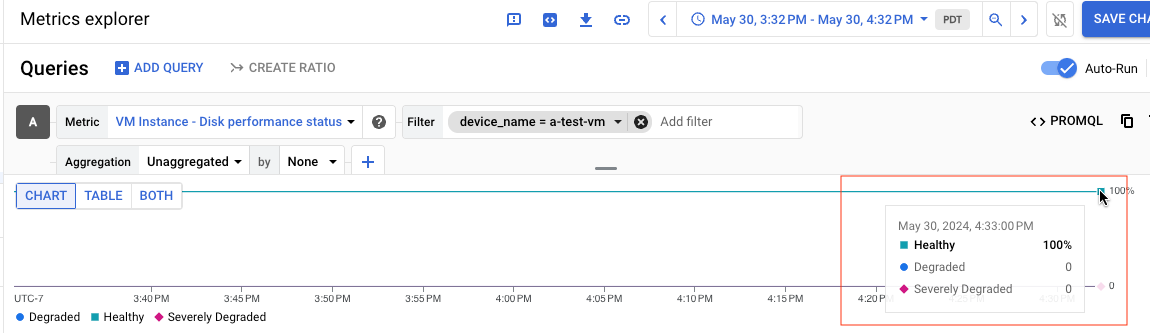
Se você visualizar os resultados da consulta como uma tabela, a tabela a seguir será um exemplo dos resultados de um disco Healthy:
| performance_status | valor |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
A captura de tela a seguir mostra o gráfico de um disco chamado replica-23509 com status Degradado:
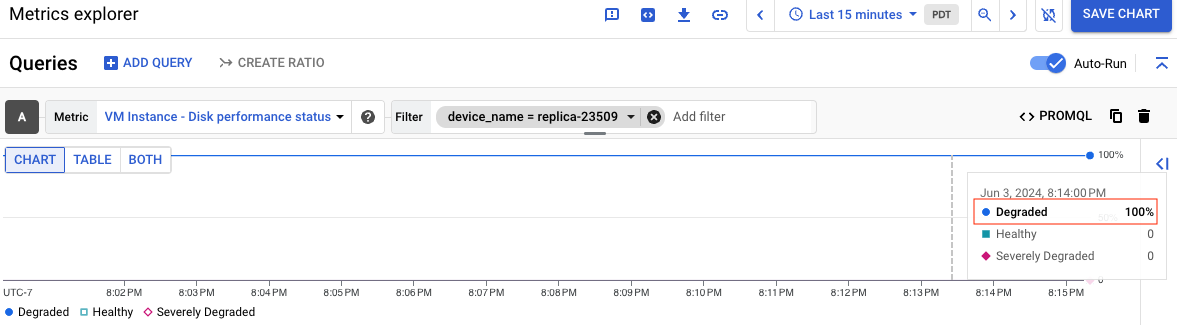
Para informações sobre o que cada status de performance significa, consulte Entenda cada status. Depois de criar o gráfico, você pode salvá-lo em um painel para uso futuro.
Resultados fracionários
Se a consulta incluir resultados fracionários, como na tabela a seguir, isso geralmente acontece porque o período de exibição selecionado foi longo. Como resultado, o Cloud Monitoring agregou os dados ao longo do tempo.
Um valor de 77% para o status Healthy significa que o status do disco foi Healthy 77% do período de exibição selecionado.
| performance_status | valor |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
Para uma visão mais detalhada da integridade de um disco, use um período de exibição de algumas horas ou alguns minutos.
Entender cada status
Esta seção discute o que cada status significa e quando você precisa tomar outras medidas.
Healthy
O status Healthy indica que, da perspectiva do Google, o disco está
funcionando normalmente.
Se um disco Healthy tiver problemas de desempenho, não entre em contato com o suporte. Em vez disso, resolva o problema do disco usando algumas das seguintes sugestões:
- Analise as métricas de desempenho do disco, como latência e profundidade da fila.
- Verifique os registros e as métricas da sua carga de trabalho para identificar anomalias e gargalos.
- Se você estiver usando um disco permanente, verifique se a capacidade provisionada atende às necessidades de desempenho do disco. Se você estiver usando volumes do Hyperdisk ou do Extreme Persistent Disk, verifique se provisionou IOPS e capacidade suficientes.
- Verifique se você seguiu as diretrizes para otimizar o disco. Para mais informações, consulte Otimizar o Hyperdisk e Otimizar o disco permanente.
Degraded
Normalmente, não é necessário entrar em contato com o suporte se o status do disco for Degraded. Um Degraded status geralmente é causado por uma manutenção interna normal na infraestrutura do Compute Engine.
Talvez você não note nenhum impacto na performance do disco enquanto o status for
Degraded. Se o problema de performance e o status Degraded tiverem correlação temporal, o problema de performance ainda poderá não estar relacionado ao status Degraded.
No caso improvável de um problema de desempenho ser causado pelo status Degraded,
o impacto geralmente é temporário. O status do disco vai voltar para Healthy em alguns minutos.
Você pode ignorar o status Degraded se não houver problemas de performance com o disco.
O que fazer se houver um problema de desempenho
Se o status de desempenho do disco for Degraded e você estiver observando um problema de desempenho, siga estas etapas:
- Verifique o painel do PSH para saber se há um incidente afetando o disco. Se houver um incidente, não entre em contato com o suporte. O Google já está ciente e trabalhando para resolver o problema.
- Se não houver problemas conhecidos, aguarde pelo menos 5 minutos para que o problema de desempenho seja resolvido sozinho.
Se, após 5 minutos, o problema de desempenho não for resolvido e o status ainda for
Degraded, verifique se o problema não está ocorrendo porque o disco não está otimizado o suficiente. Por exemplo, verifique a latência e a profundidade da fila do disco. É possível que o problema de desempenho e o statusDegradednão estejam relacionados e sejam apenas uma coincidência. Para isso, analise as métricas do disco e as diretrizes de otimização de desempenho.Se os problemas de desempenho continuarem e todas as condições a seguir forem atendidas, entre em contato com o suporte para receber ajuda:
- O status do disco é
Degradedhá mais de 5 minutos - Você tem certeza de que não é um problema de carga de trabalho porque otimizou o disco e verificou que não há outros problemas, como um gargalo ou um aplicativo sobrecarregado.
- Não há alertas no painel do PSH
- O status do disco é
O Google não recomenda criar um alerta diretamente para o status Degraded. Em vez disso, crie alertas para o status do aplicativo de nível superior e use essa métrica para depurar problemas.
Severely Degraded
Um disco com status de desempenho Severely Degraded está com um problema de desempenho. Esse problema pode ser causado por um incidente ou erro e talvez já esteja visível no painel do PSH ou no painel Google Cloud Service Health.
O que fazer
Se o status de desempenho do disco for Severely Degraded, siga estas etapas:
- Confira o painel do PSH e o painel de integridade geral Google Cloud para ver se há um incidente afetando o disco. Se houver um incidente, não entre em contato com o suporte. O Google já está ciente e trabalhando para resolver o problema.
- Se não houver problemas conhecidos nos dois painéis, entre em contato com o suporte para receber ajuda.
Árvore de decisão
O diagrama a seguir ilustra como proceder se um disco tiver um problema de desempenho e resume as informações das seções anteriores.

Como mostrado no fluxograma, entre em contato com o suporte apenas se não houver alertas conhecidos nos painéis do PSH e do serviço do Cloud e se o status do disco for Severely Degraded. Se o disco for Degraded, entre em contato com o suporte apenas se todas as condições a seguir forem atendidas:
- O disco está
Degradedhá mais de 5 minutos - Você descartou um erro ou configuração incorreta de carga de trabalho (como problemas de rede)
- Não é possível fazer outras otimizações no nível do aplicativo, da carga de trabalho ou do disco.
- Você revisou todas as métricas do disco
- Você analisou os registros da carga de trabalho e da máquina virtual (VM)
A seguir
- Saiba mais sobre como criar gráficos com o Metric Explorer e como refinar os resultados da consulta adicionando filtros a um gráfico.
- Verifique eventos ativos e anteriores de integridade do serviço no painel de integridade do serviço pessoal e no Google Service Health
- Para diretrizes de otimização de desempenho, consulte Otimizar o Hyperdisk e Otimizar o disco permanente.