构建并评估生成式 AI 模型后,您便可以使用该模型构建智能体,例如聊天机器人。借助 Gen AI Evaluation Service,您可以衡量该智能体在您的应用场景中完成任务和实现目标的能力。
概览
您可以通过以下方式评估智能体:
最终回答评估:评估智能体的最终输出(无论该智能体是否实现了其目标)。
轨迹评估:评估代理为生成最终回答而采取的路径(工具调用序列)。
借助 Gen AI Evaluation Service,只需通过一次 Vertex AI SDK 查询,便可触发智能体执行,并同时获取轨迹评估和最终回答评估的指标。
支持的智能体
Gen AI Evaluation Service 支持以下几类智能体:
| 支持的智能体 | 说明 |
|---|---|
| 通过 Agent Engine 的模板构建的智能体 | Agent Engine(即 LangChain on Vertex AI)是一个 Google Cloud 平台,您可以在其中部署和管理智能体。 |
| 通过 Agent Engine 的可自定义模板构建的 LangChain 智能体 | LangChain 是一个开源平台。 |
| 自定义智能体函数 | 自定义智能体函数是一种灵活的函数,可接收智能体的提示作为输入,并以字典形式返回回答及相应轨迹。 |
定义用于评估智能体的指标
定义用于评估最终回答或相应轨迹的指标:
最终回答评估
最终回答评估流程与模型回答评估流程相同。如需了解详情,请参阅定义评估指标。
轨迹评估
以下指标可帮助您评估模型遵循预期轨迹的能力:
完全匹配
如果预测轨迹与参考轨迹完全相同,且调用的工具及调用顺序也完全相同,则 trajectory_exact_match 指标会返回 1 分,否则返回 0 分。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
reference_trajectory |
智能体为满足查询请求而应该使用的预期工具。 |
输出得分
| 值 | 说明 |
|---|---|
| 0 | 预测轨迹与参考轨迹不一致。 |
| 1 | 预测轨迹与参考轨迹一致。 |
按顺序匹配
如果预测轨迹包含参考轨迹中调用的所有工具且调用顺序相同,不过可能还调用了一些其他的工具,则 trajectory_in_order_match 指标会返回 1 分,否则返回 0 分。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而使用的预测轨迹。 |
reference_trajectory |
智能体为满足查询请求而应该使用的预期预测轨迹。 |
输出得分
| 值 | 说明 |
|---|---|
| 0 | 预测轨迹中的工具调用与参考轨迹中工具调用的顺序不一致。 |
| 1 | 预测轨迹与参考轨迹一致。 |
任意顺序匹配
如果预测轨迹包含参考轨迹中调用的所有工具,但调用顺序可能有出入,并且可能还调用了一些其他的工具,则 trajectory_any_order_match 指标会返回 1 分,否则返回 0 分。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
reference_trajectory |
智能体为满足查询请求而应该使用的预期工具。 |
输出得分
| 值 | 说明 |
|---|---|
| 0 | 预测轨迹未包含参考轨迹中的全部工具调用。 |
| 1 | 预测轨迹与参考轨迹一致。 |
精确率
trajectory_precision 指标用于根据参考轨迹来衡量预测轨迹中有多少工具调用是真正相关的或正确的。
精确率的计算方式如下:统计预测轨迹中有多少操作同时也出现在参考轨迹中。然后,将该数量除以预测轨迹中的操作总数。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
reference_trajectory |
智能体为满足查询请求而应该使用的预期工具。 |
输出得分
| 值 | 说明 |
|---|---|
| [0,1] 范围内的浮点数 | 得分越高,预测轨迹越精确。 |
召回率
trajectory_recall 指标用于衡量预测轨迹实际捕获了多少参考轨迹中的必要工具调用。
召回率的计算方式如下:统计参考轨迹中有多少操作同时也出现在预测轨迹中。然后,将该数量除以参考轨迹中的操作总数。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
reference_trajectory |
智能体为满足查询请求而应该使用的预期工具。 |
输出得分
| 值 | 说明 |
|---|---|
| [0,1] 范围内的浮点数 | 得分越高,预测轨迹的召回性能就越好。 |
特定工具的使用
trajectory_single_tool_use 指标用于检查预测轨迹中是否使用了指标规范中指定的某个特定工具。该指标不会检查工具调用的顺序或该工具的使用次数,只会检查该工具是否被调用过。
指标输入参数
| 输入参数 | 说明 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
输出得分
| 值 | 说明 |
|---|---|
| 0 | 相应工具不存在 |
| 1 | 相应工具存在。 |
此外,默认情况下,评估结果中还会添加以下两个智能体性能指标。您无需在 EvalTask 中指定它们。
latency
智能体返回回答所用的时间。
| 值 | 说明 |
|---|---|
| 浮点数 | 以秒为单位计算。 |
failure
一个布尔值,用于描述智能体调用是导致错误还是成功完成。
输出得分
| 值 | 说明 |
|---|---|
| 1 | 错误 |
| 0 | 返回了有效回答 |
准备用于智能体评估的数据集
准备用于评估最终回答或相应轨迹的数据集。
最终回答评估的数据架构与模型回答评估的数据架构类似。
对于基于计算的轨迹评估,您的数据集需要提供以下信息:
| 输入类型 | 输入字段内容 |
|---|---|
predicted_trajectory |
智能体为生成最终回答而调用的工具的列表。 |
reference_trajectory(对于 trajectory_single_tool_use metric 不是必需的) |
智能体为满足查询请求而应该使用的预期工具。 |
评估数据集示例
以下示例展示了用于轨迹评估的数据集。请注意,除 trajectory_single_tool_use 以外的所有指标都需要提供 reference_trajectory。
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
导入评估数据集
您可以使用以下格式导入数据集:
存储在 Cloud Storage 中的 JSONL 或 CSV 文件
BigQuery 表
Pandas DataFrame
Gen AI Evaluation Service 提供了一些公开的示例数据集,用于演示如何评估智能体。以下代码展示了如何从 Cloud Storage 存储桶导入这些公开数据集:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
其中,dataset 是以下公开数据集之一:
"on-device",用于控制家居设备的设备端家居助理。该智能体可以协助处理诸如以下一类查询:“将卧室的空调设定为在晚上 11 点至次日早上 8 点期间开启,其余时间关闭。”"customer-support",客户服务智能体。该智能体可以协助处理诸如以下一类查询:“你能取消所有待处理的订单并上报所有未解决的支持服务工单吗?”"content-creation",营销内容创作智能体。该智能体可以协助处理诸如以下一类查询:“将广告系列 X 重新安排为仅于 2024 年 12 月 25 日在社交媒体网站 Y 上投放的一次性广告系列,且将预算减少 50%。”
运行智能体评估
运行轨迹评估或最终回答评估:
在评估智能体时,您可以混合使用回答评估指标和轨迹评估指标,如以下代码所示:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
指标自定义
您可以使用模板化界面或从头开始自定义基于大型语言模型的轨迹评估指标,如需了解详情,请参阅基于模型的指标部分。以下是一个模板化示例:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
您还可以按如下方式定义基于计算的自定义轨迹评估或回答评估指标:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
查看和解读结果
对于轨迹评估或最终回答评估,评估结果如下所示:
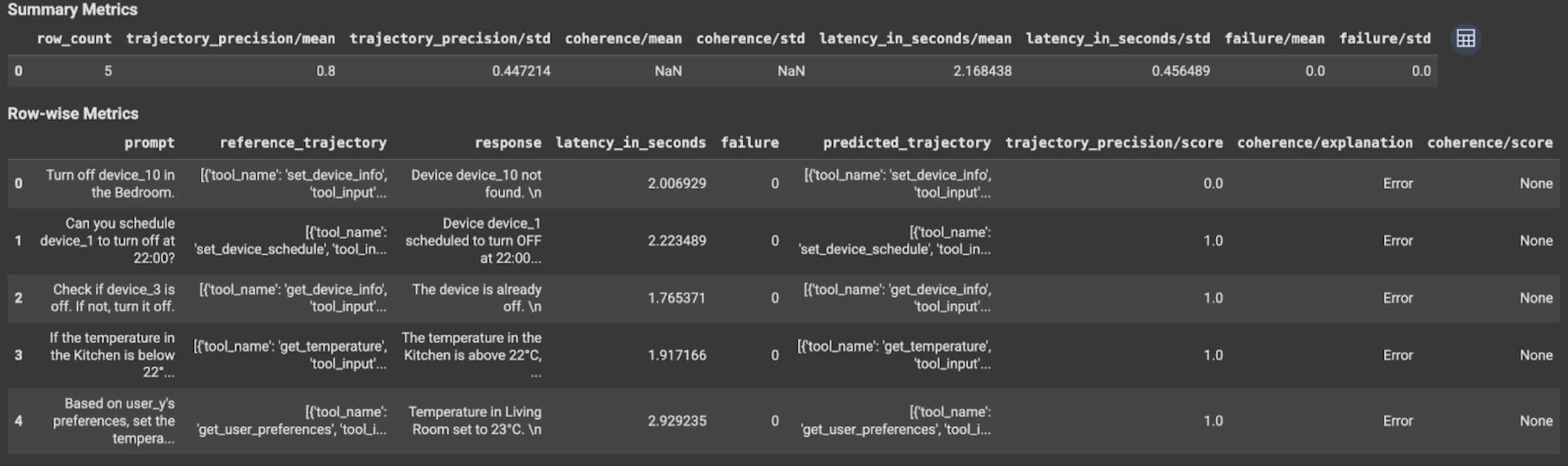
评估结果包含以下信息:
最终回答指标
实例级结果
| 列 | 说明 |
|---|---|
| 回答 | 智能体生成的最终回答。 |
| latency_in_seconds | 生成回答所用的时间。 |
| 失败 | 指示是否生成了有效回答。 |
| 得分 | 针对指标规范中指定的回答计算的得分。 |
| 说明 | 指标规范中指定的得分的说明。 |
汇总结果
| 列 | 说明 |
|---|---|
| 平均值 | 所有实例的平均得分。 |
| 标准差 | 所有得分的标准差。 |
轨迹指标
实例级结果
| 列 | 说明 |
|---|---|
| predicted_trajectory | 智能体为生成最终回答而采用的工具调用序列。 |
| reference_trajectory | 预期工具调用序列。 |
| 得分 | 针对预测轨迹和指标规范中指定的参考轨迹计算的得分。 |
| latency_in_seconds | 生成回答所用的时间。 |
| 失败 | 指示是否生成了有效回答。 |
汇总结果
| 列 | 说明 |
|---|---|
| 平均值 | 所有实例的平均得分。 |
| 标准差 | 所有得分的标准差。 |
Agent2Agent (A2A) protocol
如果您要构建多智能体系统,我们强烈建议您查看 A2A Protocol。A2A Protocol 是一种开放标准,可让 AI 智能体之间实现无缝通信和协作,而无需考虑其底层框架。该项目已于 2025 年 6 月由 Google Cloud 捐赠给了 Linux 基金会。如需使用 A2A SDK 或试用相关示例,请查看相应的 GitHub 代码库。
后续步骤
试用以下智能体评估笔记本: