La función de respuesta a preguntas visuales (VQA) te permite proporcionar una imagen al modelo y hacer una pregunta sobre el contenido de la imagen. En respuesta a tu pregunta, obtienes una o varias respuestas en lenguaje natural.
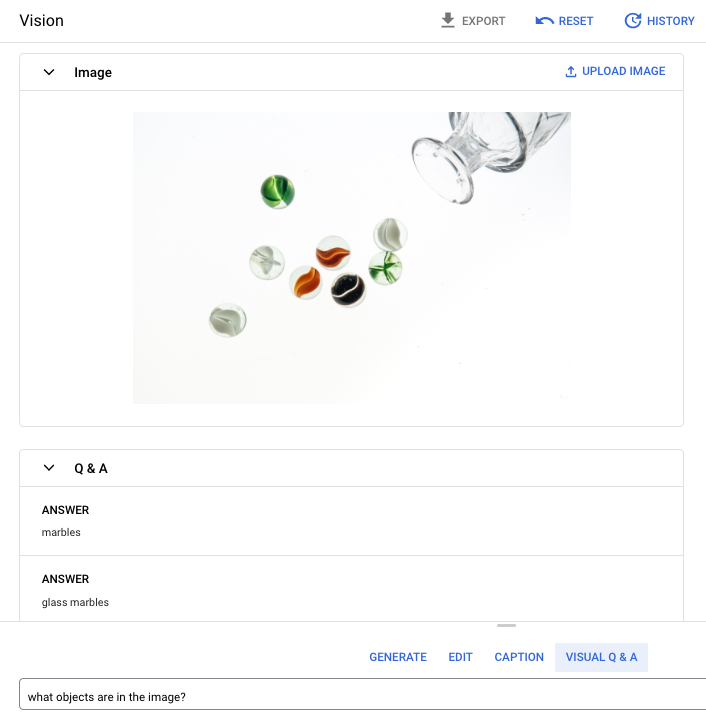
Pregunta: ¿Qué objetos hay en la imagen?
Respuesta 1: canicas
Respuesta 2: canicas de cristal
Idiomas disponibles
La función de VQA está disponible en los siguientes idiomas:
- English (en)
Rendimiento y limitaciones
Se aplican los siguientes límites cuando usas este modelo:
| Límites | Valor |
|---|---|
| Número máximo de solicitudes a la API (formato breve) por minuto y proyecto | 500 |
| Número máximo de tokens devueltos en la respuesta (formato breve) | 64 tokens |
| Número máximo de tokens aceptados en la solicitud (solo para VQA breve) | 80 tokens |
Las siguientes estimaciones de latencia del servicio se aplican cuando usas este modelo. Estos valores son meramente ilustrativos y no constituyen una promesa de servicio:
| Latencia | Valor |
|---|---|
| Solicitudes a la API (formato breve) | 1,5 segundos |
Ubicaciones
Una ubicación es una región que puedes especificar en una solicitud para controlar dónde se almacenan los datos en reposo. Para ver una lista de las regiones disponibles, consulta Ubicaciones de la IA generativa en Vertex AI.
Filtrado de seguridad de la IA responsable
El modelo de la función de subtítulos de imágenes y de preguntas y respuestas visuales no admite filtros de seguridad configurables por el usuario. Sin embargo, el Imagen filtrado de seguridad general se aplica a los siguientes datos:
- Entrada del usuario
- Salida del modelo
Por lo tanto, la salida puede ser diferente de la de ejemplo si Imagen aplica estos filtros de seguridad. Consulta los siguientes ejemplos.
Entrada filtrada
Si la entrada se filtra, la respuesta será similar a la siguiente:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Salida filtrada
Si el número de respuestas devueltas es inferior al número de muestras que has especificado, significa que las respuestas que faltan se han filtrado por la IA responsable. Por ejemplo, a continuación se muestra una respuesta a una solicitud con "sampleCount": 2, pero una de las respuestas se ha filtrado:
{
"predictions": [
"cappuccino"
]
}
Si se filtra toda la salida, la respuesta es un objeto vacío similar al siguiente:
{}
Usar VQA en una imagen (respuestas breves)
Usa los siguientes ejemplos para hacer una pregunta y obtener una respuesta sobre una imagen.
REST
Para obtener más información sobre las solicitudes de modelos de imagetext, consulta la
referencia de la API de modelos de imagetext.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: tu Google Cloud ID de proyecto.
- LOCATION: la región de tu proyecto. Por ejemplo,
us-central1,europe-west2oasia-northeast3. Para ver una lista de las regiones disponibles, consulta Ubicaciones de la IA generativa en Vertex AI. - VQA_PROMPT: la pregunta que quieres hacer sobre tu imagen.
- ¿De qué color es este zapato?
- ¿Qué tipo de mangas tiene la camiseta?
- B64_IMAGE: la imagen de la que se obtendrán los subtítulos. La imagen debe especificarse como una cadena de bytes codificada en Base64. Tamaño máximo: 10 MB.
- RESPONSE_COUNT: el número de respuestas que quieres generar. Valores enteros aceptados: del 1 al 3.
Método HTTP y URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Cuerpo JSON de la solicitud:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 y "prompt": "What is this?". La respuesta devuelve dos cadenas de predicción.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Antes de probar este ejemplo, sigue las Python instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
En este ejemplo, se usa el método load_from_file para hacer referencia a un archivo local como Image base para obtener información. Después de especificar la imagen base, usa el método ask_question en ImageTextModel e imprime las respuestas.
Node.js
Antes de probar este ejemplo, sigue las Node.js instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Node.js de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
En este ejemplo, se llama al métodopredict
en un objeto PredictionServiceClient.
El servicio devuelve respuestas a la pregunta proporcionada.
Usar parámetros para VQA
Cuando recibas respuestas de VQA, podrás definir varios parámetros en función de tu caso práctico.
Número de resultados
Usa el parámetro de número de resultados para limitar la cantidad de respuestas que se devuelven por cada solicitud que envíes. Para obtener más información, consulta la referencia de la API del modelo imagetext (VQA).
Número de semilla
Número que añades a una solicitud para que las respuestas generadas sean deterministas. Si añades un número de semilla a tu solicitud, te asegurarás de obtener la misma predicción (respuestas) cada vez. Sin embargo, las respuestas no se devuelven necesariamente en el mismo orden. Para obtener más información, consulta la referencia de la API del modelo imagetext (VQA).
Siguientes pasos
Consulta artículos sobre Imagen y otros productos de IA generativa en Vertex AI:
- Guía para desarrolladores sobre cómo empezar a usar Imagen 3 en Vertex AI
- Nuevos modelos y herramientas de contenido generado por IA, creados con y para creadores
- Novedades de Gemini: Gems personalizados y generación de imágenes mejorada con Imagen 3
- Google DeepMind: Imagen 3, nuestro modelo de texto a imagen de mayor calidad