The Gemini API code execution feature enables the model to generate and run Python code and learn iteratively from the results until it arrives at a final output. You can use this code execution capability to build applications that benefit from code-based reasoning and that produce text output. For example, you could use code execution in an application that solves equations or processes text.
The Gemini API provides code execution as a tool, similar to function calling. After you add code execution as a tool, the model decides when to use it.
The code execution environment includes the following libraries. You can't install your own libraries.
- Altair
- Chess
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulate
Supported models
The following models provide support for code execution:
- Gemini 2.5 Flash (Preview)
- Gemini 2.5 Flash-Lite (Preview)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash with Live API (Preview)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Get started with code execution
This section assumes that you've completed the setup and configuration steps shown in the Gemini API quickstart.
Enable code execution on the model
You can enable basic code execution as shown here:
Python
Install
pip install --upgrade google-genai
To learn more, see the SDK reference documentation.
Set environment variables to use the Gen AI SDK with Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Learn how to install or update the Go.
To learn more, see the SDK reference documentation.
Set environment variables to use the Gen AI SDK with Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Install
npm install @google/genai
To learn more, see the SDK reference documentation.
Set environment variables to use the Gen AI SDK with Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Learn how to install or update the Java.
To learn more, see the SDK reference documentation.
Set environment variables to use the Gen AI SDK with Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Before using any of the request data, make the following replacements:
GENERATE_RESPONSE_METHOD: The type of response that you want the model to generate. Choose a method that generates how you want the model's response to be returned:streamGenerateContent: The response is streamed as it's being generated to reduce the perception of latency to a human audience.generateContent: The response is returned after it's fully generated.
LOCATION: The region to process the request. Available options include the following:Click to expand a partial list of available regions
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: Your project ID.MODEL_ID: The model ID of the model that you want to use.ROLE: The role in a conversation associated with the content. Specifying a role is required even in singleturn use cases. Acceptable values include the following:USER: Specifies content that's sent by you.MODEL: Specifies the model's response.
TEXT
To send your request, choose one of these options:
curl
Save the request body in a file named request.json.
Run the following command in the terminal to create or overwrite
this file in the current directory:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFThen execute the following command to send your REST request:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Save the request body in a file named request.json.
Run the following command in the terminal to create or overwrite
this file in the current directory:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Then execute the following command to send your REST request:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
You should receive a JSON response similar to the following.
Use code execution in chat
You can also use code execution as part of a chat.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Code execution versus function calling
Code execution and function calling are similar features:
- Code execution lets the model run code in the API backend in a fixed, isolated environment.
- Function calling lets you run the functions that the model requests, in whatever environment you want.
In general, you should prefer to use code execution if it can handle your use
case. Code execution is simpler to use (you just enable it) and resolves in a
single GenerateContent request. Function calling takes an additional
GenerateContent request to send back the output from each function call.
For most cases, you should use function calling if you have your own functions that you want to run locally, and you should use code execution if you'd like the API to write and run Python code for you and return the result.
Billing
There's no additional charge for enabling code execution from the Gemini API. You'll be billed at the current rate of input and output tokens based on what Gemini model you're using.
Here are a few other things to know about billing for code execution:
- You're only billed once for the input tokens you pass to the model and the intermediate input tokens generated by the code execution tool use.
- You're billed for the final output tokens returned to you in the API response.
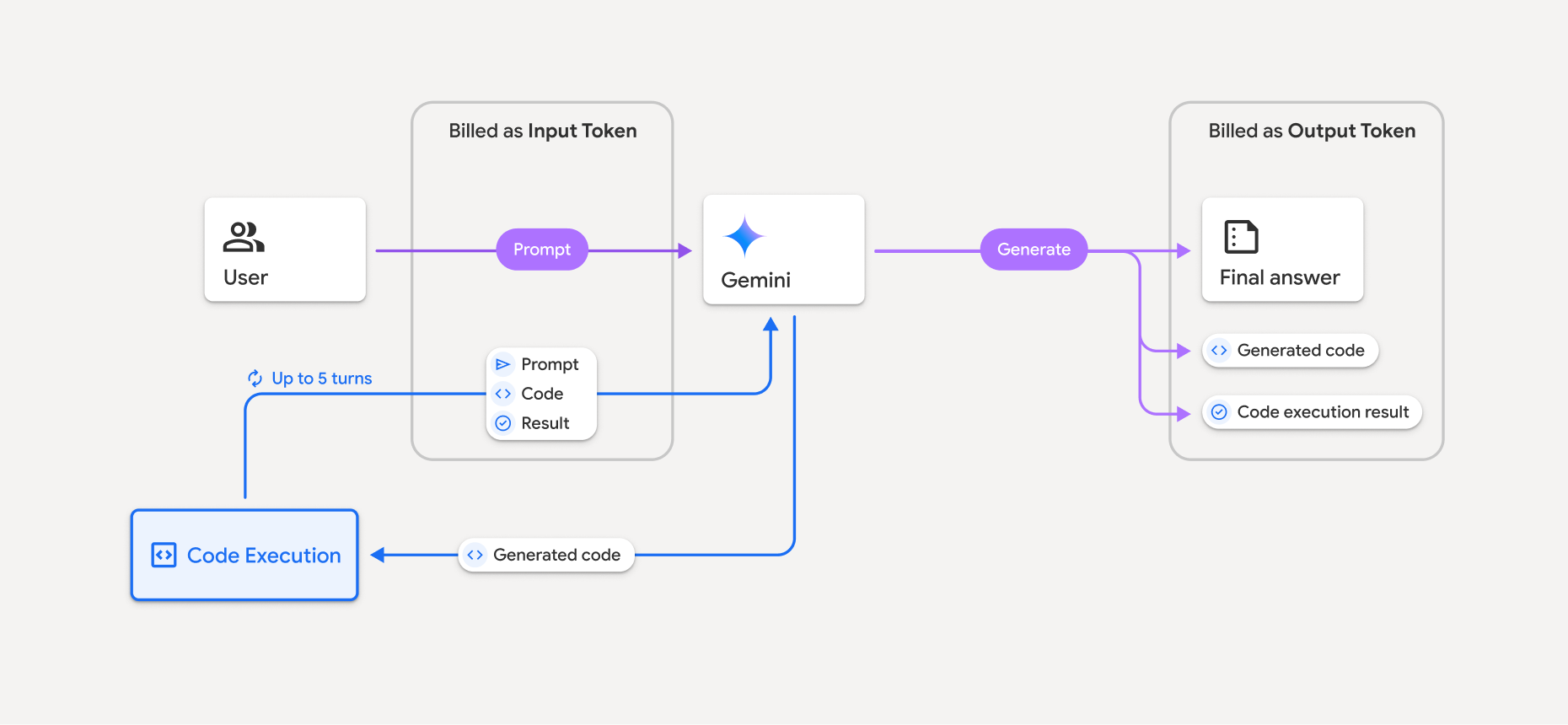
- You're billed at the current rate of input and output tokens based on what Gemini model you're using.
- If Gemini uses code execution when generating your response, the original prompt, the generated code, and the result of the executed code are labeled intermediate tokens and are billed as input tokens.
- Gemini then generates a summary and returns the generated code, the result of the executed code, and the final summary. These are billed as output tokens.
- The Gemini API includes an intermediate token count in the API response, so you can keep track of any additional input tokens beyond those passed in your initial prompt.
Generated code can include both text and multimodal outputs, such as images.
Limitations
- The model can only generate and execute code. It can't return other artifacts like media files.
- The code execution tool doesn't support file URIs as input/output. However,
the code execution tool supports file input and graph output as
inlined bytes. By using these input and output capabilities, you can upload
CSV and text files, ask questions about the files, and have
Matplotlib graphs generated as part of the code execution result.
The supported mime types for inlined bytes are
.cpp,.csv,.java,.jpeg,.js,.png,.py,.ts, and.xml. - Code execution can run for a maximum of 30 seconds before timing out.
- In some cases, enabling code execution can lead to regressions in other areas of model output (for example, writing a story).