Cette page décrit le moteur RAG Vertex AI et son fonctionnement.
| Description | Console |
|---|---|
| Pour savoir comment utiliser le SDK Vertex AI pour exécuter des tâches du moteur RAG de Vertex AI, consultez le démarrage rapide RAG pour Python. |
Présentation
Le moteur RAG Vertex AI, un composant de la plate-forme Vertex AI, facilite la génération augmentée par récupération (RAG). Le moteur RAG de Vertex AI est également un framework de données permettant de développer des applications de grand modèle de langage (LLM) augmentées par le contexte. L'augmentation par le contexte se produit lorsque vous appliquez un LLM à vos données. Cette approche implémente la génération augmentée par récupération (RAG).
Un problème courant avec les LLM est qu'ils ne comprennent pas les connaissances privées, c'est-à-dire les données de votre organisation. Le moteur RAG de Vertex AI vous permet d'enrichir le contexte LLM avec des informations privées supplémentaires, car le modèle peut réduire les hallucinations et répondre aux questions plus précisément.
En combinant des sources de connaissances supplémentaires avec les connaissances existantes des LLM, un meilleur contexte est fourni. Le contexte amélioré associé à la requête améliore la qualité de la réponse du LLM.
L'image suivante illustre les concepts clés pour comprendre le moteur RAG de Vertex AI.
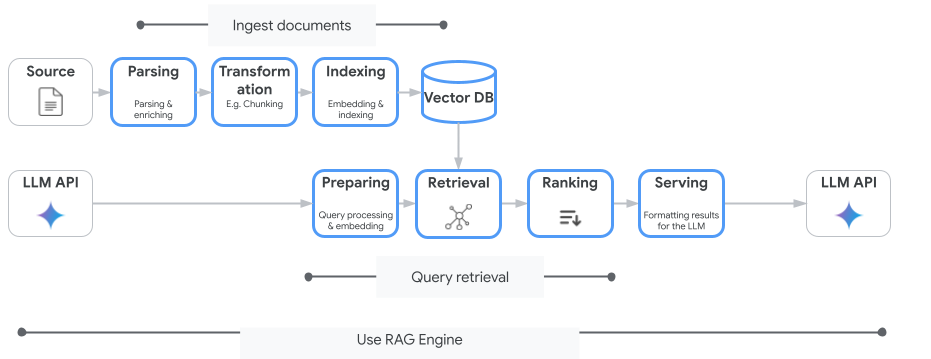
Ces concepts sont listés dans l'ordre du processus de génération augmentée par récupération (RAG).
Ingestion de données : intégrez des données provenant de différentes sources. Par exemple, les fichiers locaux, Cloud Storage et Google Drive.
Transformation des données : conversion des données en préparation pour l'indexation. Par exemple, les données sont divisées en blocs.
Embedding (ou "plongement") : représentations numériques de mots ou de textes. Ces nombres capturent la signification sémantique et le contexte du texte. Les mots ou textes similaires ou connexes ont tendance à avoir des embeddings similaires, ce qui signifie qu'ils sont plus proches les uns des autres dans l'espace vectoriel de grande dimension.
Indexation des données : le moteur RAG Vertex AI crée un index appelé corpus. L'index structure la base de connaissances afin qu'il soit optimisé pour la recherche. Par exemple, l'index s'apparente à une table des matières détaillée pour un immense livre de référence.
Récupération : lorsqu'un utilisateur pose une question ou fournit une requête, le composant de récupération du moteur RAG Vertex AI effectue une recherche dans sa base de connaissances afin de trouver des informations pertinentes pour la requête.
Génération : les informations récupérées deviennent le contexte ajouté à la requête utilisateur d'origine pour guider le modèle d'IA générative et lui permettre de générer des réponses factuelles ancrées et pertinentes.
Régions où le service est disponible
Le moteur RAG de Vertex AI est disponible dans les régions suivantes :
| Région | Emplacement | Description | Étape de lancement |
|---|---|---|---|
us-central1 |
Iowa | Les versions v1 et v1beta1 sont acceptées. |
Liste d'autorisation |
us-east4 |
Virginie | Les versions v1 et v1beta1 sont acceptées. |
DG |
europe-west3 |
Francfort, Allemagne | Les versions v1 et v1beta1 sont acceptées. |
DG |
europe-west4 |
Eemshaven, Pays-Bas | Les versions v1 et v1beta1 sont acceptées. |
DG |
us-central1devientAllowlist. Si vous souhaitez tester le moteur RAG de Vertex AI, essayez d'autres régions. Si vous prévoyez d'intégrer votre trafic de production àus-central1, contactezvertex-ai-rag-engine-support@google.com.
Supprimer le moteur RAG Vertex AI
Les exemples de code suivants montrent comment supprimer un moteur RAG Vertex AI pour la console Google Cloud , Python et REST :
Paramètres et exemples de code de l'API version 1 (v1).
Paramètres et exemples de code de l'API v1beta1.
Envoyer des commentaires
Pour discuter avec l'assistance Google, accédez au groupe d'assistance du moteur RAG Vertex AI.
Pour envoyer un e-mail, utilisez l'adresse e-mail vertex-ai-rag-engine-support@google.com.
Étapes suivantes
- Pour savoir comment utiliser le SDK Vertex AI pour exécuter des tâches du moteur RAG de Vertex AI, consultez le démarrage rapide RAG pour Python.
- Pour en savoir plus sur l'ancrage, consultez la présentation de l'ancrage.
- Pour en savoir plus sur les réponses du moteur RAG, consultez Résultats de récupération et de génération du moteur RAG de Vertex AI.
- Pour en savoir plus sur l'architecture RAG :