Gen AI Evaluation Service は、生成 AI モデルの客観的でデータドリブンな評価を行うためのエンタープライズ グレードのツールを提供します。モデルの移行、プロンプトの編集、ファインチューニングなど、さまざまな開発タスクをサポートし、情報を提供します。
Gen AI Evaluation Service の特徴
Gen AI Evaluation Service の特徴は、適応型ルーブリックを使用できることです。これは、個々のプロンプトに合わせて調整された、合格または不合格のテストセットです。評価ルーブリックは、ソフトウェア開発の単体テストに似ており、さまざまなタスクでモデルのパフォーマンスを向上させることを目的としています。
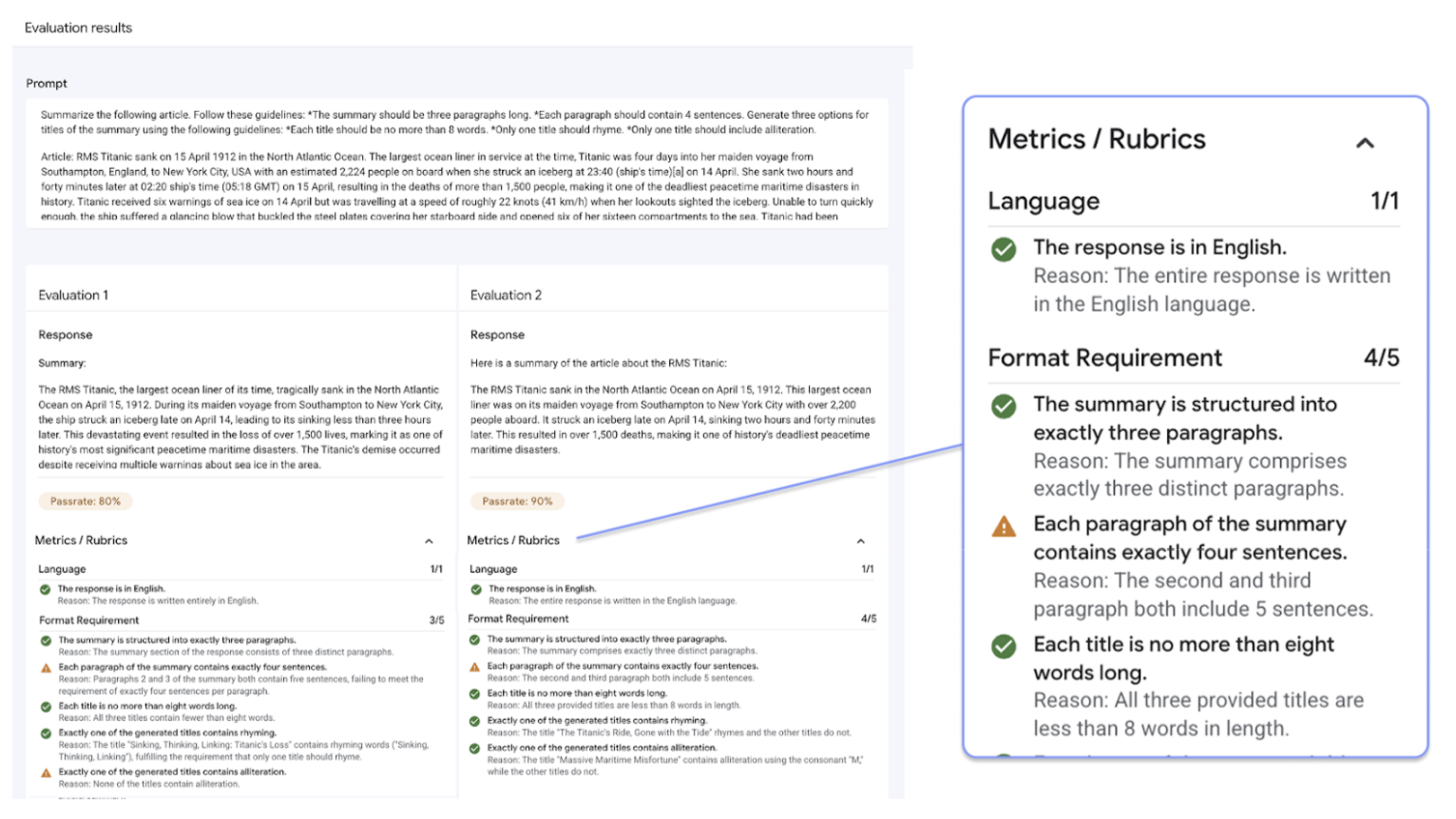
Gen AI Evaluation Service は、次の一般的な評価方法をサポートしています。
適応型ルーブリック(推奨): データセット内の個々のプロンプトごとに、合格または不合格の固有のルーブリックのセットを生成します。
静的ルーブリック: すべてのプロンプトに固定のスコアリング基準を適用します。
計算ベースの指標: グラウンド トゥルースが利用可能な場合は、
ROUGEやBLEUなどの決定論的アルゴリズムを使用します。カスタム関数: 特殊な要件に合わせて、独自の評価ロジックを Python で定義します。
評価データセットの生成
評価データセットは、次の方法で作成できます。
完全なプロンプト インスタンスを含むファイルをアップロードします。または、対応する変数値のファイルとともにプロンプト テンプレートを指定し、完全なプロンプトを入力します。
本番環境ログから直接サンプリングして、モデルの実際の使用状況を評価します。
合成データ生成を使用すると、任意のプロンプト テンプレートに対して一貫性のある大量の例を生成できます。
サポートされているインターフェース
次のインターフェースを使用して、評価を定義して実行できます。
Google Cloud コンソール: ガイド付きのエンドツーエンドのワークフローを提供するウェブ ユーザー インターフェース。データセットの管理や評価を行うだけでなく、情報を深く分析してインタラクティブなレポートを生成したり、可視化することができます。コンソールで評価を行うをご覧ください。
Python SDK: 評価をプログラムで実行し、モデルの比較を Colab または Jupyter 環境で直接レンダリングします。Vertex AI SDK で生成 AI クライアントを使用して評価を行うをご覧ください。
ユースケース
Gen AI Evaluation Service を使用すると、特定のタスクに対するモデルのパフォーマンスと、独自の基準に対するモデルのパフォーマンスを確認できます。これにより、一般公開のリーダーボードや一般的なベンチマークからは得られない貴重な分析情報を得ることができます。これは、次のような重要な開発タスクで役立ちます。
モデルの移行: モデル バージョンを比較して動作の違いを把握し、それに応じてプロンプトと設定を調整します。
最適なモデルの特定: データを基に Google モデルとサードパーティ モデルを直接比較して、パフォーマンスのベースラインを確立し、ユースケースに最適なモデルを特定します。
プロンプトの改善: 評価結果を使用して、カスタマイズを進めることができます。評価を再実行すると、フィードバック ループが緊密になり、変更に対して即時的で定量的なフィードバックを得ることができます。
モデルのファインチューニング: すべての実行に一貫した評価基準を適用し、ファインチューニングされたモデルの品質を評価します。
適応型ルーブリックを使用した評価
適応型ルーブリックは、ほとんどの評価ユースケースで推奨される方法であり、通常、最も迅速に評価を開始できます。
テスト駆動型の評価フレームワークでは、ほとんどの LLM-as-a-judge システムのように一般的な評価基準を使用するのではなく、データセット内の個々のプロンプトごとに、合格または不合格の一意の基準を適応的に生成します。このアプローチにより、すべての評価が評価対象の特定のタスクに関連したものになります。
各プロンプトの評価プロセスでは、2 段階のシステムが使用されます。
ルーブリックの生成: サービスはまずプロンプトを分析し、優れた回答が満たすべき具体的で検証可能なテスト(ルーブリック)のリストを生成します。
ルーブリックの検証: モデルが回答を生成すると、サービスは各ルーブリックに対して回答を評価し、
PassまたはFailを明確に判定して根拠を提示します。

最終結果は、集計された合格率と、モデルが合格したルーブリックの詳細な内訳になります。これにより、問題を診断して改善を測定するための実用的な分析情報を得ることができます。
大まかな主観的なスコアから、きめ細かい客観的なテスト結果に移行することで、評価主導の開発サイクルを採用し、生成 AI アプリケーションの構築プロセスにソフトウェア エンジニアリングのベスト プラクティスを導入できます。
ルーブリック評価の例
Gen AI Evaluation Service がルーブリックを生成して使用する方法を理解するには、次の例をご覧ください。
ユーザーによるプロンプト: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
このプロンプトでは、ルーブリックの生成ステップで次のルーブリックが生成される可能性があります。
ルーブリック 1: 回答は、提供された記事の要約になっている。
ルーブリック 2: 回答に 4 つの文が含まれている。
ルーブリック 3: 楽観的なトーンを維持している。
モデルは次のような回答を生成する可能性があります。The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
ルーブリックの検証では、Gen AI Evaluation Service が各ルーブリックに対して回答を評価します。
ルーブリック 1: 回答は、提供された記事の要約になっている。
判定:
Pass理由: 回答は要点を正確に要約しています。
ルーブリック 2: 回答に 4 つの文が含まれている。
判定:
Pass理由: 回答は 4 つの異なる文で構成されています。
ルーブリック 3: 楽観的なトーンを維持している。
判定:
Fail理由: 最後の文で否定的な点が導入されており、楽観的なトーンが損なわれています。
この回答の最終合格率は 66.7% です。2 つのモデルを比較するには、生成された同じテストセットに対して回答を評価し、全体的な合格率を比較します。
評価ワークフロー
通常、評価を完了するには次の手順が必要です。
評価データセットを作成する: 特定のユースケースを反映したプロンプト インスタンスのデータセットを作成します。計算ベースの指標を使用する場合は、基準となる回答(グラウンド トゥルース)を含めることができます。
評価指標を定義する: モデルのパフォーマンスの測定に使用する指標を選択します。SDK はすべての指標タイプをサポートしていますが、コンソールは適応型ルーブリックをサポートしています。
モデルの回答を生成する: データセットに対する回答を生成するモデルを 1 つ以上選択します。SDK は
LiteLLMを介して呼び出し可能なモデルをサポートしますが、コンソールは Google Gemini モデルをサポートします。評価を実行する: 評価ジョブを実行します。このジョブでは、選択した指標に基づいて各モデルの回答が評価されます。
結果を解釈する: 集計スコアと個々の回答を確認して、モデルのパフォーマンスを分析します。
評価の開始
評価はコンソールで開始できます。
次のコードは、Vertex AI SDK の生成 AI クライアントを使用して評価を完了する方法を示しています。
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Gen AI Evaluation Service には、次の 2 つの SDK インターフェースが用意されています。
Vertex AI SDK の生成 AI クライアント(推奨)(プレビュー)
from vertexai import client生成 AI クライアントは、評価用の新しい推奨インターフェースであり、統合されたクライアント クラスを通じてアクセスします。これは、すべての評価方法をサポートしており、モデルの比較、ノートブック内の可視化、モデルのカスタマイズに関する分析情報を含むワークフロー向けに設計されています。
Vertex AI SDK の評価モジュール(GA)
from vertexai.evaluation import EvalTask評価モジュールは古いインターフェースであり、既存のワークフローとの下位互換性を維持するために維持されていますが、開発は行われていません。このクラスには
EvalTaskクラスを介してアクセスします。この方法は、標準の LLM-as-a-judge と計算ベースの指標をサポートしていますが、適応型ルーブリックなどの新しい評価方法はサポートしていません。
サポートされるリージョン
Gen AI Evaluation Service では、次のリージョンがサポートされています。
アイオワ(
us-central1)北バージニア(
us-east4)オレゴン(
us-west1)ラスベガス、ネバダ州(
us-west4)ベルギー(
europe-west1)オランダ(
europe-west4)パリ、フランス(
europe-west9)