This page describes what Vertex AI RAG Engine is and how it works.
| Description | Console |
|---|---|
| To learn how to use the Vertex AI SDK to run Vertex AI RAG Engine tasks, see the RAG quickstart for Python. |
Overview
Vertex AI RAG Engine, a component of the Vertex AI Platform, facilitates Retrieval-Augmented Generation (RAG). Vertex AI RAG Engine is also a data framework for developing context-augmented large language model (LLM) applications. Context augmentation occurs when you apply an LLM to your data. This implements retrieval-augmented generation (RAG).
A common problem with LLMs is that they don't understand private knowledge, that is, your organization's data. With Vertex AI RAG Engine, you can enrich the LLM context with additional private information, because the model can reduce hallucination and answer questions more accurately.
By combining additional knowledge sources with the existing knowledge that LLMs have, a better context is provided. The improved context along with the query enhances the quality of the LLM's response.
The following image illustrates the key concepts to understanding Vertex AI RAG Engine.
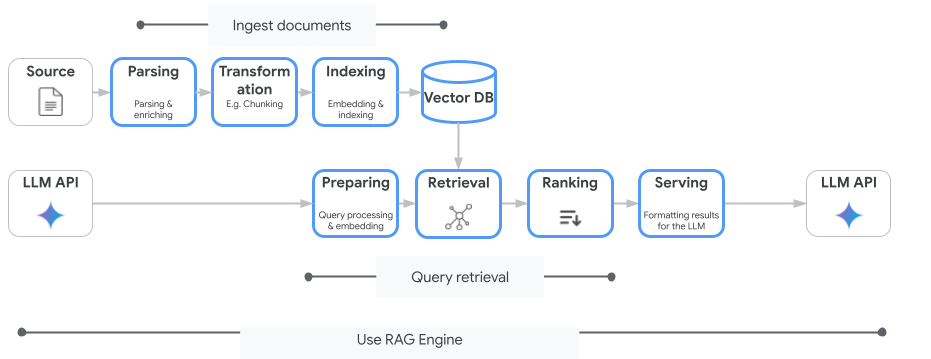
These concepts are listed in the order of the retrieval-augmented generation (RAG) process.
Data ingestion: Intake data from different data sources. For example, local files, Cloud Storage, and Google Drive.
Data transformation: Conversion of the data in preparation for indexing. For example, data is split into chunks.
Embedding: Numerical representations of words or pieces of text. These numbers capture the semantic meaning and context of the text. Similar or related words or text tend to have similar embeddings, which means they are closer together in the high-dimensional vector space.
Data indexing: Vertex AI RAG Engine creates an index called a corpus. The index structures the knowledge base so it's optimized for searching. For example, the index is like a detailed table of contents for a massive reference book.
Retrieval: When a user asks a question or provides a prompt, the retrieval component in Vertex AI RAG Engine searches through its knowledge base to find information that is relevant to the query.
Generation: The retrieved information becomes the context added to the original user query as a guide for the generative AI model to generate factually grounded and relevant responses.
Supported regions
Vertex AI RAG Engine is supported in the following regions:
| Region | Location | Description | Launch stage |
|---|---|---|---|
us-central1 |
Iowa | v1 and v1beta1 versions are supported. |
Allowlist |
us-east4 |
Virginia | v1 and v1beta1 versions are supported. |
GA |
europe-west3 |
Frankfurt, Germany | v1 and v1beta1 versions are supported. |
GA |
europe-west4 |
Eemshaven, Netherlands | v1 and v1beta1 versions are supported. |
GA |
us-central1is changed toAllowlist. If you'd like to experiment with Vertex AI RAG Engine, try other regions. If you plan to onboard your production traffic tous-central1, contactvertex-ai-rag-engine-support@google.com.
Delete Vertex AI RAG Engine
The following code samples demonstrate how to delete a Vertex AI RAG Engine for the Google Cloud console, Python, and REST:
Version 1 (v1) API parameters and code samples.
v1beta1 API parameters and code samples.
Submit feedback
To chat with Google support, go to the Vertex AI RAG Engine support group.
To send an email, use the email address
vertex-ai-rag-engine-support@google.com.
What's next
- To learn how to use the Vertex AI SDK to run Vertex AI RAG Engine tasks, see RAG quickstart for Python.
- To learn about grounding, see Grounding overview.
- To learn more about the responses from RAG, see Retrieval and Generation Output of Vertex AI RAG Engine.
- To learn about the RAG architecture: